Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
SPSS 16 Ez a dia sorozat a gyakorlatok anyagának felidézését segíti.
Nem pótolja a gyakorlatokat és a nyomtatott jegyzet megismerését és megtanulását. Ami többször fordul elő (pl. megnyitás, mentés), azt csak először magyarázom Jelenleg az utolsó téma a kétmintás t próba
, azt csak először magyarázom. Jelenleg az utolsó téma a kétmintás t próba.")
2
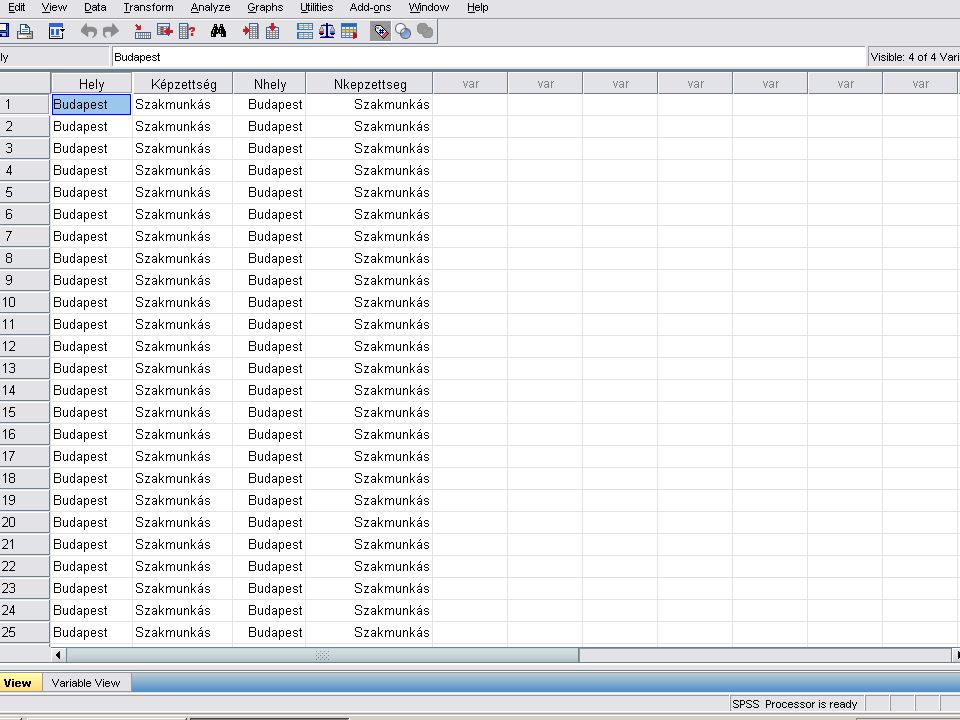
Alapvető statisztikai számítások (tehenek tejhozama)
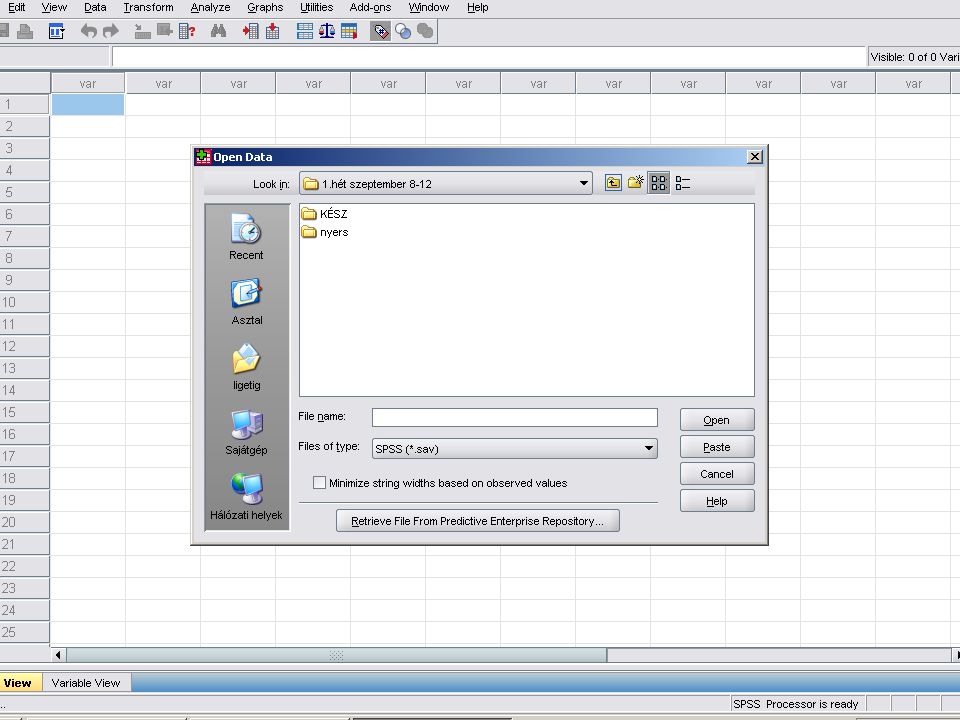
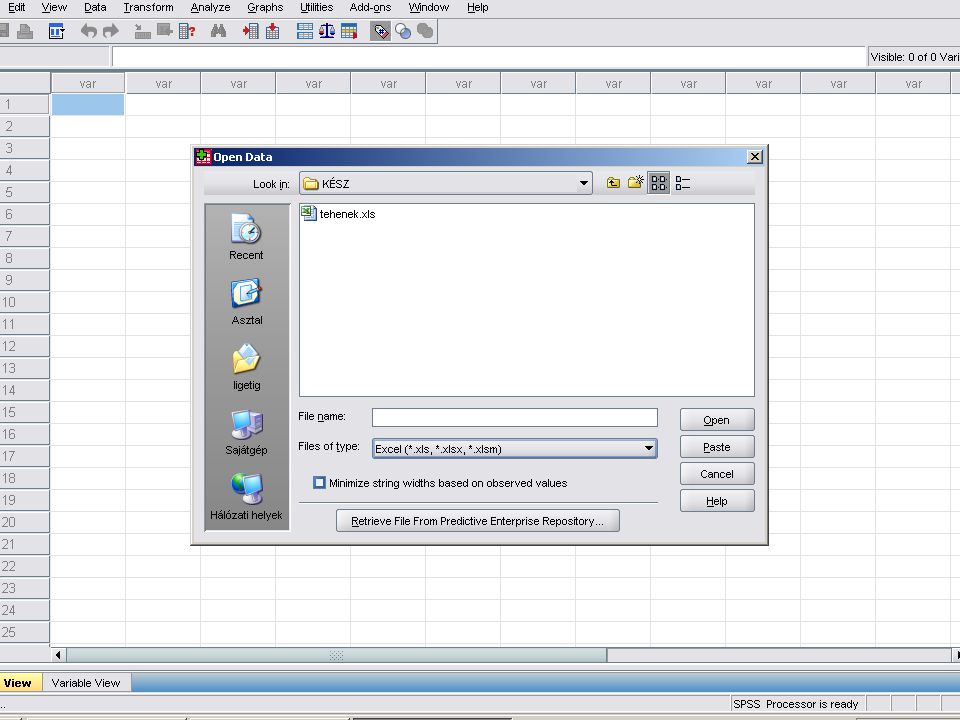
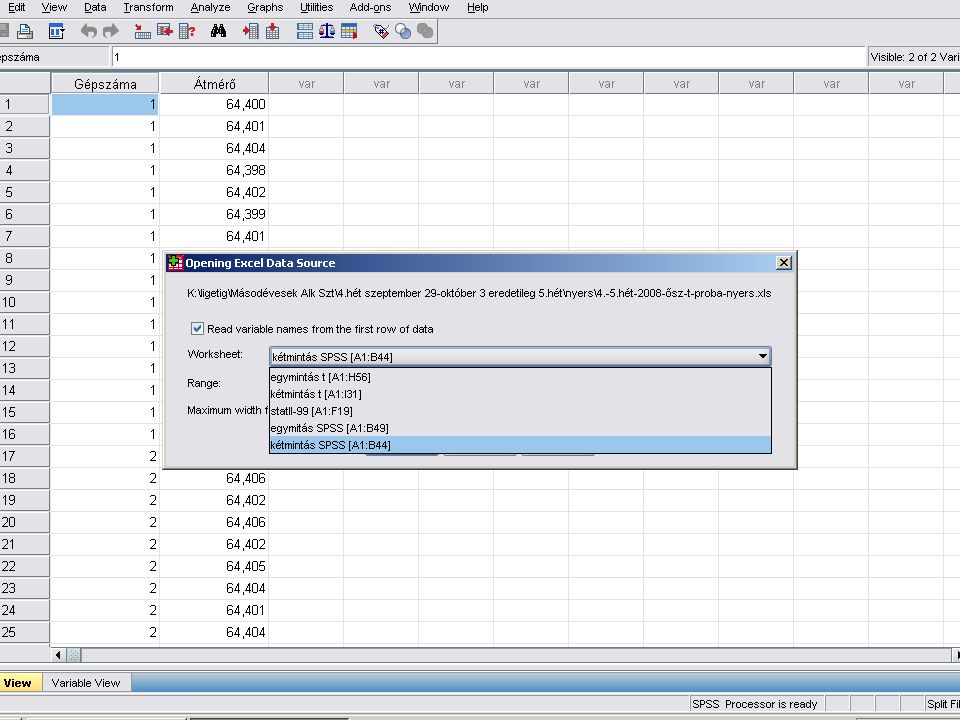
A feladathoz az EXCELben megtalálható adatokból indulunk ki. A következő 2 dián ennek megkeresés látható. (File / Open / Data) A Files of type mellett lévő kombinált választó elem (combo box) választó nyílára kattintva legördülve listát ad. Ebből az EXCELt kell kiválasztani.
 A Files of type mellett lévő kombinált választó elem (combo box) választó nyílára kattintva legördülve listát ad. Ebből az EXCELt kell kiválasztani.")
6
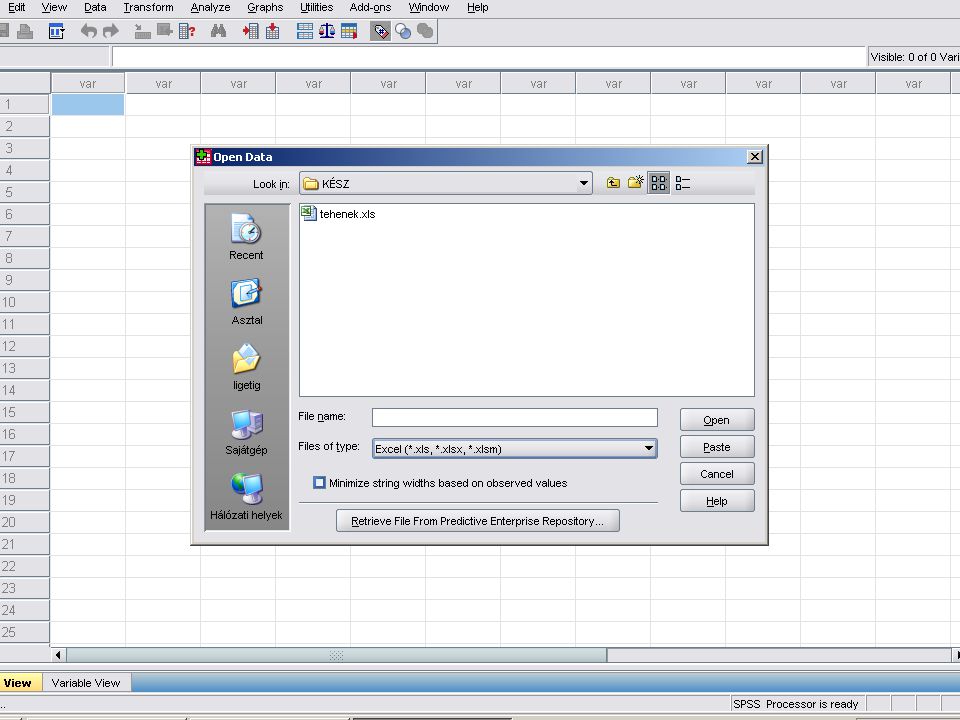
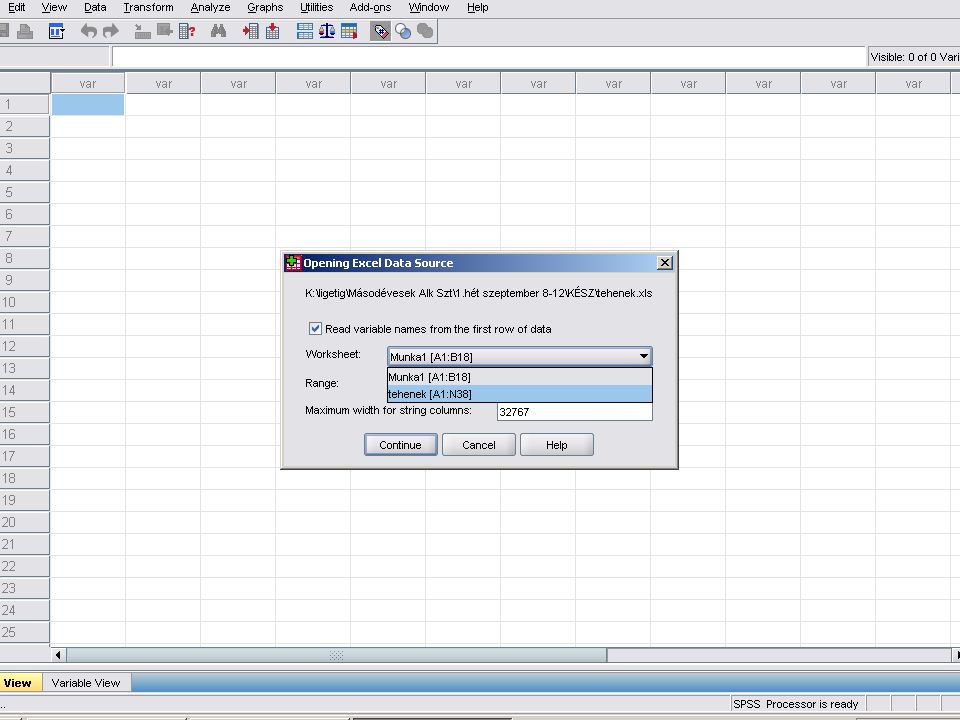
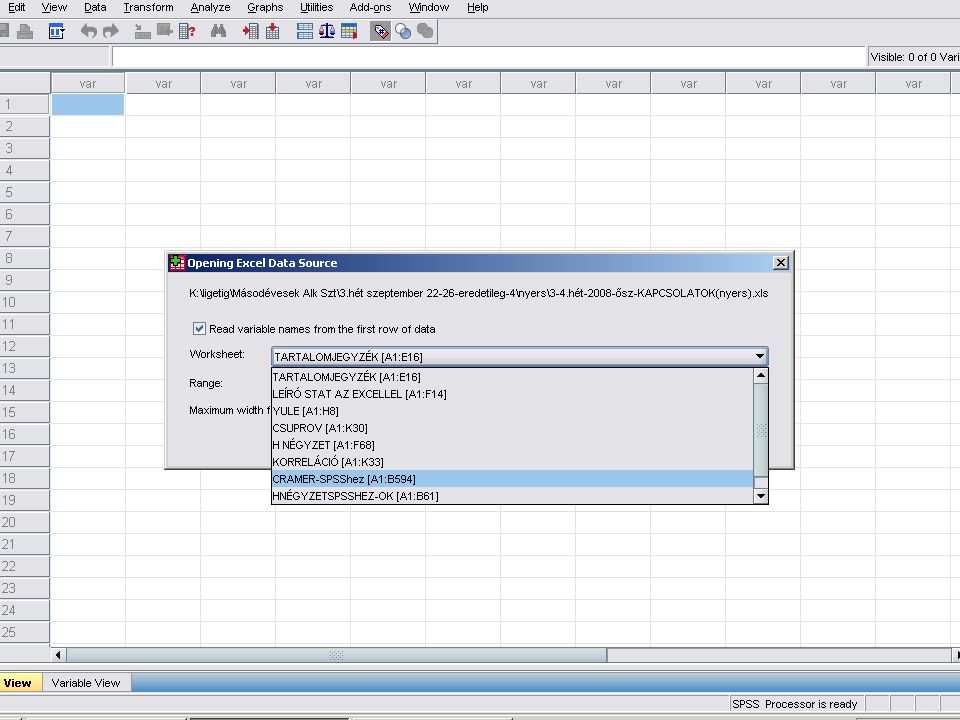
