Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
IBM SPSS Statistics Regressziós elemzések Informatikai Tudományok Doktori Iskola

2
Mintaelemzések Adott gépkocsik egy halmazának adatrendszere: Összesen 406 gépkocsi műszaki és egyéb paramétereit tartalmazza. A gépjárműveket USA- ban, Európában és Japánban gyártották a 70-es, 80-as években. A gépkocsik fogyasztásának, súlyának, gyorsulásának, lökettérfogatának, teljesítményének és hengerszámának adatait foglalja magában.

3
mpghány mérföldet tesz meg egy gallonnal? enginelökettérfogat (köbinch-ben kifejezve) horselóerő weighta gépjármű súlya (fontban) accelhány másodperc alatt gyorsul fel 60 mérföld/óra sebességre? yeara gyártás éve: 19.. origina származás helye cylinderhengerek száma Az adatmátrix változói
 horselóerő weighta gépjármű súlya (fontban) accelhány másodperc alatt gyorsul fel 60 mérföld/óra sebességre. yeara gyártás éve: 19.. origina származás helye cylinderhengerek száma Az adatmátrix változói.")
4
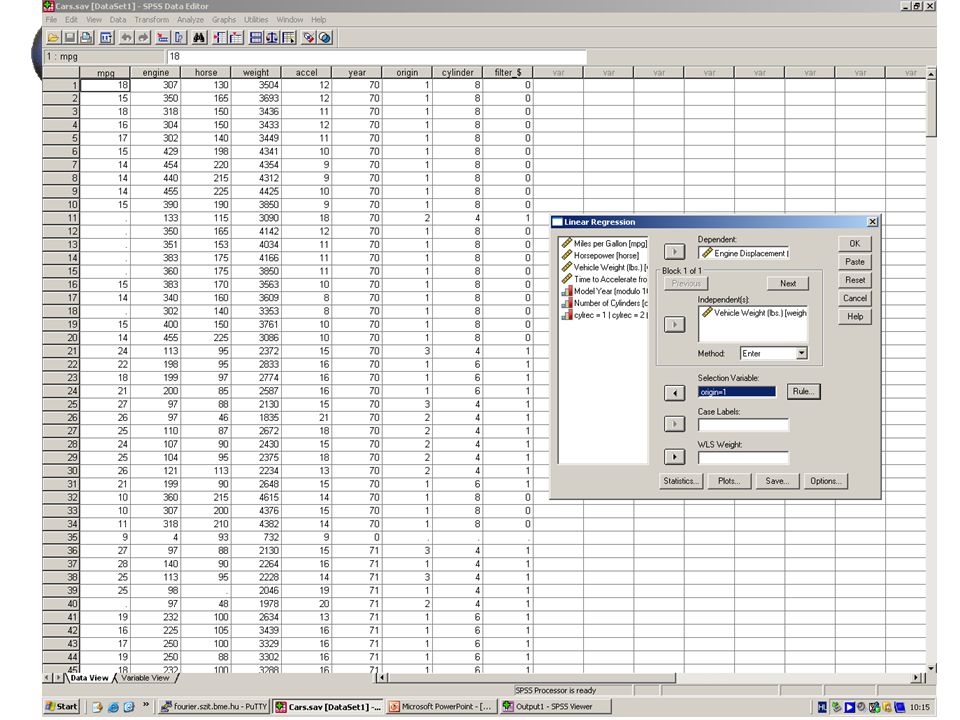
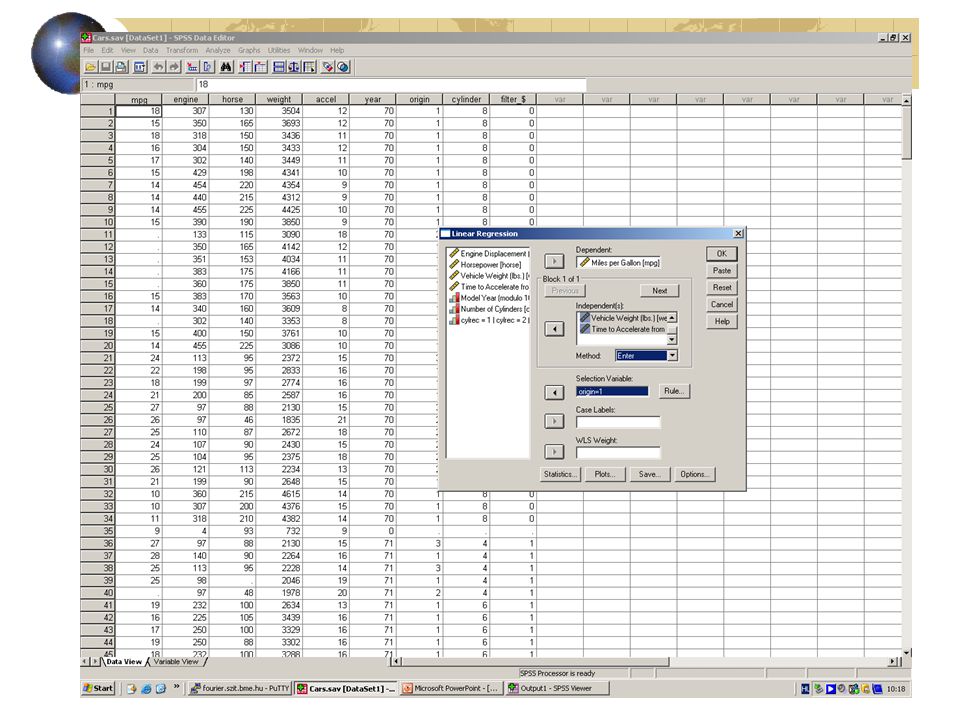
Keressünk kapcsolatokat a változók között! Lineáris kapcsolatot súly és a lökettérfogat között Többváltozós lineáris kapcsolatot a fogyasztás és az összes többi változó között Nemlineáris kapcsolatot a lóerő és a fogyasztás között

