Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Dobszayné Hennel Judit Ménesi Éva 2013. Szeptember
Kisterületi becslés – szegénység térkép a Világbank módszertanának hazai adaptálása Dobszayné Hennel Judit Ménesi Éva 2013. Szeptember

2
Tartalom A projekt ismertetése, célok, kapcsolatfelvétel
A módszertan elméleti ismertetése A hazai adaptálás – kihívások és megvalósítás Az első fázis eredményei Következő lépés, távlati hasznosítás lehetőségei

3
A projekt bemutatása Európai Bizottság felkérésére EU 10 tagállamában
Cél: területileg célzott támogatás rendszer kialakítása Világbank Elbers-Lanjouw-Lanjouw módszer – kb. 20 éves tapasztalat, 60 országban Indulás: Világbank kezdeményezésére március Szakértői egyeztetés június, projekt indulása szeptember Hazai szakemberek által, Világbank szakértők támogatásával Az adatok használatáért Világbank részéről költség térítés 2 fázisban: évi mikrocenzus és évi EU-SILC felvétel adatainak használatával évi népszámlálás és évi EU-SILC adataival

4
4 4 16% of the population in the EU27 at risk of income poverty,…
Looking at each of the three elements defining at risk of poverty or social exclusion, 16% of the population in the EU27 in 2010 were at-risk-of-poverty after social transfers, meaning that their disposable income was below their national at-risk-of-poverty threshold. The highest at-risk-of-poverty rates were observed in Latvia, Romania, Bulgaria and Spain (all 21%), and the lowest in the Czech Republic (9%), the Netherlands (10%), Slovakia, Austria and Hungary (all 12%). …8% severely materially deprived … In the EU27, 8% of the population were severely materially deprived, meaning that they had living conditions constrained by a lack of resources such as not being able to afford to pay their bills, keep their home adequately warm, or take a one week holiday away from home. The share of those severely materially deprived varied significantly among Member States, ranging from 1% in Luxembourg and Sweden to 35% in Bulgaria and 31% in Romania. … and 10% living in households with very low work intensity Regarding the indicator on low work intensity, 10% of the population aged 0-59 in the EU27 lived in households where the adults worked less than 20% of their total work potential during the past year. The United Kingdom and Belgium (both 13%) had the largest proportions of those living in very low work intensity households, and Luxembourg, Sweden and the Czech Republic (all 6%) the lowest. 4
, and the lowest in the Czech Republic (9%), the Netherlands (10%), Slovakia, Austria and Hungary (all 12%). …8% severely materially deprived … In the EU27, 8% of the population were severely materially deprived, meaning that they had living conditions. constrained by a lack of resources such as not being able to afford to pay their bills, keep their home adequately. warm, or take a one week holiday away from home. The share of those severely materially deprived varied. significantly among Member States, ranging from 1% in Luxembourg and Sweden to 35% in Bulgaria and 31% in. Romania. … and 10% living in households with very low work intensity. Regarding the indicator on low work intensity, 10% of the population aged 0-59 in the EU27 lived in households. where the adults worked less than 20% of their total work potential during the past year. The United Kingdom. and Belgium (both 13%) had the largest proportions of those living in very low work intensity households, and. Luxembourg, Sweden and the Czech Republic (all 6%) the lowest. 4.")
5
Igény a területi szintű adatok iránt
5 Mind hazai mind nemzetközi szinten egyre növekvő igény a területi szintű adatok iránt; területi különbségek kiéleződése; fejlesztési erőforrások hatékonyabb felhasználása EU-SILC – magyarországi mintanagyság kb ht. NUTS1 szinten szolgáltat adatot; NUTS2 (régió) szinten kiszámítható, de nem közöljük EU-SILC: a jövedelem adat mellett számos változót tartalmaz, azonban a mintanagyság túl kicsi már a NUTS3 (megye) szintű becsléshez is Népszámlálás/Mikrocenzus: a kisterületi becsléshez megfelelő számú elemszámmal rendelkezik, de nem tartalmaz jövedelmi adatot 5
 szinten kiszámítható, de nem közöljük. EU-SILC: a jövedelem adat mellett számos változót tartalmaz, azonban a mintanagyság túl kicsi már a NUTS3 (megye) szintű becsléshez is. Népszámlálás/Mikrocenzus: a kisterületi becsléshez megfelelő számú elemszámmal rendelkezik, de nem tartalmaz jövedelmi adatot. 5.")
6
A cenzus és az adatgyűjtés összekapcsolása
Statisztikai modell eljárás segítségével a Cenzus állományba imputálunk jövedelem változót (log) Ugyanazt a jövedelmi koncepciót alkalmazza mint a hagyományos adatgyűjtések A statisztikai megbízhatóság jól becsülhető Nagyon komoly követelmény rendszer a felhasznált adatokkal szemben
 Ugyanazt a jövedelmi koncepciót alkalmazza mint a hagyományos adatgyűjtések. A statisztikai megbízhatóság jól becsülhető. Nagyon komoly követelmény rendszer a felhasznált adatokkal szemben.")
7
Adatkövetelmények Cenzus és adatgyűjtés azonos változókat kell tartalmazzon (azonos kérdések tartalmilag, formailag) A közös változók és a jövedelem nagyság között erős kapcsolat kell fennálljon A cenzus és adatgyűjtés klaszter szinten legyen összekapcsolható Cenzus/Mikrocenzus teljes körű vagy nagymintás legyen Klaszter szinten legyen lehetőség esetleges külső adatforrás bekapcsolására

