Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
STATISZTIKA II. 10. Előadás
Dr. Balogh Péter egyetemi adjunktus Gazdaságelemzési és Statisztikai Tanszék

2
A modell feltételek vizsgálata
Az SLM modell feltételezései: F1: A magyarázó változók nem valószínűségi változók F2: A magyarázó változók lineárisan független rendszert alkotnak F3: Az eredményváltozó feltételes várható értéke lineáris függvény F4: A maradékváltozó normális eloszlású és állandó szórású F5: A maradékváltozó különböző értékei korrelálatlanok

3
A modell feltételek vizsgálata
Az F1 (a magyarázó változók nem valószínűségi változók) feltétel a modell keretei között nem vizsgálható: a felhasználó dönti el, hogy a vizsgálat tárgya eleget tesz-e ennek. Nagy minták esetén közelítőleg érvényes Az F2 (a magyarázó változók lineárisan független rendszert alkotnak) jelenti az extrém multikollinearitást (ez ritka). A gyakorlatban a szoros kapcsolat figyelhető meg a magyarázó változók között – multikollinearitás
 feltétel a modell keretei között nem vizsgálható: a felhasználó dönti el, hogy a vizsgálat tárgya eleget tesz-e ennek. Nagy minták esetén közelítőleg érvényes. Az F2 (a magyarázó változók lineárisan független rendszert alkotnak) jelenti az extrém multikollinearitást (ez ritka). A gyakorlatban a szoros kapcsolat figyelhető meg a magyarázó változók között – multikollinearitás.")
4
A modell feltételek vizsgálata
A multikollinearitás úgy is megfogalmazható, hogy a magyarázó változók között korreláció van. Multikollineáris esetben mind a becslés, mind a paraméterek értelmezése megnehezedik, hiszen a magyarázó változók hatásait nem lehet egyértelműen szétválasztani. Minden változó hatása minden más változóban is megjelenik, a becslések bizonytalanná válnak (ceteris paribus elv nem igaz).
.")
5
A modellfeltételek vizsgálata
Ez a mutató azt mutatja, hogy a j-edik változó becsült együtthatójának tényleges varianciája hányszorosa annak, ami a multikollinearitás teljes hiányának esete lenne. Ezért ezt a mutatószámot a j-edik változóhoz tartozó variancianövelő tényezőnek (Variance Inflator Factor) VIFj mutatónak nevezzük.
 VIFj mutatónak nevezzük.")
6
A modellfeltételek vizsgálata
Minimális értékét, az 1-et akkor veszi fel, amikor a megfelelő , azaz amikor a j-edik magyarázó változó nem korrelál a többivel. Látható, hogy ahogy nő az , úgy nő a VIF értéke is, mutatva, hogy a kollinearitás hányszorosára növeli a varianciával mért becslési hibát. Az esetben a mutató nem értelmezhető, ez a teljes vagy extrém multikollinearitás.

7
A modell feltételek vizsgálata
VIF értékei: 1 – 2 gyenge 2 – 5 erős (zavaró) 5 felett nagyon erős (káros) Kezelése: A zavart okozó változókat elhagyni a modellből Az egymással nagyon szoros kapcsolatban levő változókat egy új változóba vagy változókba összevonjuk (főkomponens elemzés). Ridge regresszió (torzított, de kisebb varianciájú becslőfüggvényt ad, mint a legkisebb négyzetek becslőfüggvénye)
 5 felett nagyon erős (káros) Kezelése: A zavart okozó változókat elhagyni a modellből. Az egymással nagyon szoros kapcsolatban levő változókat egy új változóba vagy változókba összevonjuk (főkomponens elemzés). Ridge regresszió (torzított, de kisebb varianciájú becslőfüggvényt ad, mint a legkisebb négyzetek becslőfüggvénye)")
9
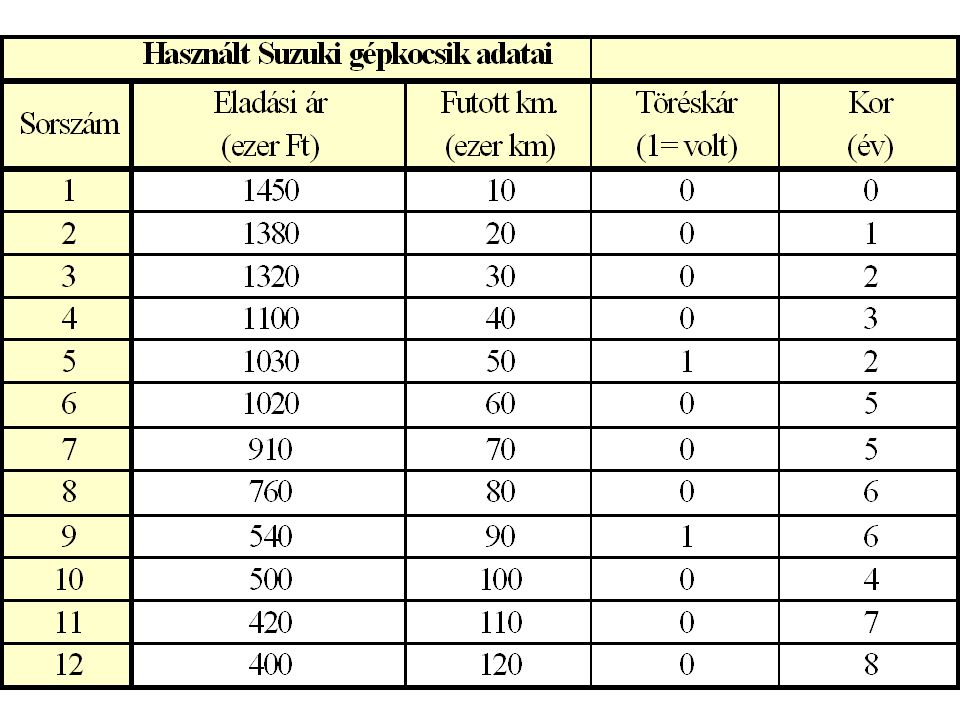
A Suzuki gépkocsik árát leíró regressziós függvény
futásteljesítmény (-9,74) kocsi életkora -6,15 együtt a két változó (-9,81) (1,30) Pozitív előjel ???
 kocsi életkora. -6,15. együtt a két változó. (-9,81) (1,30) Pozitív előjel")
10
Erős, zavaró multikollinearitás !!!!
A Suzuki gépkocsik árát leíró regressziós függvény Öregebb kocsik több kilométert futottak Erős, zavaró multikollinearitás !!!!

