Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Korpusznyelvészet

2
Mi a korpusz?

3
Korpuszdefiníciók MTA Nyelvtudományi Intézet Korpusznyelvészeti Osztályának meghatározása: „A korpusz ténylegesen előforduló írott, vagy lejegyzett beszélt nyelvi adatok gyűjteménye. A szövegeket valamilyen szempont szerint válogatják és rendezik. Nem feltétlenül egész szövegeket tartalmaz, és nem csak tárháza a szövegeknek, hanem tartalmazza azok bibliográfiai adatait, bejelöli a szerkezeti egységeket (bekezdés, mondat). Emellett pedig feltünteti a szavak mellett szófaji kódjukat is.”
. Emellett pedig. feltünteti a szavak mellett szófaji kódjukat is.")
4
Tom McArthur szakirodalmi szócikke szerint:
„A nyelvészetben és lexikográfiában az általában elektronikus adatbázisként tárolt, egy adott nyelvre többé-kevésbé reprezentatívnak tekinthető írott szövegek, szóbeli közlések vagy egyéb minták gyűjteménye.” Nelson Francis definíciója: „az adott nyelvre, dialektusra vagy más nyelvi alcsoportra nézve reprezentatívnak tekintett szövegek gyűjteménye”

5
A korpusz tehát olyan szövegek gyűjteménye, amelyek:
reprezentatívak elektronikus formában tároltak nyelvészei elemzés céljából kerültek kiválogatásra

6
Nem tekintjük korpusznak:
az elektronikus szöveggyűjteményeket (pl. Oxfordi Szövegarchívum) a különböző internetes adatbázisokat (pl. táblázatok, könyvjegyzékek…stb. )
 a különböző internetes adatbázisokat (pl. táblázatok, könyvjegyzékek…stb. )")
7
Miért hozunk létre korpuszokat?
Európa: nyelvészeti elemzések céljából Egyesült Államok: az elemzéseken keresztül a technikai fejlődés elősegítésére (pl. beszédfelismerés)
")
8
A korpusz tervezése Reprezentativitás
Az összegyűjtött anyagnak alkalmasnak kell lennie a kitűzött nyelvi elemzés megvalósítására (pl as és 1990-es évek nyelvének összehasonlítása) Lehetséges-e egyáltalán? (különösen általános korpusznál) Reprezentatív = kiegyensúlyozott (well-balanced) korpusz
 Lehetséges-e egyáltalán (különösen általános korpusznál) Reprezentatív = kiegyensúlyozott (well-balanced) korpusz.")
9
II. Mintavétel Mi kerüljön bele? Minél jobban körülhatárolható kutatásunk tárgya, annál könnyebben lehet döntéseket hozni a korpusz tartalmát illetően. (egyetlen irodalmi mű < egy alkotó összes műve < a regények nyelvezete < egy teljes nyelv)
")
10
Az amerikai nyelv reprezentálására készült
Brown Korpusz Fő kategóriái: Informatív próza (75%) Széppróza (25%)
 Széppróza (25%)")
11
Az informatív próza alkategóriái:
Riport (12%) Vezércikk (7%) Kritika és ismertetés (színház, könyv, zene tánc) (5%) Vallás (5%) Szakismeretek és hobbi (10%) Népszerű ismeretek (13%) Szépirodalom (életrajz, memoár) (20%) Vegyes (8%) Tanult (20%)
 Vezércikk (7%) Kritika és ismertetés (színház, könyv, zene tánc) (5%) Vallás (5%) Szakismeretek és hobbi (10%) Népszerű ismeretek (13%) Szépirodalom (életrajz, memoár) (20%) Vegyes (8%) Tanult (20%)")
12
A széppróza alkategóriái:
Átalános (23%) Detektívregény (19%) Tudományos-fantasztikus (5%) Kalandregény és western (23%) Romantikus és szerelmes regények (23%) Humor (7%)
 Detektívregény (19%) Tudományos-fantasztikus (5%) Kalandregény és western (23%) Romantikus és szerelmes regények (23%) Humor (7%)")
13
Nemzetközi Angol Korpusz International Corpus of English (ICE)
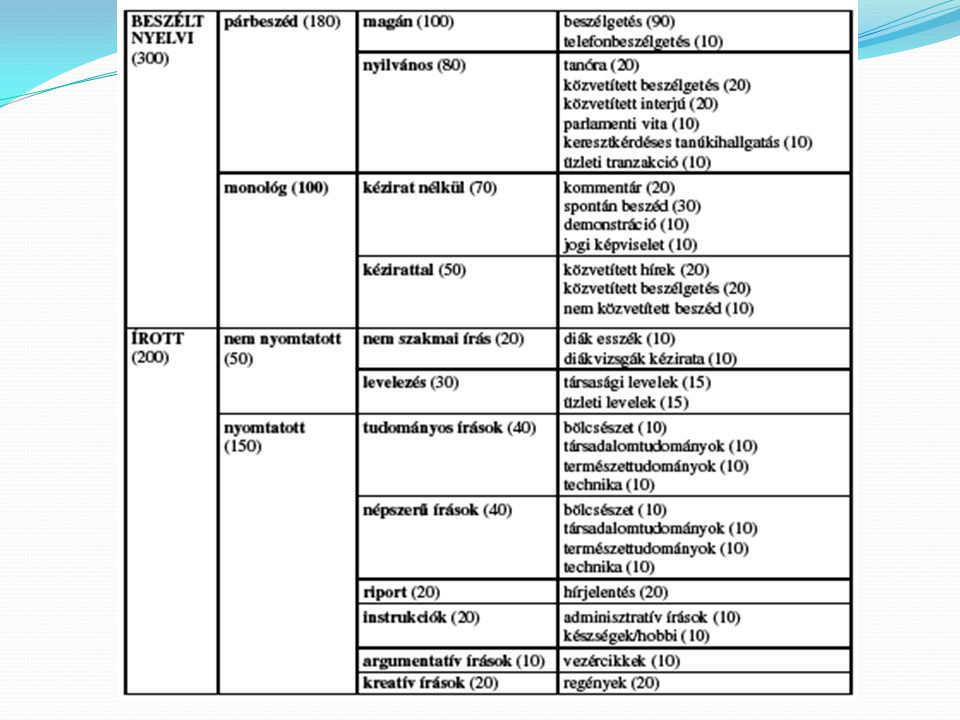
Az egyes alkorpuszok az angol nyelv egy-egy nemzetközi változatának szövegeit tartalmazzák A z összehasonlíthatóság érdekében mindegyik alkorpusz szerkezete egyforma. Minden szöveg kétezer szövegszóból áll, a zárójelben szereplő számok az adott csoportban szereplő szövegek számát jelentik.