8
Hazai adaptálás lépései
POVMAP szoftver installálása Világbank belső fejlesztésű szoftvere, ingyenesen letölthető Telepítés során a szükséges IT környezet dokumentálatlansága miatt számos nehézség Modellezési munkával párhuzamosan több szoftver verzió tesztelése zajlott (zajlik)
")
9
Adatelőkészítés 1. Területi hierarchikus azonosítók kialakítása
Aggregációs szintek:1. régió 2.megye 3.országgyűlési választó kerület 4. Település 5. számláló körzet 6. címsorszám és háztartás szám Problémák: Mikrocenzus nem hierarchizált területi azonosítása Max 15 egység az aggregációs szintre Elvégzett feladat: Mikrocenzus területi azonosítóinak átkonvertálása A területi azonosítók átkódolása, hogy 15 egység elegendő legyen az egyedi azonosításhoz Közös változók kijelölése:Demográfia; Iskolázottság; Foglalkoztatottság Lakásjellemzők; Fogyasztási javak Változók kompatibilitásának vizsgálata Azonos meghatározás, tartalom és eloszlás 2011-ben ez alaposabb vizsgálatot igényel majd! Változókör kijelölés, gyakorisági táblák összehasonlítása, változók létrehozása majd összevonások végrehajtása

10
Adatelőkészítés 2. Folyamatos változókból->Kategória változók pld:TEÁOR Folyamatos változók esetében:ht átlag, ht max. Hiányzó értékek kezelése Változók létrehozása a háztartásfő szintjén Dummy változók egy-egy jellemző, fontos gazdasági körülményt meghatározó jellemző leírására Külső adatforrás: T-STAR állománya 100 változót vizsgáltunk, Ebből 60-at vontunk be az állományba További 50 változót képeztünk - pld:átlagos Szja a 18 év felettiekre vetítve, alap-,közép-, felső fokú végzettségűek aránya a munkanélküliek között, 0-17 éves népesség aránya a településen, stb. A teljes adat előkészítő munka a POVMAP szoftveren kívül SPSS és SAS segítségével zajlott

