Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
A tudás reprezentálása a világhálón az internetes keresőrendszerek működése Tóth Erzsébet Lektorálta: Tanyiné Dr. Kocsis Anikó Debreceni Egyetem Informatikai Kar, Könyvtárinformatikai Tanszék 2010.

2
1. Bevezetés

3
1.1. A webes keresőrendszerek definíciói
Internetes keresők alatt a programoknak egy olyan általános csoportját értjük, amely lehetővé teszi a weben történő dokumentumkeresést a felhasználók számára. Ezek a programok dokumentumokat indexelnek és arra törekednek, hogy megtalálják a releváns találatokat a feltett keresőkérdésre.

4
(Forrás: angol nyelvű Wikipédia http://en.wikipedia.org )
A search engine is an information retrieval system designed to help find information stored on a computer system. The search results are usually presented in a list. Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information overload. (Forrás: angol nyelvű Wikipédia )
")
5
Search Engine: The software that searches an index and returns matches
Search Engine: The software that searches an index and returns matches. Search engine is often used synonymously with spider and index, although these are separate components that work with the engine. (Forrás: Ranking web of world repositieries

6
1.2. A globalizáció és a keresők közötti éles verseny
Korunk számos legjelentősebb folyamata: a politikai, katonai értelemben vett egyhatalmú világ kialakulása, a demokratizálódás, - az európai integráció, - a fokozódó ázsiai gazdasági együttműködés, - a technológia forradalma, - a globalizáció, - az információs és a fogyasztói társadalom kialakulása. Azok a világ minden részére közvetlenül, vagy közvetve ható, globális folyamatoknak tekinthetők.

7
Az információs és kommunikációs technológia (IKT) rohamos fejlődésének és konvergenciájának köszönhetően a társadalomban egy új életforma, újszerű működés és viselkedés alakult ki. Új értékrendek jöttek létre. Ezt a széles körben elterjedt új életmódot, magatartást, információs technológiára épülő gazdaságot információs társadalomnak hívjuk. Az „információs társadalom” kifejezés az 1960-as évek második felében jelent meg.

8
Az információs társadalom kialakulása országonként különböző időszakban és ritmusban megy végbe.
A társadalom tágabb értelemben vett fejlettségi szintje és a kultúra nagymértékben befolyásolja. Fontos, hogy erre a folyamatra sokkal „könnyebben” lehet hatni, társadalmi szinten jó irányba terelni, mint a globalizációra. A fogyasztói társadalom megjelenése a globalizációhoz és az információs társadalomhoz kapcsolódó harmadik jelentős folyamat.

9
A globalizáció gyorsuló és könyörtelen versennyel jár együtt.
Úgy lehetünk versenyképesek, ha az információs társadalom legfőbb értékét, magát az információt részesítjük előnyben. Egy adott szakmai kérdés megválaszolásának a leggyakoribb kiindulási pontja lehet az internet, amely a minket körülvevő globális társadalomnak egyik fontos eszköze.

10
A világhálón történő információkereséskor egyre nagyobb gondot jelent számunkra a minőségi, releváns információk kiválogatása a ránk zúduló információáradatból. Ebben támogatnak minket a rendelkezésünkre álló keresőszolgáltatások, bár nem minden esetben nyújtanak tökéletes megoldást számunkra.

11
Az interneten megjelenő keresőeszközök köré külön iparág szerveződött, amelybe kisebb-nagyobb méretű cégek, vállalatok nagy pénzösszegeket fektetnek be. Mindezt pedig saját versenyképességük, sikerességük és hatékonyságuk javítása érdekében teszik.

12
Search Engine Marketing Professionals Organization (SEMPO) 2008-as felmérésének lényeges megállapításai: 13,5 billió dollárt költöttek a cégek keresőmarketingre 2008-ban Észak-Amerikában. Ennek legnagyobb részét a találatelhelyezés és a keresőoptimalizálás (SEO) tette ki. Az összeg maradéka pedig olyan szolgáltatókhoz került, akik a kampányok szoftveres megvalósításában vettek részt. Az előrejelzés szerint a keresőmarketingbe fektetett pénzösszeg 2013-re elérheti a 26 billió dollárt Észak-Amerikában.
 tette ki. Az összeg maradéka pedig olyan szolgáltatókhoz került, akik a kampányok szoftveres megvalósításában vettek részt. Az előrejelzés szerint a keresőmarketingbe fektetett pénzösszeg 2013-re elérheti a 26 billió dollárt Észak-Amerikában.")
13
A költések jelenlegi arányai eltolódást mutatnak a fizetett találatok javára (88 százalékban), miközben a SEO csupán 11 százalékkal részesedik az összegből. Ez a tendencia megváltozik a jövőben, mivel az internetezők jobban kedvelik a természetes listázást, mint a fizetett találatokat. A használók relevánsabbnak, elfogadhatóbbnak tartják a keresésekre kapott természetes találatokat, míg az utóbbit egyszerű reklámnak vélik.

16
Az IAB (Interactive Advertising Bureau) Hungary „Adex 2008” felmérése alapján ban a magyar hirdetők 21,8 milliárd forintot fordítottak online reklámozásra. Ez 6,5 milliárd forinttal több mint 2007-ben. Az online reklámpiac így 2008-ban 42%-kal bővült, melynek köszönhetően részesedése a reklámtortából 10,8% volt. (Forrás: )
")
17
A keresőszolgáltatások, a cégek, vállalatok érdekeltek abban, hogy minél több bevételre tegyenek szert. Jelentős mennyiségű pénzösszeget fektetnek be keresőmarketingbe a későbbi megtérülés reményében. Ebben a kiélezett versenyhelyzetben a keresők folyamatosan törekszenek arra, hogy megújuljanak és, hogy minél több speciális, új szolgáltatással vonzzák a használókat maguk köré. Ezért rendkívül fontos a versenyben részt vevő szereplők számára, hogy az egyes keresőeszközök minőségét hogyan értékelik a kutatók.

18
1.3. Információkeresési modellek
Az információkeresésre irányuló kutatás több mint két évtizedes múltra tekint vissza. A vizsgálódás egyik lehetséges iránya a kérdést feltevő használók viselkedésének tanulmányozása, azaz milyen kérdést, hogyan, milyen társadalmi rétegből, milyen tanultsággal rendelkezők tesznek fel. A kutatók 1981-től folyamatosan számos modellt alkottak meg.

19
A modellek kialakítását befolyásolta a kutatók világlátása, kutatási területe és jártassága.
Ennek értelmében beszélhetünk kognitív perspektivikus, szociális, szociális-kognitív vagy szervezeti modellekről. E modellek által a használók weben történő keresése több szinten vizsgálható: 1. beleértve a társadalmi és a szervezeti szintet, 2. az információkeresés szintjét, 3. az ember és a számítógép közötti kapcsolat szintjét, 4. a megfogalmazott keresőkérdés szintjét.

20
Csak jelzésszerűen hivatkozom kiváló kutatókra, akik komoly eredményeket értek el ezen a területen: Spink, Jansen, Saracevic, Ingwersen.

21
1.4. A tárgykör alapvető fogalmai és azok kapcsolatai
Metadat: ez alatt a weblapok intellektuálisan vagy automatikusan létrehozott másodlagos adatait értjük, amelyek magát a dokumentumot jellemzik. Másik definíció szerint: metaadaton mindazokat a többletinformációkat értjük, amelyeket a weboldalak készítői a weboldalakhoz kapcsolnak a keresőkérdés pontosabb megválaszolása reményében.

22
Ezen adatok körébe tartoznak: a bibliográfiai leírás szabványosított adatelemei, a dokumentum tartalmát leíró kulcsszavak, tárgyszavak, deszkriptorok és az osztályozási jelzetek.

23
Metaadat-rendszerek és a katalogizálás
Szükség volt a metaadatok egységes elektronikus kezelésére, ami kiterjedt ezeknek az adatoknak az elsődleges dokumentumokból való kinyerésére és a dokumentumok számítógépes leírására. Metaadat-rendszereket hoztak létre. Pl.: - OCLC InterCat, - DublinCore, - WWW Semantic Header, - TEI (Text Encoding Initiative) fejléc stb.
 fejléc stb.")
24
E rendszereket összehasonlítva megfigyelhető, hogy a mű azonosítására szolgáló adatelemek (a szerző, a cím, a kiadó, a megjelenés éve, az ISBN stb.) mindegyikben szerepelnek. A további jellemzők (a megjelenés helye, az objektum típusa, formája, nyelve, vagy a rendszerkövetelmények, az elérés módja, költsége stb.) metaadatrendszerenként változnak. Az IFLA Katalogizálási Szekciójának keretében külön munkacsoport alakult a különböző metaadat-rendszerek alkalmazásának vizsgálatára.
 metaadatrendszerenként változnak. Az IFLA Katalogizálási Szekciójának keretében külön munkacsoport alakult a különböző metaadat-rendszerek alkalmazásának vizsgálatára.")
25
A Dublin Core szabványos metaadat formátum az elektronikus dokumentumok katalogizálását és a metaadatokból álló rekordok adatcseréjét teszi lehetővé a hálózaton. A Dublin Core létrehozásának oka az volt, hogy egyszerűbb megoldást találjanak ki a szigorú minőségi követelményeket és komplex formátumot megkívánó könyvtári katalogizáló rendszerek helyett. A Dublin Core jelentős, mert napjainkban ez az egyik legáltalánosabban elterjedt metaadat-alkalmazás.

26
A DC formátum 15 leíró elemet tartalmaz
A DC formátum 15 leíró elemet tartalmaz. Továbbá az áll a legközelebb a könyvtári katalogizáláshoz. A DC-t a USMARC-formátummal összehasonlítva Gorman azt találta, hogy minden egyes DC-elemnek megvan a megfelelő USMARC-mezője. A DC fejlesztői és használói elhatározták, hogy az IFLA FRBR-tanulmányát veszik alapul az elektronikus publikációk nemzeti indexelési szabályainak kialakításához. Elterjedését elősegítette, hogy adatelemeit az európai szabványosítási szervezet, a European Committee for Standardization (CEN) is elfogadta.
 is elfogadta.")
27
Az elektronikus dokumentumok bibliográfiai számbavételében Gorman szerint négy megközelítés lehetséges: a teljes, könyvtári szabályokon alapuló katalogizálás; a teljes (15 elemű) Dublin Core alkalmazása; a minimális (9 elemű) Dublin Core alkalmazása; a strukturálatlan teljes szövegű kulcsszavas keresés.
 Dublin Core alkalmazása; a minimális (9 elemű) Dublin Core alkalmazása; a strukturálatlan teljes szövegű kulcsszavas keresés.")
28
Ha az elektronikus dokumentumokat értékük szerint rangsorolják, akkor a bibliográfiai számbavétel mind a négy szintje alkalmazható: 1. az elektronikus dokumentumok kis része (2%-a) a teljes MARC-rekordokban katalogizálható; 2. a teljes Dublin Core szerinti “katalogizálás”; 3. a minimális Dublin Core szerinti rekordok létrehozását jelenti; 4. az elektronikus dokumentumok nagyobbik – és kevésbé értékes – része a keresőmotorokra hagyható.
 a teljes MARC-rekordokban katalogizálható; 2. a teljes Dublin Core szerinti katalogizálás ; 3. a minimális Dublin Core szerinti rekordok létrehozását jelenti; 4. az elektronikus dokumentumok nagyobbik – és kevésbé értékes – része a keresőmotorokra hagyható.")
29
1.4.1. A keresőszolgáltatások típusai
I. Indexelőszolgáltatások : (search engines, Suchmaschinen, moteurs de recherche) emberi munka nélkül, számítógépes programok segítségével végzik a keresést a hálózaton. Ezek a szolgáltatások két fő részből állnak: a keresőrobotból (crawler, web spider, web robot, bot) és az indexelőből (indexer).
 emberi munka nélkül, számítógépes programok segítségével végzik a keresést a hálózaton. Ezek a szolgáltatások két fő részből állnak: a keresőrobotból (crawler, web spider, web robot, bot) és az indexelőből (indexer).")
30
A robotok állandóan figyelemmel követik és begyűjtik a weboldalakat a világhálóról a keresőszolgáltatás adatbázisába. Az indexelő elemzi a begyűjtött dokumentumokat, amelyekből előállítja az indexkifejezéseket. Létrehoz egy indexet, amely minden szóhoz – a stopword-öket kivéve – hozzárendeli az őt tartalmazó Uniform Resource Locator-ok (URL) listáját. A keresőszolgáltatás erre az indexre támaszkodik, amely révén elvégzi a keresést a felhasználó számára.
 listáját. A keresőszolgáltatás erre az indexre támaszkodik, amely révén elvégzi a keresést a felhasználó számára.")
31
A keresőrobotot és az indexelőt integráló egységet „keresőgépnek”, „keresőmotornak”, „keresőműnek” (search engine), „keresőrendszernek” (search system) nevezzük. Tévesen a teljes keresőszolgáltatást „keresőgépnek”, „keresőmotornak”, „robotnak” hívjuk, ami a szolgáltató rendszernek csak az egyik részét jelenti. Ebbe beletartozik még a felhasználói felület és a szolgáltatott tartalom is.

32
Ezek a keresőszolgáltatások általában rendelkeznek egy egyszerű és egy összetett keresési lehetőséggel. Egyszerű kereséskor rendkívül nagy lehet a visszakeresett, nem releváns dokumentumok száma, azaz a zaj.

33
A zaj csökkentésére tanácsos használnunk a részletes keresési lehetőséget (advanced search, powered search). Példák indexelőszolgáltatásokra: Google, Altavista, AlltheWeb stb. szolgáltatások.

34
II. Internetkatalógusok: (directories, annuaires Internet, répertoires Internet),
a szakirodalmi források különbözően hívják az ilyen típusú keresőket. Megnevezéseik a következők: „böngészőszolgáltatás” (browsing service, browsing Dienste), „tárgyszótár”, „tématár” (subject directory, Themenverzeichniss, annuaire thématique), „webes katalógus” (annuaire Web, répertoire Web).
, „tárgyszótár , „tématár (subject directory, Themenverzeichniss, annuaire thématique), „webes katalógus (annuaire Web, répertoire Web).")
35
A katalógusok hagyományos vagy egyénileg kialakított osztályozási rendszert használnak.
Az osztályozást és a tartalmi kivonatok készítését szerkesztőségben végzik. Humán erővel gyűjtik és rendezik fa-struktúrába a kiválasztott weboldalakat a generikustól a specifikus témákig haladva.

36
Ezekben a katalógusokban osztályok alapján böngészhetünk, de lehetőségünk van arra is, hogy a keresőkérdés megadásával találjuk meg a kívánt osztályt. Általában rendelkeznek a saját lelőhelyükön belül használható kulcsszavas keresési lehetőséggel is. Adatbázisaik sokkal kisebbek, mint az indexelőszolgáltatásokéi.

37
Azonban a keresés bennük lényegesen kisebb zajjal jár az intellektuális feldolgozásnak és az osztályozásnak köszönhetően. A szakterületre specializálódott keresők nagy része internetkatalógusnak számít. Többnyire általánosabb szintű információk felkutatására alkalmasak a népszerű és a tudományos témák esetében. Pl.: Yahoo.

38
Az internetkatalógusok két alcsoportja:
a. Akadémiai vagy szakmai gyűjtemények: a kialakított osztályok egyes szakértői szerkesztik azokat a kutatás támogatása érdekében. A hagyományos osztályozási rendszerek használata elsősorban ezekre a gyűjteményekre jellemző. A hivatkozások gondosan megválasztottak , többnyire annotáltak. Ezek a gyűjtemények megkímélnek minket a nagytömegű hirdetésektől, reklámoktól. Példák: Internet Public Library (IPL2), BUBL Information Service.
, BUBL Information Service.")
39
b. Kereskedelmi portálok:
a nagyközönség igényeit igyekeznek kielégíteni. Ebből adódóan a szórakozás, sport, kereskedelem, utazás, stb. témakörök túlsúlya jellemzi őket, valamint az igen intenzív reklám tevékenység. Pl.: Looksmart. Számos internetkatalógussal mint kiegészítő szolgáltatással találkozunk az indexelőszolgáltatások oldalain.

40
III. Metakeresők: (meta search engines, Meta-Suchmaschinen, métamoteurs, métachercheurs)
segítségükkel több indexelőszolgáltatásban kereshetünk párhuzamosan anélkül, hogy az egyes szolgáltatásokkal külön foglalkoznunk kellene. A rendszer mindegyik keresőszolgáltatás adatbázisában végrehajtja a keresést, megjelenítve a találatoknál, hogy melyik szolgáltatás adatbázisában találta meg a rekordot.