5
Regressziós kapcsolat keresése változók között

6
Szóródási grafikonok

7
Kapcsolat a súly és lökettérfogat között

8
Gyártóhelyek szerint más-más lineáris kapcsolat van!

10
A kétváltozós regresszió eredményei Amerika

11
A kétváltozós regresszió eredményei Európa

12
A kétváltozós regresszió eredményei Japán

14
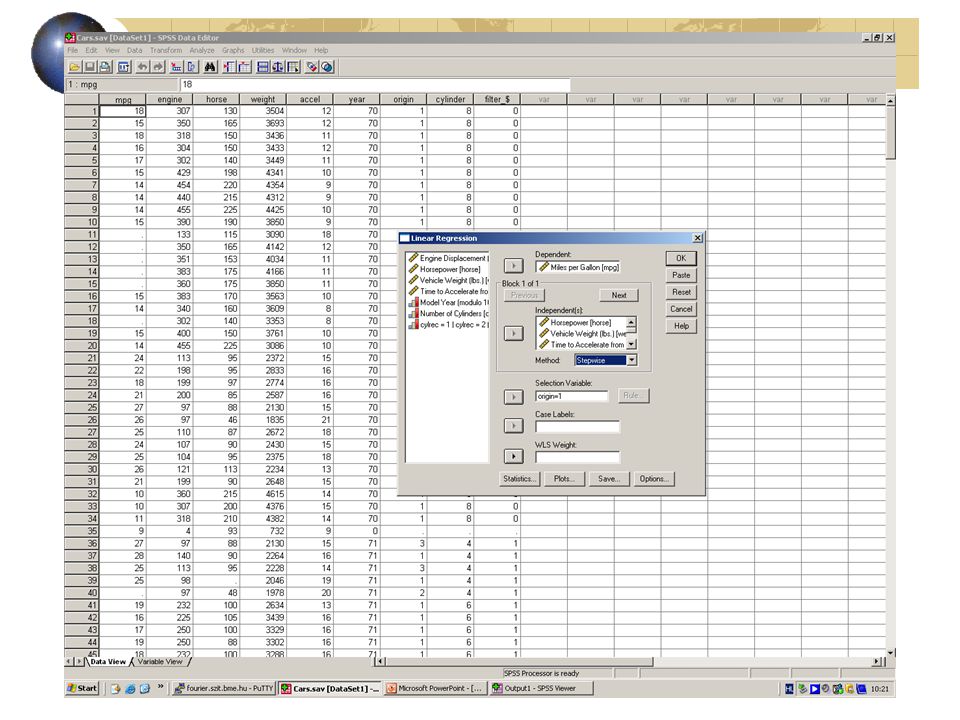
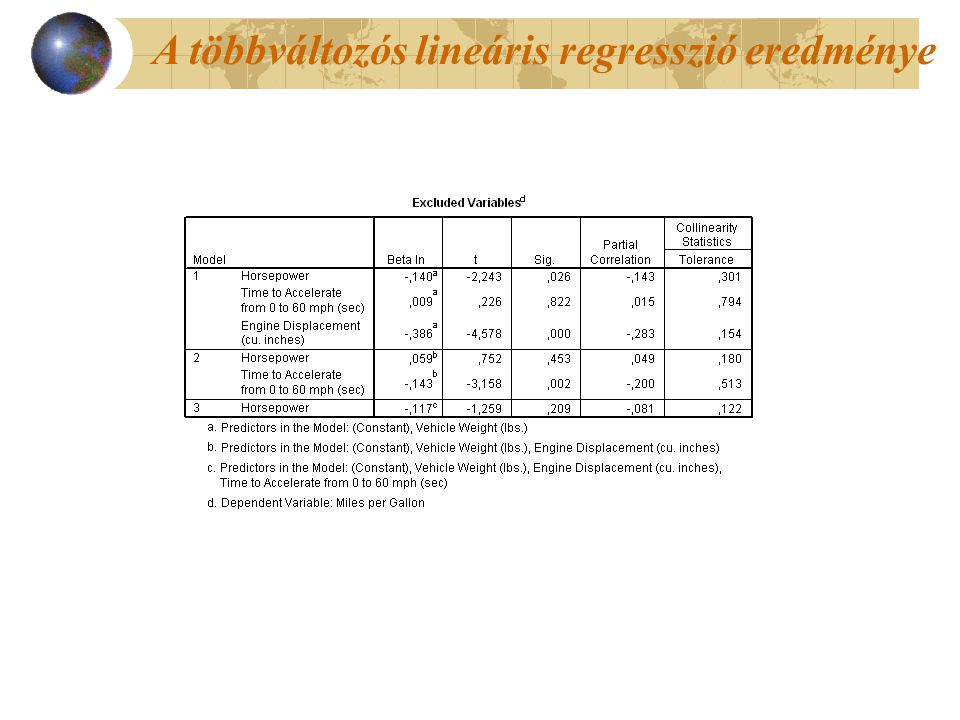
A többváltozós lineáris regresszió eredménye