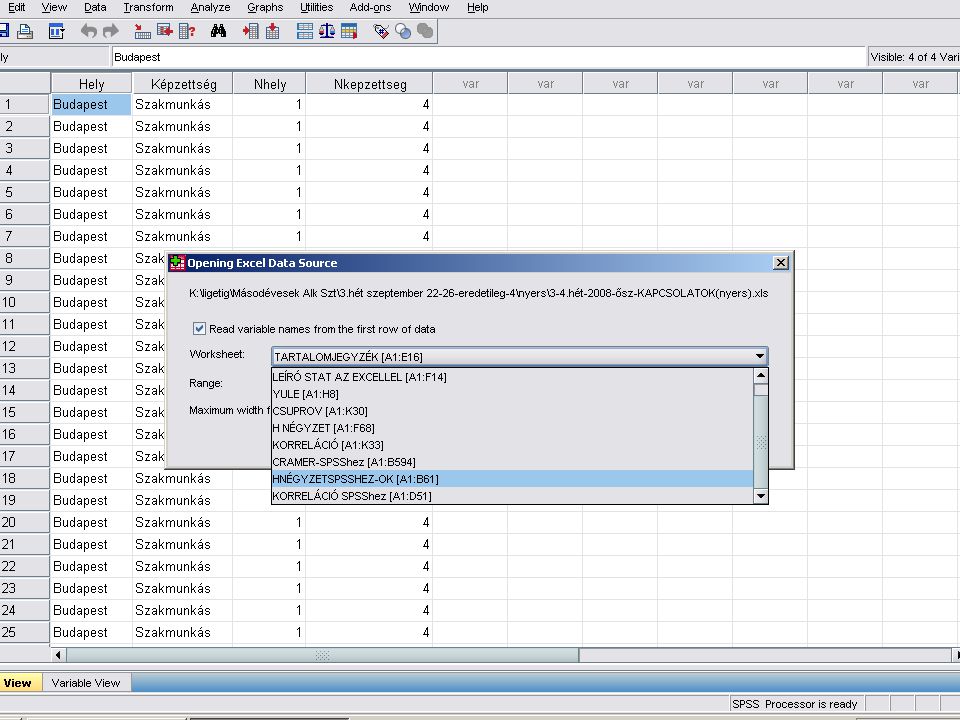
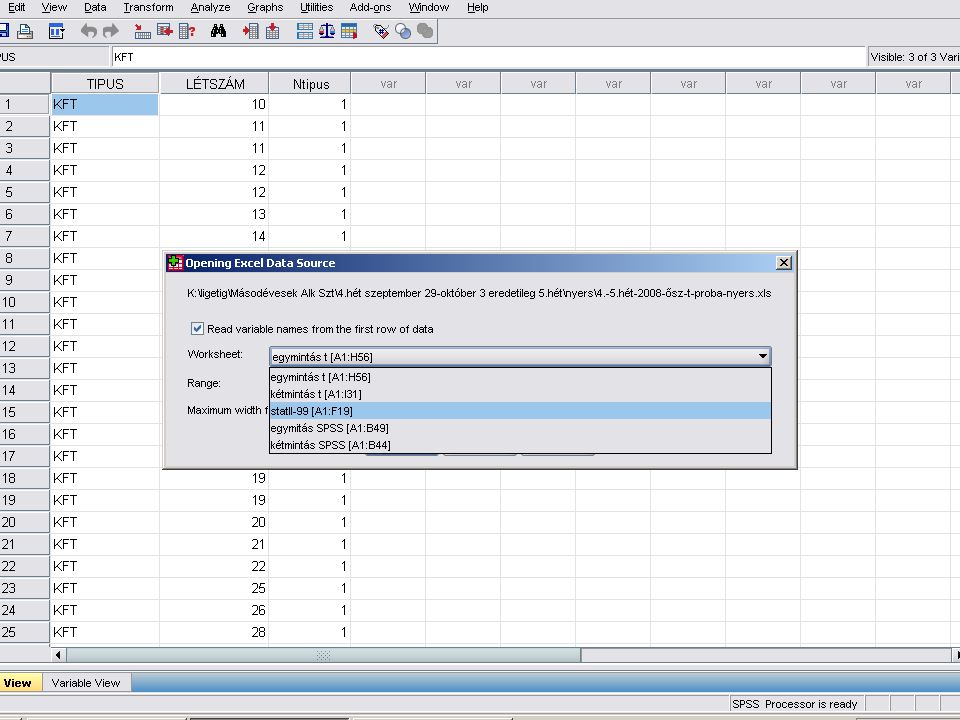
Az Excel kiválasztása után, ha az adott EXCEL munkafüzet több munkalapból áll. Választhatunk, hogy melyik munkalapot és ezen belül melyik tartományt akarjuk megnyitni. A Cuntinue gombra kattintva (vagy Entert nyomva) az SPSS beolvassa az adatokat.
 az SPSS beolvassa az adatokat.")
9
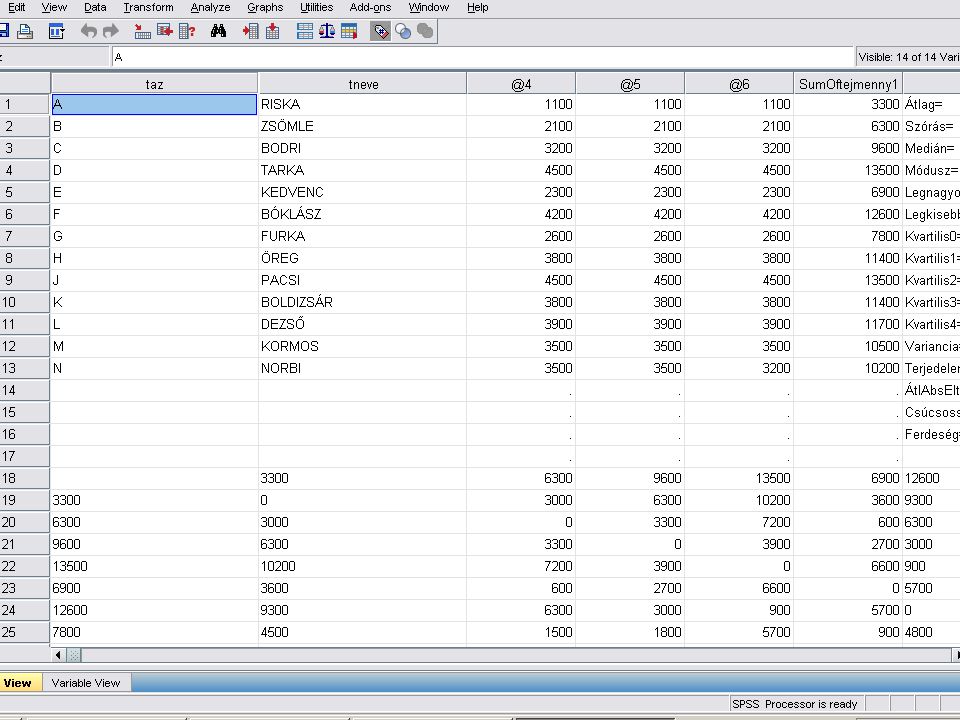
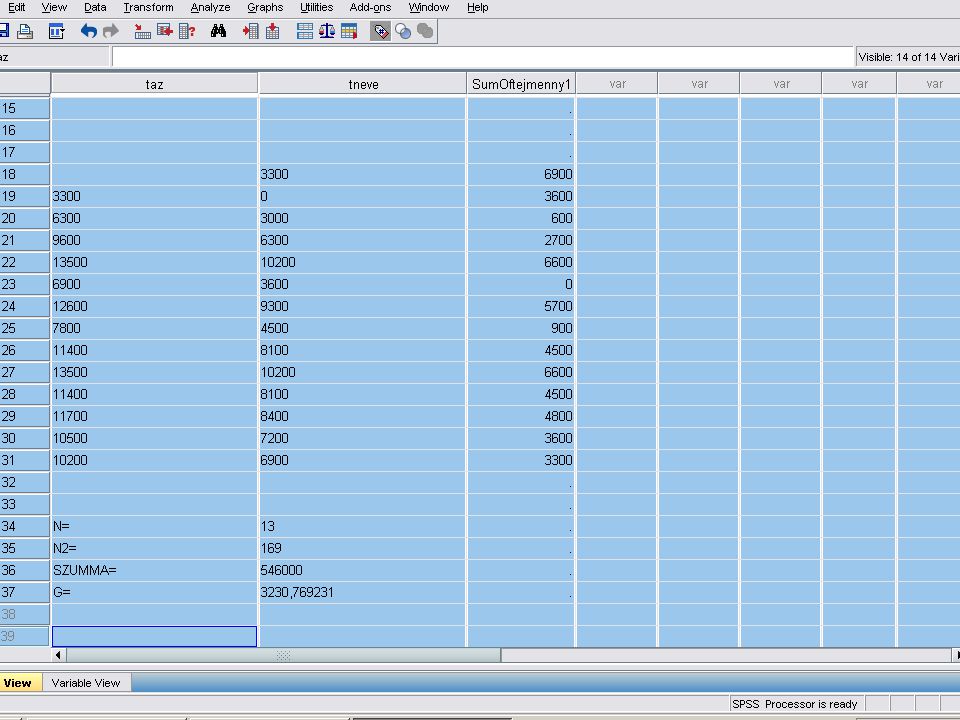
Az előző dián az EXCELből beolvasott adatok láthatók
Az előző dián az EXCELből beolvasott adatok láthatók. A számoláshoz csak a SumofTejmenny1 oszlop első 13 sorában lévő adat kell. A mentések után a felesleges adatokat kitöröljük.

13
Felesleges adatok törlése
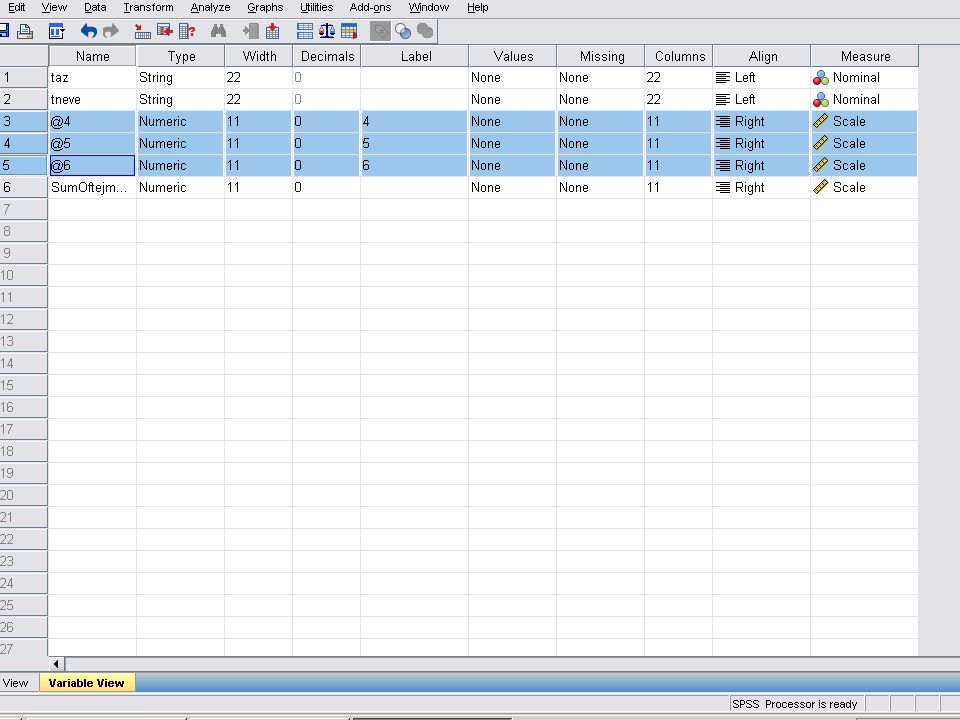
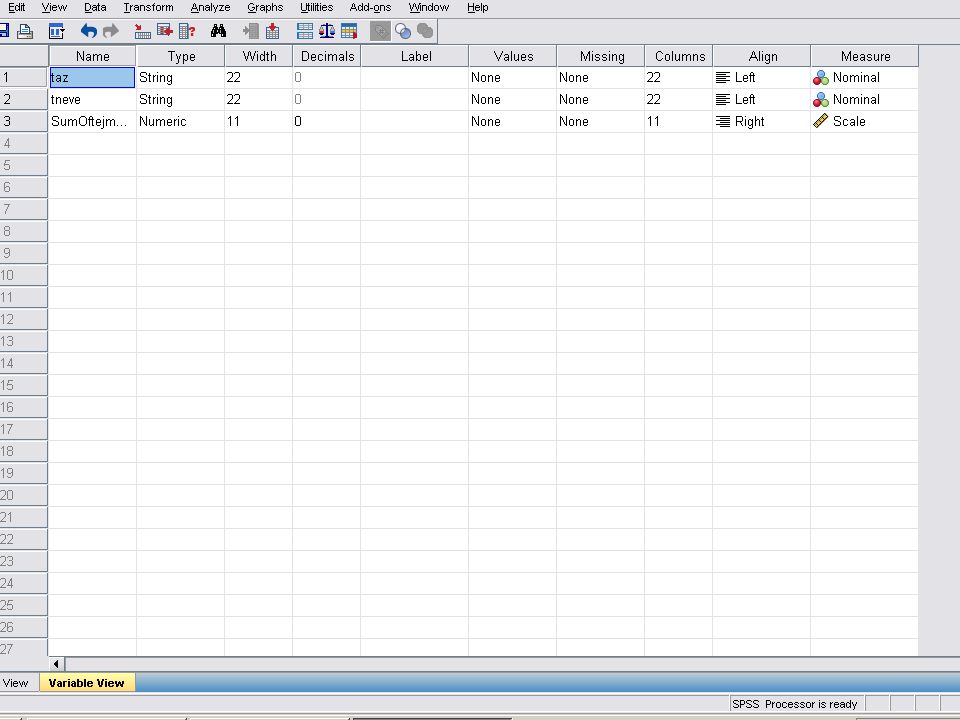
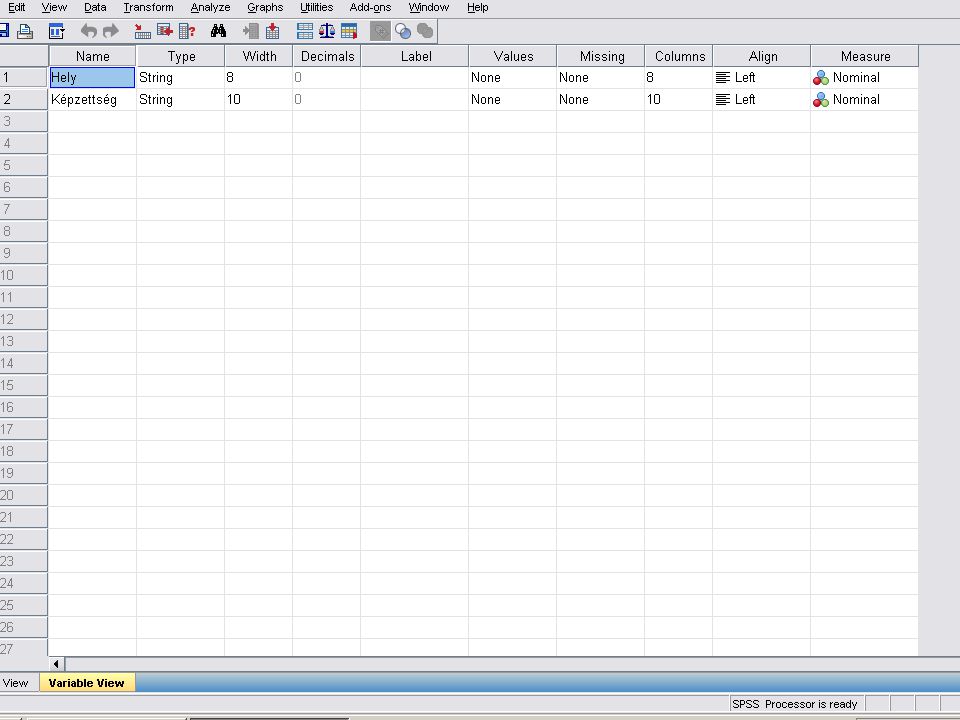
A következő 2 dián látható a felesleges adatok (oszlopok) törlése Variable viewban, majd utána a megmaradó 3 oszlop jellemzői Variable viewban . A negyedik dián látható az adatok törlése Data viewban.
 törlése Variable viewban, majd utána a megmaradó 3 oszlop jellemzői Variable viewban . A negyedik dián látható az adatok törlése Data viewban.")