15
Magyar Nemzeti Szövegtár (MNSZ)
Az MTA kezdeményezése a magyar nyelv korpusz alapú leírására 1998-ban kezdték el a kutatást, máig tart Jelenleg 150 millió szót tartalmaz célja: „lehetőségeihez mérten reprezentatívan tartalmazza a mai magyar nyelv jellegzetes megnyilvánulásait”

16
III. A korpusz mérete A korpusz mérete jelentősen befolyásolja a kutatás hitelességét Méret = szavak (szóközzel elválasztott egységek) száma - „token” (példány) a szövegben előforduló összes szó - „type” (szóalak, típus) csak a különböző szavak Brown Korpusz: 1 millió szövegszó COBUILD (Collins Birmingham University International Language Databank): jelenleg 500 millió szövegszó
 a szövegben előforduló összes szó. - „type (szóalak, típus) csak a különböző szavak. Brown Korpusz: 1 millió szövegszó. COBUILD (Collins Birmingham University International Language Databank): jelenleg 500 millió szövegszó.")
17
Problémák Ahhoz, hogy egy szót a szövegkörnyezetében megvizsgáljunk, általában nem elég, ha csak egyszer találkozunk vele. A többször előforduló szavak száma nem nő arányosan a korpusz nagyságával. A típusok száma mindent magában foglal: személyneveket, helységneveket, gépelési hibákat, amelyek látszólag új szavakat (típusokat) eredményeznek.
 eredményeznek.")
18
Vannak „csonka” szövegekből álló korpuszok: a nagyobb szövegszerkezeti jellemzőket nem vizsgálhatjuk a segítségükkel. Magyar nyelvű korpuszoknál: lemmatizálás: ugyanannak a szótári egységnek a ragozott változatait (pl. eszem, eszik, ettetek…) egy csoportba vonjuk A szóalakok csoportba vonása több előfordulást vizsgálhatunk
 egy csoportba vonjuk. A szóalakok csoportba vonása több előfordulást vizsgálhatunk.")
19
A korpuszok fajtái és annotációk

20
A korpuszok fajtái A mintavétel módja szerint: Statikus korpusz
Dinamikus korpusz Monitor korpusz A felhasználás módja szerint Általános korpusz Speciális korpusz Összehasonlító korpusz Párhuzamos korpusz Fordítói korpusz Nyelvtanulói korpusz Pedagógiai korpusz Történeti v. diakrón korpusz

21
A mintavétel módja szerint

22
Statikus korpusz Változatlan korpuszok Pl: Brown, LOB
Azért jó, mert a nyelvet egy bizonyos időpontban mintegy pillanatfelvételként ábrázolja Összehasonlító kutatásokhoz tökéletes

23
Dinamikus korpusz Folyamatosan bővül
Állandó a növekedés, de az arányok megmaradnak Pl: Cobuild Korpusz

24
Monitor korpusz Statikus és dinamikus kombinációja
Az eredeti korpusz arányait nem felborítva adnak még hozzá szövegeket Így a hozzáadott elemek is összehasonlíthatók az eredeti korpusszal Sinclair

25
A felhasználás módja szerint

26
Általános korpusz Célja egy adott nyelv minél hitelesebben történő reprezentálása Lexikológusoknak fontos Nyelvtanok, nyelvleírások is ez alapján készülnek Viszonyítási alapként is lehet használni Pl: Bank of English, BNC