11
A modell feltételek vizsgálata
Az F3 (Az eredményváltozó feltételes várható értéke lineáris függvény) közvetve az F4-en keresztül ellenőrizhető. Az F4 (A maradékváltozó normális eloszlású és állandó szórású) első része: A normalitás ellenőrzése azért fontos, mert erre az eloszlási eredményre épülnek az intervallumbecslések és a tesztek, ezért ha nem igaz, azaz a normalitás nem áll fenn, mind az intervallumbecslések, mind a paraméterekre vonatkozó tesztek félrevezetőek lesznek.
 közvetve az F4-en keresztül ellenőrizhető. Az F4 (A maradékváltozó normális eloszlású és állandó szórású) első része: A normalitás ellenőrzése azért fontos, mert erre az eloszlási eredményre épülnek az intervallumbecslések és a tesztek, ezért ha nem igaz, azaz a normalitás nem áll fenn, mind az intervallumbecslések, mind a paraméterekre vonatkozó tesztek félrevezetőek lesznek.")
12
A modell feltételek vizsgálata
Az általános illeszkedésvizsgálat – kicsi elemszám probléma Kis mintákra is jól közelítő eljárások: grafikus normalitás vizsgálat reziduumokat hisztogrammal ábrázoljuk Q – Q (quantile–quantile) és P – P (probability plot) grafikus tesztek hagyományos szignifikancia tesztek: Kolmogorov-Szmirnov-teszt Jarque-Bera-teszt
 és P – P (probability plot) grafikus tesztek. hagyományos szignifikancia tesztek: Kolmogorov-Szmirnov-teszt. Jarque-Bera-teszt.")
13
Grafikus normalitásvizsgálat
Normalitás kétséges Normalitás vélelmezhető