18
A feladat megoldásának kezdete
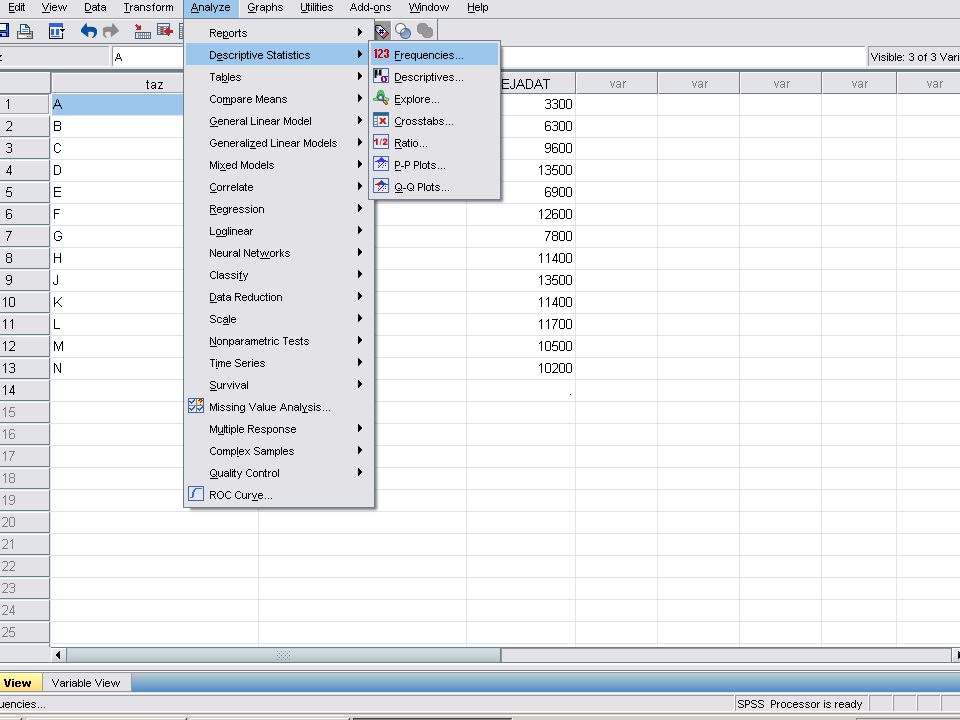
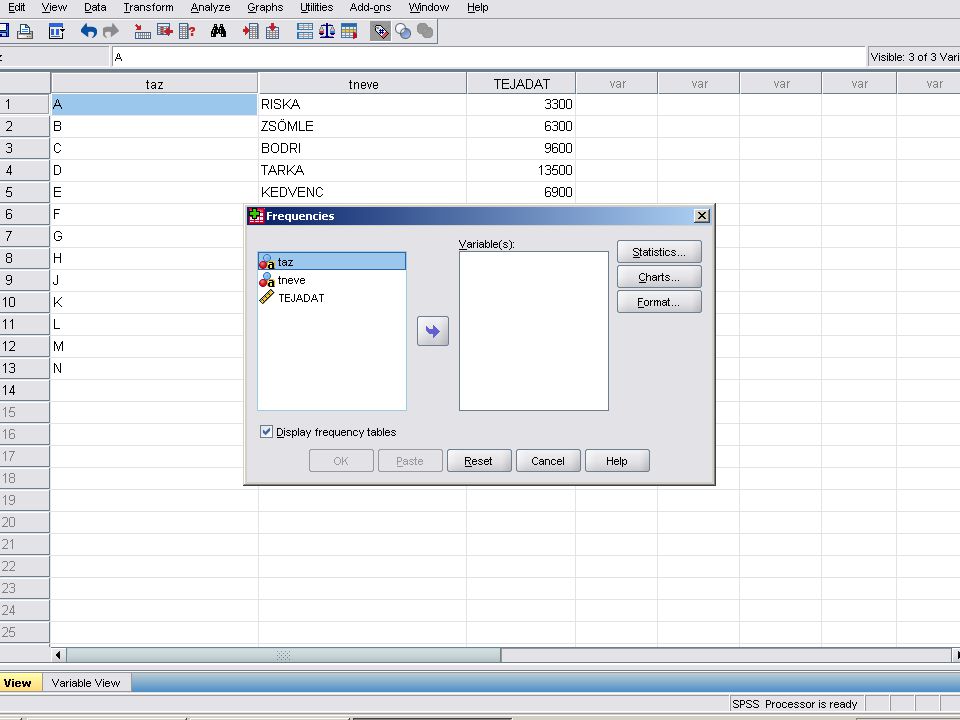
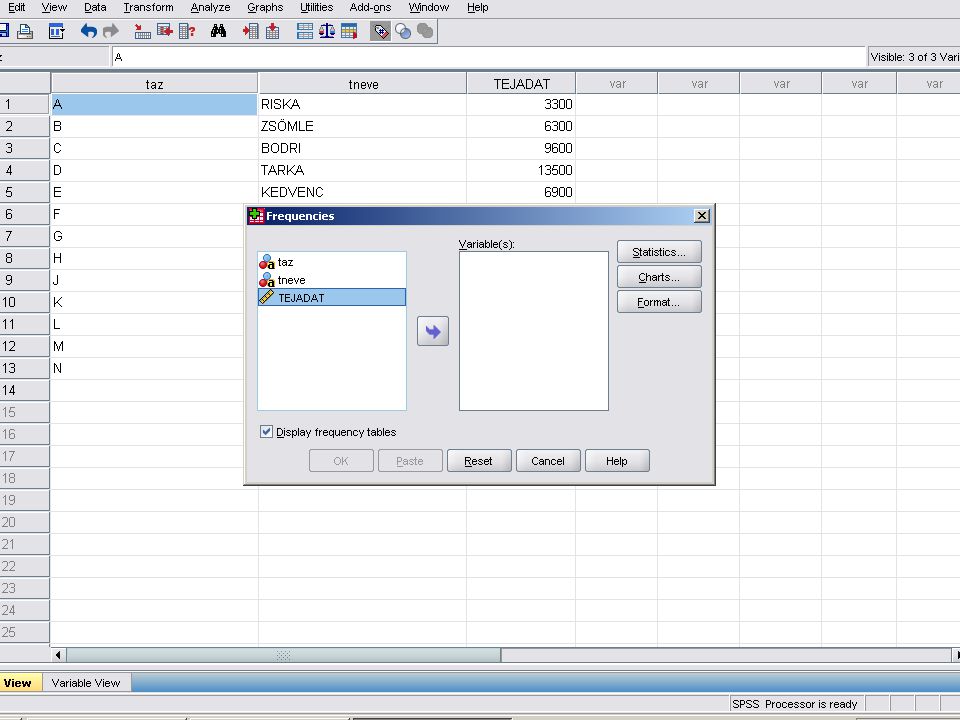
Analyze / Desciptive Statistics /Fequences menüpontban a képen látható panelt kapjuk. A numerikus adatra (TEJADAT) kattintva kijelölődik és mellette lévő nyílra kattintva átvihetjük a Variable(s) ablakba.
 kattintva kijelölődik és mellette lévő nyílra kattintva átvihetjük a Variable(s) ablakba.")
23
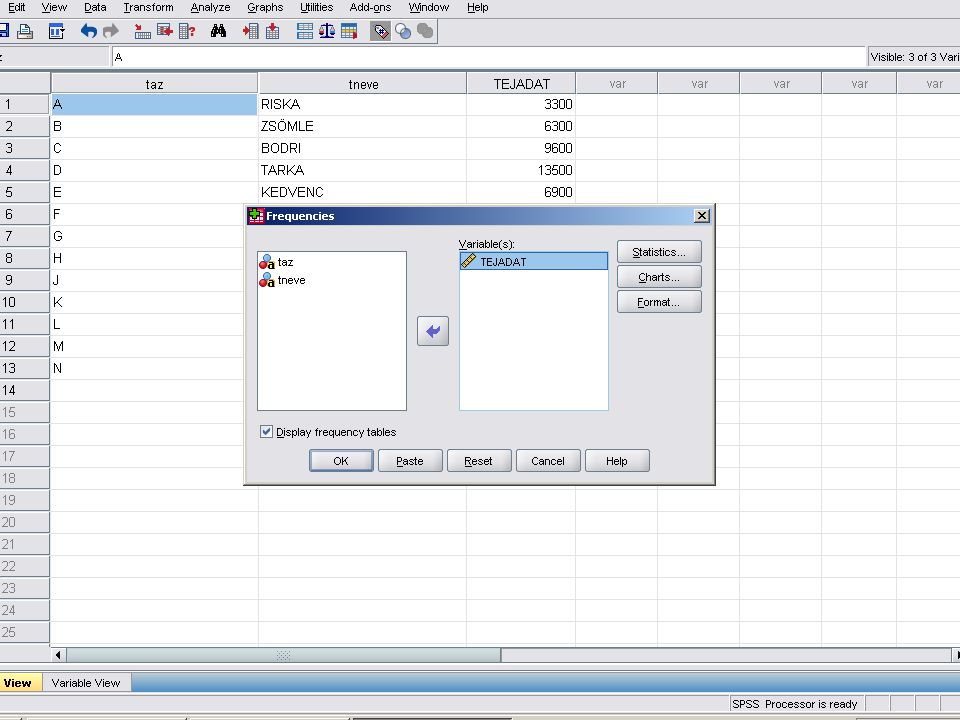
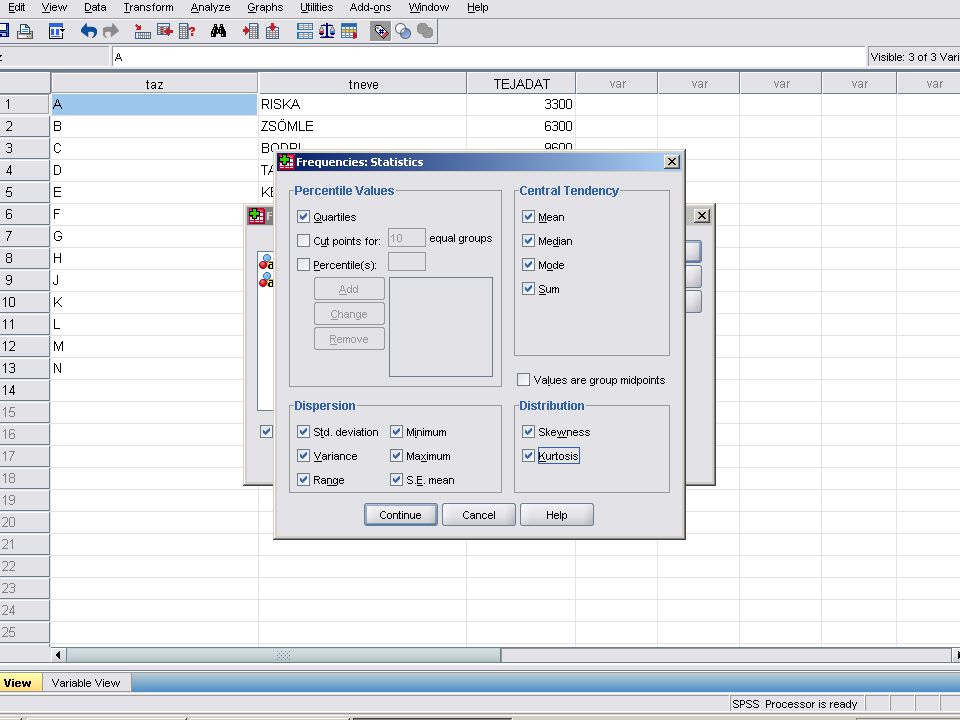
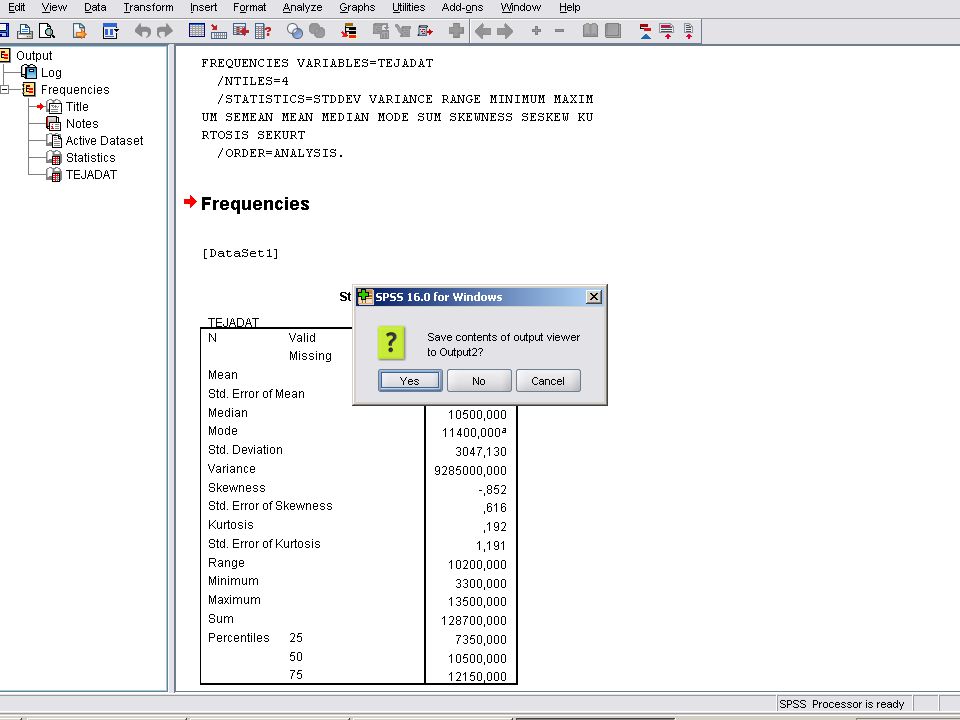
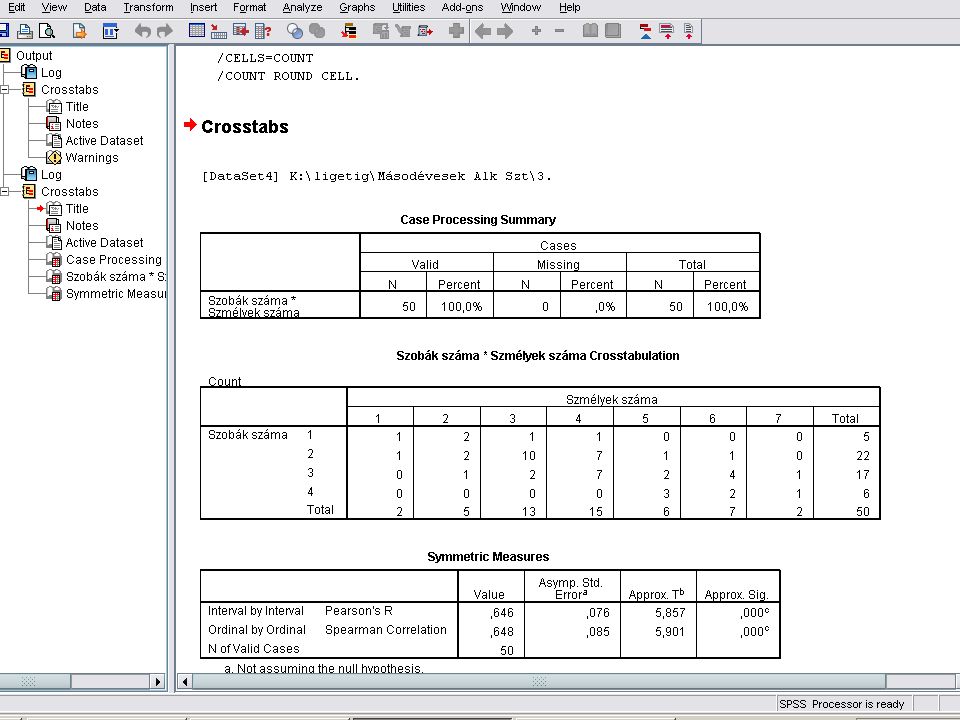
Az eredmény kiszámíttatása
Analyze / Desciptive Statistics / Frequences menüben az adatok átvitele után az előző dián látható képet kapjuk. A Statistcs nyomógombra kattintva beállíthatjuk milyen statisztikai változók értékeit szeretnénk megkapni. A Continue nyomógombra kattinva visszatérhetünk a frequencyhez.