17
STEPWISE-modellépítéssel

18
A többváltozós lineáris regresszió eredménye

21
Szóródási grafikonok

22
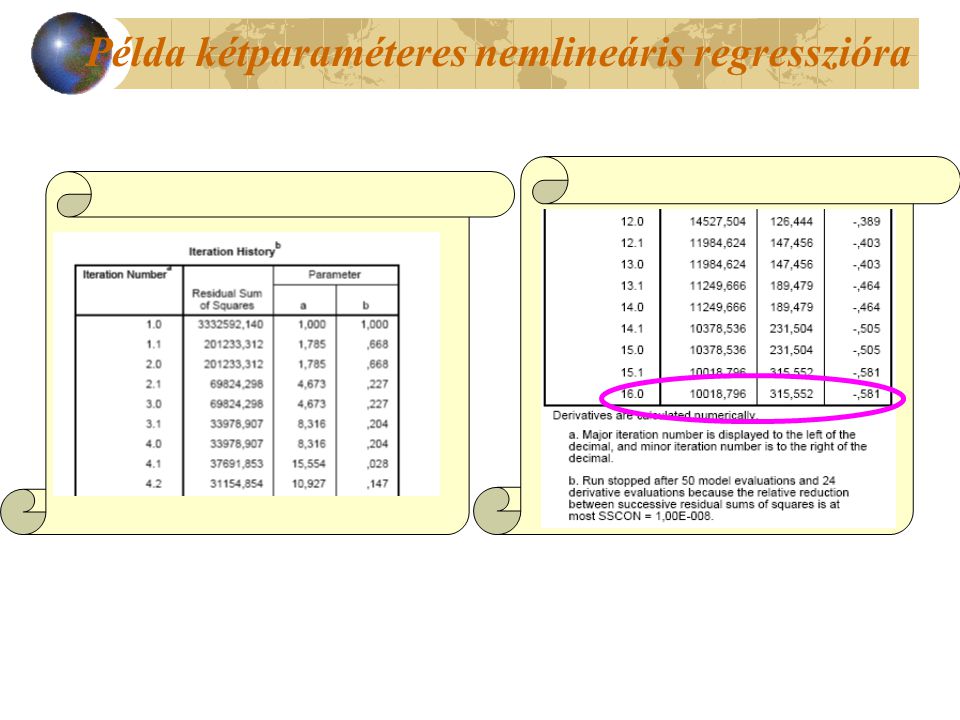
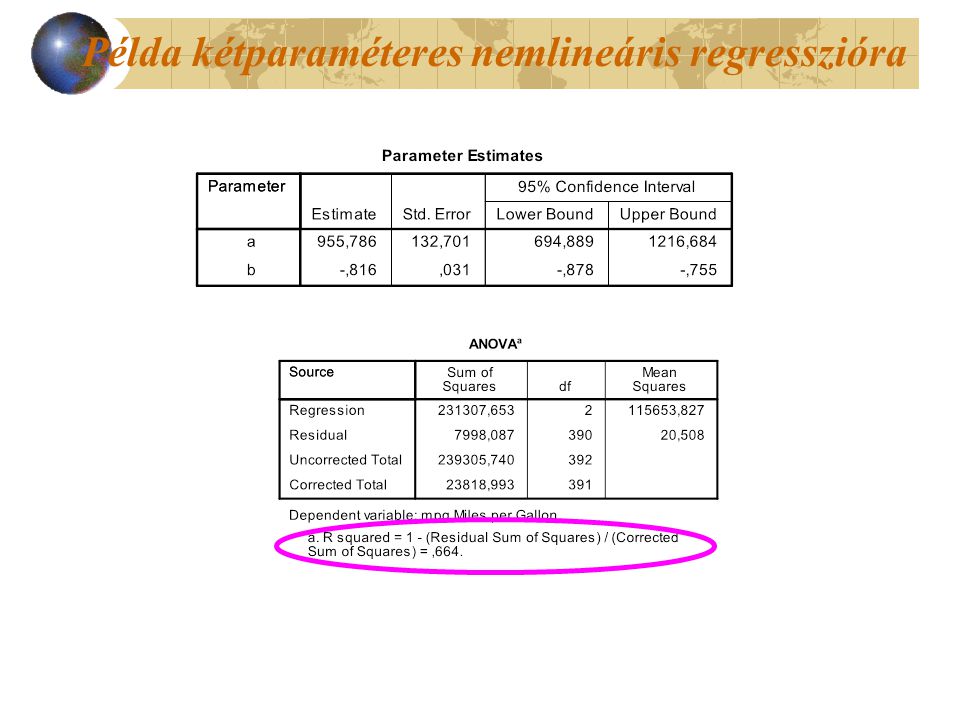