27
Speciális korpusz Tulajdonképpen minden, ami eltér az általánostól
A vizsgálat céljának és tárgyának megfelelően kell kiválasztani az anyagot és korpuszba rendezni pl: egy társadalmi réteg nyelvének vizsgálata Pl: Hongkongi Társalgási Angol Nyelv Korpusza, Cambridge and Notthingham Corpus of Discourse in English

28
Összehasonlító korpusz
Bármilyen korpusz, ha azonos szempontok szerint állították össze és méretük is azonos, összehasonlítható Pl: LOB, Kolhapur Corpus of Indian English, Freiburg Korpusz, Australian Corpus of English

29
Párhuzamos korpusz Azonos szövegek különböző nyelvi fordításai (ebben az eredeti is benne van) Fordítói korpusz: csak fordításokra, egynyelvű, eredeti műveket nem tartalmaz Pl: francia regények magyar fordításai

30
Nyelvtanulói korpusz Egy bizonyos nyelvet idegenként tanulók által létrehozott szövegek gyűjteménye Tartalmazhat szóbeli megnyilatkozásokat is Pl: International Corpus of Learner English Horváth József PTE angol szakosok esszéiből készített korpuszt (2000)
")
31
Pedagógiai korpusz Olyan szövegek gyűjteménye, amelyekkel a nyelvtanuló tanulmányai során találkozott DE! ez így nem használható Helyette: Az adott kurzuson előkerülő szövegek halmaza

32
Történeti vagy diakrón korpusz
Az adott nyelv történeti változásainak következtében, a múltbeli adatok feldolgozásával létrejött korpusz Célja: nyelv változásának követése Pl: International Computer Archive of Modern and Medieval English Magyar Történeti Korpusz (MTA oldalán)
")
33
Átírás és annotáció Létezik néhány olyan korpusz, ami a lehető legpontosabban kívánja visszaadni az élőbeszédet. Pl: Lancaster – IBM Spoken English Corpus Az átírás időigényes és szakértelmet kíván sok probléma! Hangfelismerés Automatizált átírás

34
A standard annotáció Korpuszannotációnak nevezünk minden olyan információt és jelet, amelyet az eredeti szöveg nem tartalmazott, de a korpusz készítésekor a szövegbe került. A korpuszban megjelenő leggyakoribb annotáció a szófajmegjelölés.

35
Az MNSZ alapkódjai

36
Speciális annotációk Ortografikus Fonetikus / fonémikus Prozodikus
Szemantikai Diskurzus Pragmatikai / stilisztikai

37
Az izoláló nyelveket a legkönnyebb annotálni.
Bárki bármilyen annotációt készíthet csak egyértelműnek kell lenni a jelölésnek és hogy melyik elemre utal. Az izoláló nyelveket a legkönnyebb annotálni. Az agglutináló nyelvek esetében szükség van morfológiai annotációra is. Prószéky HuMor – helyesírási elemző programhoz használják, önállóan nem alkalmazzák

38
Angol nyelvű korpuszok

39
Az elektronikus korpuszok előfutárai
I. Modern, nem elektonikus korpuszok 1.1 A szerb nyelv korpusza

40
Đorđe Kostić az 1950-es évek: a gépi fordítás, automatikus szöveg- és beszédfelismerés problémáit probabilisztikus módszerekkel lehet megoldani a korpusz létrehozása Az eredeti korpusz: 11 millió szó, a 12. századtól Kostić koráig terjedő szövegek

41
A korpuszban minden szót lemmatizáltak,
A korpuszban minden szót lemmatizáltak, a nyelvtanra vonatkozó információkat egy hat számjegyből álló kóddal írták le. A gépi fordítás tanulmányozása céljából nem csak szerb, hanem angol, német és francia szövegeket is feljegyeztek A 60-as évek elején a projekt abbamaradt, de 1996-ban sikerült újraéleszteni

42
1.2. A SEU Korpusz (Survey of English Usage Corpus)
Randolph Quirk 1959-ben megalapította a Survey of English Usage-ot A korpusz CD-ROM-on az International Computer Archive of Modern English-től (ICAME) szerezhető be A korpusz segítségével: a felnőtt, iskolázott brit lakosság nyelvtani és szóhasználati szokásait akarták vizsgálni
 szerezhető be. A korpusz segítségével: a felnőtt, iskolázott brit lakosság nyelvtani és szóhasználati szokásait akarták vizsgálni.")
43
A korpusz összesen egymillió szóból áll
A szövegek egyik fele írott, a másik fele pedig beszélt nyelvi adatokat tartalmaz, melyek kissé formálisak és tudományosak (például sajtószövegek, tudományos szövegek, magánlevelek, telefonbeszélgetések, sportkommentárok)
")
44
1.3. A Brown Korpusz (1964) teljes nevén Brown University Standard Corpus of Present-DayAmerican English a világ első elektronikus korpusza szövegszó a teljes korpusz számos nyelvész követte a Brown Korpusz példáját, amikor saját korpuszukat megalkották