25
Eredmény A frequencyesben a Continue nyomógombra kattintva megkapjuk az eredményt. Az eredmény azonos az EXCELben kiszámolttal. Ezután az outputot menteni kell (kiterjesztése .SPO). Az SPSS filet is célszerű menteni, kiterjesztés .SAV
. Az SPSS filet is célszerű menteni, kiterjesztés .SAV.")
30
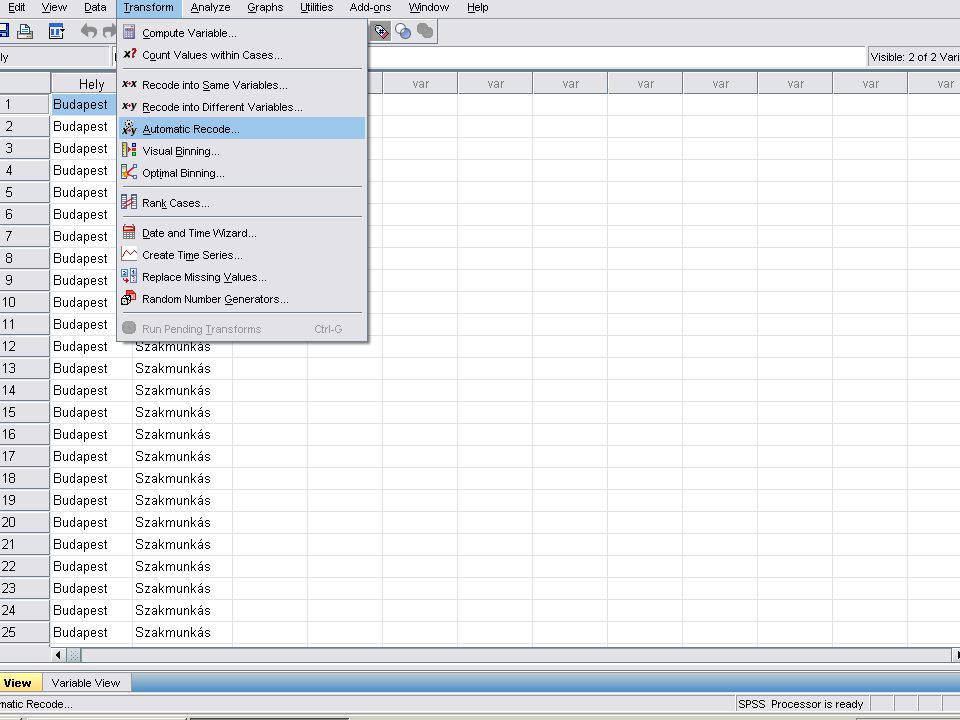
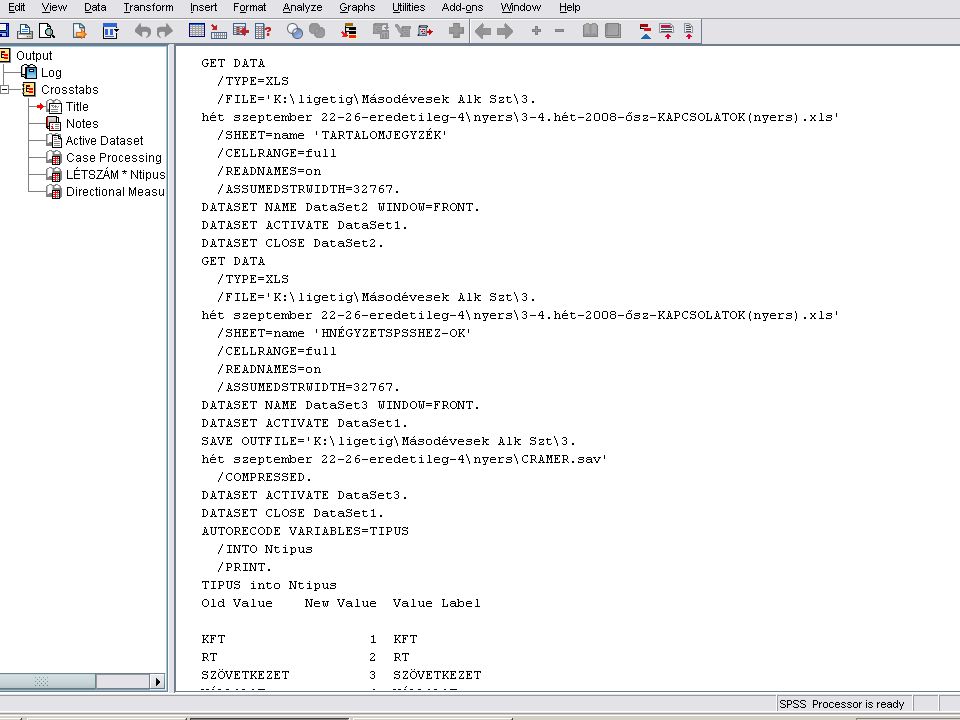
Sztochasztikus kapcsolat (Cramer)
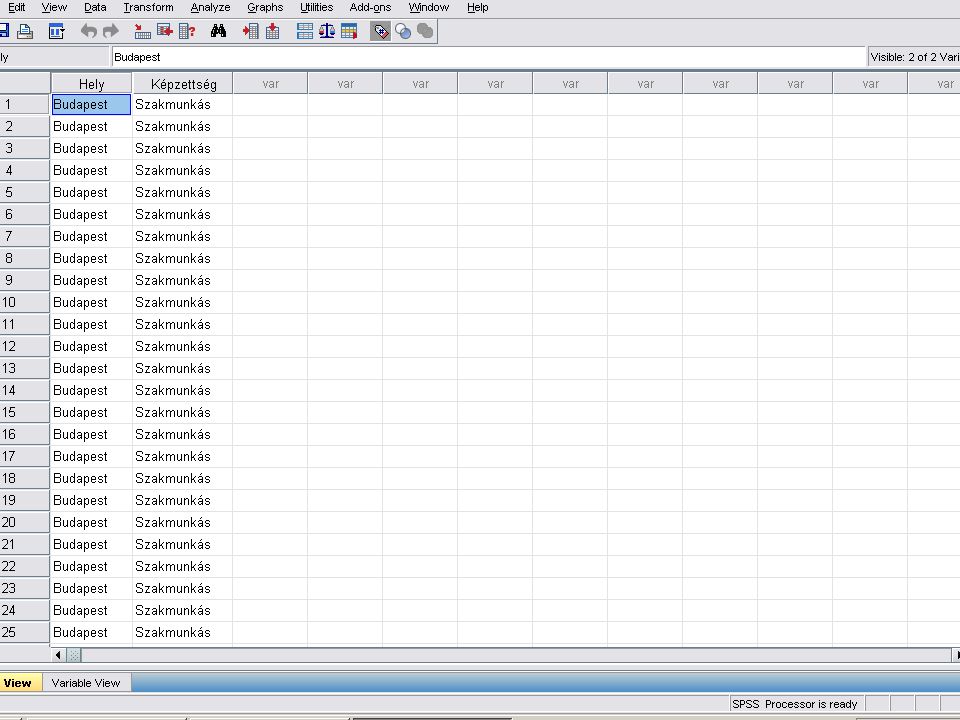
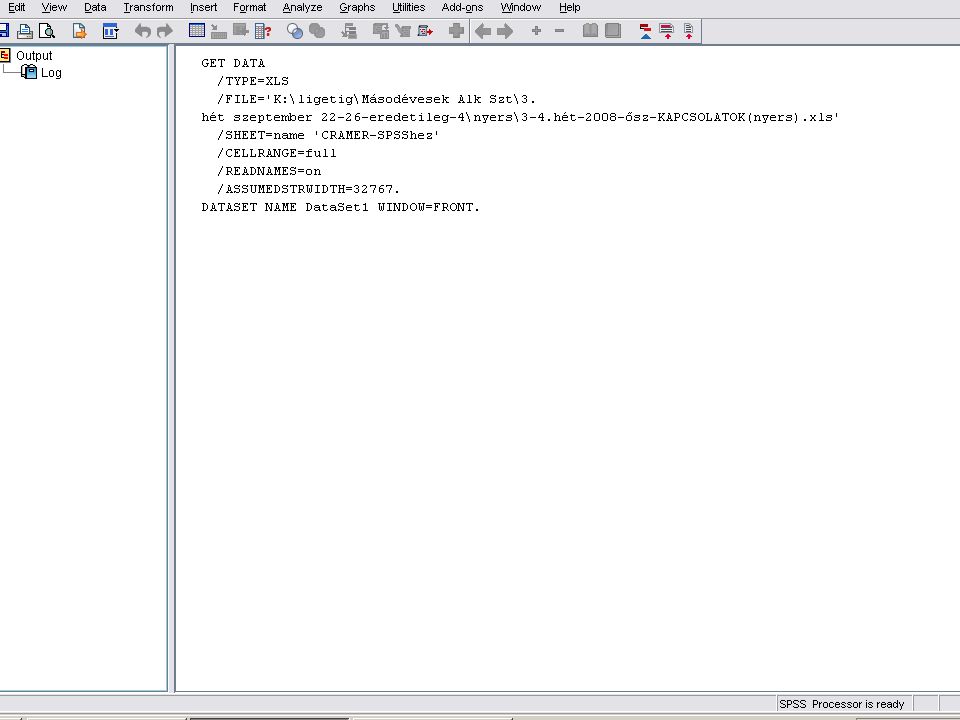
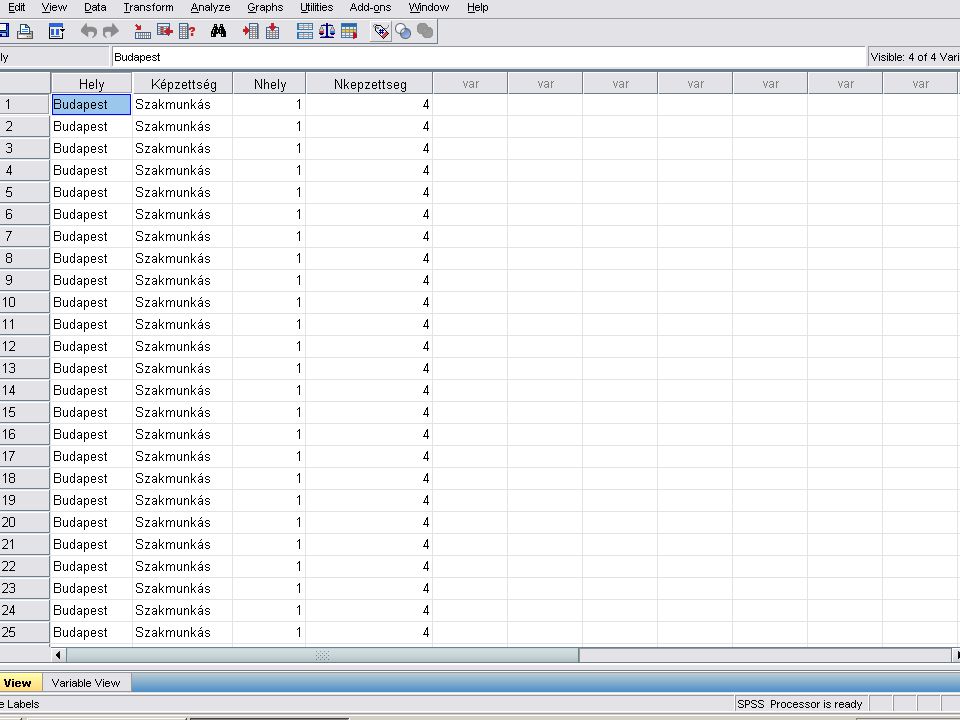
Az EXCELben lévő adatok beolvasása a szokásos módon történik Mivel mindkét adat (Hely, Képzettség) string (azaz szöveg), át kell alakítani őket számmá. Ez a Transform menüben fog történni.
 string (azaz szöveg), át kell alakítani őket számmá. Ez a Transform menüben fog történni.")