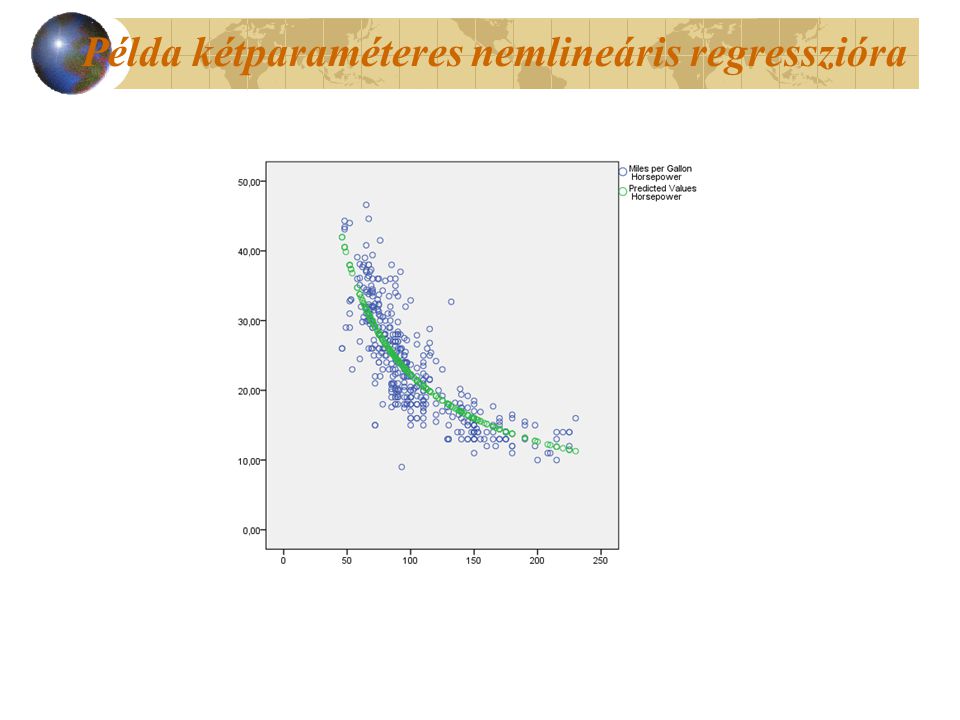
Példa kétparaméteres nemlineáris regresszióra Keressünk nemlineáris kapcsolatot Cars állományban a lóerő és a fogyasztás között!