11
Modell építés 1. Béta modell
Függő változó – OECD2 skála szerint ekvivalizált jövedelem logaritmusa Regresszorok – folytonos változók, kategória változók, dummy-k, képzett változók (területi szint – kategória/folyamatos változók kombinációi) Korreláció ellenőrzése, multikollinearitás vizsgálata R2 értékének vizsgálata 2. Klaszter hatás vizsgálata: Klaszterenként a reziduumok Függő változó tényleges és becsült értékeinek pontdiagramja Klaszter hatás kumulált eloszlása 3. Alpha modell: Háztartás hatás becslése GLS file; Szignifikancia szint ellenőrzése Visszacsatolás – iteráció; modell változtatás/új modell építés indítása a Béta modell szintjéről Modell építés az adatgyűjtés állományán zajlik – kellően robusztus modell esetén történik a szimuláció, amikor a létrejött függvényt a cenzus/mikrocenzus állományon futtatva létrejön egy lehetséges becslés
 Korreláció ellenőrzése, multikollinearitás vizsgálata. R2 értékének vizsgálata. 2. Klaszter hatás vizsgálata: Klaszterenként a reziduumok. Függő változó tényleges és becsült értékeinek pontdiagramja. Klaszter hatás kumulált eloszlása. 3. Alpha modell: Háztartás hatás becslése. GLS file; Szignifikancia szint ellenőrzése. Visszacsatolás – iteráció; modell változtatás/új modell építés indítása a Béta modell szintjéről. Modell építés az adatgyűjtés állományán zajlik – kellően robusztus modell esetén történik a szimuláció, amikor a létrejött függvényt a cenzus/mikrocenzus állományon futtatva létrejön egy lehetséges becslés.")
12
Szimuláció és Modell validálás
A szimuláció során bootstrap eljárással 100-szoros iterációs folyamat során létrejön a becslés a teljes sokaságra vonatkozóan a függő változó értékére A hivatalos szegénységi küszöb értéket használva a program elkészíti a megadott területi szintekre a szegénységi arány becslését A évi adatokon elkészített , 90% feletti megbízhatóságú, robusztus modellek száma 14 volt. Összehasonlítottuk a modell NUTS1; NUTS2 szintre adott becslés értékeit az EU-SILC felvételből származó becslésekkel A validálás során a WB szakértők által készített modellek felhasznált