45
Néhány Brown-korpusz mintájára készült korpusz: • Lancaster–Oslo/Bergen Corpus (LOB), brit angol • Kolhapur Corpus of Indian English (KOL), indiai angol • Freiburg–LOB Corpus (FLOB), brit angol • the Corpus of English-Canadian Writing, kanadai angol
, brit angol • Kolhapur Corpus of Indian English (KOL), indiai angol • Freiburg–LOB Corpus (FLOB), brit angol • the Corpus of English-Canadian Writing, kanadai angol")
46
1.4. A LOB Korpusz Létrehozó: az Oslói Egyetem, valamint a Bergenben működő Norvég Társadalomtudományi Számítástechnikai Központ (Norwegian Computing Centre for the Humanities) A Brown Korpusszal összehasonlítható, brit angol nyelvű korpusz, a szövegeket a Brown Korpusz szövegeivel azonos évből, 1961-ből válogatták.
 A Brown Korpusszal összehasonlítható, brit angol nyelvű korpusz, a szövegeket a Brown Korpusz szövegeivel azonos évből, 1961-ből válogatták.")
47
1.5. A COBUILD projekt 1980-ban kezdte meg a Birminghami Egyetem és a Collins Publishers nevű kiadó ezt a közös projektet Két fő célja: 1) nagy terjedelmű, számítógéppel feldolgozott modern angol nyelvű korpusz gyűjtése és elemzése 2) az eredmények publikálása az angolt idegen nyelvként tanuló diákok és oktató tanárok számára készült referencia és oktató könyvek széles skáláját létrehozva
 nagy terjedelmű, számítógéppel feldolgozott modern angol nyelvű korpusz gyűjtése és elemzése. 2) az eredmények publikálása az angolt idegen nyelvként tanuló diákok és oktató tanárok számára készült referencia és oktató könyvek széles skáláját létrehozva.")
48
A COBUILD projekt első eredményeként kiadott korpusz-alapú szótár, a Collins COBUILD English language dictionary az EFL (angol mint idegen nyelv) piacon változás A korpusz tervezése és az engedélyek beszerzése 1980-ban kezdődött
 piacon változás A korpusz tervezése és az engedélyek beszerzése 1980-ban kezdődött")
49
Az első korpusz: Main Corpus (Fő korpusz) volt, 7,3 millió szó
1985: Reserve Corpus (Tartalék Korpusz) 11 millió szó 1991: Bank of English (Az angol nyelv tárháza) A folyamatos hozzáadások 1993-ra már 120 millió, 1994-re 167 millió, 1995-re pedig több mint 320 millió szóra növekedett ez a korpusz A Bank of English jelenleg 524 millió szóból áll és állandóan növekszik, ennek a COBUILD Direct Corpus nevű része interneten elérhető
 11 millió szó. 1991: Bank of English (Az angol nyelv tárháza) A folyamatos hozzáadások 1993-ra már 120 millió, 1994-re 167 millió, 1995-re pedig több mint 320 millió szóra növekedett ez a korpusz. A Bank of English jelenleg 524 millió szóból áll és állandóan növekszik, ennek a COBUILD Direct Corpus nevű része interneten elérhető.")
50
A COBUILD projekt célja nem csak referenciakönyvek kiadása volt, hanem a korpuszra épülő pedagógiai jellegű segédkönyvek és tankönyvek megjelentetése is: az egyes tankönyvekben szereplő tanításra szánt szavak kiválogatásakor a korpuszelemzések eredményeit vették figyelembe Willis házaspár Collins COBUILD Course of English (1988) című tankönyvsorozata
 című tankönyvsorozata")
51
1.6. A Brit Nemzeti Korpusz – British National Corpus (BNC)
számos intézmény és kiadó együttműködésének eredménye A BNC 4124 szöveget tartalmaz, melynek 90%-a írott eredetű, és mindössze 10%-a származik a beszélt nyelvből

52
A beszélt nyelvi korpuszt a:
Beszélők kora beszélők neme Beszélők társadalmi osztálya/helyzete az ország területi megoszlása szerint,

53
(A szövegek 1960–1974 és 1975–1993 között születtek)
az írott szövegeket pedig: az időpont, a médium, és a tartalom alapján választották ki (A szövegek 1960–1974 és 1975–1993 között születtek)
")
54
A teljes korpuszt nyelvtani címkékkel látták el
A korpusz magjának (Core Corpus) nevezett rész, valamint a teljes, 100 millió szóból álló BNC CD-ROM-on megvásárolható, díj ellenében az interneten keresztül is lehet használni
 nevezett rész, valamint a teljes, 100 millió szóból álló BNC CD-ROM-on megvásárolható, díj ellenében az interneten keresztül is lehet használni.")
55
1.7. Az Angol Nyelv Nemzetközi Korpusza (International Corpus of English – ICE)
1988 Sydney Greenbaum javaslata: nagyméretű korpusz készítése összehasonlító nyelvészeti célokkal, amely az angol nyelv összes változatát tartalmazza