36
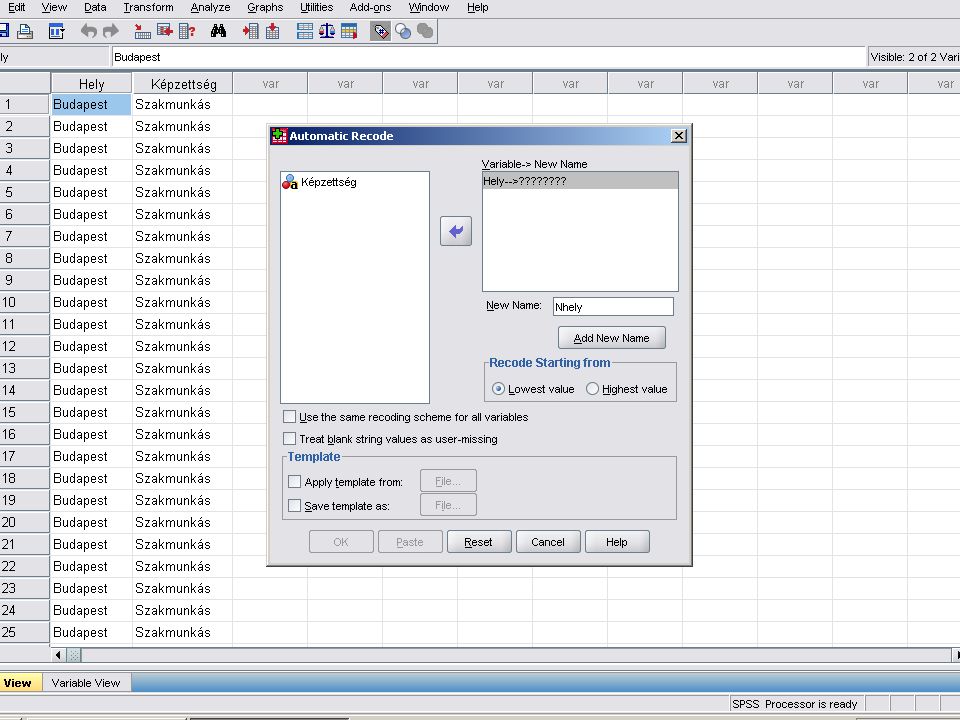
String (szöveg) adatok numerikussá alakítása
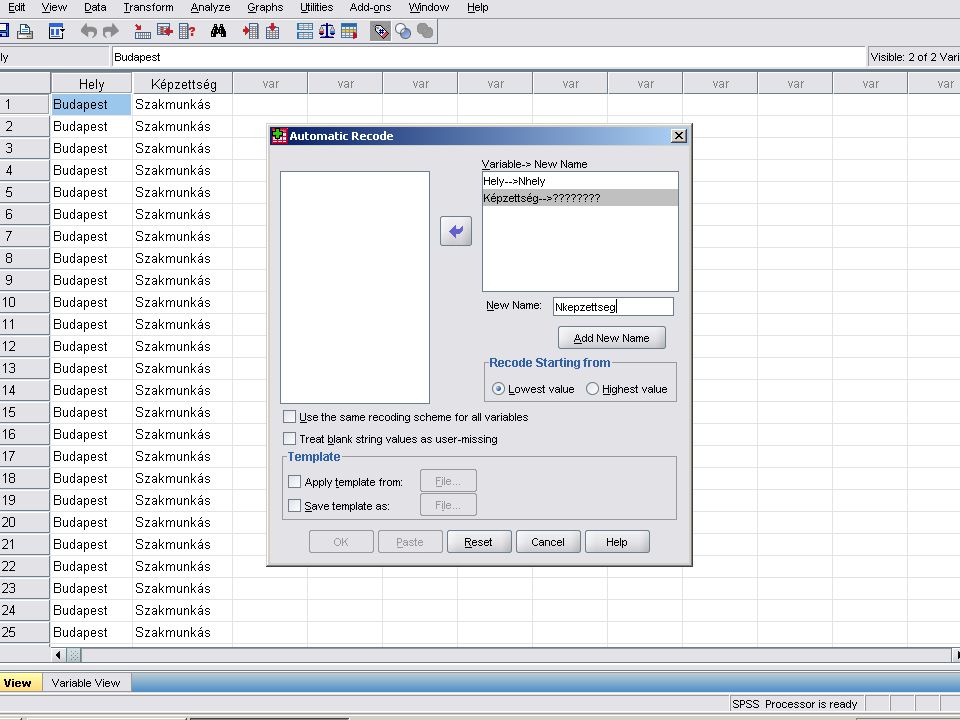
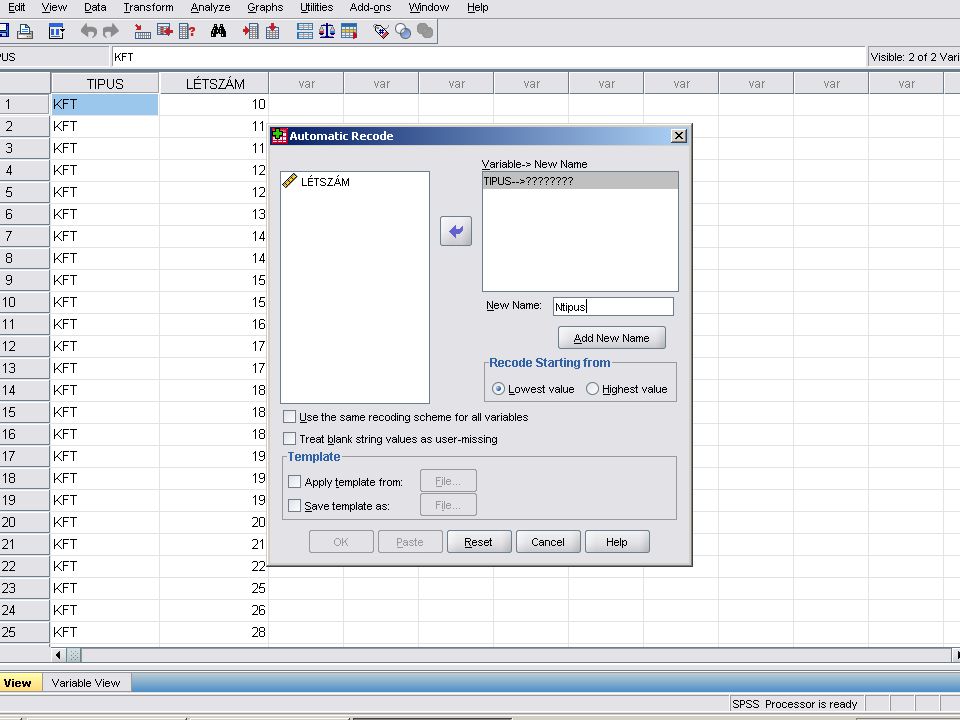
Transform / Automatic recode majd az átalakítandó adatot a variable -> New name … felíratú ablakba vsszük (a nyílra kattintva). Megadjuk az új nevet (ékezet és space nélkül) és az Add New Name nyomógombra kattintunk. Ha kell ismételjük a lépéseket.
. Megadjuk az új nevet (ékezet és space nélkül) és az Add New Name nyomógombra kattintunk. Ha kell ismételjük a lépéseket.")
40
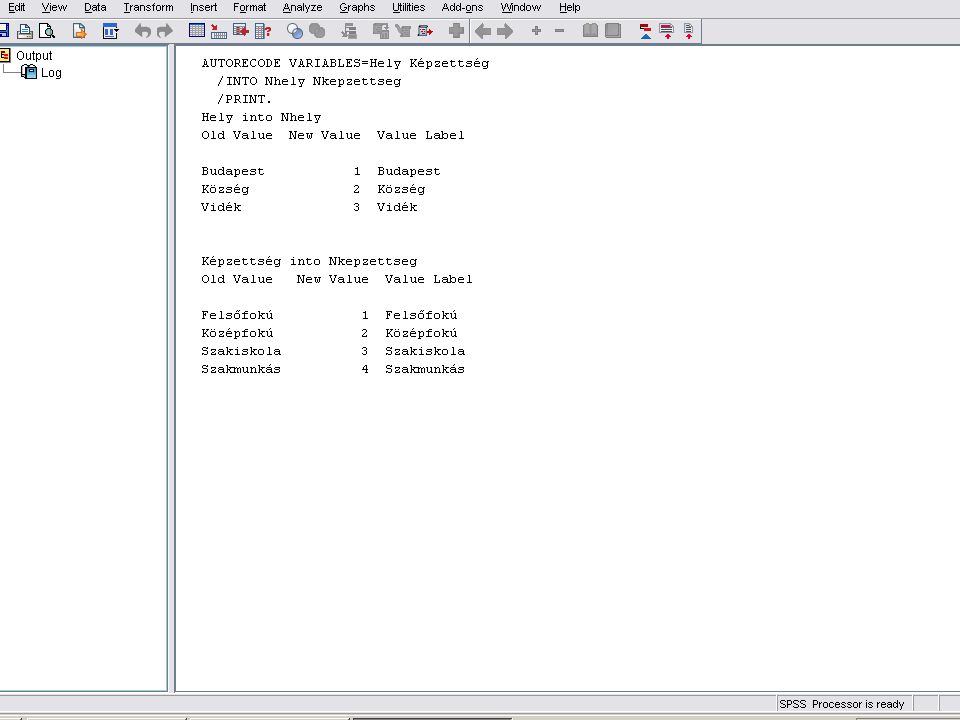
Az átalakítás eredménye
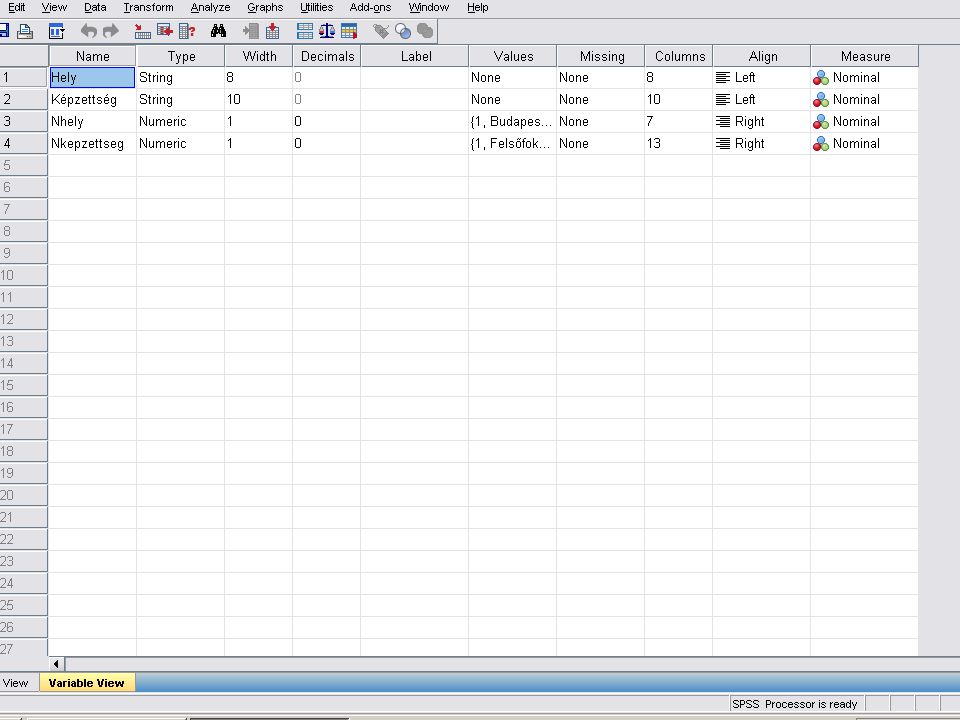
Automatic recode ablakban az Ok - ra kattintva először egy output listát kapunk a konvertálásról (következő dia). A Data Viewban megkapjuk az eredményt, melynek megjelenését a Value label ikonnal szabályozhatjuk (balról a 3.) Lásd még: Variable View Value oszlop, Value Label
. A Data Viewban megkapjuk az eredményt, melynek megjelenését a Value label ikonnal szabályozhatjuk (balról a 3.) Lásd még: Variable View Value oszlop, Value Label.")
45
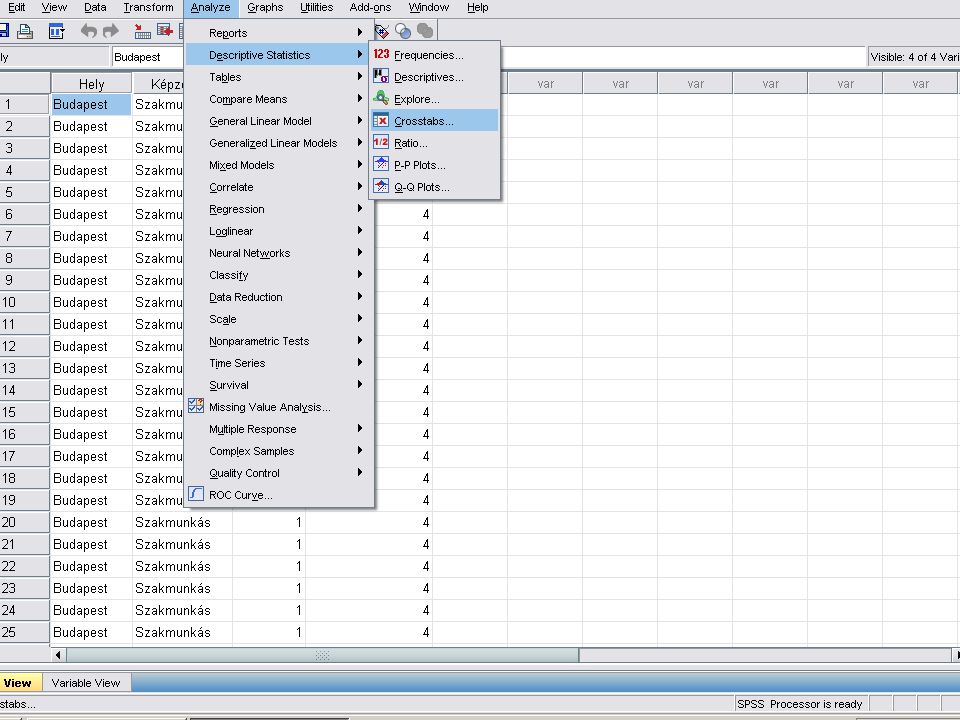
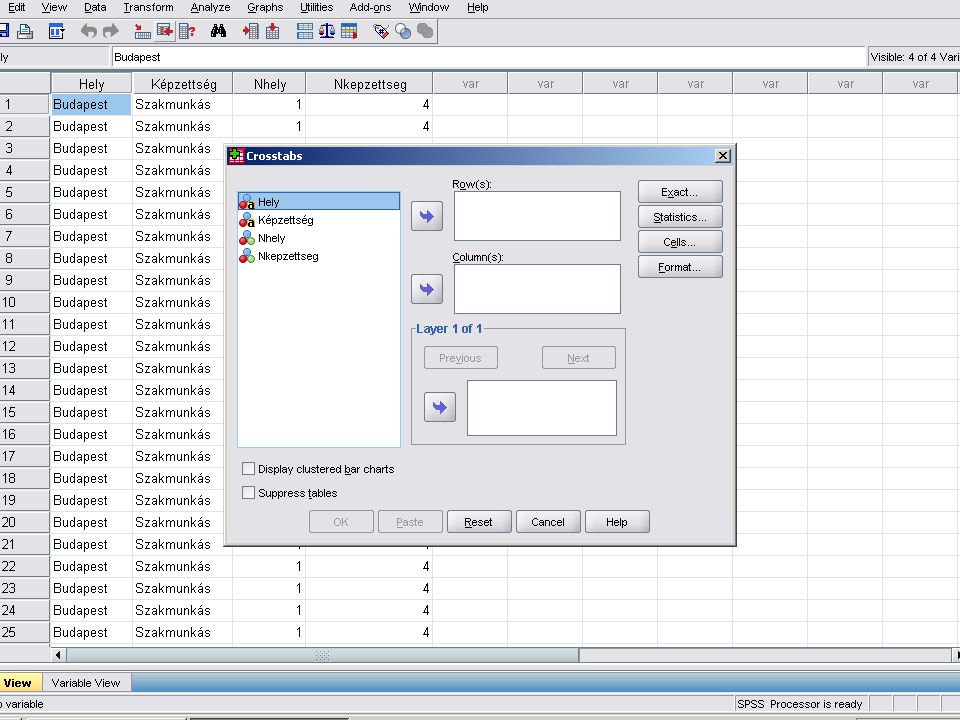
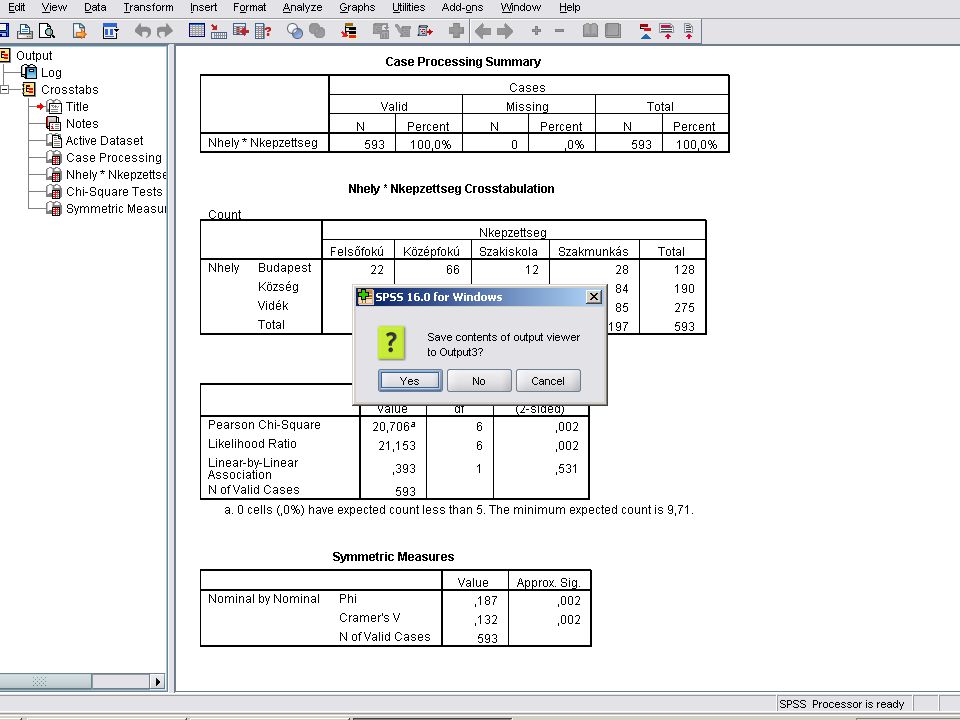
A megoldás Analyze /Despriptive Statistics /Crosstabs
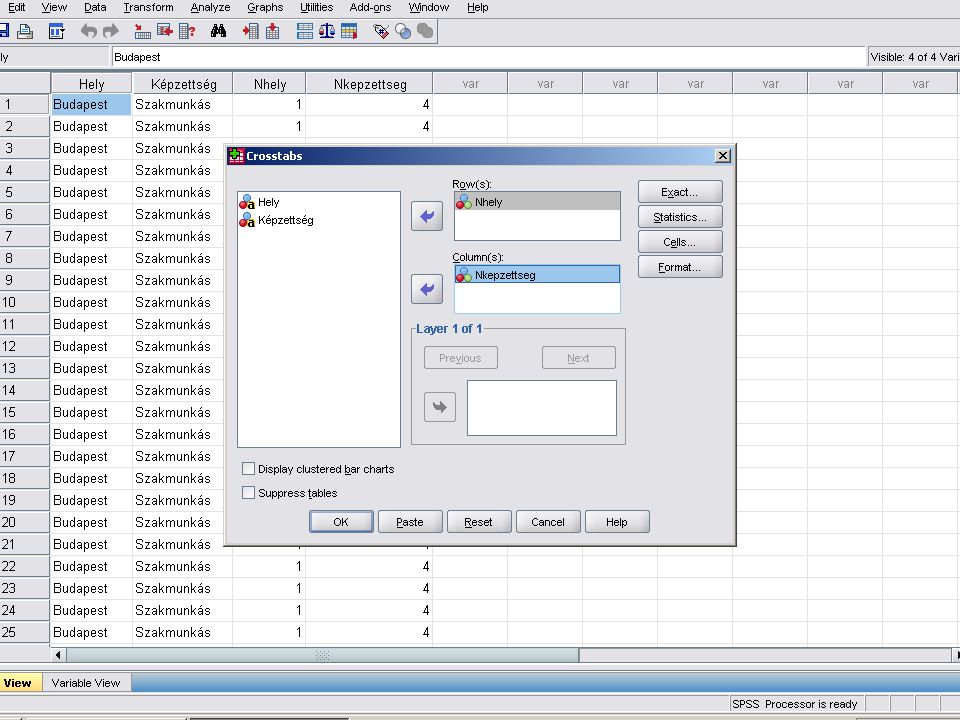
A Crosstabs panelban a szokésos módon átvisszük az Nhely és Nképzettség változókat a Column(s).. és a Row(s) ablakokba majd a Statistics nyomógombra kattinva belejelöljük a Chi-square (Khi négyzet) és Cramer’s V (Cramer) jelölőnégyzeteket.