14
A modell feltételek vizsgálata
Ha a normalitás nem teljesül az intervallumbecslések és a tesztek félrevezető eredményt adnak. Ilyen esetben más modellt kell alkalmazni (más változókkal) transzformáció
 transzformáció.")
15
A modell feltételek vizsgálata
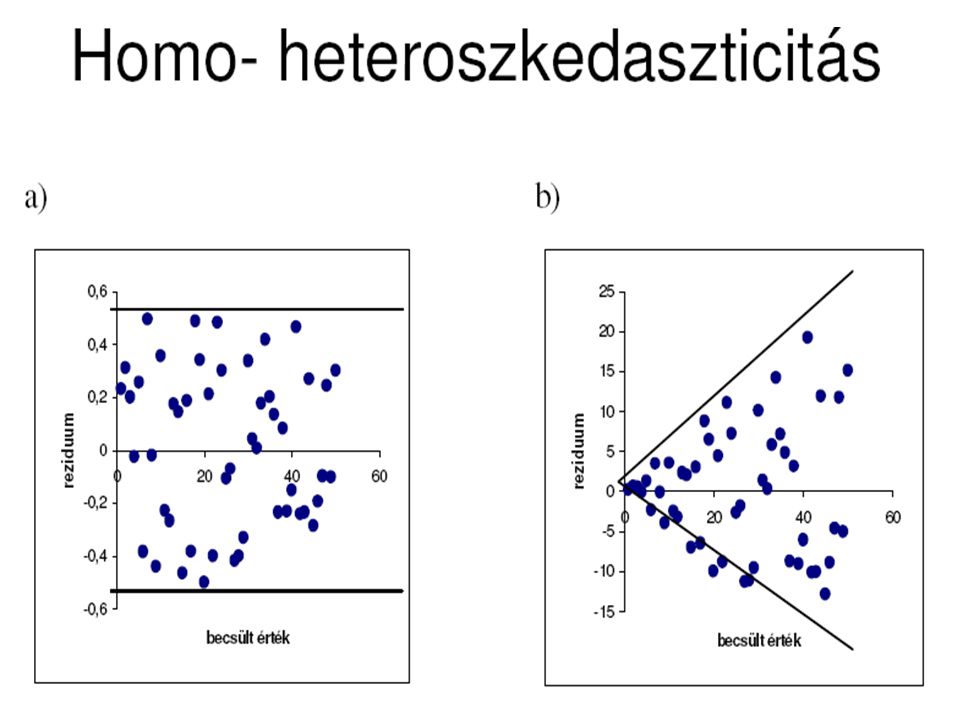
Az F4 (A maradékváltozó normális eloszlású és állandó szórású) második fele: A variancia legyen állandó, azaz független attól, hogy X illetve az Xj változók milyen értékeket vesznek fel. Ha ez teljesül a modell homoszkedasztikus, ha nem teljesül heteroszkedaszticitás problémája áll fenn.
 második fele: A variancia legyen állandó, azaz független attól, hogy X illetve az Xj változók milyen értékeket vesznek fel. Ha ez teljesül a modell homoszkedasztikus, ha nem teljesül heteroszkedaszticitás problémája áll fenn.")
18
A heteroszkedaszticitás ábrázolása
y x

19
A modell feltételek vizsgálata
Vizsgálatára számos teszt létezik Különböző esetek: Áttérés a tervgazdálkodásról a piacgazdaságra (idősoros regresszió) a maradékokban két jól elkülöníthető csoport (heteroszkedaszticitás), a csoportokon belül homoszkedaszticitás van. A lakosság jövedelem szerinti rétegzett mintavétele esetén csoportos heteroszkedaszticitás. Funkcionális heteroszkedaszticitás – a variancia valamely ismertváltozó szerint, annak mindenkori értékeivel együtt változik.
 a maradékokban két jól elkülöníthető csoport (heteroszkedaszticitás), a csoportokon belül homoszkedaszticitás van. A lakosság jövedelem szerinti rétegzett mintavétele esetén csoportos heteroszkedaszticitás. Funkcionális heteroszkedaszticitás – a variancia valamely ismertváltozó szerint, annak mindenkori értékeivel együtt változik.")
20
A modell feltételek vizsgálata
Az F5 (A maradékváltozó különböző értékei korrelálatlanok) azaz a maradékok legyenek egymástól függetlenek. Az egymástól való függetlenség csak meghatározott sorrend esetén érvényes tulajdonság – olyan megfigyelések amikor a megfigyelések sorrendje kötött. A társadalmi-gazdasági elemzésekben az idősoros regressziónál fordul elő.
 azaz a maradékok legyenek egymástól függetlenek. Az egymástól való függetlenség csak meghatározott sorrend esetén érvényes tulajdonság – olyan megfigyelések amikor a megfigyelések sorrendje kötött. A társadalmi-gazdasági elemzésekben az idősoros regressziónál fordul elő.")
21
Az autokorreláció és tesztelése
Regressziónál kétféle adatbázis: Keresztmetszeti adatbázis (egy időpontra vagy időszakra vonatkozó adatok) pl. országok adatai, háztartások vagy személyek jövedelem és fogyasztási adatai Idősoros adatbázis (idősorok közötti regressziós kapcsolatot vizsgálunk) pl. egy nemzetgazdaság adatai különböző időpontokban. Fontos, hogy az idősorok sorrendje nem cserélhető fel.
 pl. országok adatai, háztartások vagy személyek jövedelem és fogyasztási adatai. Idősoros adatbázis (idősorok közötti regressziós kapcsolatot vizsgálunk) pl. egy nemzetgazdaság adatai különböző időpontokban. Fontos, hogy az idősorok sorrendje nem cserélhető fel.")
22
Az autokorreláció és tesztelése
Egy szokásos (lineáris) korreláció, csak éppen nem különböző, hanem azonos változók, máskor vagy máshol megfigyelt értékei között. Az autokorreláció leggyakoribb előfordulása az idősorokban figyelhető meg, ahol egy változó saját késleltetett értékeivel vett összefüggéseit méri. Hiánya azt jelenti, hogy a vizsgált változó időbeli alakulása nem magyarázható saját korábbi értékeivel – időbeli függetlenség
 korreláció, csak éppen nem különböző, hanem azonos változók, máskor vagy máshol megfigyelt értékei között. Az autokorreláció leggyakoribb előfordulása az idősorokban figyelhető meg, ahol egy változó saját késleltetett értékeivel vett összefüggéseit méri. Hiánya azt jelenti, hogy a vizsgált változó időbeli alakulása nem magyarázható saját korábbi értékeivel – időbeli függetlenség.")
23
Az autokorreláció és tesztelése
Egy tőzsdeindex az előző kereskedési naphoz képest erősödött (+) vagy gyengült (-). Ha a változatlanságot kizárjuk akkor egy két jelből álló sorozattal írható fel: +++ – – – – ++++ – + – + – – + Kérdés, hogy a jelek elrendeződéséből tudunk-e következtetni a következő napi változás irányára? – ez az elsőrendű korreláció kérdése is.
 vagy gyengült (-). Ha a változatlanságot kizárjuk akkor egy két jelből álló sorozattal írható fel: +++ – – – – ++++ – + – + – – + Kérdés, hogy a jelek elrendeződéséből tudunk-e következtetni a következő napi változás irányára – ez az elsőrendű korreláció kérdése is.")
24
Az autokorreláció és tesztelése
Ha a sorozatunk a következő: – – – – – – – – – – – – A szabály: a következő nap is ugyanolyan változás várható, mint az előző napon. Ezt a megfigyelések csak egyetlen egy esetben cáfolták. – erős elsőrendű pozitív autokorreláció van az idősorban (az idősor mindenkori értékéből jó hatásfokkal tudunk következtetni a következő értékre).
.")
25
Az autokorreláció és tesztelése
Ha a sorozatunk a következő: + – + – + – + – + – + – + – + – + – Az elsőrendű (egy időszakra vonatkozó) következtetés itt is lehetséges. A következő nap éppen ellentétes irányú változásra lehet számítani. – erős elsőrendű negatív autokorreláció van az idősorban (az idősor mindenkori értékéből jó hatásfokkal tudunk következtetni a következő értékre).
 következtetés itt is lehetséges. A következő nap éppen ellentétes irányú változásra lehet számítani. – erős elsőrendű negatív autokorreláció van az idősorban (az idősor mindenkori értékéből jó hatásfokkal tudunk következtetni a következő értékre).")
26
Az autokorreláció és tesztelése
Ha két, három stb. időszakra akarunk következtetni az idősor valamely értékéből akkor másod-, harmadrendű stb. autokorrelációt keresünk. Ez bonyolultabb, mint az elsőrendű vizsgálata. ARIMA idősormodellek az autokorrelációból építkeznek. A regressziónál a maradékváltozó nem tartalmazhat autokorrelációt. Ha tartalmaz autokorrelációt: a varianciabecslés, az intervallumbecslések és a tesztek torzítottá válnak.