56
A korpuszban minden egyes alkorpuszt egymillió szóra terveztek, és mind beszélt, mind írott szövegeket tartalmaz A szövegek az 1990–1996 közötti időszakból származnak Az első(brit angol) alkorpusz szerkezete hasonlít a LOB és a Brown Korpuszéhoz, de! a LOB és a Brown Korpusz szövegei mind írott szövegek voltak, az ICE esetében viszont az írott és beszélt szövegek aránya 60% és 40%
 alkorpusz szerkezete hasonlít a LOB és a Brown Korpuszéhoz, de! a LOB és a Brown Korpusz szövegei mind írott szövegek voltak, az ICE esetében viszont az írott és beszélt szövegek aránya 60% és 40%")
57
Az ICE tanulmányozására külön számítógépes program
A korpuszt nem csak a szövegre vonatkozó információkkal, hanem szófaji címkékkel és a mondattani elemzés címkéivel is ellátták Az ICE brit angol korpuszából 10 szöveg ingyenesen letölthető, a teljes korpusz megvásárolható CD-ROM-on

58
1.8. A nem anyanyelvi angol korpuszok
Az angolt idegen nyelvként tanuló diákokat kiszolgáló kiadóknak és egyéb oktatási intézményeknek információra van szüksége ahhoz, hogy még jobban igazodhassanak a diákok eltérő igényeihez nem anyanyelvi korpuszok

59
A nem anyanyelvi beszélők produktumaiból készített korpusz lényege: sokat segíthet a idegennyelv-tanításban, hiszen fontos információkkal szolgálhat a helyesen és helytelenül használt nyelvtani vagy szókincsbeli, esetleg szövegszerkesztési hibákról.

60
1.8.1. A Longman Angol Nyelvtanulói Korpusz – Longman Corpus of Learners’ English (LCLE)
A Longman Learners’ Corpus részét képezi a Longman Corpus Networknek LCLE kb. 10 millió szóból áll, és azzal a céllal készült, hogy segítse a tudományos kutatást, valamint a lexikográfiai és más oktatási jellegű művek kiadását A korpusz 8 különböző tudásszintű, 160 különböző nyelvi háttérrel rendelkező diák szövegeit tartalmazza.

61
1.8.2. A Nemzetközi Angol Nyelvtanulói Korpusz (International Corpus of Learners’ English (ICLE)
különböző nemzetiségű, haladó szinten álló nyelvtanulók írott szövegeinek gyűjteménye Jelenleg 19 alkorpuszból áll, melyek egyenként szót tartalmaznak

62
1.8.3 Hong Kong University of Science and Technology [HKUST] Corpus of Learner English
A tanulói korpusz mellett öt témakörben angol nyelvű tankönyvek felhasználásával egyenként kb. 1 millió szavas korpuszokat is tartalmaz Tanulói korpusz: azonos anyanyelvű beszélők által írt nyelvtanulói szövegek
![1.8.3 Hong Kong University of Science and Technology [HKUST] Corpus of Learner English](http://slideplayer.hu/slide/2103675/8/images/62/1.8.3+Hong+Kong+University+of+Science+and+Technology+%5BHKUST%5D+Corpus+of+Learner+English.jpg "A tanulói korpusz mellett öt témakörben angol nyelvű tankönyvek felhasználásával egyenként kb. 1 millió szavas korpuszokat is tartalmaz. Tanulói korpusz: azonos anyanyelvű beszélők által írt nyelvtanulói szövegek.")
63
1.8.4. Japán diákok angol nyelvű korpuszai
Tono Yukio az egyik korai korpusza segítségével vizsgálta a diákok által a kollokációk terén elkövetett hibákat. Tono elemzései rámutattak, hogy a hibák nagy része az anyanyelv (L1) hatásából eredt.
 hatásából eredt.")
64
1.8.5. A Janus Pannonius Tudományegyetem Korpusza
Horváth József egy szavas korpuszt hozott létre diákjai írásaiból (JPU Corpus)
")
65
1.8.6. Az Eötvös Loránd Tudományegyetem Korpusza
Tankó Gyula diákjainak vizsgafeladatként írt esszéit gyűjtötte össze és kötőelemek vizsgálatának céljára használta fel. 93 darab, egyenként kb. 500 szavas esszé

66
1.9. A korpuszok nyelvenként
További angol nyelvű korpuszok A Brown Korpusz klónjai • Lancaster–Oslo/Bergen Corpus (LOB) • Kolhapur Corpus of Indian English (KOL) (Shastri, 1988) • Freiburg–Brown Corpus (FROWN) és Freiburg–LOB Corpus (FLOB) • Australian Corpus of English (ACE) (Macquarie Corpus of Written Australian English) • the Wellington Corpus of Written New Zealand English (Bauer, 1993a) • the International Corpus of English (ICE) (Greenbaum, 1992; Leitner, 1992a) • the Corpus of English-Canadian Writing
 • Kolhapur Corpus of Indian English (KOL) (Shastri, 1988) • Freiburg–Brown Corpus (FROWN) és Freiburg–LOB Corpus (FLOB) • Australian Corpus of English (ACE) (Macquarie Corpus of Written Australian English) • the Wellington Corpus of Written New Zealand English (Bauer, 1993a) • the International Corpus of English (ICE) (Greenbaum, 1992; Leitner, 1992a) • the Corpus of English-Canadian Writing.")
67
A Brown Korpusz klónjai azzal a céllal készültek, hogy az amerikai angol nyelvvel összehasonlíthassák az angol nyelv különböző változatait: az indiai, ausztrál, új-zélandi és kanadai angolt A klónok közül a kivételek a Freiburg–Brown (FROWN) Korpusz, és a Freiburg–LOB (FLOB) Korpusz, melyek nem a nyelvterületek eltérő nyelvhasználatának összehasonlítása céljából, hanem az időbeli összehasonlítás céljából készültek
 Korpusz, és a Freiburg–LOB (FLOB) Korpusz, melyek nem a nyelvterületek eltérő nyelvhasználatának összehasonlítása céljából, hanem az időbeli összehasonlítás céljából készültek.")
68
1.9.1.2. Könyvkiadók korpuszai
a Collins COBUILD English Language Dictionary megjelenése után a kiadók igyekeztek saját korpuszt létrehozni, hogy az anyanyelvi beszélők nyelvhasználatának pontosabb leírása és a tanulói korpuszok hibáinak elemzése eredményeképpen jobb szótárakat és nyelvkönyveket készíthessenek a nyelvtanulók számára