.. és a Row(s) ablakokba majd a Statistics nyomógombra kattinva belejelöljük a Chi-square (Khi négyzet) és Cramer’s V (Cramer) jelölőnégyzeteket.")
50
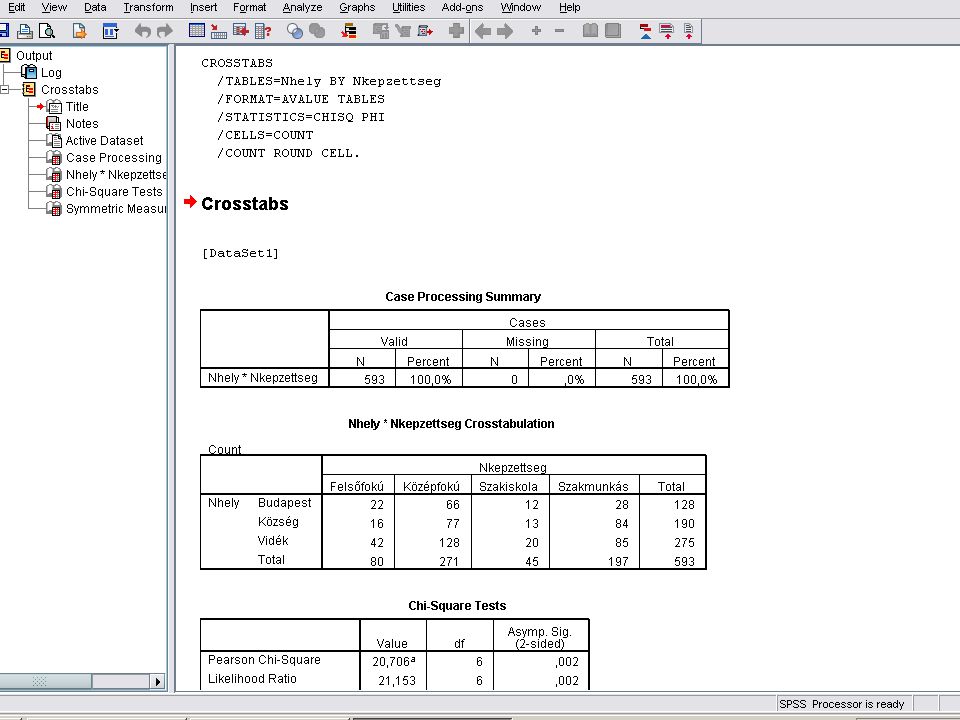
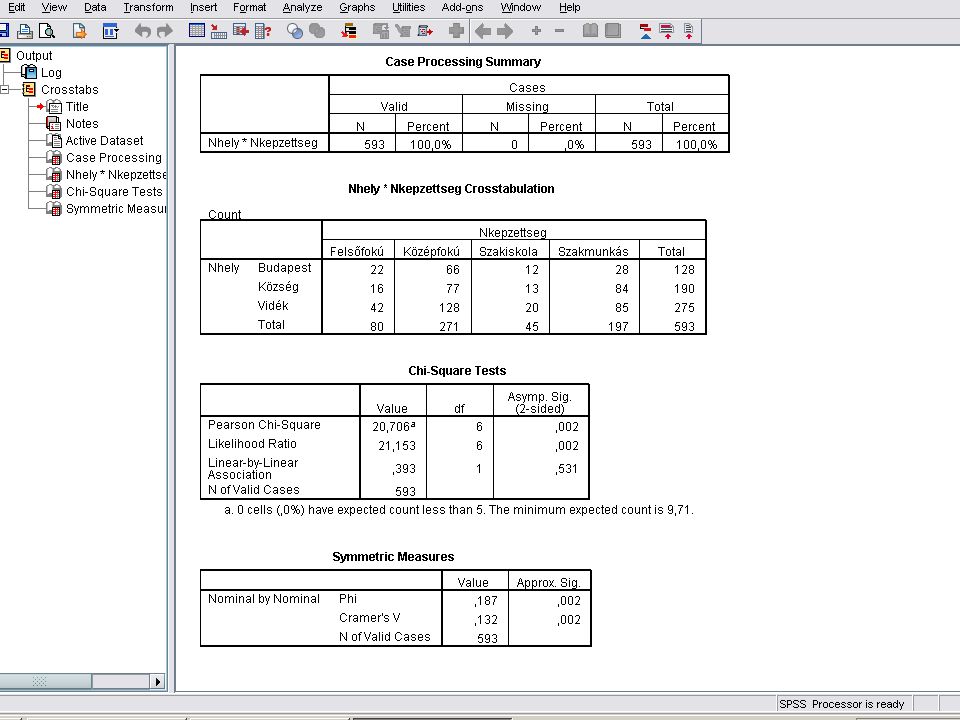
A Cramer eredménye A Continue nyomógombra kattintva kilpünk a Crosstab’s Statistcs majd a Crosstab panelből is A következő dián látható eredmányeket kapjuk Eredménye azonos az EXCELben számolttal Mentések a szokásosak

54
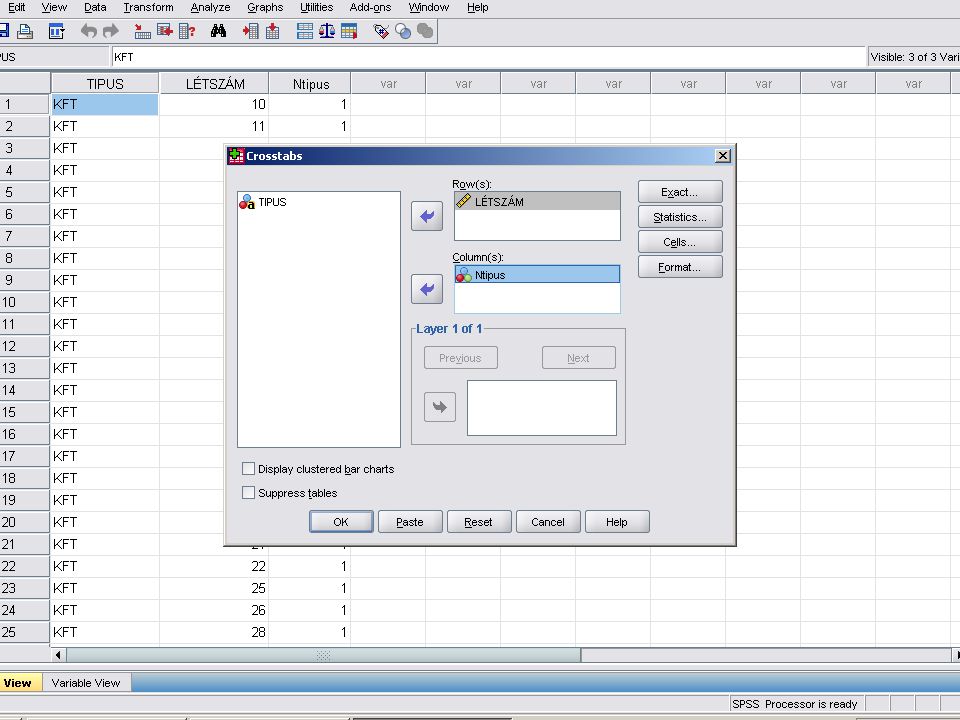
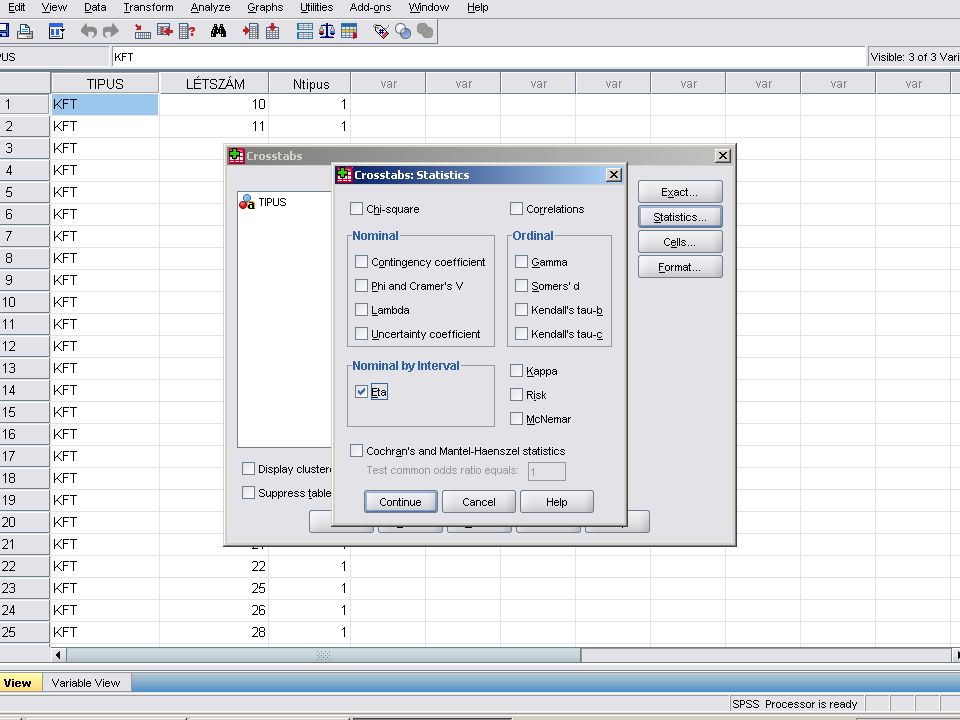
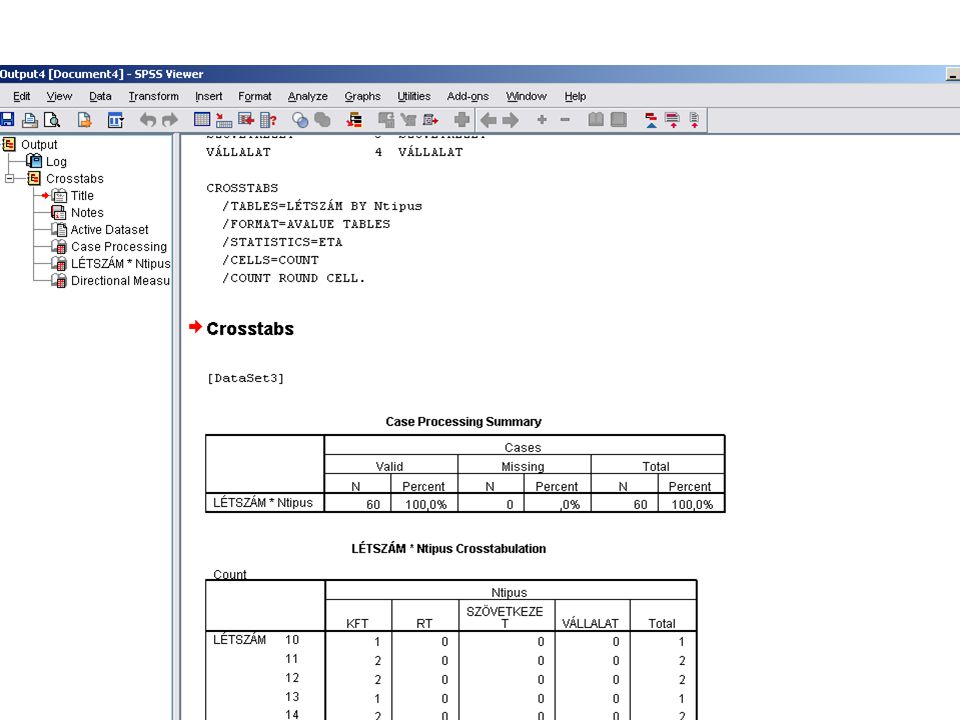
H2 Az adatok beolvasása az eddigiekhez hasonló
A Tipus string típusu ezért itt is át kell alakítani(Transform /Automatic recode) Analyze /Despriptive Statistics /Crosstabs A Crosstabs panelban a szokésos módon átvisszük az Ntipus és Létszám változókat a Column(s).. és a Row(s) ablakokba majd a Statistics nyomógombra kattinva belejelöljük az Eta jelölőnégyzetet.
 Analyze /Despriptive Statistics /Crosstabs. A Crosstabs panelban a szokésos módon átvisszük az Ntipus és Létszám változókat a Column(s).. és a Row(s) ablakokba majd a Statistics nyomógombra kattinva belejelöljük az Eta jelölőnégyzetet.")