41
Előnyük, hogy rövid idő alatt valószínűsíthetően több releváns találathoz jutunk.
Növeli a találati esélyünket az ismeretlen, homályos témák esetében. Átfogóbb képet nyújthat a weben egy adott témában fellelhető információkról. A metakeresők hátránya viszont, hogy azoknál általában egyszerű keresési módszereket alkalmazhatunk és többnyire nincs mód a mező szerinti szűkítésre.

42
A metakeresőket nehezebben csapják be őket azok az oldalak, amelyek mindenféle trükkös megoldásokkal a javukra befolyásolják a keresők találatrangsorolását. Az ilyen oldalak igazi, használható tartalommal nem rendelkeznek. Ezeket az oldalakat “spam”-eknek hívjuk. A metakeresők azért képesek a “spam” oldalak kiszűrésére, mert azok általában egy-egy keresőre szakosodnak és egyszerre több keresőt már nem tudnak becsapni.

43
A metakeresők két típusa:
1. Az átfogó keresés eredményeit külön megjelenítő rendszerek, amelyek a különböző keresők által létrehozott találati halmazokat nem dolgozzák egybe. 2. Az eredményeket válogatottan és együttesen megjelenítő rendszerek, amelyek mindig a saját oldalukon jelenítik meg a találatokat összefésülve. Gyakrabban fordulnak elő, mint az előző típus. Többnyire kiszűrik a duplumokat, de az egyes keresők által generált találati listákat egy bizonyos rekordszámnál egyszerűen elvágják. Példák: Mamma, Metacrawler, Dogpile stb.

44
A metakeresőkkel szemben támasztott követelmények:
Párhuzamos keresés végrehajtása; Találat-összefésülés; Duplum rekordok kezelése, azaz ugyanazt a weboldalt a rendszernek fel kell ismernie, és jelölnie kell az egyes forrásokat, amelyből származik; ÉS- meg VAGY logikai műveletek biztosítása keresésnél;

45
Információveszteség nélküli működés (ha pl
Információveszteség nélküli működés (ha pl. az egyik weboldal tartalmi kivonatokat tartalmaz, azt át kell tudni vennie a metakeresőnek); Forrásrendszer elfedés (=hiding) a lekérdezett keresők tulajdonságai nem játszhatnak semmiféle szerepet a metarendszer szintjén, a felhasználónak semmit sem kell tudnia ezekről a specifikumokról; Teljesség (a keresésnek addig kell tartania, ameddig a lekérdezett szolgáltatásokból találatok nyerhetők).
; Forrásrendszer elfedés (=hiding) a lekérdezett keresők tulajdonságai nem játszhatnak semmiféle szerepet a metarendszer szintjén, a felhasználónak semmit sem kell tudnia ezekről a specifikumokról; Teljesség (a keresésnek addig kell tartania, ameddig a lekérdezett szolgáltatásokból találatok nyerhetők).")
46
IV. Intelligens keresőprogramok (intelligent agents)
- A felhasználó számítógépére telepíthető keresőprogramok. - Nagy részük működésébe intelligens ügynökszoftver technológiát integrál, ezáltal újabb keresési funkciókat nyújt a felhasználóknak. Pl.: a találatok automatikus finomítását, a keresőszavak tényleges kiemelését, a találatok elmentését és újra történő felhasználását, a megszakadt hivatkozások ellenőrzését, stb.

47
Működésükre jellemző, hogy:
a felhasználói elvárásokhoz történő folyamatos alkalmazkodás. Ezek a keresőprogramok figyelemmel követik a felhasználó kereső profilját, érdeklődési körét és annak megfelelő minőségi információt szolgáltatnak a hálózatról. Hasonlítanak a metakeresőkhöz, mert ugyanazt a keresőkérdést párhuzamosan több keresőszolgáltatáshoz juttatják el és a találatokat összefésülve jelenítik meg.

48
Dokumentumtípustól és formátumtól függetlenül képesek keresni.
Az ügynökszoftverek nem hoznak létre nagy indexeket, hanem autonóm módon keresik a kért információt. Kereső algoritmusaikat a felhasználótól kapott információ és visszajelzés alapján módosítják meg. A felhasználó csupán a kitűzött célt határozza meg számukra, de a megvalósítás mikéntjével és hogyanjával kapcsolatos döntéseket rábízza az ügynökszoftverekre.

49
Fő tulajdonságaik: Autonómia: a felhasználó nevében tevékenykednek és döntéseket hoznak a környezetükből kapott információk alapján. Rugalmasság: figyelemmel követik külső környezetüket és megvizsgálják a hasonló körülmények között végrehajtott korábbi tevékenységek (heurisztikák) sikerességét. Tevékenységüket olyan irányban képesek megváltoztatni, hogy azzal növeljék a cél sikeres elérésének valószínűségét.
 sikerességét. Tevékenységüket olyan irányban képesek megváltoztatni, hogy azzal növeljék a cél sikeres elérésének valószínűségét.")
50
Tanulás: ismerik a felhasználó személyes érdeklődési körét, ezért egy bizonyos idő után képesek egyre növekvő pontossággal előrejelezni, hogy az adott dokumentum számításba jöhet-e az adott felhasználónál, avagy sem. Mobilitás és távoli végrehajtás: ezek a programok a szerverek között vándorolnak egy heterogén hálózati környezetben.

51
Több népszerű keresőprogram jelent meg eddig a szoftverpiacon, amely kipróbálásra ingyenesen letölthető a hálózatról, teljes verziójukért azonban már fizetni kell, pl. Copernic szoftver. Ez a technológia a kutatás és egyben az új alkalmazásfejlesztés egyre növekvő területe. Egyre nagyobb szerepet kap a kifinomultabb keresések lebonyolításában a weben, például a láthatalan web információinak a felkutatásában.

52
1.4.2. A keresők szűkítési lehetőségei
Minden keresőrendszer nyitó oldalán van egy kereső ablak, ahol a beírt szavakon felül az egyén bejelölhet bizonyos szűkítéseket: Boole-algebrai kifejezések (AND, OR, NOT); azoknak a szavaknak a megadása, amelyeknek benne kell lenniük, vagy amelyeknek nem szabad benne lenniük a keresett dokumentumban +, - jelekkel jelöljük; csonkolás (* maximum 5 karaktert helyettesít);
; azoknak a szavaknak a megadása, amelyeknek benne kell lenniük, vagy amelyeknek nem szabad benne lenniük a keresett dokumentumban +, - jelekkel jelöljük; csonkolás (* maximum 5 karaktert helyettesít);")
53
pontos kifejezésre történő keresés „….” ;
helyzeti operátorok (NEAR, BETWEEN); szűkítés: dátum, nyelv, terület, fájltípus szerint. A nagy találathalmazok csökkentésére használjuk a keresőknél felkínált szűkítési lehetőségeket! Mivel az egyes keresőrendszerek által alkalmazott keresési szintaxis eltérő, mindig meg kell vizsgálni a felajánlott keresési lehetőségeket!
; szűkítés: dátum, nyelv, terület, fájltípus szerint. A nagy találathalmazok csökkentésére használjuk a keresőknél felkínált szűkítési lehetőségeket! Mivel az egyes keresőrendszerek által alkalmazott keresési szintaxis eltérő, mindig meg kell vizsgálni a felajánlott keresési lehetőségeket!")
54
2. A tárgykör kapcsolódó területei
Szemantikus web: feladata a jelentés megtalálása a webes tartalmakban. A szemantikus web kialakítására irányuló törekvések során jelentek meg az ontológiák. Gruber megfogalmazása szerint az „ontológia megegyezésen alapuló fogalmi rendszer formális, egyértelmű leírása”.

55
Ebben a meghatározásban a „megegyezésen alapuló” kitétel lényeges, mert azt a szemléletet tükrözi, hogy az ontológiák szemantikai szabályrendszerek, melyek a dolgok rendezésére használhatók. Az ontológiák lehetővé teszik számunkra, hogy tisztázzuk az alapvető fogalmakat és a közöttük lévő relációkat. Elősegítik számunkra, hogy az erre vonatkozó tudásunkat formálisan és gépi következtetésre alkalmasan fogalmazzuk meg.

56
A webes ontológiák kialakulásához vezető út
2000-ben közreadtak egy „tématérképnek” (topic map) nevezett hierarchikus fogalmi struktúrát kezelő szabványt. A weben jelenleg elérhető vizualizált fogalmi struktúrák többsége ezen, vagy ehhez hasonló fejlesztéseken alapszik.
 nevezett hierarchikus fogalmi struktúrát kezelő szabványt. A weben jelenleg elérhető vizualizált fogalmi struktúrák többsége ezen, vagy ehhez hasonló fejlesztéseken alapszik.")
57
A W3C konzorcium irányítása alatt egy másik irányban kezdődött el a fejlesztés.
Ennek egyik fontos eredménye, hogy 2000-ben a web metaadatainak leírására egy szabványt hoztak létre, az XML-en alapuló webforrás leíró nyelvet (Resource Description Framework= RDF). A weben található hierarchikus fogalmi struktúrák formális leírására is ezt a nyelvet használták fel.
. A weben található hierarchikus fogalmi struktúrák formális leírására is ezt a nyelvet használták fel.")
58
2002-ben a W3C konzorcium kezdeményezésére hozzákezdtek az ontológiák szabványának tekinthető webontológia-nyelv (Ontology Web Language) kidolgozásához. Az OWL 2-re vonatkozó szabványajánlást 2009-ben adta közre a W3C konzorcium. Forrás: OWL 2 Web Ontology Language Document Review.

59
Jelenleg elérhető és már létező általános ontológiák,
pl. - Dublin Core, - Magyar Egységes Ontológia. Szakterületi ontológiák: Pl.: - Galen orvostudományi területen , - Gold leíró nyelvészeti területen .

61
A „Museo24” projektben kifejlesztett ontológiának érdekes felhasználási területe a virtuális múzeum, amely gondolatvilágában közel áll a könyvtárakéhoz. Forrás:

63
Jelenleg egyfajta közeledés figyelhető meg hazánkban a könyvtári és az informatikai szakmai közösségek között az ontológiák terén, amit a W3C konzorcium magyar irodája szakmai előadások szervezésével támogat. Forrás:

65
2. Láthatatlan/mély web („invisible web”, „hidden web”, „deep web”)
Mindazon dokumentumok körét értjük alatta, amelyek számos okból kifolyólag nem érhetők el a keresőszolgáltatások számára. A láthatatlan web csoportjába sorolhatók: - a dinamikus weblapok (azaz a kereshető adatbázisokból kapott oldalak), - azok az oldalak, amelyek csak regisztráció után érhetők el, a nem szöveges dokumentumok, - a keresőmotorok által kizárt oldalak.
, - azok az oldalak, amelyek csak regisztráció után érhetők el, a nem szöveges dokumentumok, - a keresőmotorok által kizárt oldalak.")
66
Fontos hangsúlyoznunk, hogy a web csak egy szolgáltatás az interneten, tehát az nem azonos vele.
Egy olyan hipertext struktúrára épül, amelyben szabadon böngészhetünk a szöveges formában megjelenített információk közötti kapcsolatok alapján. Ha egy weblapra nem mutat egyetlen link sem, akkor nem kerül bele a kereső adatbázisába.

67
Azokat a weboldalakat, amelyeket a keresők keresőmotorjai megtalálnak „felszíni webnek” (surface web) vagy „statikus webnek” nevezzük. Ennek nagysága a teljes web méretének a 0,18%-ára becsülhető. Ezzel szemben a láthatatlan web információmennyisége 550-szer nagyobb, mint a felszínié és növekedése, gyarapodása is sokkal gyorsabb ütemű.

68
Sokféle törekvéssel igyekeztek a rejtett webet „láthatóvá tenni”
pl. bizonyos metakeresőkkel, intelligens keresőprogramokkal (ágensek), témakatalógusok kialakításával, egyéb speciális keresőkkel stb.
, témakatalógusok kialakításával, egyéb speciális keresőkkel stb.")
69
3. A szövegbányászat és az adatbányászat területe
A rejtett tudás kinyerésére törekszik a weben található, nagy mennyiségű strukturálatlan vagy félig strukturált HTML és egyéb formátumú dokumentumokból. Fiatal kutatási területnek számít még a web mining, amely kiterjed az adatbányászatra, az internet technológiákra, valamint a szemantikus webre.

70
4. Speciális keresőszolgáltatások
A weben találkozunk például képek, videóanyagok visszakeresésére alkalmas keresőkkel, amelyek nagy népszerűségnek örvendenek a használók körében. Megjelenésük jelzi, hogy a használók rendkívül nagy mértékben igénylik a nem szöveges dokumentumok eredményes felkutatását. Ezen az új kutatási területen a megfelelő információkereső nyelvek létrehozása és azok további fejlesztése elengedhetetlenül fontos feladat.

71
A képkeresőkre irányuló vizsgálatok gyakran nem veszik figyelembe a felhasználói oldalt:
pl. a szövegek és a képek utáni kutatás különbségeit, a képjellemzőket a keresésnél, és a képkereső kérdések sajátosságait. Ezek lényeges kérdések, különösen a webes keresők szempontjából.

72
Greisdorf és O'Connor es tanulmányukban megfogalmazták, hogy a találatként megjelenő képek relevanciája olyan fogalmi és tartalmi jellemzőktől is függ, amelyek nincsenek is rajta a képeken. Ilyen minősítők pl.: - művészettörténeti információ, - hely, - tárgy, - esemény, - ember, absztrakt fogalom stb. Továbbá, hogy az érzelmeket kifejező szavak fontos keresőkérdések a képeknél.

73
A keresésre fordított átlagos idő és a keresőkérdés is hosszabb a képek esetében, mint általában a webes kereséseknél. Ebből adódóan a multimédia-információ megtalálása nagyobb szellemi erőfeszítést követel tőlünk. Jansen as kutatása ugyanezt erősítette meg, aki az AltaVista-val társult multimédia-gyűjtemények használatát vizsgálta.

74
Kutatásának eredményei:
A képekre történő kereséseknél átlagosan négy szót írtak be a felhasználók. 28%-ban még Boole-operátorokat is alkalmaztak, hosszabb ideig keresgéltek, mint más dokumentumtípusoknál.

75
A képek indexelésére a legtöbb rendszer egyszerű megoldásokat használ, amelyek a következők:
a fájlnevek leindexelése és kereshetővé tétele, a környező szöveges információt gyűjtik egy adatbázisba, a weboldalak fejlécébe és a multimédiafájlokba ágyazott metaadatok alapján történik az indexelés.

76
Léteznek már osztályozási rendszerek képekre és képekre vonatkozó keresőkérdésekre.
Célszerű lenne a webes képkeresések jellemzőihez igazított osztályozási rendszereket használni, melyeket pl. a keresőkérdések kézi vagy automatikus metaadatolásához, címkézéséhez lehet felhasználni.

77
A kutatások eredményei szerint öt új jellemzőt kell bevezetni a képkereséseknél:
- gyűjtemény (pl. „stock photography”), - pornográfia (pl. „gay”), - prezentálás (pl. „clipart”), - URL (pl. „ - költség (pl. „free”). A költség fontos szempont a használók számára kereséskor. A web hipertext jellegéből adódóan URL címek is nagy számban fordulnak elő a keresőkérdésekben.
, - pornográfia (pl. „gay ), - prezentálás (pl. „clipart ), - URL (pl. „ ) - költség (pl. „free ). A költség fontos szempont a használók számára kereséskor. A web hipertext jellegéből adódóan URL címek is nagy számban fordulnak elő a keresőkérdésekben.")
78
Az emberek gyakran szűkítik a keresést a kép lelőhelyére, azaz a gyűjteményre.
Az emberek és az emberekkel kapcsolatos dolgok meghatározóak a kérdések között, míg az olyan tulajdonságok, mint pl. a szín, alig számítanak, pedig az ilyen képjellemzőkhöz a keresők külön szűkítési lehetőséget biztosítanak. Nem nagyon vizsgálták még meg, hogy ezek az osztályozási rendszerek mennyire lennének használhatók a weben lévő képek indexelése és visszakeresése során.

79
5. Blogok keresése Egy másik, szerkezeti sajátosságaiból adódóan elkülönülő dokumentumcsoportot is meg kell említenünk a weben, a blogokat és a mikroblogokat. Számuk rohamosan növekszik, mert divatos véleménnyilvánítási forma a használók körében. Komoly kihívást jelent napjainkban a blogok hatékony visszakeresésének megoldása, amely a hagyományos információvisszakereső rendszerek módszereitől eltérő mechanizmusokat követel meg.