69
Ezek a korpuszok csak az adott kiadónak dolgozó szerzők számára érhetők el
Könyvkiadók korpuszai: Longman Corpus Network Cambridge Nemzetközi Korpusz – Cambridge International Corpus (CIC)-Cambridge-i Egyetemi Könyvkiadó (brit, amerikai és nyelvtanulói angol korpuszok)
-Cambridge-i Egyetemi Könyvkiadó (brit, amerikai és nyelvtanulói angol korpuszok)")
70
A Macmillan Kiadó: World English Corpus – Világ Angol Korpusz
kb. 220 milliós korpusz, összetevői: 1) Brit angol; 2) Amerikai angol; 3) Világ angol; 4) nyelvtanulói szövegek; 5) az angol mint idegen nyelv tanításához használt anyagok. A korpuszt kizárólag a kiadó használja
 Brit angol; 2) Amerikai angol; 3) Világ angol; 4) nyelvtanulói szövegek; 5) az angol mint idegen nyelv tanításához használt anyagok. A korpuszt kizárólag a kiadó használja.")
71
1.9.1.3. Történeti nyelvészeti korpuszok
A történeti nyelvészeti korpuszok nem változnak vagy csak nagyon ritkán A történeti jellegű korpuszok esetében a helyesírási változatok okozhatnak gondot a keresés során Számos projekt van folyamatban, amelyeknek az a közös célja, hogy az angol nyelv változását a nyelv fejlődésének valamennyi fázisában elemezze

72
Történelmi korpuszok:
The York–Helsinki Parsed Corpus of Old English Poetry (York–Helsinki Óangol Költészet Korpusza) szóból áll, szintaktikailag és morfológiailag elemzett The York–Toronto–Helsinki Parsed Corpus of Old English Prose (York–Toronto–Helsinki Szintaktikailag Elemzett Óangol Prózai Korpusz)
 szóból áll, szintaktikailag és morfológiailag elemzett. The York–Toronto–Helsinki Parsed Corpus of Old English Prose (York–Toronto–Helsinki Szintaktikailag Elemzett Óangol Prózai Korpusz)")
73
The Brooklyn–Geneva–Amsterdam–Helsinki Parsed Corpus of Old English (Brooklyn–Geneva–Amsterdam–Helsinki Szintaktikailag Elemzett Óangol Korpusza), szó The Penn–Helsinki Parsed Corpus of Middle English (Penn–Helsinki Szintaktikailag Elemzett Közép Angol Korpusza): két kiadása is létezik. Közép angol prózai szövegek gyűjteménye, melyet díj ellenében bárki használhat.
: két kiadása is létezik. Közép angol prózai szövegek gyűjteménye, melyet díj ellenében bárki használhat.")
74
The Parsed Corpus of Early English Correspondence (A Szintaktikailag Elemzett Korai Angol Levelezés Korpusza): a Yorki és a Helsinki Egyetem kutatói, kb. 2 millió szó The Penn–Helsinki Parsed Corpus of Early Modern English (Penn–Helsinki Szintaktikailag Elemzett Korai Modern Angol Korpusz): Pennsylvania Egyetemen Anthony Kroch és Beatrice Santorini
: Pennsylvania Egyetemen Anthony Kroch és Beatrice Santorini.")
75
A magyar nyelvű korpuszok