23
Példa kétparaméteres nemlineáris regresszióra

29
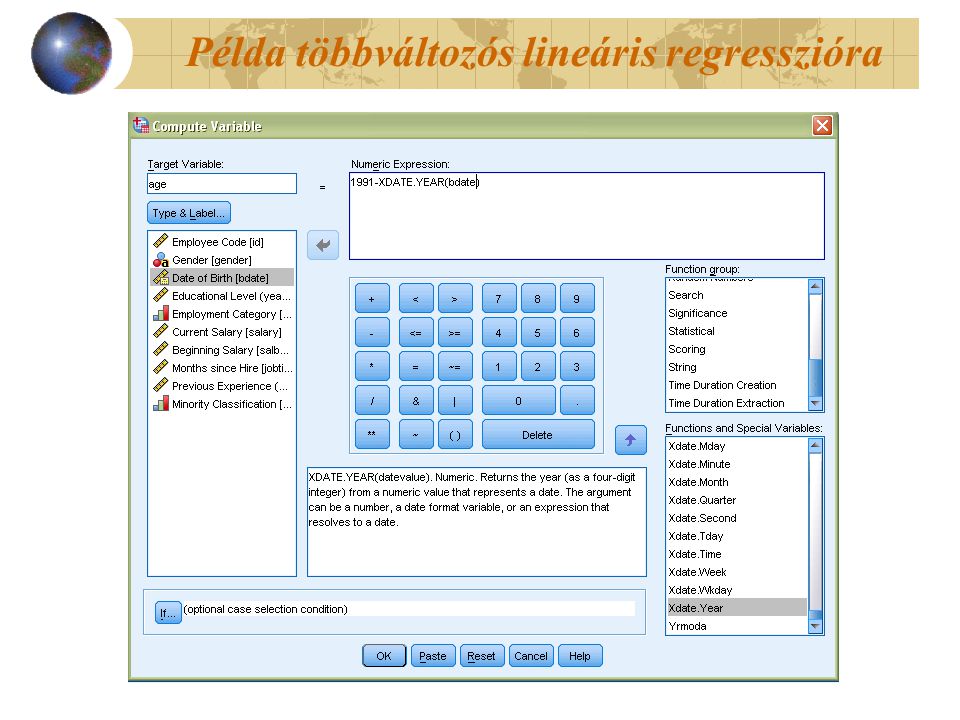
Példa többváltozós lineáris regresszióra Adjunk többváltozós lineáris elemzést a dolgozó fizetésére, a magyarázó változók a kezdőfizetés (salbegin), az alkalmazás ideje (jobtime) és a dolgozó kora (age) legyen!
, az alkalmazás ideje (jobtime) és a dolgozó kora (age) legyen!")
30
A dolgozó kora eredetileg nem szerepelt a változók listáján. Úgy képeztük, hogy a születési dátumból az év adatot levontuk az állomány keletkezésének évéből! Példa többváltozós lineáris regresszióra

32
Új változót hoztunk létre a dolgozó korával

33
Példa többváltozós lineáris regresszióra A konstans szerepe elhanyagolható a modellben.

34
Bináris logisztikus regresszió Egy bank kölcsönkihelyezésért felelős vezetője alkalmas bináris logisztikus regressziós modellel kívánja tanulmányozni a bank 700 jelenlegi ügyfelének rendelkezésre álló adatait abból a célból, hogy 150 új kölcsönért folyamodó potenciális ügyfél kérelmét minél megalapozottabban bírálhassa el. Az adatok a bankloan.sav adatmátrixban vannak.