80
Ez abból is adódik, hogy a blogoknál rendkívül nagy szerepe van az aktualitásnak és a kapcsolódó linkeknek, azonban sokszor nehéz meghatároznunk a témájukat. Megjegyzem, hogy az időtényező fokozottabb kiaknázása a keresésekben új vonásnak számít, pl. a blogok és a hírek esetében. A blogoknak is megvannak a speciális keresőik; közülük a legjobb a Technorati ( ).
.")
82
6. Innováció és tudásmenedzsment
Óriási fejlődési lehetőségeket rejt magában ez a terület, amit a Google is kiaknáz saját üzleti modelljében. 2006-ban egy jelentős változás tanúi lehettünk, amikor az interaktív, programozható web háttérbe szorította a statikus webet. A korábbi passzív internetezők önszerveződő közösségek aktív tagjaivá váltak, ami főként a web 2.0 térhódításának volt köszönhető.

83
A web tehát rendkívül nyitott közösségi színtérré alakult át az innováció, a kibontakozás, valamint az értékteremtés számára. Don Tapscott webelemző szerint az új web kollektív tudásbázisként jelenik meg, amiben emberek millióinak közös tudása gyűlik össze önszerveződő formában.

84
A Google és más üzleti cégek fokozatosan teret engednek a tömeges együttműködés kultúrájának. Olyan formában, hogy nyíltan hozzáférhetővé teszik alkalmazásaik programozófelületét (az API-t) platformjaikon. Mindezt azért teszik, hogy saját hasznukra fordíthassák az ott megjelenő tömegek ötleteit, tudását és energiáját.

85
Az API-k megnyitása után a fejlesztők (akik közül néhányan korábban „hekkerek” voltak…) gyors tempóban kezdték el gyártani az új alkalmazásokat. A Google tehát sikeresen maga köré gyűjtötte a fejlesztők hatalmas, önszerveződő hálózatát, amelyet önkényes eszközökkel meg sem próbál szabályozni, hisz az csak akadályozná a kreatív ötletek megvalósulását, azaz az innovációt.

86
6.1. A tudásmenedzsment lehetséges példái a Google-nél:
Innováció, kutatás fenntartása: A Google lelke egy új fejlesztés, és ez a fő téma a cég csaknem minden vezetőségi összejövetelén. A cég vezetői számára az a fő kihívás, hogy fenntartsák az innovatív fejlődést a Google méretbeli növekedésével. Az innováció tehet arról, hogy a cég lekörözött másokat, és jelenleg is az első vonalban van.

87
Az alapítók tisztában vannak vele, hogy valakik valahol mindig megpróbálnak olyan megoldásokat találni, melyek jobban, gyorsabban csinálják a dolgokat. Az innovativitás fenntartása egy nagy tempóban növekedő vállalatnál olyan komplex kihívás, ami komoly problémákat okozott már más, ígéretes vállalkozások számára.

88
A fejlesztések tesztelése felhasználókkal:
A Google munkatársai mindent megtesznek annak érdekében is, hogy a felhasználók még véglegesítésük előtt kipróbálhassák a termékeket. Így aztán a fejlesztések folyamatosak, az értékes reakciók pedig lehetővé teszik, hogy megszabaduljanak a hibáktól.

89
Nyitás más tudományterületek felé:
A Google egyéb területeken is tevékenykedik, ilyenek a molekuláris biológia és genetika. A gének milliói, a hatalmas mennyiségű adat végül is illik a Google keresőhöz, a komoly adatbázishoz, a számolókapacitáshoz.

90
A Google immár letöltötte az emberi genom-térképet, és vezető biológusokkal, genetikusokkal karöltve dolgozik olyan tudományos, gyógyászati területeken, ahol fontos áttörésekre lehet számítani a közeljövőben. Talán már nincs messze az idő, amikor az emberek rákereshetnek a Google-lel saját génjeikre.

91
Követi az egyetemi struktúrát működésében:
A Google céget úgy működtetik mint egy egyetemet. Rengeteg projekten dolgoznak párhuzamosan kis, három főből álló csoportok. A munkatársaktól elvárják, hogy idejük 20%-át olyan problémákra fordítsák, amelyek a legjobban izgatják őket.

92
„Az idő 20%-a„ az egyetemi világból jön, ahol a professzorok egy napot kapnak egy héten, melyet saját érdeklődésük kielégítésére fordíthatnak. A cégnél hiányoznak a szokásos jogász középvezetők, a társaságok hagyományos felépítését itt nem találjuk meg.

93
Könyvek digitalizálása:
A Google könyvek millióit kívánja digitalizálni számos könyvtár bevonásával. Célja, hogy minél több könyv legyen elérhető online, hogy kereshetőek legyenek. Továbbá célkitűzése, hogy ledőljenek a könyvtárak fizikai korlátai. Ez egy ambiciózus vállalkozás, globális, társadalmi, oktatási eredményei lehetnek.

94
„The Library Project's aim is simple:
make it easier for people to find relevant books – specifically, books they wouldn't find any other way such as those that are out of print – while carefully respecting authors' and publishers' copyrights. Our ultimate goal is to work with publishers and libraries to create a comprehensive, searchable, virtual card catalog of all books in all languages that helps users discover new books and publishers discover new readers” Forrás:

95
A Google 2009 novemberében ideiglenes egyezségre jutott az Egyesült Államokban a szerzői jogtulajdonosok képviselőivel, akik kifogásolták, hogy a keresőcég könyvek millióit digitalizálta. Az Authors Guild és az Association of American Publishers sokáig alkudozott a Google céggel egy New-York-i bíróság előtt, amíg nem sikerült kialkudni a részesedésüket az eredeti jogsértésből származó jövedelemből. Forrás:

97
Jelenleg a Google 125 millió dollárt fizet a per lezárásáért és létrehoz egy Book Rights Registry nevű nyilvántartást, amelyet az online szolgáltatott kiadványok szerzőinek és kiadóinak honorálásánál alkalmaz majd. Az egyezség pontos részletei is nyilvánosságra kerülhetnek, de sokkal valószínűbb, hogy olyan üzleti titok marad, amely a jövőben nagymértékben megváltoztatja az információellátás jellegét.

98
Ezzel az egyezménnyel a Google-nak megengedték, hogy digitalizálja azokat a könyveket is, amelyeket az Egyesült Államokban véd a copyright. A Google tervei szerint az egyetemek hozzáférhetnének a szolgáltatásaihoz térítés ellenében pl. ezekhez a ma még csak kereshető, de nem letölthető könyvekhez. Az ebből származó bevételeket megosztja majd a jogtulajdonosokkal és a szerzőkkel.

99
Ha ez az üzleti modell jól működik, akkor lehetséges, hogy a még forgalomban levő művek közül is sokat hozzáférhetővé tesznek majd így a szerzőik. Még nem lehet tudni, hogy milyen licencdíjak lesznek, és hogy a felsőoktatási könyvtárak korlátos költségvetéséből érdemes lesz-e ezeket kifizetni, többségében olyan könyvekért, amelyek iránt minimális a kereslet, hiszen nem véletlenül nincsenek már forgalomban.

100
Google Scholar szolgáltatás:
A Google tudományos keresője, amely különféle témájú és formájú tudományos publikációk között keres. 2004. november 18-án indult, mára szinte minden online elérhető referált folyóiratban keres, kivéve a legnagyobb tudományos kiadó, az Elsevier által kiadottakat. 2006. február 20-ától a magyar könyvtárakban is keres a MOKKA-n keresztül.

101
A szolgáltatás keresőalgoritmusa hasonló a hagyományos Google keresőéhez, de nem a hiperlinkeket használja fel egy-egy publikáció fontosságának meghatározásához, hanem azt, hogy más cikkek milyen gyakran hivatkoznak rá. A keresések a publikációk teljes szövegében történnek. Szűkíthetők szerző, év vagy megjelenési hely alapján.

102
A találatoknál a kereső megjeleníti a cím és az esetleges online elérhetőség mellett azt is, hogy milyen más tudományos munkák hivatkoznak rá, és milyen könyvtárakban található meg. Utóbbihoz a WorldCat adatbázist, és egy saját, Library Links nevű szolgáltatást használ. A tudóstársadalom részéről már több bírálat érte a Google Scholart, mert a neten eddig a tudományos szakirodalomnak csak kisebb része jelent meg, így a kereső a hagyományos szakirodalmat értelemszerűen nem figyeli. Forrás:

104
3. A keresők működése A világháló heterogén szintaktikájú és szemantikájú, nem ellenőrzött tartalmú dokumentumok halmaza. Az internetes keresés alapvetően eltér egy lassan változó, kontrollált dokumentumgyűjteményben való kereséstől. A keresőknek meg kell találniuk a releváns webes tartalmaknak azt a halmazát, amelyek jól hasznosíthatók a felhasználók számára. Nem pedig egy hagyományos dokumentumgyűjteményből kell kiválogatniuk a keresőkérdésre pontosan illeszkedő dokumentumokat.

105
Kereséskor a legjobb találatoknak egyéb jellemzőik is vannak (frissítési gyakoriság, minőség, hivatkozások száma, népszerűség stb.), amit a keresőknek szintén figyelembe kell venniük és nem elegendő csupán a keresésnek pontosan megfelelő dokumentumokat szolgáltatniuk. Egy-egy keresésre különböző válaszokat adhatunk, ezért nagyon lényeges, hogy mely találatokat jelenítjük meg elsőként a felhasználóknak.

106
3.1. Keresőszolgáltatások előretörése az Interneten
1994-ben jelentek meg az első internetes keresők. A keresőknek nagy része kutatási programként indult. A kezdeti időszakban néhány kezdeményezés kudarcba fulladt, mert a vállalt feladat meghaladta a korlátozott emberi és technikai erőforrásokat. A fennmaradt keresőszolgáltatásokat főként vállalati tőkéből, reklámokból, tőkebefektetésekből, illetve kutatási kezdeményezésekből finanszírozták.

107
1996-ra már a különböző folyóiratok, üzleti és napilapok is komoly figyelmet szenteltek a keresőknek. Megnövekedett a keresésre specializálódó szoftvertermékek száma, pl. webes katalógusok, metakeresők, szakterületi szolgáltatások, kereső ágensek és “push” szolgáltatások jelentek meg.

108
3.2. Egy kereső alkotóelemei és azok feladatai

109
A keresők első feladata az oldalak meglátogatása és begyűjtése, amit speciális szoftverek, ún. keresőrobotok (crawlers, web robots, bots, web spiders) segítségével valósítanak meg. Ezek a programok folyamatosan és bizonyos időközönként átfésülik a webet. Egy keresőrobot választhat egy népszerű, de megbízható oldalt kiindulópontjául, illetve dolgozhat egy korábbi, meglévő adatbázis alapján is. A robotnak le kell töltenie az általa meglátogatott oldalt, és át kell adnia azt az indexelőnek. Ezután az oldalon lévő linkeket nyomon követve ugyanígy kell eljárnia a hivatkozott oldalakkal is.

110
Számos esetben bizonyos időkülönbség jelentkezik a begyűjtés és az indexelés, valamint az eredmény keresőbe történő beépülése között. Ezért az oldalak begyűjtését és indexelését két, párhuzamosan zajló feladatnak kell tekintenünk. A keresőrobotok tehát nem végeznek semmilyen elemzést a meglátogatott dokumentumon, hanem csak nyomon követik a hivatkozásokat és letöltik a felfedezett oldalakat. Látszólag a robotok nagyon hasonló módon működnek, azonban jelentős különbségek figyelhetők meg a viselkedésükben.

111
Egy robot számára fontos szempont, hogy mely hivatkozásokat kövesse nyomon, és mely oldalakat keresse fel, valamint lényeges kérdés, hogy milyen gyakran végezze el az oldalak begyűjtését. Egy keresőrendszer általában több robotot alkalmaz a weblapok begyűjtésére. Emiatt a hálózati forgalom megnövekszik. A robotok igyekeznek nem folyamatosan leterhelni egy szervert különböző kérésekkel, hanem időben elosztva küldik neki a kéréseket.

112
A robotok az oldalak begyűjtése közben egy prioritási sort használnak, amelyben a még meg nem látogatott oldalak címei szerepelnek fontossági sorrendben. A sor elejéről kiveszik a címeket és a hozzájuk tartozó oldalakat, letöltik és kigyűjtik belőlük a hivatkozásokat. A felderített linkekről a robotok eldöntik, hogy melyiket kell követniük, ezeket beteszik a prioritási sorba, a többit pedig elhagyják. A begyűjtés addig tart, amíg a helyi erőforrások, mint például a tárolókapacitás, el nem fogynak.

113
A webszervereknek módjukban áll a robotok számára megtiltani egyes oldalak begyűjtését, az oldalon lévő hivatkozások követését és az oldal archiválását. Ezt a Robot Kizárási Szabványban (Robot Exclusion Standard) megszabott módon tehetik meg. Ha egy weblapra nem hivatkozik egy másik oldal, akkor a keresőrobot nem fogja megtalálni azt. Ezért az új honlapokat tanácsos manuálisan regisztrálnunk az egyes keresőknél, amelyek így indexelni tudják azokat.

114
A keresőrobotok által begyűjtött oldalak az adattárba kerülnek (repository).
Az adattár elsődleges feladata az oldalak egyenkénti tömörítése és szekvenciális tárolása. Ezenkívül a rendszer nyilvántartja egy állományban a dokumentumok pontos elhelyezkedését. Az adattár további feladata a meglévő, begyűjtött dokumentumok frissítése is. Ha pl. módosul egy oldal, akkor annak az új metaadatait el kell helyezni az adatbázisban, a régit pedig törölni kell.

115
A keresők másik lényeges összetevője az indexelő (indexer).
Fő feladata az adatbázisban lévő meglátogatott oldalak elemzése és az indexelendő kifejezések belőlük történő kigyűjtése. Az indexelő tulajdonképpen az adattárra támaszkodik. A feldolgozás elején két problémával találkozik az indexelő: A weboldalak elemzése összetett feladat. Ezt nem csupán a dokumentumok heterogén kialakítása okozza, hanem az egy-egy adott formátum esetén előforduló hibák is, pl. szintaktikai hibák a HTML dokumentumokban.

116
2. Az indexelőnek szét kell tudnia választani a fontos és a kevésbé fontos kifejezéseket egy dokumentumban. Erre egy lehetséges megoldás, hogy figyelembe vesszük a szavak gyakoriságát és eldobjuk a legkisebb, valamint a legnagyobb gyakoriságú szavakat. Az előbbieket azért, mert nem lehetnek fontosak, hogyha csak néhány alkalommal fordulnak elő, az utóbbiakról nagy valószínűséggel állítható, hogy felesleges szavak a dokumentumban. Feltételezzük, hogy a töltelék- és egyéb szavak eloszlása eltérő egy dokumentumban.

117
A gyakorlatban elterjedt egy másik megközelítés is
A gyakorlatban elterjedt egy másik megközelítés is. Ebben nyelvenként létrehoznak egy ún. tiltott szó (stopwords) listát, amely magába foglalja a tartalmi szempontból feleslegesnek tekintett szavakat. Az ilyen lista meggátolja a névelők, a kötőszavak és más, szinte minden dokumentumban előforduló szavak indexelését. Tehát ez a módszer rendkívül gyors, egyszerű és könnyen használható.
 listát, amely magába foglalja a tartalmi szempontból feleslegesnek tekintett szavakat. Az ilyen lista meggátolja a névelők, a kötőszavak és más, szinte minden dokumentumban előforduló szavak indexelését. Tehát ez a módszer rendkívül gyors, egyszerű és könnyen használható.")
118
A megmaradt releváns kifejezéseket bizonyos jellemzőivel együtt gyűjti ki a dokumentumból az indexelő. Fontos jellemzőnek minősül a szó előfordulásának helye, mint pl. az oldal címe, a metaelemek, az oldalon belüli pozíció. Ezenkívül az indexelő létrehoz egy indexet, amely minden releváns kifejezéshez hozzákapcsolja az őt tartalmazó URL-ek listáját. A kigyűjtött indexelendő kifejezéseket és jellemzőiket a tényleges keresés és sorrendezés során veszik alapul a keresők.

119
3.3. A találatok sorrendezése, rangsorolása
A keresőknek jelentős alkotóeleme a Rangsoroló modul, amely egy adott keresésre automatikusan sorrendezi a találatokat fontosság szerint. Az indexelt adatmennyiség megnövekedésével vált egyre fontosabb feladattá a találatok pontos sorrendezése. Mivel a felhasználók csak az első találatot képesek áttekinteni egy adott keresőkérdésre, ezért rendkívüli fontossággal bír, hogy a kereső milyen találatokat jelenít meg a találati lista elején.

120
A találatrangsorolás fő elvei a következők:
a keresőkifejezés helyének vizsgálata a dokumentumban: A keresők nagyon gyakran előnyben részesítik azokat az oldalakat, amelyeknek a címében is megtalálható a keresendő kifejezés. A találatok sorrendezésénél azt is figyelembe vehetik, hogy a dokumentum mely részében jelenik meg először a keresőkifejezés. Itt alapelv, hogy a weblap szempontjából releváns kifejezések nagy valószínűséggel fordulnak elő már a bevezetésben is, vagy legalábbis a dokumentum elején.