76
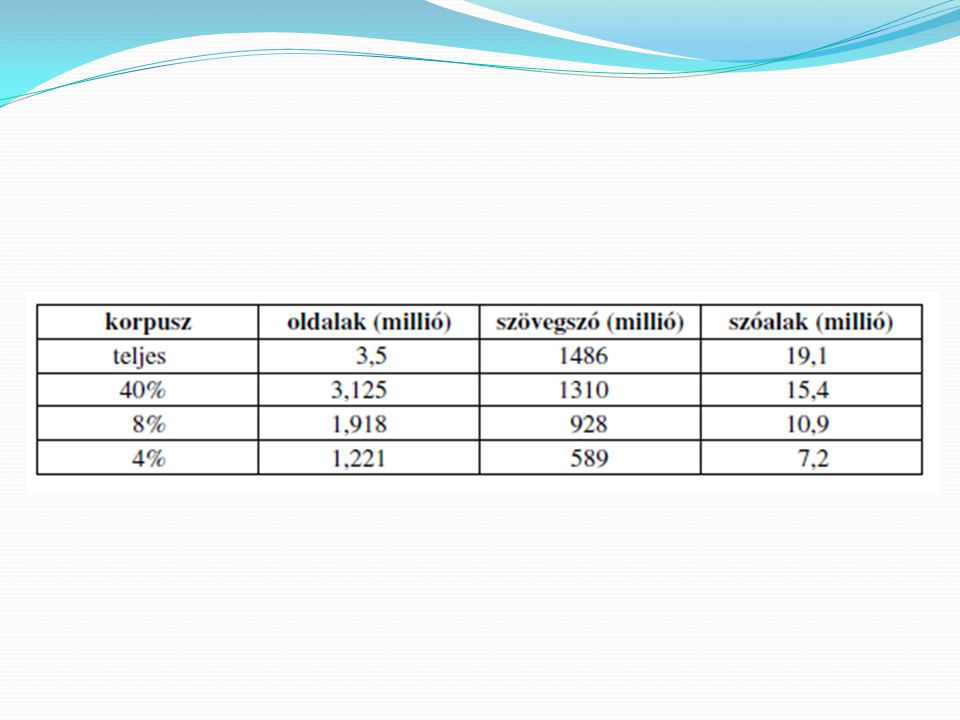
A Magyar Nemzeti Szövegtár (MNSZ)
Azzal a céllal lett létrehozva, hogy reprezentatívan tartalmazza a mai magyar nyelv jellegzetes megnyilvánulásait. A korpusszal kapcsolatos munkálatokat 1998-ban kezdték meg, jelenleg 153,7 millió szövegszóból áll. Az itt megtalálható szövegek típusai a következők: hivatalos, tudományos, szépirodalmi, sajtó, személyes.

77
A korpusz 153 782 228 szövegszóból áll.
Összesítve a korpusz 53%-át a sajtó szövegei teszik ki, ami az anyagok könnyű hozzáférhetőségével is magyarázható. A szépirodalom kategória a Digitális Irodalmi Akadémia szövegeit tartalmazza, ezt folyamatosan bővítik. 40 millió szóra tervezik, és az MNSZ részét fogja képezni. A tudományos szövegek a Magyar Elektronikus Könyvtárból származnak.

78
A hivatalos alkorpusz többek között törvényeket, parlamenti vitákat és szabályokat tartalmaz.
A személyes alkorpusz az index.hu internetes fórum szövegeit tartalmazza. Stílusából adódóan a spontán történő élőbeszéd érzetét kelti az olvasóban. A teljes korpusz anyaga tehát kizárólag írott szövegekből áll, semmilyen beszélt nyelvi alkorpuszt nem foglal magába.

79
Mivel a magyar nyelvet a határon túl is sokan beszélik, tervbe van véve a Határon Túli Korpusz megalkotása, melyet 15 millió szövegszóra terveznek. Ebből a 15 millióból 6 millió Románia, 4 millió Szlovákia, 3 millió Ukrajna és 2 millió a Vajdaság területéről került a korpuszba 2005 végéig. Ezekben az országokban az adatgyűjtést azok a nyelvészek végezték, akik a Magyar Tudományos Akadémia Nyelvtudományi Intézete által működtetett Nyelvi Irodákban dolgoznak, az adatfeldolgozást és a kutatást azonban a budapesti MTA Nyelvtudományi Intézet végzi.

80
A korpusz itt található: http://www.nytud.hu/hhc/
A Magyar Irodalmi és Köznyelv Nagyszótárának korpusza / Magyar Történeti Korpusz Ez a korpusz az 1772 és a 2000 közötti szövegeket tartalmazza, melyek összesen 25 millió közötti szövegszót tesznek ki. A XVIII. századból 2 millió szó, a XIX. századból 7 millió, a XX. századból pedig 16 millió szó került a korpuszba. Ez több mint 200 szerzőtől származik és mű részletét jelenti. A szövegek közt található próza (mely 31%-ban szépirodalom), szerepel benne vers és dráma is. A korpusz itt található:
, szerepel benne vers és dráma is. A korpusz itt található:")
81
A keresés nem csak a teljes korpuszon elvégezhető, hanem tetszés szerint adott szempontok alapján az általunk kiválasztott területeken is.

83
Találatok:

84
A keresett szó, vastagon szedve a lap közepén jelenik meg, és nem csak az alapszó, hanem annak toldalékos alakjai is megjelennek. A sor elején levő számra kattintva bővebb kontextusban figyelhetjük meg a keresett szót, és az előfordulásának pontos helyéről is felvilágosítást kapunk.

85
Szeged Korpusz A következő honlapon található meg: A honlap adatai szerint a korpusz 1,2 millió szövegszóból áll, és 167 ezer szóalakot tartalmaz, melyeket főként morfológiailag elemeztek. Az első változat szeptember 1. és június 30. között készült, a második változatot egy szavas üzleti szövegeket tartalmazó résszel egészítették ki.