27
Az autokorreláció és tesztelése
A Durbin-Watson-próba az elsőrendű autokorreláció tesztelésére alkalmas. A regressziós maradékokra épít és a maradékok sorrendje kötött (idősorok). Az i-t t-re (time) cseréljük. A t-edik megfigyelésre vonatkozó egyenlet a következő: A maradékváltozó elsőrendű autokorrelációjának felírása: Azt feltételezzük, hogy a maradékváltozó t-edik időpontbeli értéke (εt) a lineáris regressziós egyenletben saját késleltetett értéke és egy jó tulajdonságú (0 várható értékű, homoszkedasztikus, autokorrelálatlan, normális eloszlású) véletlen változó (ηt) segítségével írható fel. Ez az elsőrendű autoregresszív egyenlet.
. Az i-t t-re (time) cseréljük. A t-edik megfigyelésre vonatkozó egyenlet a következő: A maradékváltozó elsőrendű autokorrelációjának felírása: Azt feltételezzük, hogy a maradékváltozó t-edik időpontbeli értéke (εt) a lineáris regressziós egyenletben saját késleltetett értéke és egy jó tulajdonságú (0 várható értékű, homoszkedasztikus, autokorrelálatlan, normális eloszlású) véletlen változó (ηt) segítségével írható fel. Ez az elsőrendű autoregresszív egyenlet.")
28
Az autokorreláció és tesztelése
Ha a elsőrendű autokorrelációs együttható 0, nincs elsőrendű autokorreláció. A Durbin-Watson-teszt nullhipotézise és ellenhipotézise: Felírható lenne a De nem közvetlenül a -t hanem annak egy transzformáltját teszteljük.