121
Egyes keresők az oldal fontosságának meghatározásához szemügyre veszik a fontméretet is, következtetésekre jutnak a szavak közti távolságokból is, valamint elemzik a HTML-metaelemeket. A metaadatok segítségével közölhetjük honlapunk tartalmának összefoglalóját, valamint az oldalunkra vonatkozó kulcsszavakat. Ezeket a háttér-információkat is hasznosíthatják a keresők a rangsorolás, valamint a keresés közben is.

122
II. a keresőkifejezések előfordulási gyakorisága:
Itt azzal a feltételezéssel élhetünk, ha egy dokumentumban egy bizonyos kifejezés gyakran fordul elő, akkor fontos a téma szempontjából. Ebben az esetben természetesen kivételt képeznek a tiltott szavak listáján lévő kifejezések. Lényeges, hogy ne csak az egyes szavak előfordulási gyakoriságát kövessük nyomon, hanem az adott szóösszetételekét is.

123
A keresők sokszor tanulmányozzák felhasználóik reakcióit is
A keresők sokszor tanulmányozzák felhasználóik reakcióit is. Ha a felhasználók többsége nem az első találatra kattint a szolgáltatott találatlistában, akkor nagy a valószínűsége annak, hogy rossz a találatok rangsorolása és nem az első helyen szereplő oldal a legrelevánsabb. Ezek a felsorolt sorrendezési szempontok sajnos lehetővé teszik, hogy könnyedén befolyásoljuk a találatok rangsorolását.

124
Megfigyelhető az a tendencia, hogy a könnyedén manipulálható rangsorolási szempontok egyre inkább háttérbe kerülnek és csökken a súlyuk a végső sorrend kialakításában. Helyettük pedig olyan kritériumokra helyeződik a hangsúly, amelyeket nehezebb befolyásolni. Itt megemlíthetők pl. olyan módszerek, amelyek az oldalak közti linkstruktúrát veszik figyelembe (ld. PageRank algoritmus).
.")
125
A találatok rangsorolásánál kényes etikai kérdésként merülhet fel, hogy a kereső jó pénzért nem árul-e kulcsszavakat a cégek számára. A megvásárolt kulcsszóért cserébe az adott cég webhelye az első 10 találat között szerepelhet. Ez nem jellemző a nagyobb keresőkre, azonban a felhasználói kulcsszavakhoz kapcsolódó reklámok eladása széles körben elterjedt gyakorlat. Ezekben az esetekben a szoftverfejlesztők úgy változtatják meg a keresők relevancia rangsorolási algoritmusát, hogy az eladott kulcsszó a felhasználót rögtön vezesse arra a webhelyre, amely korábban megvásárolta azt.

126
Egyes keresők a linkhez tartozó szöveget nem a linket tartalmazó, hanem a link által hivatkozott oldalhoz tartozónak veszik. Az ilyen típusú linket horgonynak hívjuk, amit bizonyos keresők a találatok rangsorolásakor használnak fel. A Google együttkezeli a linkek szövegét azokkal a weboldalakkal, amelyekre ténylegesen hivatkoznak. Ennek a módszernek számos előnye van: a linkek sok esetben pontosabb leírást nyújtanak a hivatkozott oldalakról, mint maguk az oldalak. A linkek szövegének hatékony felhasználása technikailag nehezen oldható meg, mert az nagy mennyiségű adat feldolgozását igényli.

127
Az Internet megjelenése előtt az egyik legismertebb és sokat használt információ-visszakeresési technika a Vektortér Modell volt, ami azonban közvetlenül nem használható internetes kereséskor. Ennek oka egyrészt a világháló mérete és annak állandóan változó tartalma. Másrészt pedig az a mindennapos gyakorlat, hogy a keresőket használók többsége nem definiálja pontosan a keresőkérdést, ez pedig sokszor rossz találatokat eredményez a Vektortér Modell esetében.

128
A Google nem a Vektortér Modellt alkalmazza, hanem az ún
A Google nem a Vektortér Modellt alkalmazza, hanem az ún. Boole modellt és egy lexikális keresőt épít. A Google döntése ellenére számos próbálkozás irányul arra, hogy a Vektortér Modellt webes környezetben is használható változattá fejlesszék. Sokan vélekednek úgy, hogy a Google népszerűségét annak köszönheti, hogy a találatokat minőségileg jobban rangsorolja, mint a többi kereső.

129
3.4. A Google PageRank algoritmusa
A PageRank (PR) egy valós szám, ami egy adott oldal fontosságát tükrözi. A Google kereső a PageRank algoritmust alkalmazza az általa indexelt oldalak fontosságának meghatározásához, amit figyelembe vesz a rangsorolás során. A Google más egyéb szempontokat is felhasznál a sorrend kialakításakor, amelyek közül csak egy a PageRank érték, azonban ez az egyik legfontosabb.
 egy valós szám, ami egy adott oldal fontosságát tükrözi. A Google kereső a PageRank algoritmust alkalmazza az általa indexelt oldalak fontosságának meghatározásához, amit figyelembe vesz a rangsorolás során. A Google más egyéb szempontokat is felhasznál a sorrend kialakításakor, amelyek közül csak egy a PageRank érték, azonban ez az egyik legfontosabb.")
130
Az algoritmus alapgondolata, hogy amikor egy oldal hivatkozik egy másik weblapra, akkor a forrásweboldal tulajdonképpen ajánlja a hivatkozott weblapot. Tehát az oldal létrehozója azért tüntette fel a linket az oldalán, mert a másik lapot valamilyen szempontból fontosnak tekintette. Azt is figyelembe kell vennünk, hogy a hivatkozó oldal mennyire fontos, mert egy fontos oldalnak többet ér a hivatkozása. Eredményül egy rekurzív algoritmust kapunk, ami azt fejezi ki, hogy egy oldal fontos, ha mérvadó oldalak hivatkoznak rá.

131
Ez a modell természetesen vitatható, hiszen lehetséges, hogy csak rossz példáként hozunk fel egyes weboldalakat és nem arra szeretnénk velük célozni, hogy azok értékes oldalak. A gyakorlat azonban az eredeti alapötlet sikerességét igazolja, hiszen kevésbé meghatározóak ez utóbbi linkek az Interneten. Az alapalgoritmust 1998-ban közölték először. Nagy valószínűséggel feltételezhetjük, hogy a Google most már egy másik változatát használja az itt tárgyaltaknak, amiről azonban nem tájékoztatják a nyilvánosságot.

132
Ez a rekurzív egyenlet a weboldal fontosságára egy megközelítőleges becslést nyújt.
Érdekesség, hogy a szerzők egyik cikkükben pontatlanul adták meg az egyenlet első tagját és az így terjedt el a szakmában széles körben.

133
Az egyenlet az A oldal PageRank értékét határozza meg.
Az egyenletben t1...tn jelöli azokat az oldalakat, amelyek A oldalra mutatnak. PR(ti) fejezi ki az i. ilyen oldal PageRank értékét, azaz annak a fontosságát. A d paramétert egy skálázó faktornak tekintjük, aminek értéke 0 és 1 közé eshet. A d értékét a szerzők 0,85-nek határozták meg. C-vel jelöljük az egy oldalon lévő összes kimenő hivatkozás darabszámát.
 fejezi ki az i. ilyen oldal PageRank értékét, azaz annak a fontosságát. A d paramétert egy skálázó faktornak tekintjük, aminek értéke 0 és 1 közé eshet. A d értékét a szerzők 0,85-nek határozták meg. C-vel jelöljük az egy oldalon lévő összes kimenő hivatkozás darabszámát.")
134
Pl. ha C(ti) értékét 24-nek vesszük, az azt jelenti, hogy az i
Pl. ha C(ti) értékét 24-nek vesszük, az azt jelenti, hogy az i. oldal összesen 24 darab kimenő hivatkozást tartalmaz, amelyek közül egy biztosan az A oldalra hivatkozik. Az eredeti algoritmus nem számol azzal az esettel, hogy mi történik akkor, hogyha egy oldalról több link is hivatkozik egy másik oldalra.
 értékét 24-nek vesszük, az azt jelenti, hogy az i. oldal összesen 24 darab kimenő hivatkozást tartalmaz, amelyek közül egy biztosan az A oldalra hivatkozik. Az eredeti algoritmus nem számol azzal az esettel, hogy mi történik akkor, hogyha egy oldalról több link is hivatkozik egy másik oldalra.")
135
Az egyenlet tehát a következőt jelenti:
az A oldal az első olyan oldaltól, amely hivatkozik rá, PR(t1)/C(t1)-nyi szavazatot kap, azaz a t1-es oldal egyenletesen elosztja a saját fontosságát a kimenő hivatkozásai között. Ha t1 oldalon egyetlen kimenő link található, akkor A megkapja a teljes PR(t1) értéket, ha három, akkor csak t1 fontosságának a harmadát stb. Ugyanezt az elvet követjük az összes többi olyan oldal esetén, ahonnan találunk hivatkozást A-ra. Ezután ezeket a fontosságokat összeadjuk és megkapjuk A oldal fontosságát.
/C(t1)-nyi szavazatot kap, azaz a t1-es oldal egyenletesen elosztja a saját fontosságát a kimenő hivatkozásai között. Ha t1 oldalon egyetlen kimenő link található, akkor A megkapja a teljes PR(t1) értéket, ha három, akkor csak t1 fontosságának a harmadát stb. Ugyanezt az elvet követjük az összes többi olyan oldal esetén, ahonnan találunk hivatkozást A-ra. Ezután ezeket a fontosságokat összeadjuk és megkapjuk A oldal fontosságát.")
136
Ebből tehát az következik számunkra, hogy kedvezőbb PR értéket kapunk, ha egy alacsonyabb PR értékű lap mutat ránk, mintha egy magasabb, amennyiben az alacsonyabb fontosságú lapon nem sok kimenő link található. Egy dolgot azonban biztosan kijelenthetünk, ha oldalunkra több oldal hivatkozik, nem számít, hogy milyen rangos oldalak, valamilyen mértékben nőni fog a fontosságunk.

137
A d faktornak köszönhetően egy bizonyos oldal nem a teljes fontosságát osztja szét a kimenő linkjei között, hanem annak csak a 85%-át. Ahhoz, hogy megértsük ezt az összefüggést, szükségünk van egyrészt a javított PageRank egyenletre és a PageRank algoritmus egy újabb jelentésének bemutatására. A javított PageRank egyenlet a következőképpen adható meg, ahol N az összes indexelt weblap számát jelenti.

138
A PageRank algoritmus egy olyan modellnek is tekinthető, amely a „véletlen szörfölő” viselkedését tükrözi. Egy ilyen felhasználó véletlenszerűen elindul egy weboldalról és a hivatkozásokra véletlenszerűen kattintva folyamatosan előrehalad. Nem is figyeli meg, hogy hova kattint, hanem egyenletes eloszlás szerint választ a meglévő hivatkozások közül. Ezzel magyarázható az, hogy a PageRank algoritmus a kimenő linkek számával elosztja egy bizonyos oldal fontosságát. Mindez addig tart, amíg szörfölőnk meg nem unja a kattintgatást és egy másik véletlenszerűen kiválasztott weboldalon nem indul el.

139
Ez az egyenlet egy valószínűségi eloszlást határoz meg, ahol egy-egy weboldal PageRank értéke egy valószínűségnek (0 és 1 közötti valós szám) felel meg. Ebben a modellben az összes weboldal PageRank értékeinek összege maximum 1 lehet. Ez a megállapítás csak abban az esetben igaz, ha a felhasználónk egy adott oldalon mindig talál legalább egy hivatkozást, amelyen továbbhaladhat.

140
Ha webszájtunk olyan oldalt tartalmaz, amelyre ugyan mutat link, de belőle nem indul kimenő hivatkozás, akkor a szájt nem veszi fel a maximális PageRank értéket. Lógó (dangling) oldalnak hívjuk az ilyen oldalakat. A Google figyelmen kívül hagyja a lógó oldalakat, mert azok ellentmondanak a PageRank algoritmus által használt „véletlen szörfölő” modellnek. A megmaradt linkstruktúrában kiszámolja a pontos PR értékeket. Ezután fokozatosan visszahelyezi a lógó oldalakat és kiszámolja azok fontosságát is a már kiszámított PR értékek alapján.

141
A Google nem csupán a linkstruktúrát elemzi, hanem egyéb tényezőket is figyelembe vesz az oldalak rangsorolásakor. Pl. sokszor negatívan értékeli azt, ha bizonyos, megjelölt oldalakra mutató hivatkozásokat tüntetünk fel az oldalunkon. Nyomon követi azt is, hogy az oldalra történő hivatkozások ugyanabból a domainből, földrajzi területről származnak-e. Tehát a rangsorolás szempontjából többet ér az, ha valaki „független” hivatkozik ránk, mint ha egy „ismerős” szavaz nekünk bizalmat.

142
A PageRank algoritmus manipulálása
Az sokkal nehezebb feladat, mint a szöveges dokumentumok sorrendjének befolyásolása. Ennek oka, hogy a web nagyobb részét kell módosítanunk, valamint hivatkozások sűrű szövevényével kell ellátnunk. A Google által alkalmazott rangsorolási módszer ismert a nagy nyilvánosság számára, ezért a világban számos cég specializálódott különféle manipulatív megoldások használatára, amelyekkel a saját forgalmukat tudják indokolatlanul befolyásolni.

143
A cégeknek ezt a törekvését finomabb változatban “kereső optimalizálásnak” hívjuk, erősebb változatban pedig “hivatkozás spam-nek”. A PageRank támadásának egyik közkedvelt módszere a linkfarmok létrehozása. Ilyenkor nagyszámú és sok szerverre kiterjedő, részben értékes oldalak másolatát, részben számítógéppel előállított oldalakat tartalmazó oldalcsoportot állítanak elő. Itt az oldalak mindegyike a céloldalra hivatkozik, ezáltal magas fontosságot tulajdonítanak annak.

144
3.5. Problémák az internetes kereséssel és a megoldási kísérletek
A kereséssel kapcsolatos problémák öt fő csoportba sorolhatók: Az Internet hatalmas mérete, ami nemcsak a keresést, hanem az oldalak begyűjtését is nagymértékben befolyásolja. A weblapok meglátogatása és feltérképezése időigényes feladatot jelent még a legjobb keresők számára is. 2. Az utolsó begyűjtés óta eltelt idő alatt az Internet tartalma és szerkezete gyorsan megváltozik, ami további nehézségeket eredményez.

145
3. A keresőrendszerek számára általában elérhetetlenek azok az Interneten meglévő tartalmak, amelyek a mély web körébe sorolhatók. 4. A keresőrobotok nem gyűjtik be a dinamikus weblapokra mutató hivatkozásokat. Az internetes keresők nem a felkutatható dokumentumok és a keresőkérdés jelentésével foglalkoznak, hanem csupán a szöveges alakkal. A keresést indítók többsége, egyes források szerint háromnegyede valamilyen okból nem jut el a számára szükséges információig. Az online keresések szegmensében nő a nem angol nyelvű keresések jelentősége és száma, mert a web használóinak több mint 60%-a nem az angol nyelvet használja kereséskor.

146
Egy 2007-es amerikai felmérés néhány lényeges megállapítása a következő:
– 72.3 percent of Americans experience “search engine fatigue” (either “always,” “usually,” or “sometimes”) when researching a topic on the Internet. – 65.4 percent of Americans say they’ve spent two or more hours in a single sitting searching for specific information on search engines. – More than three out of four (75.1 percent) of those who experience search engine fatigue report getting up and physically leaving their computer without the information they were seeking – either “always,” “usually” or “sometimes.” Forrás: Report: 7 Out Of 10 Americans Experience ‘Search Engine Fatigue’
 when researching a topic on the Internet. – 65.4 percent of Americans say they’ve spent two or more hours in a single sitting searching for specific information on search engines. – More than three out of four (75.1 percent) of those who experience search engine fatigue report getting up and physically leaving their computer without the information they were seeking – either always, usually or sometimes. Forrás: Report: 7 Out Of 10 Americans Experience ‘Search Engine Fatigue’")
147
A keresési problémák megoldásai:
Az óriási adattömeg visszakeresését oldják meg a metakeresők, amelyek párhuzamosan más keresőkkel kerestetnek. Így azok az Internet nagyobb részét képesek átfésülni. Növelik a találati esélyünket az ismeretlen témák esetében, valamint átfogóbb képet nyújtanak számunkra a weben fellelhető információkról egy adott témában.