62
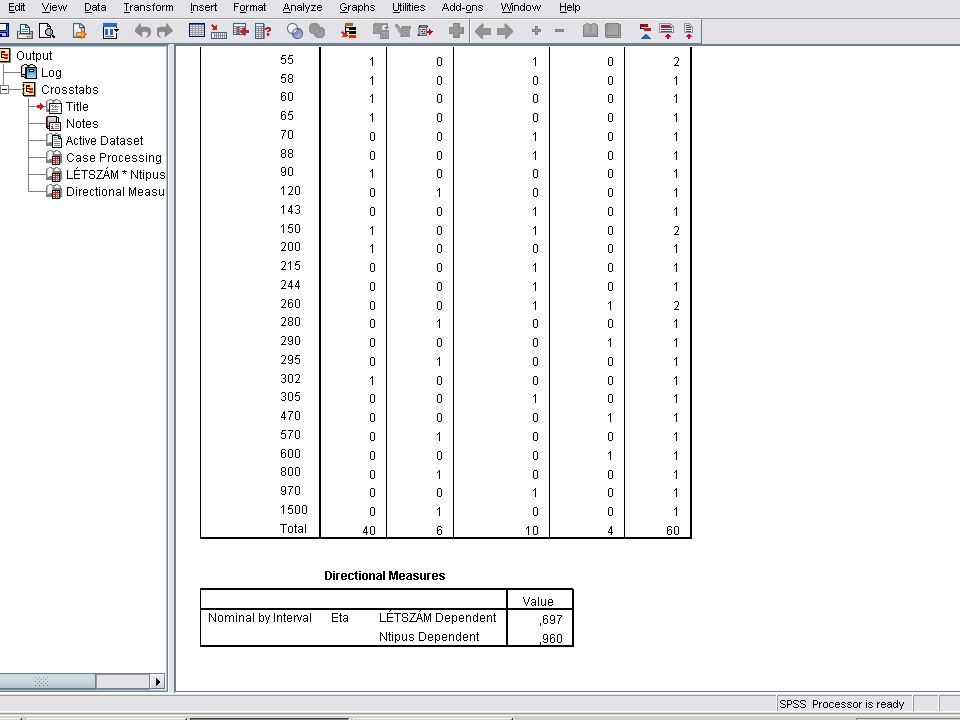
A H2 eredménye A Continue nyomógombra kattintva kilpünk a Crosstab’s Statistcs majd a Crosstab panelből is A következő dián látható eredmányeket kapjuk Eredménye azonos az EXCELben számolttal Mentések a szokásosak

66
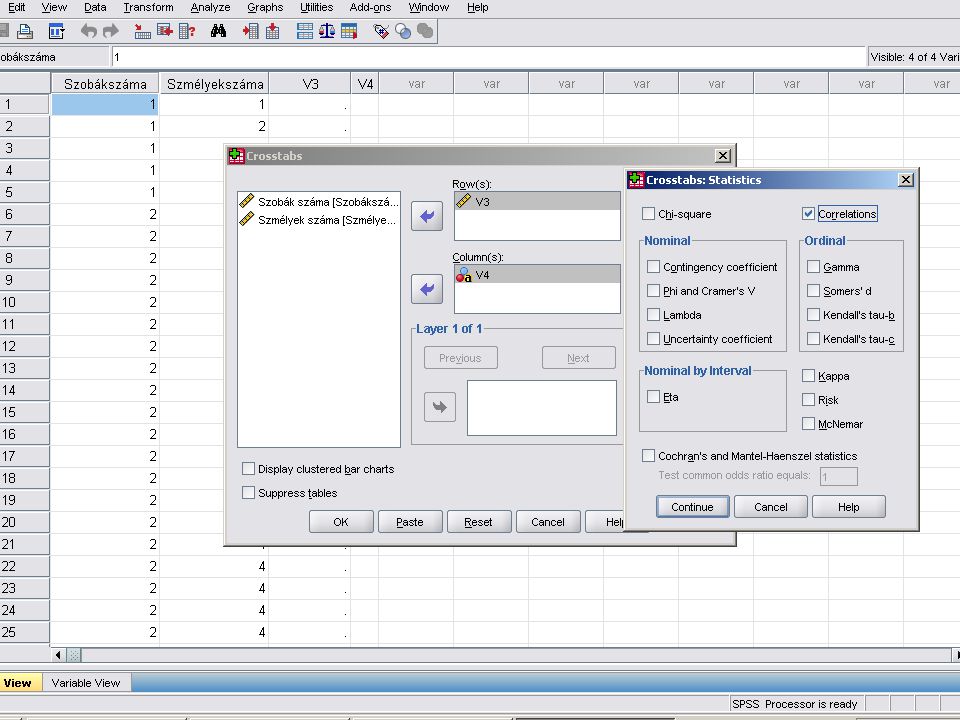
Korreláció (lakók szobák)
A beolvasás a szokásos Itt mindkét változó numerikus ezért konvertálni sem kell. A megoldás és az eredmény a következő diákon látható Analyze / Despriptive Statistics / Crosstabs / Correlations

69
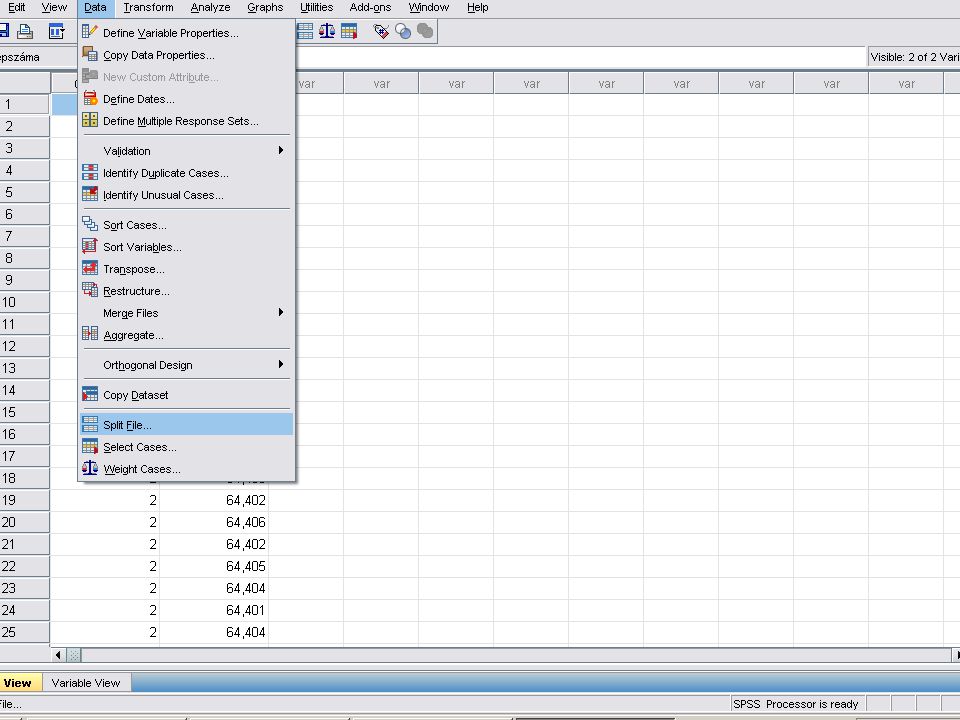
Egymintás t próba A beolvasás az EXCELből szokásosan történik
Data / Split File majd a Group Based on feliratú ablakba bevisszük a Gép száma változót a nyíllal, majd az OK nyomógombra kattintva kilépünk a Split Fileból

73
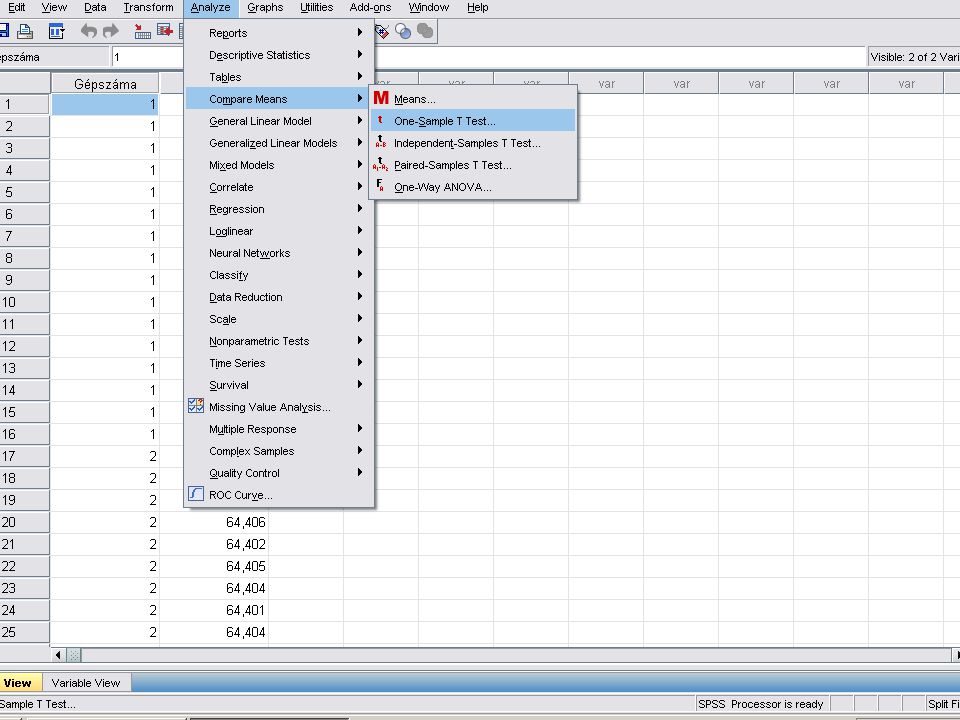
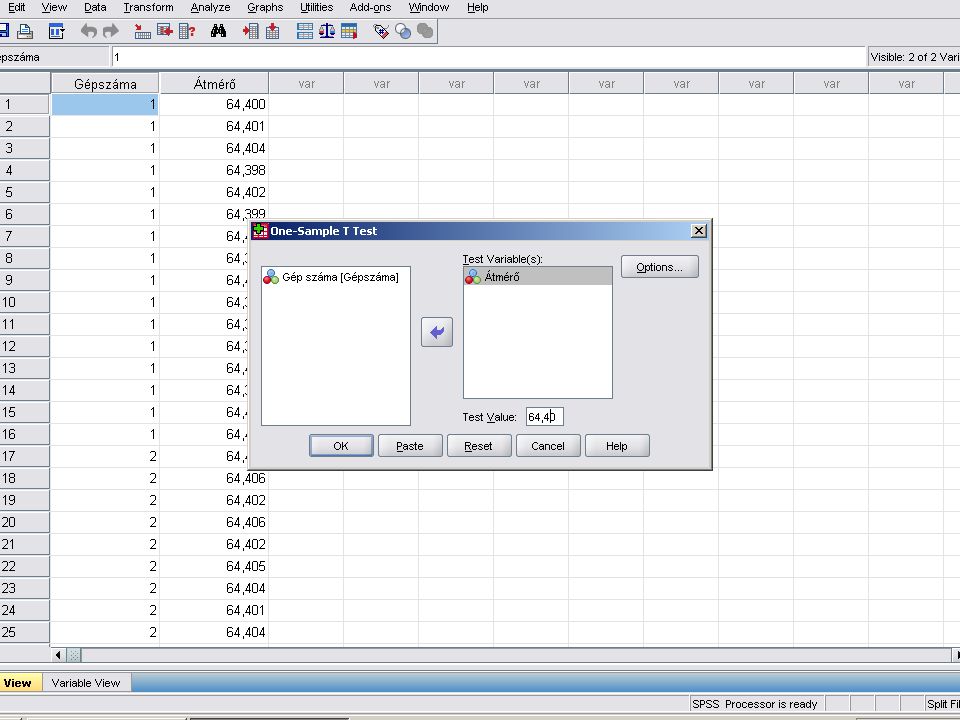
Egymintás t próba Analyze / Compare Means / One sample T test
A test variable(s) ablakba visszük az Átmérő nevű változót és a Test value mezőbe beírjuk a 64,4 értékét. A Continue nyomógombra kattintva megkapjuk a megoldást
 ablakba visszük az Átmérő nevű változót és a Test value mezőbe beírjuk a 64,4 értékét. A Continue nyomógombra kattintva megkapjuk a megoldást.")
77
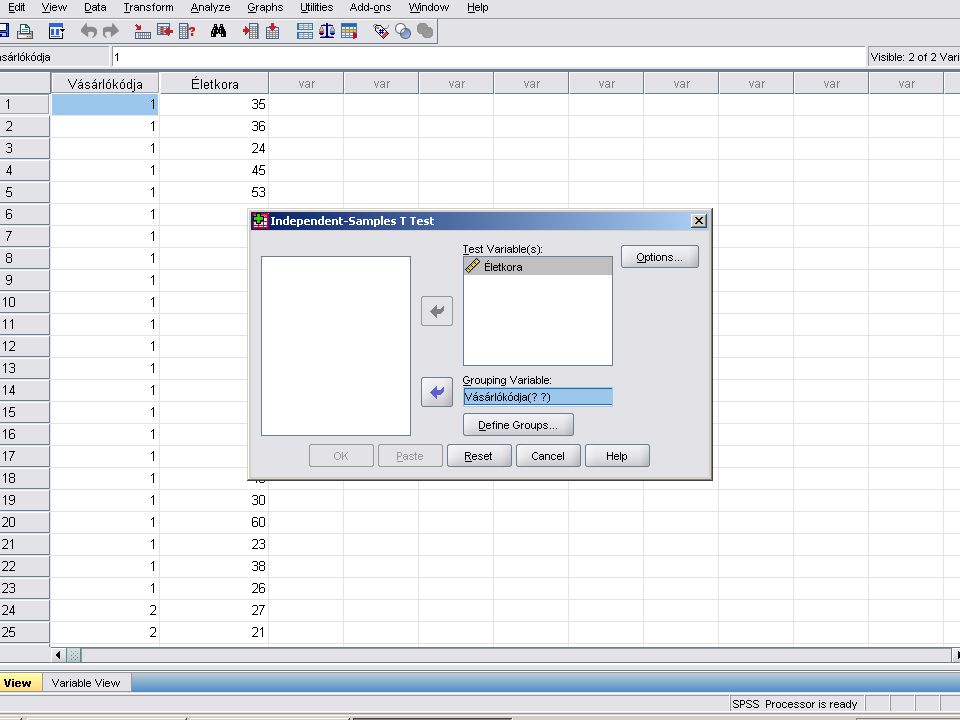
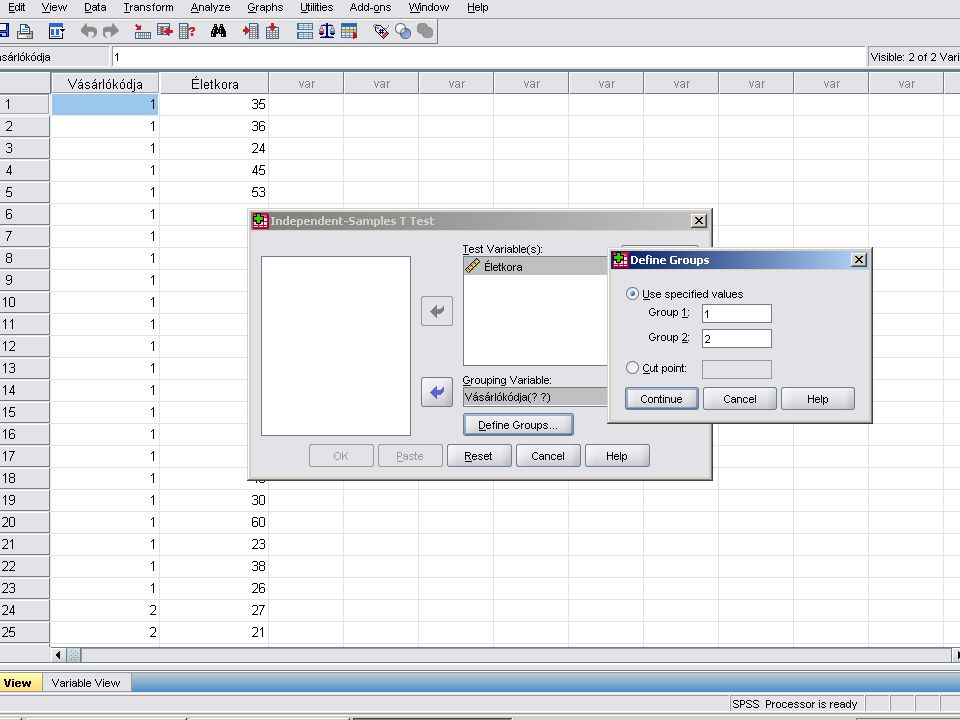
Kétmintás t próba Analyze / Compare Means / Independent Samples T test
Test variable(s): Életkora Grouping variables: Vásárló kódja A Define groups nyomógombra kattintva a megjelenő ablakba beírjuk: Group1: 1 Group2: 2
: Életkora. Grouping variables: Vásárló kódja. A Define groups nyomógombra kattintva a megjelenő ablakba beírjuk: Group1: 1. Group2: 2.")