29
Az autokorreláció és tesztelése
Definiáljuk a regressziós maradékokból a ún. Durbin-Watson-statisztikát. A számláló alapján, nagy minták esetén jól leírható a függvényében, hiszen: Ennek eloszlása – nem standard – a d=2 pontra szimmetrikus és (0, 4) intervallumban vehet fel értékeket. Az eloszlás általánosságban (x konkrét ismerete nélkül) nem határozható meg, de kvantiliseinek alsó és felső közelítő értékei (dL és dU) táblázatosan megadhatók.
 intervallumban vehet fel értékeket. Az eloszlás általánosságban (x konkrét ismerete nélkül) nem határozható meg, de kvantiliseinek alsó és felső közelítő értékei (dL és dU) táblázatosan megadhatók.")
30
Az autokorreláció és tesztelése
Ha a próbafüggvény (d) empirikus értéke a 0 – dL tartományba esik, a döntés az, hogy a maradékváltozó szignifikáns mértékű pozitív autokorrelációt tartalmaz. Ha a próbafüggvény empirikus értéke a dL – dU tartományba esik, e próba alapján nem tudunk dönteni, ezt a tartományt semleges zónának nevezzük. Ha a próbafüggvény empirikus értéke a dU – (4 - dU) tartományba esik, a nullhipotézist, azaz a maradékváltozó elsőrendű autokorrelációtól való mentességét nem tudjuk elutasítani. Ennek a tartománynak a közepe 2.
 empirikus értéke a 0 – dL tartományba esik, a döntés az, hogy a maradékváltozó szignifikáns mértékű pozitív autokorrelációt tartalmaz. Ha a próbafüggvény empirikus értéke a dL – dU tartományba esik, e próba alapján nem tudunk dönteni, ezt a tartományt semleges zónának nevezzük. Ha a próbafüggvény empirikus értéke a dU – (4 - dU) tartományba esik, a nullhipotézist, azaz a maradékváltozó elsőrendű autokorrelációtól való mentességét nem tudjuk elutasítani. Ennek a tartománynak a közepe 2.")
31
Az autokorreláció és tesztelése
Ha a próbafüggvény empirikus értéke a (4 - dU) – (4 - dL) tartományba esik, ismét semleges zónában vagyunk és nem tudunk dönteni. Ha a próbafüggvény empirikus értéke a (4 - dL) – 4 tartományba esik, döntésünk szignifikáns negatív autokorreláció.
 – (4 - dL) tartományba esik, ismét semleges zónában vagyunk és nem tudunk dönteni. Ha a próbafüggvény empirikus értéke a (4 - dL) – 4 tartományba esik, döntésünk szignifikáns negatív autokorreláció.")
32
pozitív autokorreláció negatív autokorreláció
A Durbin – Watson – teszt döntési szabálya H0: nincs autokorreláció H1: pozitív autokorreláció H1: negatív autokorreláció ? ? dL dU 2 4 - dU 4 - dL 4