148
A gyorsan változó tartalom kezelésére használható az oldalak begyűjtésének fókuszált módja (focused crawling). A módszer lényege, hogy nem követünk minden hivatkozást, hanem valamilyen szempontrendszer szerint egy bizonyos területhez kapcsolódó oldalakra szűkítjük a keresési teret, pl. nevezetes hírportálok meglátogatására. A fókuszált begyűjtést végző robotokkal kialakíthatunk egy-egy adott szakterületre specializálódott keresőt is, pl. orvosi tartalmak indexelésére alkalmas szolgáltatást.

149
A mély web kezelését úgy támogathatjuk, ha a keresők számára is elérhető metainformációkat közlünk az adatbázisok tartalmáról, valamint különböző csatoló programokat hozunk létre a nem szöveges állományokhoz (PDF, Excel, JPG stb.). 4. A keresőrobotok nem követik a dinamikus weblapokra mutató hivatkozásokat, ezáltal azok sok információhoz nem férnek hozzá. Ennek oka, hogy a dinamikus linkek gyakran hoznak létre hatalmas vagy esetleg végtelen keresési tereket. Ezeket keresőcsapdának (spider trap) hívjuk, amelyeket a keresőrobotok megpróbálnak elkerülni.
 hívjuk, amelyeket a keresőrobotok megpróbálnak elkerülni.")
150
Gyakran előfordul, hogy bizonyos szerverek megkísérlik álcázni magukat és egy keresőrobotnak eltérő tartalmat nyújtanak, mint pl. egy böngészőnek. Napjainkban számos technika terjedt el a dinamikus oldalak indexelésének támogatására, amelyeknek lényege, hogy elhitetjük a keresőrobotokkal, hogy statikus hivatkozást követnek.

151
Az internetes keresők nem a fellelhető dokumentumok és a keresőkérdés jelentésével foglalkoznak, hanem csak a szöveges alakkal. A nyelvi problémákat az okozza, hogy a mai eszközökkel történő információ-visszakeresés túlságosan a letárolt szöveges információ tényleges alakjára épül. Ennek egyik következménye, hogy a nem szöveges dokumentumok által tárolt információk nem kereshetők vissza automatikusan.

152
További hiányosságként kiemelhetjük azt is, hogy a keresőrendszerek nem ismerik a fogalmak jelentését és a fogalmak közötti kapcsolatokat, ezért nem képesek különféle következtetések levonására. Ezt a problémát a szemantikus keresők orvosolják hatékonyan. Az internetes keresőknek létezik egy másik fajtája, a webes katalógusok, amelyek emberek által összegyűjtött oldalakat tesznek visszakereshetővé. Ezek a katalógusok eredményesen oldják meg a jelentés, azaz a szemantika megragadását, ami az oldalak begyűjtését és indexelését végző emberek feladata.

153
Ezenkívül meg kell említenünk a kérdésátalakító keresőket is, amelyek szintén a jelentés megragadására törekednek. Feladatuk, hogy megpróbálják jobban értelmezni a feltett keresőkérdést és azt úgy átalakítani, hogy az új keresőkérdés már jobb találatokat eredményezzen. Egy ilyen átalakításhoz a keresőknek rendelkezniük kell bizonyos háttértudással, amely valamilyen matematikai formalizmussal írható le.

154
A szemantikus web irányzat hatékonyan oldja meg a jelentéssel kapcsolatos problémakört, amelynek fő célja, hogy jelentést vigyen a webre. Ezt úgy teszi lehetővé, hogy a webes tartalmakhoz szabványos formában metainformációt rendel és biztosítja számunkra, hogy ezen metainformációk alapján következtetéseket vonjunk le. Jelenleg a metainformációk ugyanolyan heterogén formában fordulnak elő, mint maguk a webes dokumentumok. Ezért a szemantikus webnek elsődlegesen a metainformációk és a következtetéshez szükséges háttértudás egységes és feldolgozható alakban történő leírására kell törekednie.

155
Számos nemzetközi tudományos fórum támogatja a nem angol nyelvű keresések során felmerülő nehézségek elemzését, valamint az új módszertani megoldások és eszközök fejlesztését. Pl. SIGIR 2007 Workshop on Non-English Queries, 2nd International ACM Workshop: Improving Non-English Web Searching (iNEWS08). Ilyen vonatkozású további fontos események, programok sorát részletezi a következő forrás:
. Ilyen vonatkozású további fontos események, programok sorát részletezi a következő forrás:")
158
4. Keresőmarketing Hazánkban a keresőmarketing kifejezés leginkább az online hirdetések célzott elhelyezését jelenti a keresőgépek találati oldalain, figyelemfelkeltő helyeken. Keresőmarketing minden olyan tervezett tevékenység, ahol különböző keresőket eszközként használva látogatókat toborzunk weboldalunkra.

159
Másik meghatározása szerint:
Azokat a módszereket, technikákat, melyek révén növelhető a keresőoldalak felől bejövő forgalom, összefoglalva keresőmarketingnek (search engine marketing = SEM) nevezzük. A SEM egyik leghatékonyabb és legolcsóbb, tulajdonképpen ingyenes fajtája a keresőoptimalizálás (Search Engine Optimization - SEO).
 nevezzük. A SEM egyik leghatékonyabb és legolcsóbb, tulajdonképpen ingyenes fajtája a keresőoptimalizálás (Search Engine Optimization - SEO).")
160
A keresőoptimalizálás, illetve keresőmarketing az a tevékenység, melynek célja, hogy egy weboldalt a webes keresők megtaláljanak, és a találati listában minél előrébb mutassanak. A keresőoptimalizálás egyik szakmai ága az ún. kiemelt keresők optimalizálása. Ezek között a Google-optimalizálás az egyik legmeghatározóbb irányzat, mert a Google piacvezető szerepéből adódóan a felhasználók jelentős számban használják és üzleti érték, hogy hol található a weboldalunk a Google-ban.

161
Ezt az értéket azzal éri el a weboldal tulajdonosa, ha igényes weboldalát rendszeresen karbantartja, és odafigyel arra, hogy az ún. keresőtalálatok nagyszámú kulcsszókészletre legyenek optimalizálva. A keresőmarketing tevékenység alapvetően négy részből áll: A saját oldalunk optimalizálása keresőkre. Weboldalunk regisztrációja keresőkbe, katalógusokba és linkgyűjteményekbe. Fizetett találatok – reklámkampányok a keresőkben. További linkstratégiák a partner weboldalakkal.

162
Miért fontos az, hogy az Interneten látható, illetve megtalálható legyen a vállalat vagy a márka weboldala? Azért, mert ha rossz helyen tennék, akkor senki nem tudna róluk, vagy csak azok, akik pont arra járnak (zsákutca effektus). Ezért a weboldalunkat regisztrálni kell nagyobb keresőkbe, katalógusokba és linkgyűjteményekbe, vagy összelinkelni nagyobb weboldalakkal, hogy a termékünk, szolgáltatásunk iránt érdeklődők, azaz az ő látogatóik egy része megjelenjen majd a mi oldalunkon is.
. Ezért a weboldalunkat regisztrálni kell nagyobb keresőkbe, katalógusokba és linkgyűjteményekbe, vagy összelinkelni nagyobb weboldalakkal, hogy a termékünk, szolgáltatásunk iránt érdeklődők, azaz az ő látogatóik egy része megjelenjen majd a mi oldalunkon is.")
163
4.1. Az internetes láthatóság előnyei: a költségek csökkentése,
a weboldal-látogatottság növekedése, a költségek csökkentése, a befektetések megtérülése.

164
A weboldal-látogatottság növelése
Egy, a keresőeszközökre optimalizált website folyamatos és ingyenes látogatókat biztosít. Internet böngészés közben az emberek sok terméket és szolgáltatást keresnek. Ezt szavak vagy szócsoportok felhasználásával teszik, megpróbálva körülírni a keresett fogalmat. Ha pedig a website-unk nem található meg ezekre a szavakra, akkor a potenciális vásárló is elmegy a versenytárshoz.

165
Persze lehet szó olyan látogatókról, akik nem vásárolnak, hanem csak a témában érdekeltek. Szükségünk van rájuk azonban akkor is, ha a website-unkon nem értékesítünk, csupán a vállalatunk népszerűségét szeretnénk növelni.

166
A költségek csökkentése:
Nagy cégek esetében jelentősen csökkentheti a promóciós költségeket az a weboldal, amely keresőeszközökre van optimalizálva. Ha pl. a website-látogatottság növelése a cél, akkor nem egy rövid, kampányszerű növekedést várunk el, mivel jelenleg az a probléma, hogy a website-unkat kevesen látogatják. A látogatottságnövelés alatt pedig folyamatos és állandó forgalomnövekedést várunk el, nem pedig néhány hetes emelkedést, amit a kampányok általában eredményeznek.

167
Ha a reklámkampány célja a márkaismeretség növelése (branding), akkor egyértelmű, hogy csak a keresőeszközökből érkezett forgalom nem elegendő, hanem szükség van nagyobb reklámmegjelenésre ahhoz, hogy a márkánkat többen ismerjék meg. Vannak olyan esetek, amikor nincs pénz reklámkampányra és a weboldal-tulajdonos csak a keresőkből érkező forgalomra van ráutalva.

168
A befektetések megtérülése:
Keveset lehet hallani és olvasni arról, hogy mi történik az online reklámra való rákattintás után. A keresőmarketing pl. olyan lehetőségeket nyújt számunkra, ahol a reklámra kiadott pénz mozgása teljesen transzparenssé válik (médiaelméletben a jelentése: átlátszó).
.")
169
Egy keresőben úgy is hirdethetünk, hogy csak az általunk megadott kulcsszavakra jelenjen meg a reklámunk, a fizetés pedig az ezekre a szavakra megjelent találati oldalakból és a hirdetésünkre való rákattintásból adódik össze. A Google keresőben úgy is lehet hirdetni, hogy csak a kattintásért fizessünk, illetve azt is meghatározhatjuk, hogy mekkora összeget fogunk elkölteni. Tehát licit típusú hirdetési helyeket kínál az ügyfeleinek.

170
A Google.com-ban pl. a találatoknál, a jobb oldalon látni lehet kis szövegdobozokat, amelyeknek a rangsorolása licittől függ. Ezek az ún. AdWords hirdetési találatok. Ha valaki többet fizet a legfelső hirdetőnél, és a hirdetésére sokan kattintanak , akkor elfoglalja a vezető helyét. A Google Adwords a Google hirdetési szolgáltatása, melyet regisztráció és díjfizetés ellenében vehet igénybe a felhasználó. A rendszert bárki használhatja, ha betartja a szabályait.

171
4.2. Az online reklám és a keresőmar- keting
A keresőmarketing leginkább a direkt reklámeszközök közé sorolható, amely egyben interaktív és márkázási jellemzőkkel rendelkezik. A következőkben megismerkedünk a keresőmarketing reklámlehetőségeivel, a kampánytervezési, az optimalizálási és az utóértékelési folyamatokkal.

172
A keresőmarketing reklámlehetőségei
A keresők üzemeltetői gyorsan rájöttek arra, hogy a napi sok százezer felhasználói rákeresés reklámértékkel bír. Az értéket csak növelte a páratlan célzási lehetőség, ami miatt nem kellett sokat várni az első hirdetőkre sem.

173
Különböző keresőeszközök (keresők, katalógusok, linkgyűjtemények) különböző reklámeszközöket kezdtek kínálni, különböző árazással. Az ügyfelek jobb kiszolgálása érdekében színre léptek az ügynökségek és a speciális tanácsadócégek, melyek segítségével könnyebben át lehetett látni a keresőmarketinges piacot.

174
Reklámformátumok és árstruktúrák:
Ha reklámformátumokról van szó, akkor a keresőeszközök általában 5 lehetőséget kínálnak. Bannerek és boxok: reklámcsíkok, melyek figyelemfelkeltő helyen jelennek meg, amikor a felhasználó begépeli az adott kulcsszót vagy szócsoportot. Bár minden más típusú website-on az átlagos piaci kattintási érték 0,5% körül mozog, addig a keresőkben ez az érték sokkal magasabb. Néha eléri az 5%-ot vagy akár a 10%-ot is.

175
Szponzorált link: katalógusok és linkgyűjtemények egyik leghatásosabb reklámformátuma exkluzív vagy kiemelt dobozokban található. Nagyobb értékkel bír, mint az előbb említett hirdetési csík. A sikerének titka az, hogy a felhasználó sokszor a tartalom részeként tekint a szponzorált linkre, és hitelesebbnek veszi azt, mint egy egyszerű reklámot. A hirdetési csíkok egyértelműen reklámra utalnak, míg a szponzorált link inkább PR jelleggel bír. A szponzorált link árazása általában fix alapú (link/hét v. hónap).
.")
176
Szponzorált szó: katalógusok és linkgyűjtemények rendelkeznek saját, belső keresőkkel. Az átlagos kattintási arányok pedig sokszor 10% felettiek. Hazai keresőeszközök költséghatékony áron kínálnak ilyen lehetőségeket. A szponzorált szó árazása általában fix alapú (per szó és per év).
.")
177
Nulladik fizetett találat:
kulcsszavas reklámlehetőség, mely szerényen kiemelt 0-dik találatot jelent, általában más színnel, melynek a keresőiparban a legnagyobb hatása van. A Google-ban ez a reklámtípus jelenleg havi dollárért (kb. 1 millió forint) rendelhető meg, de az értéke ennél sokkal nagyobb. Egy átlagfelhasználó számára a legelső találatok számítanak, így a 0-dik találat is.
 rendelhető meg, de az értéke ennél sokkal nagyobb. Egy átlagfelhasználó számára a legelső találatok számítanak, így a 0-dik találat is.")
178
Árazásuk lehet: - megjelenés alapú (CPM), - fix alapú (/hét, /hónap), - hibrid alapú (a megjelenés és a rákattintás után kell fizetni), - csak rákattintás alapú (CT), mint a Google-nál.
, mint a Google-nál.")
179
Ezek is óriási értékkel bírnak. Árazásuk lehet:
Rejtett találatok: Azok a keresők tartoznak ide, amelyek fizetett első találatot (esetleg másodikat v. harmadikat) kínálnak gyengén vagy megkülönböztetés nélkül. Ezek is óriási értékkel bírnak. Árazásuk lehet: - megjelenés alapú (CPM), - hibrid alapú (CPM+CT), - csak rákattintás alapú (CT).
 kínálnak gyengén vagy megkülönböztetés nélkül. Ezek is óriási értékkel bírnak. Árazásuk lehet: - megjelenés alapú (CPM), - hibrid alapú (CPM+CT), - csak rákattintás alapú (CT).")
180
A kampánytervezés folyamata
A céloknak sokkal pontosabb meghatározása azért szükséges, hogy a kampányban használt kreatívokat, reklámhelyeket és a büdzsét időben változtatni tudjuk, mindezt a marketingcélok sikeres elérése érdekében. A kampánycélokat számszerűen érdemes meghatározni, hogy a kampány utáni eredményeket össze tudjuk hasonlítani valamivel.

181
A leggyakoribb és mérhető kampánycélok:
X százalékos kattintási arány a hirdetésre/kereső, X számú kattintás az összesen használt keresőkben, katalógusokban, vagy linkgyűjteményekben, tévéreklám támogatása (a tévéreklám kulcsszavainak a használata a keresőkben), adatbázis-építés vagy -tervezés, ahol már a konverziós arányokat is meghatározhatjuk (pl. a keresőkből érkező látogatók 50%-a kell, hogy vásároljon v. kérdőívet töltsön ki).
, adatbázis-építés vagy -tervezés, ahol már a konverziós arányokat is meghatározhatjuk (pl. a keresőkből érkező látogatók 50%-a kell, hogy vásároljon v. kérdőívet töltsön ki).")
182
A célcsoport A célcsoport nem demográfiai adatok alapján (pl. 18 és 39 év közötti, városi lakók), hanem website-látogatóink szokásaiból, viselkedéséből eredő ismérvek alapján kiválasztott közönség lesz. Mit értünk website látogatóink szokásai alatt? A naplófájlokat elemző szoftver többek közt a látogatók által leginkább használt útvonalakat és azokat a kulcsszavakat mutatja, amelyeken keresztül a felhasználó hozzánk érkezett valamelyik keresőeszközből.

183
A látogatók által leginkább használt útvonalakat azért szükséges elemezni és a tervezésnél figyelembe venni, mert ezekből az adatokból megtudhatjuk, hogy a keresőeszközből érkező látogató továbbment -e a weboldalon belül vagy azonnal távozott a megérkezés után. Ha azonnal távozott, akkor nem kapta meg azokat az információkat, amelyeket a keresőben találatként megígértünk neki.

