Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Generatív (Bayesi) modellezés 2013. ápr. 17.
 modellezés ápr. 17.")
2
Slides by (credit to): David M. Blei Andrew Y. Ng, Michael I. Jordan, Ido Abramovich, L. Fei-Fei, P. Perona, J. Sivic, B. Russell, A. Efros, A. Zisserman, B. Freeman, Tomasz Malisiewicz, Thomas Huffman, Tom Landauer and Peter Foltz, Melanie Martin, Hsuan-Sheng Chiu, Haiyan Qiao, Jonathan Huang Thank you!

3
Generatív modellezés Felügyelet nélküli tanulás … túl a klaszterzésen Hogyan írjuk le/modellezzük a világot a számítógépnek? Bayes háló!

4
Generatív (Bayesi) modellezés ADAT Modell „Generatív sztori” Találjuk meg a paramétereket amikkel a modell a legjobban „rekonstruálja” a megfigyelt adatot
 modellezés ADAT Modell „Generatív sztori Találjuk meg a paramétereket amikkel a modell a legjobban „rekonstruálja a megfigyelt adatot")
5
A dokumentum klaszterzés/osztályozás probléma Szöveges dokumentumokat sorolunk be témákba vagy Képekről tanuljuk meg, hogy mi szerepel rajtuk „Szózsák modell” A term-dokumentum mátrix:

6
Kép „Szavak” zsákja

7
N db dokumentum: D={d 1, …,d N } A szótár M db szót tartalmaz –W={w 1, …,w M } A term-dokumentum mátrix mérete N * M, az egyes szavak (termek) dokumentumbeli előfordulását tartalmazza –term lehet 1 szó, többszavas frázis vagy képrészlet is –Előfordulást jellemezhetjük gyakorisággal, binárisan stb.
 dokumentumbeli előfordulását tartalmazza –term lehet 1 szó, többszavas frázis vagy képrészlet is –Előfordulást jellemezhetjük gyakorisággal, binárisan stb.")
8
A szózsák modell problémái –Sorrendiség és pozíció elveszik –Szinonímák: sok féleképen hivatkozhatunk egy objektumra (fogalomra), pl: álmos-kialvatlan → gyenge fedés –Poliszémia: a legtöbb szónak több jelentése van, pl: körte, puska → gyenge pontosság
, pl: álmos-kialvatlan → gyenge fedés –Poliszémia: a legtöbb szónak több jelentése van, pl: körte, puska → gyenge pontosság")
9
képi poliszémia

10
Dokumentumok klaszterezése Minden dokumentumhoz rendeljünk egy „topic”-ot

11
Generatív sztori az „unigram modell”hez TOPIC szó szó... Hogyan generálódik(ott) egy dokumentum? 1. „Dobjunk” egy topicot 2. Minden kitöltendő szópozícióra „dobjunk” egy szót a kiválasztott topichoz
 egy dokumentum. 1. „Dobjunk egy topicot 2. Minden kitöltendő szópozícióra „dobjunk egy szót a kiválasztott topichoz.")
12
Valószínűségi LSA pLSA Probabilistic Latent Semantic Analysis Minden dokumentumot egy valószínűségi eloszlás ír le a topicok felett Minden topicot egy valószínűségi eloszlás ír le a szavak felett Az eloszlások interpretálhatóak

13
Viszony a klaszterzéshez… A dokumentumok nem pontosan egy klaszterbe sorolódnak be Topicok egy eloszlását határozzuk meg minden dokumentumhoz → sokkal flexibilisebb

14
Generatív sztori a pLSA-hoz TOPIC eloszlás TOPIC TOPIC szó szó...... Hogyan generálódik(ott) egy dokumentum? 1. Generáljunk egy topic-eloszlást 2. Minden kitöltendő szópozícióra „dobjunk” egy topicot a topic- eloszlából 3. „Dobjunk” egy szót a kiválasztott topichoz
 egy dokumentum. 1. Generáljunk egy topic-eloszlást 2. Minden kitöltendő szópozícióra „dobjunk egy topicot a topic- eloszlából 3. „Dobjunk egy szót a kiválasztott topichoz.")
16
loan TOPIC 1 money loan bank money bank river TOPIC 2 river stream bank stream bank loan DOCUMENT 2: river 2 stream 2 bank 2 stream 2 bank 2 money 1 loan 1 river 2 stream 2 loan 1 bank 2 river 2 bank 2 bank 1 stream 2 river 2 loan 1 bank 2 stream 2 bank 2 money 1 loan 1 river 2 stream 2 bank 2 stream 2 bank 2 money 1 river 2 stream 2 loan 1 bank 2 river 2 bank 2 money 1 bank 1 stream 2 river 2 bank 2 stream 2 bank 2 money 1 DOCUMENT 1: money 1 bank 1 bank 1 loan 1 river 2 stream 2 bank 1 money 1 river 2 bank 1 money 1 bank 1 loan 1 money 1 stream 2 bank 1 money 1 bank 1 bank 1 loan 1 river 2 stream 2 bank 1 money 1 river 2 bank 1 money 1 bank 1 loan 1 bank 1 money 1 stream 2.3.8.2 Példa.7