34
Az autokorreláció és tesztelése
A teszt a negatív, illetve a pozitív autokorrelációt mindig az ellenkező oldalon mutatja. A alapján a jellemző autokorrelációs értékek (-1, 0, 1) a (4, 2, 0) formában jelennek meg a Durbin-Watson-tesztben. A semleges zónákba eső próbafüggvény értéke alapján nem tudunk dönteni: - szignifikanciaszintet változtatjuk meg, - más próbafüggvényt kell választanunk.
 a (4, 2, 0) formában jelennek meg a Durbin-Watson-tesztben. A semleges zónákba eső próbafüggvény értéke alapján nem tudunk dönteni: - szignifikanciaszintet változtatjuk meg, - más próbafüggvényt kell választanunk.")
35
Cementtermelés (ezer tonna) Épített lakások száma (darab)
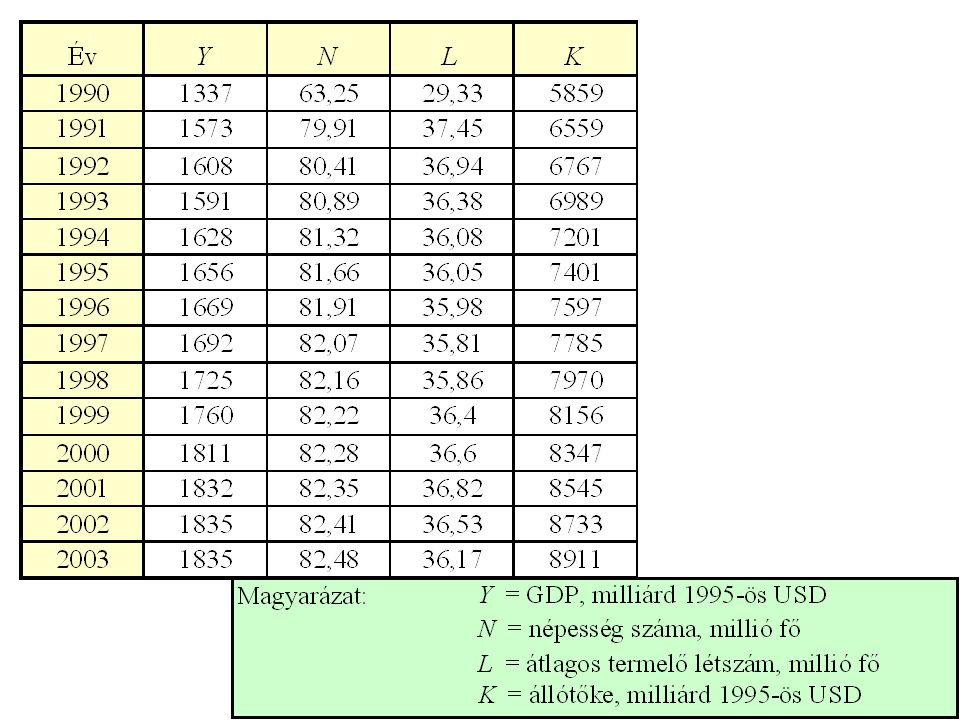
Év Cementtermelés (ezer tonna) GDP volumenindex (1985=100) Épített lakások száma (darab) 1985 3678 100 72507 1986 3846 101,34 69428 1987 4153 105,7 57200 1988 3873 50566 1989 3857 106,38 51487 1990 3933 102,68 43771 1991 2529 90,27 33164 1992 2236 87,58 25807 1994 2793 89,6 20947 1995 2875 90,94 24718 1996 2747 92,28 28257 1997 2811 96,64 28130 1998 2999 20323 1999 2980 19287 2000 3326 111,07 21583 2001 3452 115,1 28054 2002 3510 119,13 31511 2003 3641 122,58 35543
 GDP volumenindex (1985=100) Épített lakások száma (darab) , , , , , , , , , , , , , ,")
36
Az autokorreláció és tesztelése
Példa A cementtermelés háromváltozós egyenletének maradékait vizsgálva kiszámítottuk a maradékok elsőrendű autokorrelációs együtthatóját és a Durbin-Watson-statisztika értékét (d=1,8133). Látható, hogy az egyébként nagy mintákra érvényes közelítés, a összefüggés: jó közelítéssel itt is érvényes, hiszen A Durbin-Watson-teszt 5%-os táblázatából n=19 és k=2 paraméterek esetén dU=1,08 és dL=1,53 olvasható ki, ami azt jelenti, hogy a maradékokban 5%-os szinten nincs szignifikáns autokorreláció.
. Látható, hogy az egyébként nagy mintákra érvényes közelítés, a összefüggés: jó közelítéssel itt is érvényes, hiszen. A Durbin-Watson-teszt 5%-os táblázatából n=19 és k=2 paraméterek esetén dU=1,08 és dL=1,53 olvasható ki, ami azt jelenti, hogy a maradékokban 5%-os szinten nincs szignifikáns autokorreláció.")
37
Az autokorreláció és tesztelése
Az autokorreláció jelenléte a maradékokban problémát okoz – védekezni kell ellene!!! Módosított modellbe olyan változók beépítése, amelyek „átveszik” az autokorrelációt, így az a véletlen elemekben nem jelenik meg. Ez legtöbbször újabb késleltetett változókat jelent a modellben. Olyan adattranszformáció alkalmazása, amely kiszűri azt a hibát. Tekintsük az regressziót, ahol a maradékváltozóra a elsőrendű autokorrelációs egyenlet érvényes.