változói körét és a KSH modellek változói körét részletesen összehasonlítottuk A modell akkor robusztus, ha jellemzően azonos változó kört von be, s a becslő függvény értékei tagonként is minimális eltérés mutattak Ennek alapján az azonos változók alapján készült el a végleges validált, robusztus modell (model20)
")
13
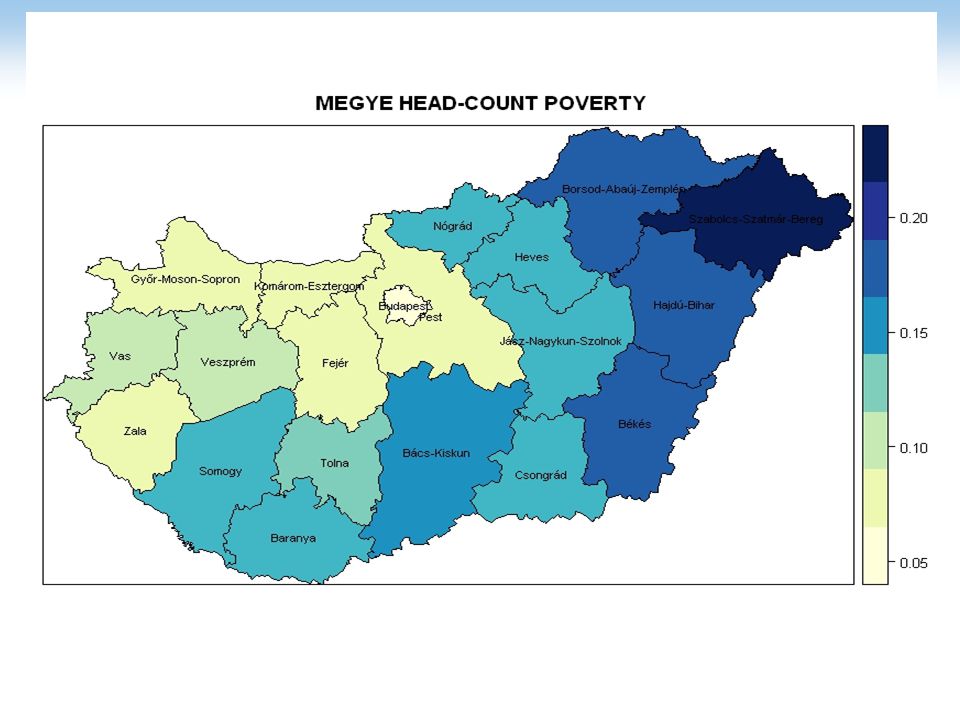
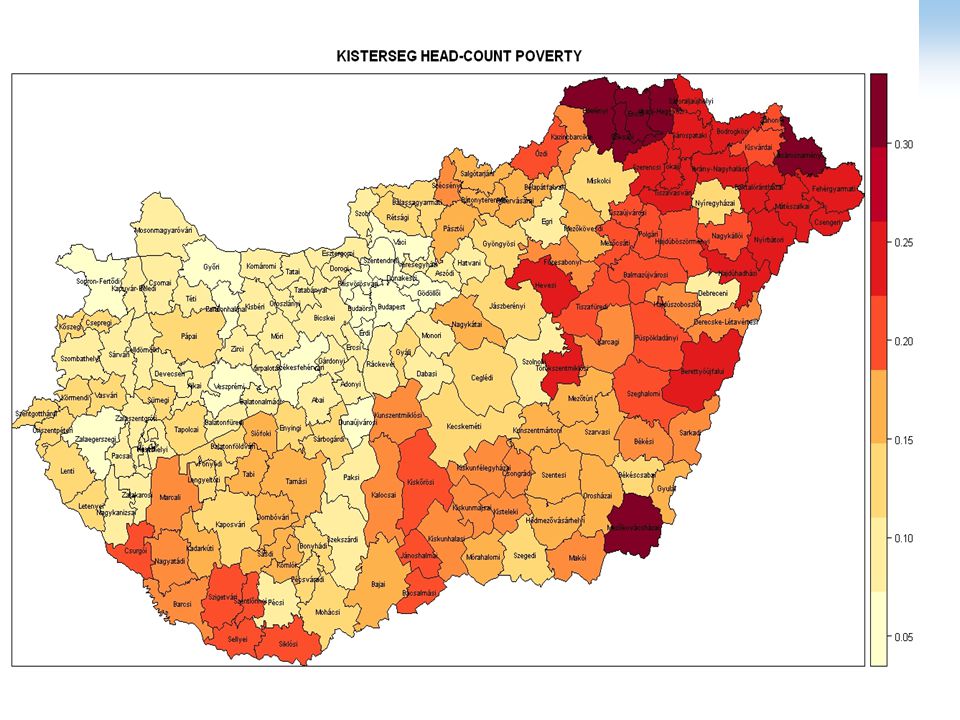
Az eredmények megjelenítése
POVMAP önmagában nem vizualizál; R nevű programcsomaggal oldottuk meg, ingyenesen letölthető Használatához szükséges: Magyarország vaktérképe a megfelelő területi bontásban Felmerült probléma: évi Mikro cenzus mintája az országgyűlési választókerületeket (OVK) vette alapul OVK szintű térkép séma nem állt rendelkezésre, csak kistérség szintű. A kistérségek nem esnek egybe az OVK-val Egy település több OVK-hoz tartozott – általában a nagyobb települések, azonban a kistelepülések esetében több település adott egy db OVK-t. Rendelkezésre állt a települések szerint lakásszám adat, amelyet felhasználva súlyozással létre tudtuk hozni a kistérség szintű szegénységi arányt Ennek csv formátuma képezte az R szoftver egyik bemenő adatát a magyarországi vaktérkép mellett
 vette alapul. OVK szintű térkép séma nem állt rendelkezésre, csak kistérség szintű. A kistérségek nem esnek egybe az OVK-val. Egy település több OVK-hoz tartozott – általában a nagyobb települések, azonban a kistelepülések esetében több település adott egy db OVK-t. Rendelkezésre állt a települések szerint lakásszám adat, amelyet felhasználva súlyozással létre tudtuk hozni a kistérség szintű szegénységi arányt. Ennek csv formátuma képezte az R szoftver egyik bemenő adatát a magyarországi vaktérkép mellett.")
16
Modell eredmények összehasonlítása 1.

17
Modell eredmények összehasonlítása 2.

18
Következő lépések A modell elkészítése népszámlálás és évi EU-SILC adatai alapján További lehetőségek: más kismintás adatgyűjtés és a népszámlálás eredményeinek összekapcsolása Nemzetközi tapasztalat alapján: Alultápláltság/túlsúly becslés

19
Köszönjük a figyelmet!

Hasonló előadás