184
Ezek után, ha a kulcsszavas reklámozásban ezeket a szavakat elkezdjük használni, akkor több mint valószínű, hogy hasonló eredményeket várhatunk a kampány után, azaz a látogatók többsége nem lesz kíváncsi a weboldal-tartalmunkra. Ha a keresőkből érkezők több oldalt töltenek le, sőt X termékünk oldala az egyik legpreferáltabb, és a termékkel kapcsolatos kulcsszavak is megtalálhatók a naplófájlokat elemző szoftverben, akkor szinte biztos a siker, ha ezeket a szavakat használjuk hirdetésként a keresőkben.

185
Időzítés A cél az, hogy az összes érdeklődőt elérjük, napszaktól és hónaptól függetlenül. Kisebb büdzsével rendelkező cégek mindenképpen a fontosabb ajándékozási ünnepek előtt és alatt jelenjenek meg, mert ezekben az időszakokban kivételesen megugrik a keresők használata.

186
Regionalitás Akiknek a szolgáltatásai vagy a termékei nem csak magyarországi célcsoportnak szólnak (szállodák, szoftverek stb. esetén), érdemes használni külföldi keresőket és katalógusokat (about.com). Több országban egy időben futó kampányokat nemzetközi ügynökségi hálózatok készítenek. A kinti ügynökség segíthet abban, hogy a kampány magyar része a nemzetközi keresőkben és katalógusokban is fusson. Ha erre nincs mód, vagy ha kisebb cégről van szó, akkor nincs más hátra, mint mindent egyedül megcsinálni.
, érdemes használni külföldi keresőket és katalógusokat (about.com). Több országban egy időben futó kampányokat nemzetközi ügynökségi hálózatok készítenek. A kinti ügynökség segíthet abban, hogy a kampány magyar része a nemzetközi keresőkben és katalógusokban is fusson. Ha erre nincs mód, vagy ha kisebb cégről van szó, akkor nincs más hátra, mint mindent egyedül megcsinálni.")
187
Büdzsé A hazai reklámárak a keresőeszközökben nagyságrendekkel alatta maradnak a többi online reklámeszközénél. A linkgyűjteményekben és a katalógusokban éves szinten már forinttól hirdethetünk. Az összes magyar keresőeszköz használatának egyéves költsége 1-1,5 millió forintot tesz ki. A külföldi keresőkben reklámozni drágábban lehet.

188
Targetálási előnyök és hátrányok
Ezeket az előnyöket leginkább az árazási típuson keresztül követhetjük. Megjelenés alapú árazás (CPM: Cost per Impression): linkgyűjteményekben és katalógusokban különösen hasznos az ún. „többszintű targetálás”, ahol a megrendelő több alkategóriát is megrendelhet. Pl. a Startlap bizonyos aloldalain hirdetünk különféle célcsoportoknak.
: linkgyűjteményekben és katalógusokban különösen hasznos az ún. „többszintű targetálás , ahol a megrendelő több alkategóriát is megrendelhet. Pl. a Startlap bizonyos aloldalain hirdetünk különféle célcsoportoknak.")
189
Hibrid alapú árazás: a megjelenés plusz a kattintás alapú árazás, mindenképpen kulcsszófüggő. Ha a keresőkben megjelenik a hirdetésünk, ami után akkor is fizetnünk kell, ha a felhasználó nem kattintott rá a reklámunkra (megjelenési ár). Ha pedig rá is kattint, akkor a megjelenési ár mellett a kattintási árat is fizetnie kell. Ilyenkor nem kell sajnálni az olyan felhasználók után kifizetett összegeket, akik nem kattintottak rá a hirdetésünkre, de az megjelent előttük, mert nekik is át tudtuk adni márkánk értékeit.
. Ha pedig rá is kattint, akkor a megjelenési ár mellett a kattintási árat is fizetnie kell. Ilyenkor nem kell sajnálni az olyan felhasználók után kifizetett összegeket, akik nem kattintottak rá a hirdetésünkre, de az megjelent előttük, mert nekik is át tudtuk adni márkánk értékeit.")
190
Kattintás alapú árazás- CPC (Click per Click)
A keresők fő reklámbevételei ebből származnak. A célzás itt attól függ, hogy mennyire ismerjük a website-unk célközönségét, és mennyit vagyunk hajlandók költeni. Nagyobb költés, pontos kulcsszavakkal első pozíciókat hoz, és természetesen értékes látogatókat.

191
Optimalizálás és utóértékelés
Míg a tévécsatornának a reklámfilmeket hetekkel a sugárzás előtt le kell adni és az esetleges változtatásokat szintén hetekkel előbb kell közölni, addig az online reklám ennél sokkal rugalmasabb. Az előkészített hirdetéseket nemhogy az utolsó pillanatban leadhatjuk, hanem a kampány első napjaiban akár meg is változtathatjuk azokat. Ilyen jellegű kampányoptimalizálás nagyobb eredményeket és a reklámbefektetés gyorsabb megtérülését hozhatná.

192
A kulcsszavas reklámkampány elindítása után lehetőségünk van a következő paraméterek megváltoztatására: kreatív (grafika, üzenet); felhívás a cselekvésre és az üzenet ajánlatrésze; reklámhely a weboldalon belül; landing (fogadó) weboldal és linkje; reklámmennyiség, gyakoriság és kampányhossz; médiacélok, reklámozási célok.
; felhívás a cselekvésre és az üzenet ajánlatrésze; reklámhely a weboldalon belül; landing (fogadó) weboldal és linkje; reklámmennyiség, gyakoriság és kampányhossz; médiacélok, reklámozási célok.")
193
Utóértékelés Az adott keresőeszköz üzemeltetői minden reklámhelyre, amely a weboldalukon található, meg tudják mondani az adott kulcsszó rákeresési gyakoriságát és az átlagos kattintási arányt. Már ezekből az adatokból kiszámítható a megrendelő weboldalának jövőbeni látogatottsága.

194
Reklámletöltés: azaz ad szerver által szolgáltatott adatok, minden online reklámkampányban segítenek átlátni és pontosan irányítani a megrendelt reklámletöltéseket. Akár ügynökség, akár direkt megrendelő irányítása alatt álló ad szerver azonnali beavatkozásokat is lehetővé tesz. Optimalizálhatjuk a reklámok megjelenési számát, a kreatívok típusát, megjelenési helyeket stb., ami a kulcsszavas reklámozásnál igen fontos.

195
Kampányelemző: minden nagyobb kereső a kulcsszavas kampányok működtetésére, utóértékelésére és elszámolására egy jelszavas webfelületet biztosít minden hirdető számára. Ilyen kampányirányítással és utóértékeléssel biztosítva van a kulcsszavas reklámba befektetett pénz megtérülése.

196
Naplófájl-elemzés: A naplófájl-adatok a website-on történt minden akcióról beszámolnak. Az adatok pl. elárulnak olyan információkat, mint: honnan érkeznek a látogatóink. Megmutatja, hogy melyik keresőből, milyen kulcsszavak begépelésével érkeztek a látogatóink. Ezeket az adatokat azért érdemes figyelembe venni, mert valószínű, hogy a webhelyünk tartalmából származnak. A naplófájl adatok (kulcsszavak) útmutatóként szolgálnak a website fejlesztése során. Ezekkel az eszközökkel (ad szerver, kampányelemző és naplófájl) kiszámolhatjuk a befektetett pénz pontos megtérülését.
 útmutatóként szolgálnak a website fejlesztése során. Ezekkel az eszközökkel (ad szerver, kampányelemző és naplófájl) kiszámolhatjuk a befektetett pénz pontos megtérülését.")
197
ETARGET (www.etarget.hu )
Az ETARGET rendszer szponzorált linkek szolgáltatója a magyar, szlovák, cseh, román, szerb, bulgáriai, horvát és lengyel piacon. Lehetővé teszi ügyfelei számára, hogy a magyar kereső portálokon, az első pozíciók között jelenítsenek meg weboldalukra mutató linkeket. Az ETARGET ügyfelei kiválaszthatják azokat a kulcsszavakat, amelyekre keresve linkjeik megjelennek. A legszélesebb körű PPC (Pay Per Click – Kattintás alapú) szolgáltató rendszer.
 szolgáltató rendszer.")
198
Google AdSense program www.google.hu/ads
Az AdSense a Google hirdetéskiszolgáló programja. A szolgáltatás lényege, hogy a weboldal-tulajdonosok regisztráció után engedélyezhetik weboldalukon szöveg, kép és videó formátumú hirdetések megjelenítését, amely Cost Per Click (CPC) vagy Cost Per Thousand (CPT) rendszerben bevételhez juttathatja őket, a Google anyacégen keresztül.
 vagy Cost Per Thousand (CPT) rendszerben bevételhez juttathatja őket, a Google anyacégen keresztül.")
199
A rendszer fontos tulajdonsága, hogy az oldalon megjelenő hirdetések összefüggésben állnak az oldal szöveges tartalmával, így a hirdető cégek nagyobb hatékonyságot érhetnek el célzott reklámjaikkal. A hirdetések a Google adminisztrációs felületének segítségével testre szabhatóak, úgy lehet őket a weboldalba illeszteni, hogy az teljes egészében illeszkedjen a lap megjelenésébe: beállítható az egyes bannerek mérete és a színvilága is.

200
5. A keresők értékelése A keresők mérésére irányuló szabvány létrehozása Kezdetben a W3C konzorcium Web Characterization Activity nevű munkacsoportja a mérési módszereknek egy sorát definiálta, azonban ezek közül egyik sem kapcsolódott a keresőeszközökhöz. 1999 végére a WCA munkacsoport megszüntette a tevékenységét, ami nem bizonyult sikeresnek ezen a területen.

201
Az eddig megjelent értékelésekben a kutatók az internetes keresők minőségét számos mérték alapján vizsgálták. Ezeknek a megbízható mutatóknak a megtalálása rendkívül nehéz feladat, számos vita folyik erről a kutatók körében. A mértékek általános szabványának hiánya nagy problémát jelent az értékelésekben. E hiányosság miatt a keresőszolgáltatások értékelésével foglalkozó kutatás jelenleg nem egységes a használt módszerek tekintetében.

202
Oppenheim és Froehlich ezért egy olyan szabvány kidolgozását javasolták, amely az alábbi mértékeket tartalmazná: pontosság, azaz a visszakeresett dokumentumok összességén belül a releváns dokumentumok aránya; teljesség, a megtalált releváns dokumentumoknak az összes (akár talált, akár nem) releváns dokumentumhoz viszonyított arányát jelenti; relatív teljesség, azaz az adott kereső által visszakeresett releváns dokumentumok száma osztva az összes vizsgált keresők valamelyike által megtalált releváns dokumentumok számával;
 releváns dokumentumhoz viszonyított arányát jelenti; relatív teljesség, azaz az adott kereső által visszakeresett releváns dokumentumok száma osztva az összes vizsgált keresők valamelyike által megtalált releváns dokumentumok számával;")
203
válaszidő, vagyis az, hogy mekkora az átlagos időeltérés a keresőkérdés feltétele és a válasz megadása között ; tesztelési idő, azaz a tesztelésre fordított teljes időtartam hossza; egy adott időtartamon belül a találatok megbízhatóságának mérése, melynek során a találatokat megvizsgáljuk, hogy az adott keresőkérdésre mindig ugyanazokat kapjuk-e; zsákutcás, halott hivatkozások aránya; ismétlődő találatok aránya; találatok minősítése felhasználókkal;

204
grafikus felhasználói felület értékelése (használata mennyire felhasználóbarát?);
a súgó és a keresőprogram mennyire hasznos a kezdő és a tapasztalt felhasználók számára; találatmegjelenítés, azaz az output megjelenítési módja; reklámok jelenléte;

205
a gyűjtemény vélhető érdeklődést lefedő volta (angolul: coverage), vagyis, hogy milyen mértékben tartalmaz a rendszer releváns dokumentumokat. Ezt a mutatót az adott kereső adatbázisában lévő összes releváns dokumentum és az összes vizsgált kereső adatbázisában található releváns dokumentumok hányadosa adja; elvárt keresési hossz, azaz átlagosan hány nem releváns dokumentumot kell áttekintenie a felhasználónak ahhoz, hogy bizonyos számú releváns dokumentumot megtaláljon; találatleírások terjedelme és olvashatósága.

206
Egyéb értékelési szempontok:
Testreszabhatóság: a keresőszolgáltatás testreszabható-e? Vizuális egyértelműség: a keresőkérdés és a találatmegjelenítés világos, érthető és következetes-e? Navigáció: egyértelmű-e a navigációs eszközök használata? Könnyen tudunk-e a találatmegjelenítéstől a forrásdokumentumig eljutni és fordítva? A keresőszolgáltatás felkínál-e valamilyen webes katalógust, amiben böngészhetünk.

207
Ez a lista természetesen bővülhet további új mérési jellemzőkkel
Ez a lista természetesen bővülhet további új mérési jellemzőkkel. Statisztikai szempontból érdekes lenne megvizsgálni, hogy létezik-e valamilyen összefüggés a felsorolt mutatók között. A rendelkezésünkre álló szakirodalom rávilágított arra, hogy mindenki maga választja ki a vizsgálatához szükséges mutatókat és nincs közmegegyezés arról, hogy milyen mértékek használata lenne elengedhetetlenül fontos egy mérés elvégzéséhez.

208
5.1. A cranfieldi vizsgálatok során kidolgozott mértékek
Cranfieldben számos vizsgálatot végeztek az 1960-as években, melyek során 33 osztályozási rendszer hatékonyságát hasonlították össze. Mértékeket dolgoztak ki különböző szempontok megválaszolására, mint pl.: az információkereső nyelv kiválasztja-e a releváns tételeket vagy sem? Visszamaradnak-e releváns tételek vagy sem? A létrehozott mutatórendszer ezeknek a szempontoknak a kölcsönös összehasonlításán alapult.

209
Miután egy keresőkérdés alapján elvégeztek egy irodalomkutatást, az osztályozási rendszer tételei négy csoportba voltak sorolhatók: a: releváns és visszakeresett dokumentumok; b: releváns és nem visszakeresett dokumentumok; c: nem releváns és visszakeresett dokumentumok; d: nem releváns és nem visszakeresett dokumentumok. Ahol a+b+c+d megfelelt az N-nek, azaz a teljes gyűjteménynek. A releváns dokumentumokat a+b jelentette, a visszakeresett dokumentumokat a+c, az összes irreleváns dokumentumot pedig c+d.

210
Ennek alapján a következő mértékeket definiálták:
1. teljesség: R (recall) = a/a+b 2. pontosság: P (precision) = a/a+c 3. fölösleg: F (fallout) = c/c+d A teljesség mutató kifejezi, hogy a releváns dokumentumok hányada került elő. A pontosság megmutatja, hogy a visszakeresett dokumentumok hányad része releváns. A fölösleg mutatót a visszakeresett irreleváns dokumentumok és az összes irreleváns dokumentum hányadosa határozza meg.
 = a/a+b. 2. pontosság: P (precision) = a/a+c. 3. fölösleg: F (fallout) = c/c+d. A teljesség mutató kifejezi, hogy a releváns dokumentumok hányada került elő. A pontosság megmutatja, hogy a visszakeresett dokumentumok hányad része releváns. A fölösleg mutatót a visszakeresett irreleváns dokumentumok és az összes irreleváns dokumentum hányadosa határozza meg.")
211
A keresőszolgáltatások általában arra törekszenek, hogy a teljesség legyen nagy, ezért a pontosságról eleve nincsen szó. A pontosság és a teljesség között fennálló összefüggésről elmondható, hogy a pontosság a teljesség hátrányára érvényesül, és mivel e két fogalom fordított arányban áll egymással, ezért az ideális keresési állapot lényegében sosem érhető el. Minél teljesebb egy keresés, annál pontatlanabb, mert a teljesség növelésével csökken a pontosság és viszont: a pontosság növelése a teljesség csökkenését vonja maga után.