35
Bináris logisztikus regresszió age (ügyfél életkora), ed (ügyfél iskolázottsága), employ (ügyfél hány éve van alkalmazásban jelenlegi munkaadójánál), address (ügyfél jelenlegi lakcíme), income (ügyfél háztartásának évi jövedelme ezer USD-ban), debtinc (ügyfél által felvett hitel aránya a jövedelméhez), creddebt (ügyfél hitelkártya tartozása ezer USD- ban), othdebt (ügyfél egyéb tartozása ezer USD-ban), default (ügyfél korábban megtagadta-e már a törlesztést).
, ed (ügyfél iskolázottsága), employ (ügyfél hány éve van alkalmazásban jelenlegi munkaadójánál), address (ügyfél jelenlegi lakcíme), income (ügyfél háztartásának évi jövedelme ezer USD-ban), debtinc (ügyfél által felvett hitel aránya a jövedelméhez), creddebt (ügyfél hitelkártya tartozása ezer USD- ban), othdebt (ügyfél egyéb tartozása ezer USD-ban), default (ügyfél korábban megtagadta-e már a törlesztést).")
36
Bináris logisztikus regresszió Az iskolai végzettség (ed) egy ötfokozatú ordinális változó, A bedőlés (default) egy bináris változó (ez a célváltozónk)
 egy ötfokozatú ordinális változó, A bedőlés (default) egy bináris változó (ez a célváltozónk)")
37
Az adatmátrix első 22 esete

38
A default változónak csak az első 700 esetben vannak értékei, hiszen a bank számára csak a jelenlegi ügyfelek esetében ismert, hogy korábban megtagadták-e már valamikor az aktuális törlesztésüket. Az elemzés célja, hogy a 150 új kölcsönért folyamodó potenciális ügyfélhez megalapozottan hozzárendelhessük a default változó várható értékeit. A módszerünk az lesz, hogy a 700 jelenlegi ügyfélből veszünk egy kb. 70%-os véletlen tanító (Training) részmintát (kb. 490 főt) és – miután a modellt a maradék kb. 30%-os Holdout részminta alapján validáltuk (érvényesítettük) - az így kapott a bináris logisztikus regressziós modellt alkalmazzuk a 150 új kölcsönért folyamodó potenciális ügyfélre, megtippelve azt, hogy problémás vagy megbízható ügyfél lesz-e. Bináris logisztikus regresszió
 részmintát (kb. 490 főt) és – miután a modellt a maradék kb. 30%-os Holdout részminta alapján validáltuk (érvényesítettük) - az így kapott a bináris logisztikus regressziós modellt alkalmazzuk a 150 új kölcsönért folyamodó potenciális ügyfélre, megtippelve azt, hogy problémás vagy megbízható ügyfél lesz-e. Bináris logisztikus regresszió.")
39
Hozzunk létre egy olyan particionáló változót, amely a 700 jelenlegi ügyfél kb. 70%-ához 1 kódot rendel, a maradék kb. 30%-hoz pedig 0 kódot rendel, a 150 új kölcsönért folyamodó potenciális ügyfélhez pedig nem rendel értéket!

40
Bináris logisztikus regresszió A művelet eredménye: A 150 új ügyfél nem kapott kódot! A régi ügyfelek 69.9%-a 1- es, 30.1%-a 0-ás kódot kapott! Az 1-esek lesznek a tanuló (training), a 0-ások lesznek a ellenőrző (holdout) részminta elemei.
, a 0-ások lesznek a ellenőrző (holdout) részminta elemei..")
41
Bináris logisztikus regresszió