38
Az autokorreláció és tesztelése
Írjuk fel most t-1 időszakra, majd szorozzuk meg ρ-val, majd vonjuk ki a kiindulási egyenletből a második egyenletet: Az eredmény azt mutatja, hogy a változókból kivonva saját ρ-val szorzott késleltetett értékeit (ezt szokták elsőrendű autoregresszív transzformációnak nevezni), olyan alakot kapunk, amelyiknek a maradékváltozója az utolsó egyenlet értelmében ηt, ami már rendelkezik a modellfeltételek által megkövetelt autokorreláció-mentességgel ezért alkalmas a paraméterek KLN becslésére. A ρ előre általában nem ismert, így a mintából kell becsülnünk.
, olyan alakot kapunk, amelyiknek a. maradékváltozója az utolsó egyenlet értelmében ηt, ami már rendelkezik a modellfeltételek által megkövetelt autokorreláció-mentességgel. ezért alkalmas a paraméterek KLN becslésére. A ρ előre általában nem ismert, így a mintából kell becsülnünk.")
39
Az autokorreláció és tesztelése
A gyakorlatban a sűrű megfigyelésű (napi, heti) idősorok esetén gyakori az, hogy a megfigyelt adatok között igen erős, 1-hez közel álló elsőrendű autokorreláció tapasztalható, ami a regressziós maradékokban is megjelenhet. Ekkor a KLN becslés komoly hibaforrás lehet. Ilyenkor a ρ-t célszerű 1-nek tekinteni. Az autoregresszív transzformáció eredménye a következő: Így eltűnik a β0 és a maradékváltozó lehetővé teszi a KLN becslést. A változók növekedésükkel (differenciáikkal) lépnek be az egyenletbe, ahol a meredekségi paraméter (β1) eredeti formájában jelenik meg. Ez az eljárás, amikor a változók szintjei helyett azok szukcesszív differenciáira építenek regressziós modellt nagyon elterjedt.
 idősorok esetén gyakori az, hogy a megfigyelt adatok között igen erős, 1-hez közel álló elsőrendű autokorreláció tapasztalható, ami a regressziós maradékokban is megjelenhet. Ekkor a KLN becslés komoly hibaforrás lehet. Ilyenkor a ρ-t célszerű 1-nek tekinteni. Az autoregresszív transzformáció eredménye a következő: Így eltűnik a β0 és a maradékváltozó lehetővé teszi a KLN becslést. A változók növekedésükkel (differenciáikkal) lépnek be az egyenletbe, ahol a meredekségi paraméter (β1) eredeti formájában jelenik meg. Ez az eljárás, amikor a változók szintjei helyett azok szukcesszív differenciáira építenek regressziós modellt nagyon elterjedt.")
40
A változók körének és számának meghatározása – modellépítés
A gyakorlatban a regressziós elemzésnél első feladat az eredményváltozó pontos meghatározása, az arra vonatkozó adatok összegyűjtése, összehasonlíthatóvá tétele, szerkesztése. A következő lépés a magyarázó változók kijelölése, a rájuk vonatkozó adatok összeállítása, valamint a regressziós függvény formájának (lineáris, exponenciális, hatvány, polinom) meghatározása.
 meghatározása.")
41
A változók körének és számának meghatározása – modellépítés
A magyarázó változók lehetséges körének kijelölése Lehetséges-e ezekre adatot gyűjteni? Proxy, dummy változók alkalmazása Több változó specifikálása Az összes változó felhasználása (beépítése a modellbe)? - szoros kapcsolatban levő változók zavarják egymást, parciális hatások torzulnak. Az összes fontos (szignifikáns) magyarázó változó szerepeltetése a modellben. Kialakítás 3 követelménye: A modell valamennyi változója egy előre megadott (pl. 5%-os) szinten szignifikáns legyen. Maga a modell (az ANOVA F-próbájával mérve) legyen egy előre megadott (pl. 5%-os) szinten szignifikáns Illeszkedjék a lehető legjobban valamely kritérium szerint
 - szoros kapcsolatban levő változók zavarják egymást, parciális hatások torzulnak. Az összes fontos (szignifikáns) magyarázó változó szerepeltetése a modellben. Kialakítás 3 követelménye: A modell valamennyi változója egy előre megadott (pl. 5%-os) szinten szignifikáns legyen. Maga a modell (az ANOVA F-próbájával mérve) legyen egy előre megadott (pl. 5%-os) szinten szignifikáns. Illeszkedjék a lehető legjobban valamely kritérium szerint.")
42
A változók körének és számának meghatározása – modellépítés
R2 szelekcióra nem alkalmas, mivel egy újabb változó bevonása értékét növeli (esetleg változatlan marad). A szabadságfokkal korrigált R2 (adjusted R2) már alkalmas mutató: Képes két regressziós modell magyarázó erejét összehasonlítani. Egy modell esetén értelmetlen használni!!!!!! Számítógépes kereső eljárások (stepwise eljárások) alkalmazása – minden lépés után összehasonlítás Forward regresszió: alulról építkezik, legegyszerűbb modellből indul ki Backward regresszió: az összes lehetséges változóból épített modellből hagyja el a lényegtelen változókat. Ha mindhárom követelmény teljesül – optimális regressziónak nevezik.
. A szabadságfokkal korrigált R2 (adjusted R2) már alkalmas mutató: Képes két regressziós modell magyarázó erejét összehasonlítani. Egy modell esetén értelmetlen használni!!!!!! Számítógépes kereső eljárások (stepwise eljárások) alkalmazása – minden lépés után összehasonlítás. Forward regresszió: alulról építkezik, legegyszerűbb modellből indul ki. Backward regresszió: az összes lehetséges változóból épített modellből hagyja el a lényegtelen változókat. Ha mindhárom követelmény teljesül – optimális regressziónak nevezik.")
43
Néhány nevezetes alkalmazás
A termelési függvények: Mikrogazdasági elemzések – termelési tényezők, azaz inputok (pl. munka, tőke, föld) milyen mennyiségű kibocsátást (outputot) képesek előállítani. Ezek a termelési függvények általában alakúak, ahol a Q az előállított termelés mennyiségét X1, X2, … Xk pedig a termelési tényezőket jelöli. Leggyakoribb a Cobb-Douglas-típusú termelési függvény alkalmazása – két tényezőt a tőkét (K) és munkát (L) vesz figyelembe, és hatványkitevős függvényt specifikál:
 milyen mennyiségű kibocsátást (outputot) képesek előállítani. Ezek a termelési függvények általában. alakúak, ahol a Q az előállított termelés mennyiségét X1, X2, … Xk pedig a termelési tényezőket jelöli. Leggyakoribb a Cobb-Douglas-típusú termelési függvény alkalmazása – két tényezőt a tőkét (K) és munkát (L) vesz figyelembe, és hatványkitevős függvényt specifikál:")
44
Néhány nevezetes alkalmazás
Ez egy nemlineáris regressziós függvény. Probléma: Mivel mérjük a munkaráfordítást (idővel, bérrel, létszámmal) A tőkét milyen mutatóval reprezentáljuk Ez modell választási probléma!! A 1 és 2 paraméterek parciális (állandó) rugalmasságot fejeznek ki. Ez a függvény alapul szolgálhat a további szakmai elemzéseknek (előrejelzés, helyettesíthetőség elemzése, ráfordítás optimalizálás)
 A tőkét milyen mutatóval reprezentáljuk. Ez modell választási probléma!! A 1 és 2 paraméterek parciális (állandó) rugalmasságot fejeznek ki. Ez a függvény alapul szolgálhat a további szakmai elemzéseknek (előrejelzés, helyettesíthetőség elemzése, ráfordítás optimalizálás)")
46
Néhány nevezetes alkalmazás
A német gazdaság fejlődése jól modellezhető a klasszikus Cobb-Douglas-termelési függvénnyel. A becsült függvény a következő: és mind az F, mind az összes t érték minden szóbajöhető szignifikanciaszinten azt jelzi, hogy a modell, illetve az egyes változók helyesek.