78
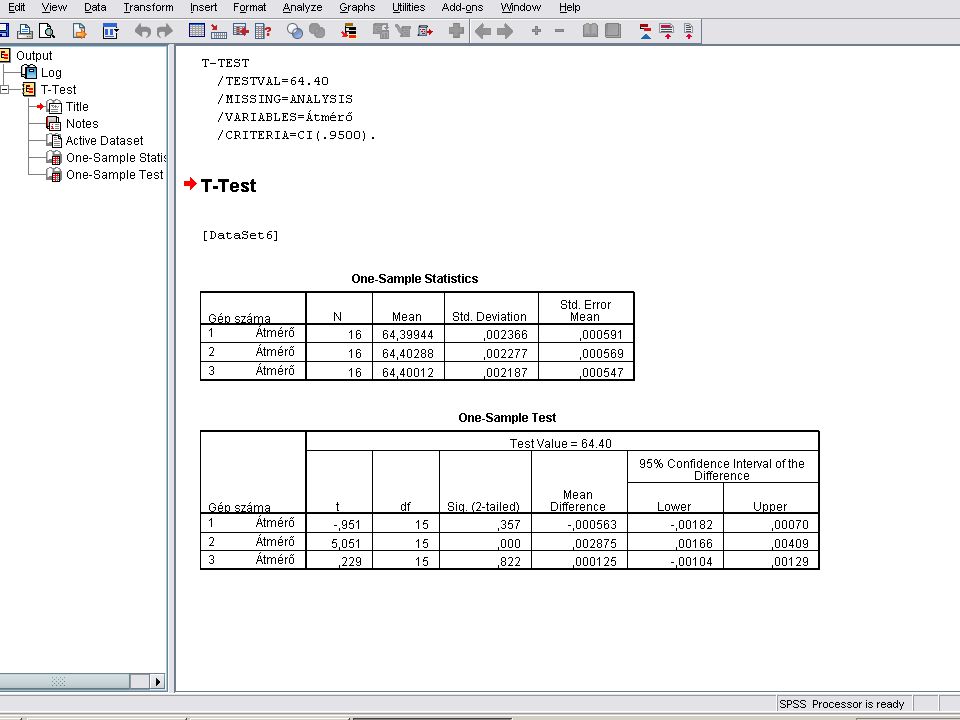
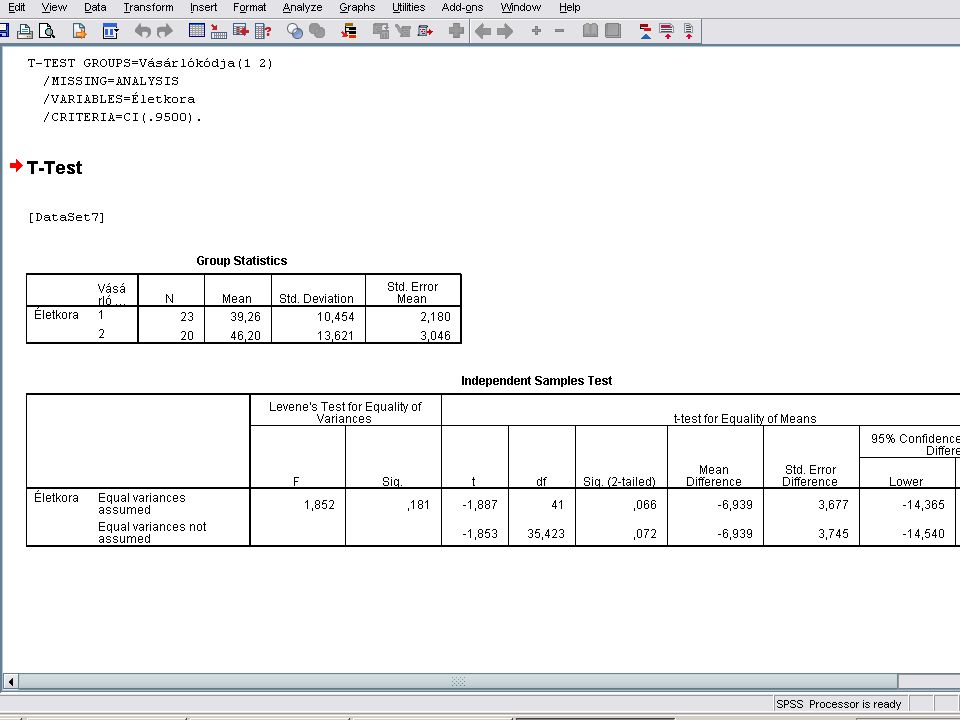
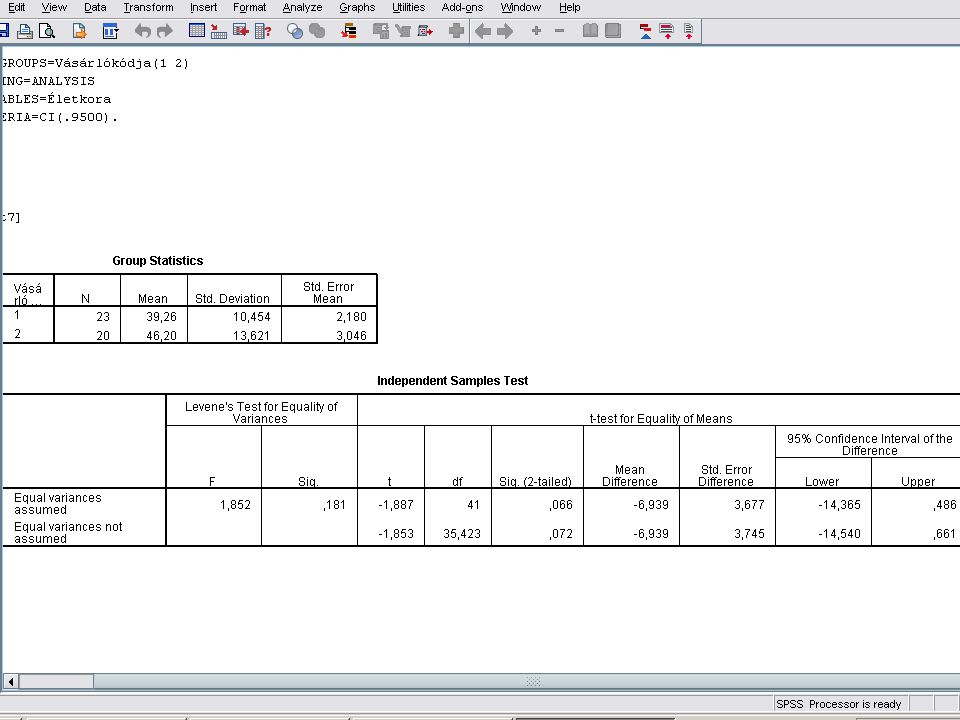
A Continue nyomógombra kattintunk majd az Option nyomógombra.
Itt a Confidencia Interval (konfidencia intervallum) értékét 95% - ra állítjuk be, és Contnuet nyomva majd Ok-t nyomva megkapjuk az eredményt.
 értékét 95% - ra állítjuk be, és Contnuet nyomva majd Ok-t nyomva megkapjuk az eredményt.")
86
VARIANCIA Az ACCESS-ben előkészítettük az adatokat az SPSSHEZ:
Tipusnév, rendszám fogy100 adatmezőkkel és az összes (90) adattal. Ezután vágólapra másoljuk az adatokat (CTRL+C) Behívjuk az SPSS-t (ha eddig nem tettük) Az SPSS-ben a vágólapról bemásoljuk az adatokat (CTRLV)
 adattal. Ezután vágólapra másoljuk az adatokat (CTRL+C) Behívjuk az SPSS-t (ha eddig nem tettük) Az SPSS-ben a vágólapról bemásoljuk az adatokat (CTRLV)")
87
A következőt kapjuk

88
A típust és fogyasztás átneveztük

89
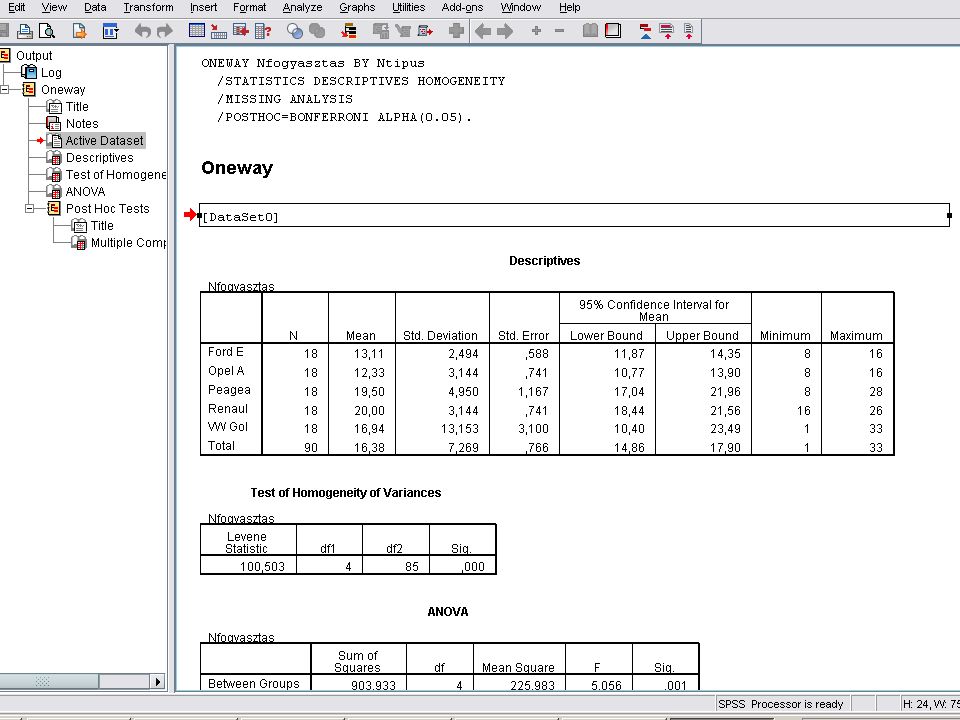
Mivel a változók szöveg (string) típusuak, a szokásos eljárással (transform / automatic recode) átkódoltuk Az elemzés ? Analyze /Compare means /One way ANOVA Dependent: Nfogyasztas, Factor: Ntipus Options nyomógomb:Desriptive, Means Plot és Homogenity of variance test jelölőnégyzeteket bejelöljük

90
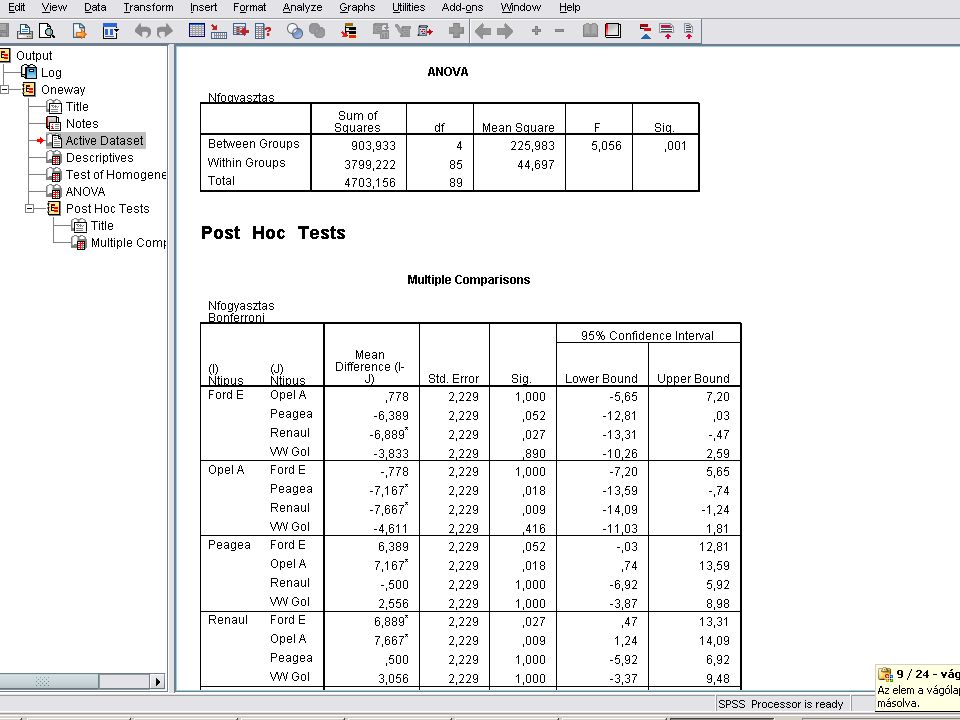
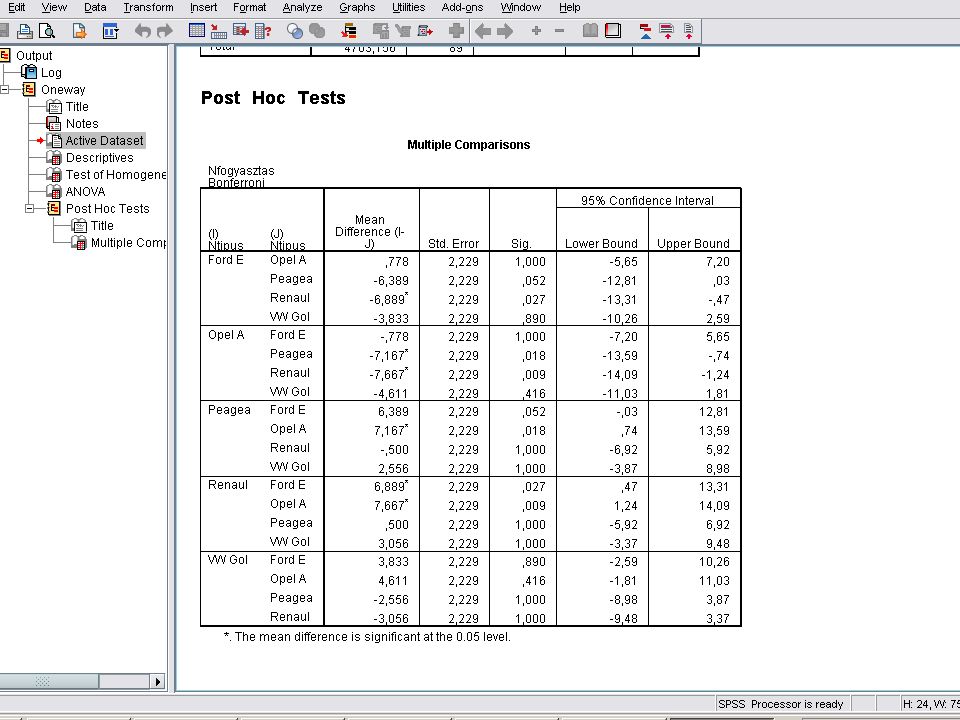
Post hoc test nyomógombra kattintva: a Bonferroni jelölőnégyzetet kattintsuk be
A Continuera majd az OK-ra kattintva megkapjuk az eredményt. (Értelmezést lásd a jegyzetben és az órán) (Eredmény a következő dián)
 (Eredmény a következő dián)")
95
Graph / Lagacy Dialogs / Boxplot /Simple
Summaries for groups of cases rádiógomb bejelölése majd Define mnyomógomb Varaible Nfogyasztas Category axis: Ntipus

96
Minimum Felső kvartilis Medián Alsó kvartilis Minimum

97
A következő diagramot a Graph / Lagacy Dialogs / ErrorBar menüpontból hívhatjuk be:
Summaries for groups of cases rádiógomb bejelölése majd Define mnyomógomb Varaible Nfogyasztas Category axis: Ntipus Barrepresent: kiválasztjuk a Stabdard error of mens-t és a Multiplier 2

98
Standard hiba Átlag

Hasonló előadás