86
A korpusz egyenként kb. 200–200 ezer szavas szövegeket tartalmaz öt kategóriában, melyek:
Tizenévesek fogalmazásai (8. és 10. osztályos tanulók fogalmazásai két témában). Irodalmi alkotások (3 regény, de nem teljes művek). Számítástechnikai témájú szövegek Újságok (a Magyar Hírlap, a Népszabadság, a Népszava, és a HVG egy-egy teljes száma 1999-ből). Jogi szövegek (a CD Jogtár: Hatályos magyar jogszabályok CD-ROM-ról).
. Irodalmi alkotások (3 regény, de nem teljes művek). Számítástechnikai témájú szövegek. Újságok (a Magyar Hírlap, a Népszabadság, a Népszava, és a HVG egy-egy teljes száma 1999-ből). Jogi szövegek (a CD Jogtár: Hatályos magyar jogszabályok CD-ROM-ról).")
87
A Szeged Korpusz összefoglaló adatai

88
Magyar dalszövegek A magyar dalszövegek egy nagyobb korpusz részét képezik, mely más nyelvek dalszövegeit is tartalmazza. A korpusz itt található meg: A magyar dalszövegek itt megtekinthetőek:

89
CHILDES database magyar nyelvű korpusza
Ez az adatbázis a gyerekek nyelv- és társalgási készségük fejlődésének vizsgálatát teszi lehetővé. A tárolás mellet az átírt anyagok számítógépes elemzéséhez szükséges programok és egyéb segédprogramok is ingyenesen a kutatók rendelkezésére állnak. Az adatbázis nagy része angol nyelvű, de helyet kapott benne 22 más nyelvű adatbázis is, köztük magyar is.

90
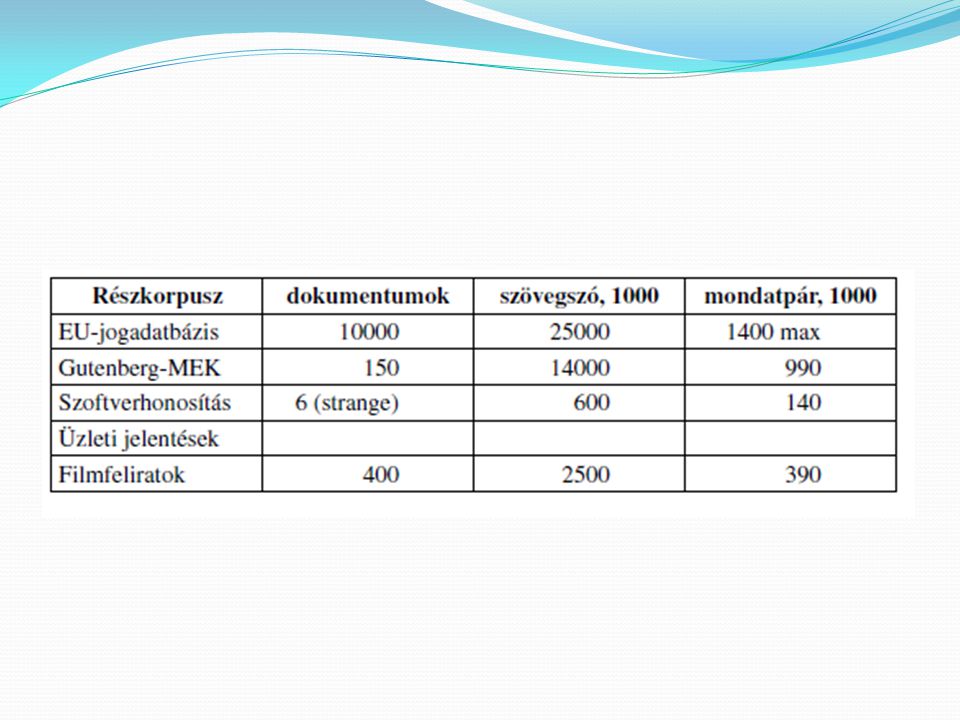
A Hunglish Korpusz A Média Oktató és Kutató Központ (MOKK) által készített korpusz magyar és angol szövegek párhuzamos tára, melyet 50 millió szövegszóra terveztek. Ezen a címen elérhető: A szövegek egyrészt az interneten hozzáférhető forrásokból, másrészt honosítási projektek szövegekből erednek.
 által készített korpusz magyar és angol szövegek párhuzamos tára, melyet 50 millió szövegszóra terveztek. Ezen a címen elérhető: A szövegek egyrészt az interneten hozzáférhető forrásokból, másrészt honosítási projektek szövegekből erednek.")
92
A Magyar Webkorpusz A korpuszt 2003-ban szintén a MOKK készítette.
A szövegek mindenféle gondos válogatás nélkül, automatizált szűrés útján kerültek bele az internetről. A korpusz mérete ebből adódóan hatalmas. Innen nemcsak az eredeti szövegek, hanem a belőlük készült gyakorisági szótárak is, valamint a MOKK lapjáról egy nyílt morfológiai programcsomag is letölthető.

Hasonló előadás