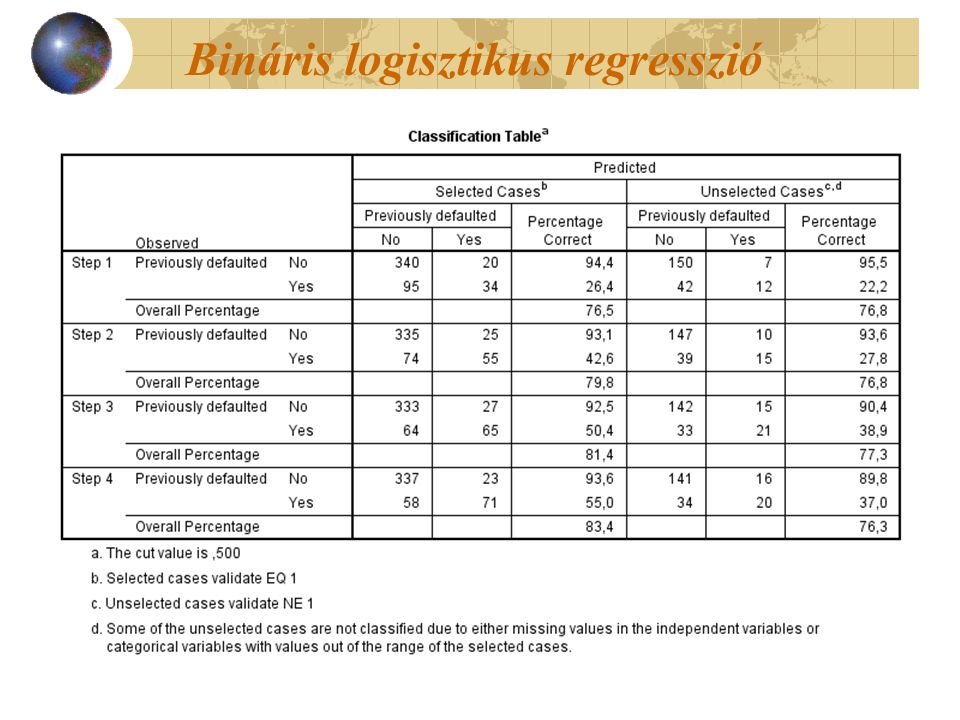
44
Classification Table táblázat legalsó sora az iterációs eljárás 4. lépésének eredményét mutatja. A táblázatban az „Observed” értékek a ténylegesen megfigyelt No és Yes adatok, míg a „Predicted” értékek akkor kerülnek a Yes kategóriába, ha a modellből becsült rájuk vonatkozó nem-fizetési valószínűség nagyobb az alkalmazott vágási szintnél (most ez 0,5-ös). Ha a modellből becsült nem-fizetési valószínűség kisebb a vágási szintnél, a „Predicted” értékek értelemszerűen a No kategóriába kerülnek. A Selected Cases oszlop felel meg a Training részmintából felépített modellnek, míg az Unselected Cases oszlop a Holdout részminta alapján validált végső modellnek felel meg.
. Ha a modellből becsült nem-fizetési valószínűség kisebb a vágási szintnél, a „Predicted értékek értelemszerűen a No kategóriába kerülnek. A Selected Cases oszlop felel meg a Training részmintából felépített modellnek, míg az Unselected Cases oszlop a Holdout részminta alapján validált végső modellnek felel meg..")
45
Bináris logisztikus regresszió Érdekesség, hogy a kor (age), jövedelem (income), iskolai végzettség (ed) és az egyéb hiteltartozás (othdebt) nem került be a magyarázó változók közé!
, jövedelem (income), iskolai végzettség (ed) és az egyéb hiteltartozás (othdebt) nem került be a magyarázó változók közé!")
46
Bináris logisztikus regresszió A Hosmer-Lemeshow goodness-of-fit statistic bináris klasszifikációs modelleknek a mért adatokhoz történő illeszkedésének a vizsgálatára alkalmas robusztus statisztika. Mivel itt az a nullhipotézis, hogy a modell nem illeszkedik a mért adatokhoz, Sig. (p) 0,05 alatti értékei esetén lenne a modell elfogadhatatlan. Esetünkben azonban a szignifikancia szintje a negyedik lépésben.155, ami azt jelenti, hogy az illeszkedés még megfelelőnek tekinthető.
 0,05 alatti értékei esetén lenne a modell elfogadhatatlan. Esetünkben azonban a szignifikancia szintje a negyedik lépésben.155, ami azt jelenti, hogy az illeszkedés még megfelelőnek tekinthető..")
47
Bináris logisztikus regresszió A 0.5-ös vágási szinttel az új ügyfelekre becslést adunk a bedőlés változóra!

48
Bináris logisztikus regresszió Az új ügyfelek 16%-a tűnik rizikósnak!

Hasonló előadás


















 alapjában a változók csoportosítására, redukciójára.>")