17
DOCUMENT 2: river ? stream ? bank ? stream ? bank ? money ? loan ? river ? stream ? loan ? bank ? river ? bank ? bank ? stream ? river ? loan ? bank ? stream ? bank ? money ? loan ? river ? stream ? bank ? stream ? bank ? money ? river ? stream ? loan ? bank ? river ? bank ? money ? bank ? stream ? river ? bank ? stream ? bank ? money ? DOCUMENT 1: money ? bank ? bank ? loan ? river ? stream ? bank ? money ? river ? bank ? money ? bank ? loan ? money ? stream ? bank ? money ? bank ? bank ? loan ? river ? stream ? bank ? money ? river ? bank ? money ? bank ? loan ? bank ? money ? stream ? A modell illesztése (tanulása) TOPIC 1 TOPIC 2 ? ? ?
 TOPIC 1 TOPIC")
18
Megfigyelt adat- eloszlások termek eloszlása a topicok felett topicok eloszlása dokumentumonként Slide credit: Josef Sivic pLSA

19
Generatív sztori a pLSA-hoz TOPIC eloszlás TOPIC TOPIC szó szó...... Hogyan generálodott egy dokumentum? 1. Generáljunk egy topic-eloszlást 2. Minden kitöltendő szópozícióra „dobjunk” egy topicot a topic- eloszlából 3. „Dobjunk” egy szót a kiválasztott topichoz

20
pLSA – modell-illesztés

21
Az „expectation-maximisation”, EM algoritmus Iteratív módszer maximum likelihood becslésre rejtett változók esetén E-lépés –Rejtett változók várható értékének kiszámítása, úgy hogy fixáljuk a keresett paramétereket M-lépés –Frissítsük a paramétereket úgy, hogy a rejtett változók értékét rögzítjük. –Maximalizáljuk a (likelihood) célfüggvényt
 célfüggvényt.")
22
pLSA – E-lépés A paraméterek ismerete mellett, mi a rejtett változók (z, topicok) eloszlása
 eloszlása")
23
pLSA – M-lépés Rögzítsük p(z|d,w)-ket és
-ket és")
24
EM algoritmus Lokális maximumhoz konvergál Megállási feltétel? –Adatbázis és/vagy ismeretlen példákra való illeszkedés?

25
pLSA problémái Korábban nem látott dokumentumokra újra kell számítani a teljes halmazon. A paraméterek száma az adathalmaz méretével nő d tulajdonképpen csak egy index, nem illik a generatív sztoriba

26
LDA

27
Unigram modell Minden M db dokumentumhoz, dobjunk egy z topicot. Dobjunk N szót, egymástól függetlenül multinomiális eloszlásból z függvényében Minden dokumentumhoz egy topicot rendelünk ZiZi w 4i w 3i w 2i w i1

28
pLSA modell Minden d dokumentum minden szópozíciójára: Dobjunk egy z témát egy multinominális eloszlásból ami a d indextől függ Dobjunk egy szót multinomális eloszlásból, ami z-től függ. pLSA-ban a dokumentumokhoz topicok egy eloszlását rendeljünk. d z d4 z d3 z d2 z d1 w d4 w d3 w d2 w d1

29
LDA modell z4z4 z3z3 z2z2 z1z1 w4w4 w3w3 w2w2 w1w1 z4z4 z3z3 z2z2 z1z1 w4w4 w3w3 w2w2 w1w1 z4z4 z3z3 z2z2 z1z1 w4w4 w3w3 w2w2 w1w1 Minden dokumentumra, dobjunk ~Dirichlet( ) Minden n szópozícióra : –dobjunk egy z n topicot z n ~ Multinomial( ) –dobjunk egy w n szót p(w n |z n, ) multinomiális eloszlásból
 Minden n szópozícióra : –dobjunk egy z n topicot z n ~ Multinomial( ) –dobjunk egy w n szót p(w n |z n, ) multinomiális eloszlásból")
30
LDA modell Minden dokumentumra, dobjunk ~Dirichlet( ) Minden n szópozícióra : –dobjunk egy z n topicot z n ~ Multinomial( ) –dobjunk egy w n szót p(w n |z n, ) multinomiális eloszlásból
 Minden n szópozícióra : –dobjunk egy z n topicot z n ~ Multinomial( ) –dobjunk egy w n szót p(w n |z n, ) multinomiális eloszlásból")
31
w N d z D pLSA példa “szem” Sivic et al. ICCV 2005