212
5.2. A relevancia értelmezései a szakirodalomban
„Mennyiségileg a relevancia adott keresőkérdés vonatkozásában a visszakeresett tételek azon hányada, amely objektív értelemben megfelel a feltett kérdésnek” ([Ungváry-Vajda2002] 153. p.). Egy másik meghatározás szerint „a relevancia azt fejezi ki, hogy mekkora a közelség a felhasználói kérdés és a talált dokumentumok tartalma között (azaz azok a dokumentumok, melyek a kérdésnek megfelelnek, relevánsak)” ([Ungváry-Vajda2002] 155. p.).
. Egy másik meghatározás szerint. „a relevancia azt fejezi ki, hogy mekkora a közelség a felhasználói kérdés és a talált dokumentumok tartalma között (azaz azok a dokumentumok, melyek a kérdésnek megfelelnek, relevánsak) ([Ungváry-Vajda2002] 155. p.).")
213
A relevanciát úgy is definiálhatjuk, hogy az hasonlósági kapcsolat a tárolt információ reprezentációja (indextétel) és a kérdés reprezentációja (keresőprofil) között ([Horváth-Sütheő2003] 175. p.). Különbséget kell tennünk az ún. technikai és tartalmi relevancia között. Az előbbi a rendszer által relevánsnak ítélt találatok relevanciáját jelenti (a Boole-algebrán alapuló illesztéses kereséskor a visszakeresett tételek technikai relevanciája minden esetben 100%), az utóbbi a felhasználó döntését ugyanarról a tételről ([Horváth-Sütheő2003] p.).
![A relevanciát úgy is definiálhatjuk, hogy az hasonlósági kapcsolat a tárolt információ reprezentációja (indextétel) és a kérdés reprezentációja (keresőprofil) között ([Horváth-Sütheő2003] 175. p.).](http://slideplayer.hu/slide/2107516/8/images/213/A+relevanci%C3%A1t+%C3%BAgy+is+defini%C3%A1lhatjuk%2C+hogy+az+hasonl%C3%B3s%C3%A1gi+kapcsolat+a+t%C3%A1rolt+inform%C3%A1ci%C3%B3+reprezent%C3%A1ci%C3%B3ja+%28indext%C3%A9tel%29+%C3%A9s+a+k%C3%A9rd%C3%A9s+reprezent%C3%A1ci%C3%B3ja+%28keres%C5%91profil%29+k%C3%B6z%C3%B6tt+%28%5BHorv%C3%A1th-S%C3%BCthe%C5%912003%5D+175.+p.%29..jpg "Különbséget kell tennünk az ún. technikai és tartalmi relevancia között. Az előbbi a rendszer által relevánsnak ítélt találatok relevanciáját jelenti (a Boole-algebrán alapuló illesztéses kereséskor a visszakeresett tételek technikai relevanciája minden esetben 100%), az utóbbi a felhasználó döntését ugyanarról a tételről ([Horváth-Sütheő2003] p.).")
214
A relevanciában sok szubjektív vonás található pl
A relevanciában sok szubjektív vonás található pl. különböző használók eltérő álláspontot képviselhetnek adott dokumentumnak egy kérdésre vonatkozó relevanciáját vagy irrelevanciáját illetően ([Ungváry2001] 197. p.). Mortimer Taube 1965-ben kiállt a szubjektív relevanciafogalom használata mellett, és tiltakozott mindenfajta „matematizált” relevancia bevezetése ellen. Ez utóbbin alapuló képleteket pszeudo-matematikai konstrukcióknak tekintette, melyekkel az információkereső rendszerek hatékonyságát számszerűen értékelték .
. Mortimer Taube 1965-ben kiállt a szubjektív relevanciafogalom használata mellett, és tiltakozott mindenfajta „matematizált relevancia bevezetése ellen. Ez utóbbin alapuló képleteket pszeudo-matematikai konstrukcióknak tekintette, melyekkel az információkereső rendszerek hatékonyságát számszerűen értékelték .")
215
Van Rijsbergen szerint elvileg van olyan relevanciafogalom, amelyet objektívnek tarthatunk, s amelyet „logikai relevanciának” nevezhetünk ([Ungváry2001] 198. p.). A relevancia fontos szerepet játszik a felhasználók különböző információs igényeinek megválaszolásában, azaz a számítógépes tájékoztatásban. A felhasználók az általuk keresett információt, kutatási-fejlesztési témát természetes nyelven fogalmazzák meg, amit keresőkérdésnek nevezünk.
![Van Rijsbergen szerint elvileg van olyan relevanciafogalom, amelyet objektívnek tarthatunk, s amelyet „logikai relevanciának nevezhetünk ([Ungváry2001] 198. p.).](http://slideplayer.hu/slide/2107516/8/images/215/Van+Rijsbergen+szerint+elvileg+van+olyan+relevanciafogalom%2C+amelyet+objekt%C3%ADvnek+tarthatunk%2C+s+amelyet+%E2%80%9Elogikai+relevanci%C3%A1nak+nevezhet%C3%BCnk+%28%5BUngv%C3%A1ry2001%5D+198.+p.%29..jpg "A relevancia fontos szerepet játszik a felhasználók különböző információs igényeinek megválaszolásában, azaz a számítógépes tájékoztatásban. A felhasználók az általuk keresett információt, kutatási-fejlesztési témát természetes nyelven fogalmazzák meg, amit keresőkérdésnek nevezünk.")
216
A referensz interjú során a felhasználónak és a tájékoztató könyvtárosnak át kell alakítania a keresőkérdést keresőprofillá. A természetes nyelvű keresőkérdésnek az adatbázis információkereső nyelvére „lefordított” változatát keresőprofilnak hívjuk. Tehát a keresés megkezdése előtt a megfelelő keresőprofil, más néven keresési stratégia kialakítása a cél, amely releváns rekordokat eredményez a keresésünkre.

217
A keresőprofil létrehozásához ismernünk kell az adatbázis tárgyszavait, szakrendjét, a Boole-algebra szabályainak használatát, valamint a számítógépes keresőprogramot. Ezek együttese határozza meg a keresőprofil szerkezetét. Ebben a kontextusban a relevanciát úgy lehet meghatározni, hogy az a keresési stratégiában megfogalmazott kritériumoknak eleget tevő releváns rekordok halmaza. „A hibás vagy hiányos stratégiával kikeresett rekordok a nem releváns rekordok” ([Roboz98] 39. p.).
.")
218
Tanácsos a keresési stratégiát az általa visszakeresett rekordokkal együtt azonnal ellenőriznünk, s ha kell, a stratégiát nyomban módosítanunk. A keresőprofil módosítása olyan kihívás, ahol a „keresés művészete”, a tájékoztató szakember fantáziája és gyakorlata leginkább érvényesülhet.

219
5.3. Az internetes keresők elemzésével kapcsolatos problémák
A keresők elemzésére irányuló kísérletek nem egységes módszerekkel valósultak meg, ezért a legtöbb kutatási beszámoló tájékoztató jellegűnek tekinthető. Eddig főként indexelőszolgáltatásokon végeztek ilyen jellegű méréseket, de elvileg bármilyen típusú kereső értékelhető. Leighton és Srivastava szerint sok összehasonlító értékelés ellentmondásos következtetésekre jutott arra vonatkozóan, hogy melyik szolgáltatás nyújtja a legrelevánsabb találatokat.

220
Ezenkívül több tanulmány kisebb tesztelési kísérletek eredményeire épült, és nem számolt be az általa használt módszertanról. Mivel ezek a tanulmányok kevés tesztelési eredménnyel rendelkeznek, ezért nem alkalmasak a mélyebb szintű statisztikai elemzések végzésére. A népszerű folyóiratokban közölt tanulmányok gyakran nem ismertetik azt sem, hogy hány keresést futtattak le mérés közben, és konkrétan milyen keresőkérdéseket alkalmaztak.

221
A megjelent értékelések főként rendszerjellemzőket vizsgáltak és azok összehasonlításait közölték több keresőszolgáltatásra vonatkozóan. Su megállapítja, hogy hiányzik a szisztematikus megközelítés ezekből a tanulmányokból. Rámutat arra, hogy a kutatóknak nincs egységes kialakult véleménye arról, hogy mit mérjenek, és hogyan mérjenek egy szolgáltatást. Megjegyzi, hogy a legtöbb tanulmányból a felhasználók mint aktív közreműködők kimaradnak. Általában az első 10 vagy 20 lekérdezett találat relevanciáját mérik. A relevancia ítéleteket többnyire a kutatók hozzák meg, nem pedig a felhasználók.

222
A mérési eredmények rendszerint jelzik, hogy a legjobbnak minősített második vagy harmadik kereső között a teljesítménybeli különbség minimális. Az értékelés során alkalmazott keresési folyamat sokféleképpen befolyásolható pl. választható egy olyan tárgykör, amelyről köztudott, hogy az egyik kereső színvonalasabb szolgáltatást nyújt róla, mint a másik. Fontos, hogy az értékelők ne legyenek elfogultak egyik keresővel szemben sem, és megőrizzék pártatlanságukat objektív módszerek alkalmazásával. Ennek a szemléletnek tükröződnie kell a keresőkérdések megválasztásában is.

223
A keresők minőségi információszolgáltatásában problémát jelent a reklámok jelenléte, ami főként a hirdetők érdekeit szolgálja, és távol esik a felhasználók tényleges elvárásaitól. Értékelésüket nagymértékben nehezíti az a tény, hogy a keresők képesek befolyásolni a keresési találatokat rendkívül burkolt formában. Amennyiben nem feltűnő ez a befolyásolás, akkor azt maga a piac is képes tolerálni. A reklámozásból származó bevételek többnyire ösztönzik a keresőket a gyengébb minőségű találatok szolgáltatására.

224
Az értékeléseknél külön gondot jelent a keresők állandó változása, mivel azok gyakran fejlesztik a keresési mechanizmusaikat és a felhasználói felületüket. Ehhez párosul még az a tény, hogy a világháló egy dinamikusan változó közeg. Ennek eredményeként a megjelenő értékelések rendkívül rövid életűek, és csak a pillanatnyi helyzetképet tükrözik a keresőszolgáltatásokról. Mindezek ellenére igenis van értelme elemezni a használatban lévő keresőket, de szabványos értékelési módszereket erre a feladatra nem alkalmazhatunk.

225
Általában megfigyelhető az a jelenség, hogy az elemzések egyéni értékelési módszerekről számolnak be, és többnyire elkerülik a szabványos értékelési módszerek használatát is. Az információkeresés területén végzett kutatások rámutatnak arra, hogy rendkívül nehéz megfelelő mértékeket találni az értékelésekhez. Leggyakrabban a pontosságot és a teljességet használják mutatókként, amelyek érzékenyek arra, hogy a relevanciát hogyan definiáljuk és mérjük.

226
A teljesség mérése megköveteli, hogy az értékelők a megtalált releváns találatok teljes halmazához hozzáférhessenek, vagy a releváns találatokat képviselő mintához. Ennek a követelménynek a kielégítése külön problémát jelent az internetes keresők értékelésénél. Sokan érveltek amellett, hogy nem lehet mérni a teljességet, mert nehéz meghatározni a (visszakeresett és a nem visszakeresett) releváns találatok összességét egy bizonyos keresésre a weben. Az eddig megjelent tanulmányok minimális mértékben, vagy egyáltalán nem kísérelték meg a különböző keresők teljességének a mérését.
 releváns találatok összességét egy bizonyos keresésre a weben. Az eddig megjelent tanulmányok minimális mértékben, vagy egyáltalán nem kísérelték meg a különböző keresők teljességének a mérését.")
227
A pontosság mérése főként emberi relevancia ítéletektől függ, ezért rendkívül szubjektív. Azonban annak mérése egyértelmű, hiszen a keresési találatok megvizsgálása után azokat a releváns, illetve a nem releváns dokumentumok halmazába soroljuk. Spink és Greisdorf szerint jobb eredményeket nyerhetünk, ha a bináris mérés helyett a relevancia többféle szintjét definiáljuk. Ezeket a relevancia szinteket már korábban is felhasználták az internetes keresők pontosságának a mérésére.

228
Gordon és Pathak hangsúlyozta, hogy a relevancia ítéleteket csak az eredeti információs igényekkel rendelkező egyének hozhatják meg. Mások a relevancia ítéletek meghozatalát szakértőkre, illetve szakértői csoportokra bízzák. A keresők visszakeresési teljesítményének mérésekor egyéb mértékeket is használtak pl. elemezték a keresők gyűjteményének lefedettségét a weben, a felhasználói megelégedettséget, a felhasználók keresési viselkedését és a találatok megjelenítését.

229
Az eddig megjelent értékelésekben használt
módszerek négy fő csoportba sorolhatók: Cranfieldi tanulmányok készítése egy szűk, behatárolt témáról, ahol a kutató ismeri egyenként a találatokat, és a releváns találatok kis halmazát vizsgálja meg. A relatív teljességet elemző cranfieldi tanulmányok. Ebben az esetben a különböző keresőszolgáltatásokkal nyert releváns találatokat összeadják, amelyek a releváns találatok halmazát képviselik. A kutatók ezután az adott kereső esetében elemzik, hogy az mennyire képes a releváns találatok halmazát visszakeresni.

230
Statisztikai módszerrel mintát vesznek a webről, amelyben felmérik a releváns weboldalak számát. Ezen a mintán vizsgálják a teljességet, és egy cranfieldi tanulmányt készítenek róla. A teljességet figyelmen kívül hagyó tanulmányok. Ezek a kísérletek megpróbálják a teljességet más mértékekkel helyettesíteni, mint pl.: gyűjtemény lefedettség, indexelés, felhasználói felület, keresési technikák, találatok megjelenítése, stb.

231
Értékelési problémák származhatnak a következetlen relevancia ítéletekből, az automatizált technikák nem megfelelő használatából, és abból, hogy a téma másképpen szerepel a kezdeti kérdésfeltevésben, mint a keresőhöz ténylegesen elküldött keresőkérdésben. Az értékelésekben használt mutatók mérési sajátosságai további problémákat okozhatnak. Ezért megállapíthatjuk, hogy azok a mértékek, amelyek egy adott esetben jól működnek nem biztos, hogy egy másik helyzetben megfelelőek lesznek

232
5.4. Az internetes keresők értékeléséhez javasolt módszertan
Az értékelés általános célkitűzéseinek meghatározása: mit szeretnénk tesztelni, kiknek és milyen céllal. Az értékelésnél számításba jöhető követelmények és az ezekhez kapcsolódó mértékek áttekintése: végignézzük a kiválasztott követelmények és a hozzájuk kapcsolódó mérési jellemzők listáját. Közben felmérjük, hogy mely követelmények, illetve azoknak milyen együttes kombinációja elégíti ki a kutatási elképzeléseinket.

233
Az internetes keresők elemzése: információt gyűjtünk az értekélésben résztvevő eszközökről.
A kísérlet meghatározása: megtervezzük a kísérletet, amely figyelembe veszi a korábban definiált célkitűzéseinket és az adott környezetet. Az eredmények elemzése: a kísérlet eredményeinek kifejtése a célok és az elvárások tükrében. A következő részben részletezzük az értékelés egyes fázisait.

234
Az értékelés általános célkitűzéseinek meghatározása:
Robertson szerint egy kísérletnél általában ötféle célkitűzés jöhet számításba: a különböző rendszerek összehasonlítása; a rendszerek lehetséges fejlesztési irányainak keresése; a rendszer tervezésével kapcsolatos elképzelések tesztelése; a rendszer működésének ellenőrzése az előírt szabványok és követelmények szerint; általános alapelvek keresése és tesztelése.

235
Sokféle kérdést feltehetünk magunknak, amelyek megválaszolása segít a kísérlet céljainak a meghatározásában. Ezek pedig a következők lehetnek: A teszttel a legjobb teljesítményű internetes keresőket szeretnénk-e meghatározni vagy egy adott keresőt akarunk-e közelebbről megvizsgálni? Több keresőszolgáltatást szeretnénk-e megvizsgálni abból a célból, hogy tanulmányozzuk a lehetséges fejlesztési irányaikat? Össze szeretnénk-e hasonlítani a manuális és az automatikus indexelés lehetőségeit egymással?, stb.

236
A fenti kérdésekre adott válaszok egyben befolyásolják azt is, hogy milyen szempontokra helyeződjön a hangsúly mérés közben, és hogyan alkalmazzuk azokat.

237
II. Az értékelésnél számításba jöhető követelmények és az ezekhez kapcsolódó mértékek áttekintése:
A teljesség igénye nélkül itt csak a legnépszerűbb és a legfontosabb értékelési követelményeket vesszük számba. A relevancia minősül a legrégebbi mérőeszköznek. Gyakran használták azt az információ-visszakereső rendszerek értékelésében. A relevancián kívül más egyéb mérési követelményeket is figyelembe vettek a keresők értékelésekor, a használatot és a felhasználói megelégedettséget.

238
A relevanciával és a használattal kapcsolatban egy sor mérési jellemzőt vezettek be a tesztelésekbe. Ezek pedig a következők: Pontosság: az információ-visszakeresés egyik legnépszerűbb és leghagyományosabb mértéke. Az internetes keresők pontosságának mérése három irányból közelíthető meg: Meghatározzuk egy adott keresésnél a releváns találatok számát. Felmérjük a különböző lefuttatott keresések összes releváns találatának a számát. A találatok relevanciáját rangsoroljuk egy algoritmus segítségével.

239
A relevancia ítéletek bonyolultsága és kétértelműsége miatt ne tulajdonítsunk nagy fontosságot annak, hogy melyik lehetőséget válasszuk. Teljesség: a relevancia mérésének ez a második legfontosabb mértéke. Ezenkívül egyéb szempontok is igénybe vehetők a keresők értékelésénél. Pl. a gyűjtemény vélhető érdeklődést lefedő volta, zaj, hozzáférhetőség, stb.