47
Néhány nevezetes alkalmazás
A visszatranszformált eredeti (hatványkitevős) alak: A két paraméter a munka, illetve a tőke szerinti (állandó) rugalmasságot mutatja. A létszám 1%-os növekedése ceteris paribus 0,41%-os növekedést indukál a GDP-ben. A rugalmassági paraméterek összege közel 1, ami azt jelenti, hogy a skálahozadék közel konstans.
 alak: A két paraméter a munka, illetve a tőke szerinti (állandó) rugalmasságot mutatja. A létszám 1%-os növekedése ceteris paribus 0,41%-os növekedést indukál a GDP-ben. A rugalmassági paraméterek összege közel 1, ami azt jelenti, hogy a skálahozadék közel konstans.")
48
Néhány nevezetes alkalmazás
Autoregresszív modellek: Állományi típusú idősorok esetén az adat függ az előző időszaki adatoktól. Az ilyen idősorban autokorreláció van – autoregresszív egyenlet vagy modell A legegyszerűbb autoregresszív egyenlet: Alakú és hasonlít egy kétváltozós lineáris regressziós függvényre. Ez a modell kiindulópontja egy egész elemzési módszercsaládnak. ARMA (Autoregresszív Mozgó Átlagolású) alapú modellek – pl. több késleltetés, véletlenhatások sem a legegyszerűbbek, hanem időbeli kapcsolatot mutatnak, szóródásuk időben változó, összefüggnek az eredményváltozóval.
 alapú modellek – pl. több késleltetés, véletlenhatások sem a legegyszerűbbek, hanem időbeli kapcsolatot mutatnak, szóródásuk időben változó, összefüggnek az eredményváltozóval.")
49
HUF/EUR árfolyam

50
Néhány nevezetes alkalmazás
HUF/EUR árfolyam egyszerű autoregresszív modelljének keresése: 2006. január és augusztus között napi adatok alapján, 158 napra vonatkozóan. A késleltetés miatt csak 157 megfigyelés. Modellünk azt feltételezi, hogy az eredményváltozó jól leírható saját (1 nappal) késleltetett függvényeként lineáris regresszióval.
 késleltetett függvényeként lineáris regresszióval.")
51
A HUF/EUR árfolyam lineáris autoregresszív jellege

52
Néhány nevezetes alkalmazás
A becslés eredménye: (68,86)
")
53
A HUF/EUR árfolyam időbeli alakulása és annak becslése
megfigyelés becslés

54
Néhány nevezetes alkalmazás
ARMA modellek kiterjesztései: (ARIMA, SARIMA, ARCH, GARCH stb.) az idősorelemzés és a regressziószámítás külön, gyorsan fejlődő fejezetét képezik. Általános Lineáris Modell (GLM) Logisztikus regresszió – diszkrét eredményváltozós modellek Többegyenletes kiterjesztés – gazdaság, mint komplex jelenség modellezése – ökonometria Sokváltozós modellek – társadalmi jelenségekre
 az idősorelemzés és a regressziószámítás külön, gyorsan fejlődő fejezetét képezik. Általános Lineáris Modell (GLM) Logisztikus regresszió – diszkrét eredményváltozós modellek. Többegyenletes kiterjesztés – gazdaság, mint komplex jelenség modellezése – ökonometria. Sokváltozós modellek – társadalmi jelenségekre.")
Hasonló előadás


















 3., mintavételi információk alapján megállapítások, következtetések.>")