32
w N c z D Fei-Fei et al. ICCV 2005 “part” LDA példa

33
A dirichlet eloszlás Egy eloszlás a multinominális eloszlások felett. A k dimenziós Dirichlet valószínűségi változó elemei nem negatívak és 1-re összegződnek (k-1 szimplex) i pozitív (nem összegződik 1-re, az abszolút értékei is számítanak, nem csak a relatívak!) A dirichlet eloszlás a multinominális eloszlás konjugált priorja (ha a likelihodd multinominális dirichlet priorral akkor a posterior is dirichlet) Az i paraméterre gondolhatunk úgy, mint az i. topic gyakoriságára vonatkozó priorra
 i pozitív (nem összegződik 1-re, az abszolút értékei is számítanak, nem csak a relatívak!) A dirichlet eloszlás a multinominális eloszlás konjugált priorja (ha a likelihodd multinominális dirichlet priorral akkor a posterior is dirichlet) Az i paraméterre gondolhatunk úgy, mint az i. topic gyakoriságára vonatkozó priorra.")
34
Példák 0 1 0 Dirichlet(5,5,5) Dirichlet(0.2, 5, 0.2) Dirichlet(0.5,0.5,0.5)
 Dirichlet(0.2, 5, 0.2) Dirichlet(0.5,0.5,0.5)")
35
Dirichlet példák

36
1 = 2 = 3 = a

37
LDA

38
Következtetés Egzakt optimalizáció nem kivitelezhető

39
Következtetés Gibbs mintavételezéssel közelítő valószínűségi következtetés –dobjunk a Bayes hálónak megfelelően mintákat –a felvett változóértékek gyakoriságával becsüljük az együttes eloszlásokat Markov Lánc Monte Carlo módszer –a következő minta függ az előző mintáktól (azaz ne véletlenül és egymástól függetlenül dobáljunk mintákat) Gibbs mintavételezés –a következő mintát úgy kapjuk, hogy az egyes változókat kidobjuk a többi változó aktuális értékének rögzítése mellett
 Gibbs mintavételezés –a következő mintát úgy kapjuk, hogy az egyes változókat kidobjuk a többi változó aktuális értékének rögzítése mellett")
40
39 pLSA és LDA összehasonlítás pLSA problémái –új dokumentumokat nem tudja kezelni –adatbázis méretével nő a paraméterek száma (kezelhetőség, túlillesztés) LDA mindkét problémát kezeli azzal, hogy a topic-eloszlásokat rejtett változóként kezeli k+kV paraméter
 LDA mindkét problémát kezeli azzal, hogy a topic-eloszlásokat rejtett változóként kezeli k+kV paraméter")
41
LDA zárszó Az LDA egy flexibilis generative valószínűségi modell Ekzakt következtetés nem kivitelezhető, de a közelítő megoldások (pl. variációs következtetés, MCMC) használhatóak és a gyakorlatban jól működnek
 használhatóak és a gyakorlatban jól működnek.")
42
1990 1999 2003
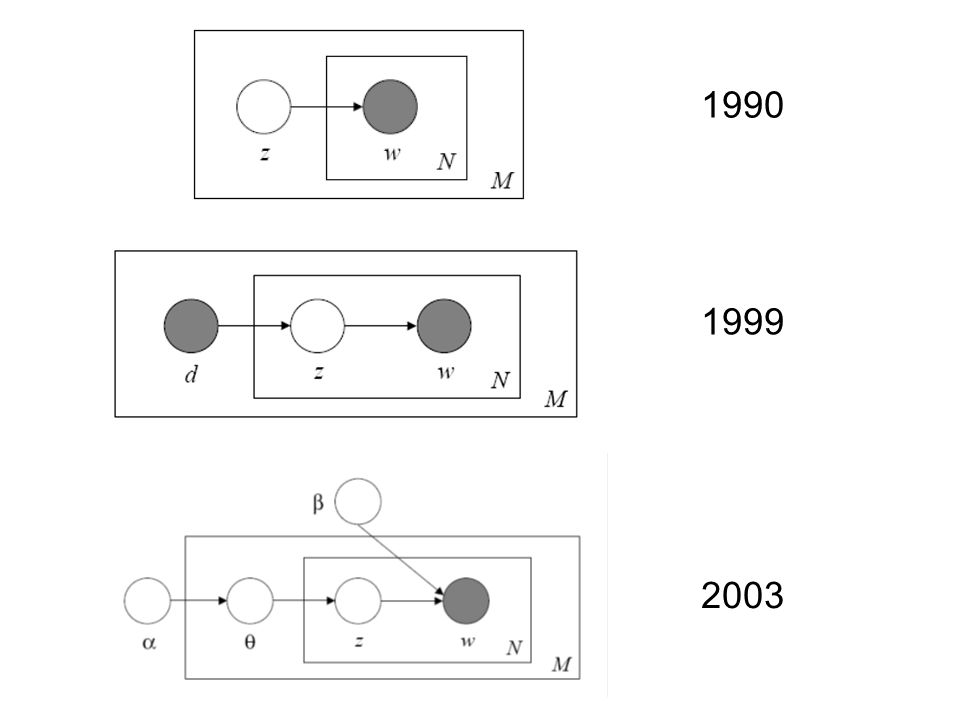
44
Objektumok azonosítása képekről Találjuk meg milyen objektumok szerepelnek a képgyűjteményben, felügyelet nélküli módon! Ezeket utána új képeken is ismerjük fel! Automatikusan találjuk meg, hogy milyen jellemzők fontosak az egyes tárgyak azonosításához!

Hasonló előadás



 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")










 osztályozó a Bayes világból>")



,>")

>")