240
Zaj Ez a mérték a használathoz kapcsolódik. A zsákutcás, halott, és az ismétlődő hivatkozásokat ellenőrizzük le együttesen, vagy külön-külön a kutató elképzeléseitől függően. Ez a jellemző tájékoztat minket arról, hogy a felhasználó mennyi zajra számíthat a keresőszolgáltatás használatakor, pl. milyen lépéseket tettek a kereső adatbázisának frissítése érdekében, és az ismétlődő weblapok kiszűrése céljából.

241
Hozzáférhetőség Ez a mérték szintén a használathoz kapcsolódik. Itt tulajdonképpen azt ellenőrízzük, hogy milyen gyakran nem érhető el a keresőszolgáltatás, és hányszor küld hibaüzenetet számunkra a keresés megadása után.

242
III. Az internetes keresők elemzése:
Egy hatékony értékelés megtervezésében rendkívül fontos, hogy minél több információt gyűjtsünk össze az elemzésben résztvevő eszközökről. Javasolt információkat gyűjteni az alábbi szempontokról: A szolgáltatás leírása: röviden összefoglaljuk a keresőszolgáltatást, és kiemeljük annak előnyös tulajdonságait. Érdemes kitérnünk arra is, hogy ki a szolgáltatója, és mióta működik a szolgáltatás, stb.

243
Az adatbázis leírásának részleteznie kell a következőket:
Az adatbázis mérete: az internetes keresők szolgáltatói sok esetben a használatra vonatkozó adatokat tüntetik fel a weboldalak számaként. Az index adatbázis építése manuális vagy automatikus indexeléssel történik-e? Az indexelés milyen speciális forrásokra terjed ki az Interneten (weblapok, Usenet üzenetek, stb.)? Az indexelési stratégia: Automatikus indexelésnél a robot program milyen mélységig jut el az adott web-site vizsgálatában?
 Az indexelési stratégia: Automatikus indexelésnél a robot program milyen mélységig jut el az adott web-site vizsgálatában")
244
Az aktualizálás gyakorisága: Milyen gyakran frissítik az adatbázist?
Az indexelés a weblap mely elemeire terjed ki, pl. a teljes szövegére vagy csak néhány sorára? Adatbevitel: röviden részletezzük, hogy a felhasználó milyen keresési képernyőket használhat az adott keresőszolgáltatásnál.

245
Keresési technikák: felsoroljuk a felhasználó által igénybe vehető keresési lehetőségeket, beleértve a Boolean operátorokat, a helyzeti (távolsági/közelségi) operátorokat, a csonkolást, a felhasználói preferencia szerinti keresést, a mezők szerinti keresést és szűkítést. Fontos megvizsgálni azt, hogy a szolgáltatás felkínál-e valamilyen téma szerinti web-site listát, amiben szabadon böngészhetünk. Soroljuk fel azt is, hogy milyen alapértelmezett operátorokat használhatunk egy kulcsszavas keresésnél.
 operátorokat, a csonkolást, a felhasználói preferencia szerinti keresést, a mezők szerinti keresést és szűkítést. Fontos megvizsgálni azt, hogy a szolgáltatás felkínál-e valamilyen téma szerinti web-site listát, amiben szabadon böngészhetünk. Soroljuk fel azt is, hogy milyen alapértelmezett operátorokat használhatunk egy kulcsszavas keresésnél.")
246
Találatmegjelenítés:
összegyűjtjük, hogy a keresési találatokról a felhasználók milyen leírást kapnak, pl. a találati rekord tartalmazhatja: az URL-t, a weblap címét vagy néhány sorát, a létrehozás dátumát, stb. Részleteznünk kell, hogy a találatokról szóló összefoglalások hogyan jönnek létre. Kiegészítő szolgáltatások: számbavesszük az internetes keresőkhöz kapcsolódó egyéb hasznos szolgáltatásokat pl. , “chat” funkció, stb.

247
IV. A kísérlet meghatározása:
Egy kísérlet megtervezése az alábbi elemekre épül: A keresőkérdések kiválasztása: Javasolt olvasói referenszkérdéseket alkalmazni keresőkérdésként, és olyan keresőkifejezéseket alkotni, amelyek tesztelik az internetes keresők jellegzetességeit és jól tükrözik a keresés bonyolultságának különböző szintjeit (pl.: egy vagy több szavas keresőkifejezések használata, ÉS-, VAGY- műveletek kipróbálása).
.")
248
Igyekezzünk felhasználókat is bevonni az értékelésekbe, akik összeállítják a keresőkifejezéseket és egyben kiértékelik a keresésre kapott találatokat. Tanácsos minél több keresőkérdést használni, és azokat egymáshoz közel egyidőben lefuttatni. A relevanciával kapcsolatos döntések: A találatok elemzésébe tanácsos bevonni a kezdő és a tapasztalt felhasználókat is, akik az első n számú rekordot tanulmányozzák számunkra az általunk megadott instrukciók alapján. Egyenlőre még nem született közmegegyezés az n szám pontos értékéről.

249
Ha a felhasználók bevonása az elemzésbe nem lehetséges, akkor a rendelkezésre álló háttér információink alapján értékelhetjük a találatokat. A vizsgálat tárgya: Értékeléseket csupán az eredeti weblapok alapján végezhetünk, mivel az internetes keresők találatai nem minden esetben megbízhatóak. A tesztelés pontos idejét és a keresett témát mindig rögzítenünk kell az értékelés dokumentációjában.

250
V. Az eredmények elemzése:
A tesztelés eredményeit a meghatározott célok szerint elemezzük. A különböző lefuttatott keresések eredményeit átlagoljuk, ami alapján már összehasonlításokat végezhetünk. További következtetéseket vonhatunk le az eredményekből a megfelelő statisztikai módszerek segítségével. De ügyeljünk arra, hogy minél több keresőkérdést alkalmazzunk mérés közben, mert a tesztelési eredmények csak így elemezhetők kielégítően.

251
Felhasznált irodalom Damjanovich N.: Online marketing – alapoktól felsőfokig. 2. rész: Keresőmarketing. Budapest, 2003, Bagolyvár. Horváth T. – Sütheő P.: A tartalmi feltárás. In: Könyvtárosok kézikönyve. 2. köt. Feltárás és visszakeresés. Szerk. Horváth T., Papp I. Budapest, 2001, Osiris p. Roboz, P.: Számítógépes tájékoztatás. Online és CD-ROM adatbázisok keresése. Budapest, 1998, OSZK.

252
Szeredi P. [et al. ]: A szemantikus világháló
Szeredi P. [et al.]: A szemantikus világháló. In: A szemantikus világháló elmélete és gyakorlata. Szerz. Szeredi P. [et al.] Budapest, 2005, Typotex p. Ungváry R.: Az információkeresés értékelése. In: Osztályozás és információkeresés. Kommentált szöveggyűjtemény. 2. köt. Az információkeresés és elmélete. Szerk. Ungváry R., Orbán É. Budapest, 2001, OSZK p. Ungváry R. – Vajda E.: Könyvtári információkeresés. 2. jav. kiad. Budapest, 2002, Typotex.
![Szeredi P. [et al. ]: A szemantikus világháló](http://slideplayer.hu/slide/2107516/8/images/252/Szeredi+P.+%5Bet+al.+%5D%3A+A+szemantikus+vil%C3%A1gh%C3%A1l%C3%B3.jpg "Szeredi P. [et al.]: A szemantikus világháló. In: A szemantikus világháló elmélete és gyakorlata. Szerz. Szeredi P. [et al.] Budapest, 2005, Typotex p. Ungváry R.: Az információkeresés értékelése. In: Osztályozás és információkeresés. Kommentált szöveggyűjtemény. 2. köt. Az információkeresés és elmélete. Szerk. Ungváry R., Orbán É. Budapest, 2001, OSZK p. Ungváry R. – Vajda E.: Könyvtári információkeresés. 2. jav. kiad. Budapest, 2002, Typotex.")
Hasonló előadás
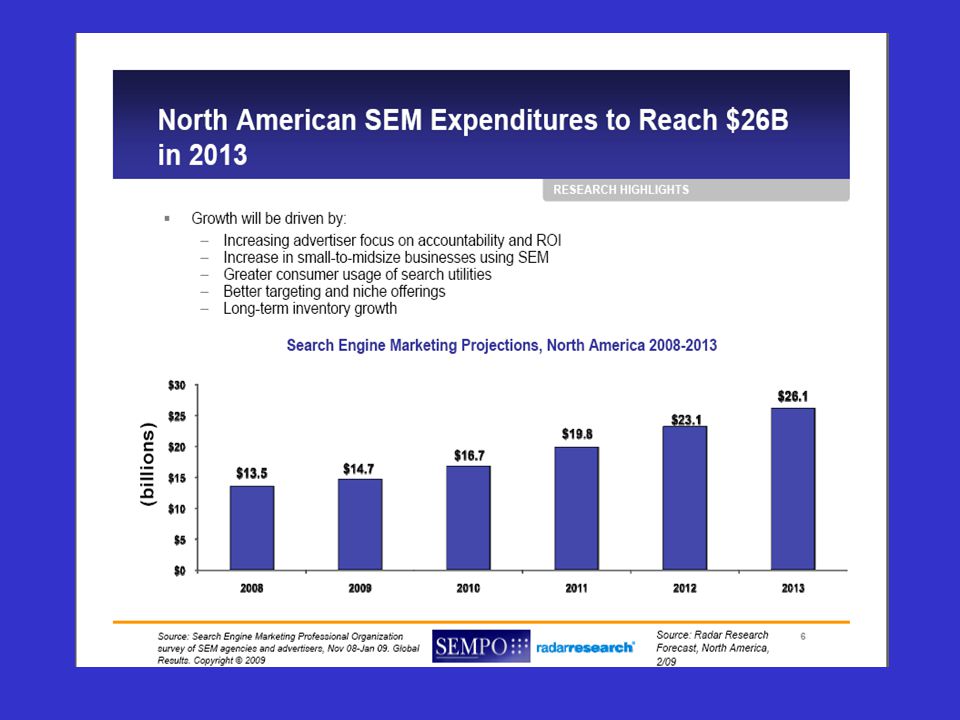

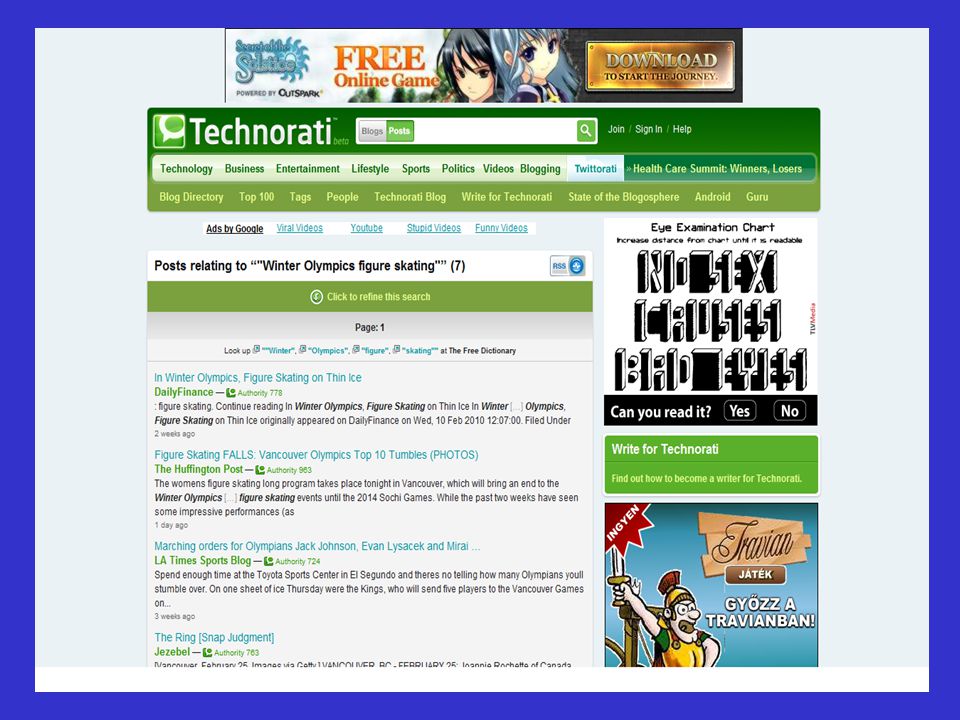
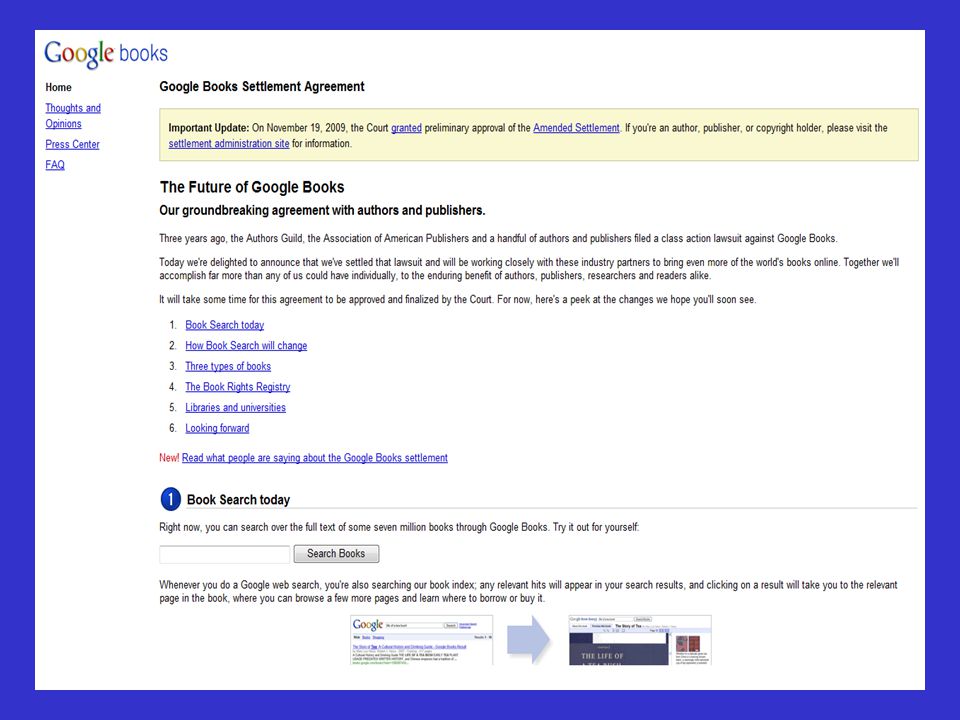
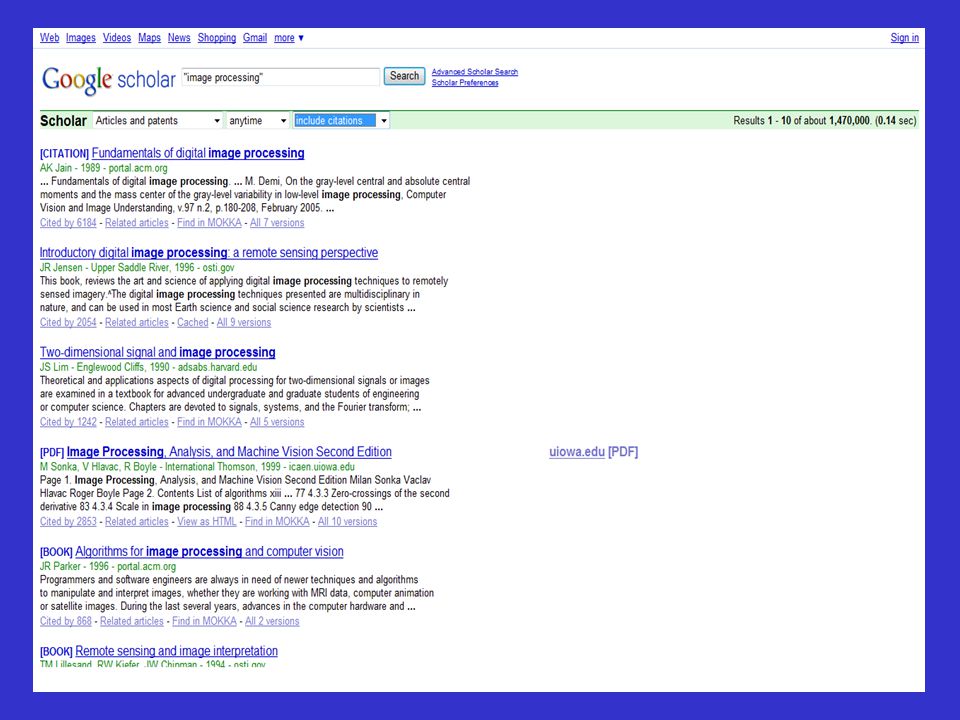











 Egyéb szolgáltatások.>")







