Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Gépi tanulási módszerek febr. 20.
Bayes döntéselmélet Gépi tanulási módszerek febr. 20.

2
Osztályozás Felügyelt (induktív) tanulás:
2 Osztályozás Felügyelt (induktív) tanulás: tanító halmaz alapján olyan modell tanulása ami korábban nem látott példákon is helyesen működik. Osztályozás: előre definiált kategóriákba besorolás.
 tanulás: tanító halmaz alapján olyan modell tanulása ami korábban nem látott példákon is helyesen működik. Osztályozás: előre definiált kategóriákba besorolás.")
3
A priori ismeretek előre adott A természet állapota véletlen változó
3 A priori ismeretek előre adott A természet állapota véletlen változó A tengeri sügér és a lazac kifogása egyenlően valószínű? P(1 ) = P(2 ) (egyenletes a priori) P(1 ) + P( 2 ) = 1 (csak ezeket foghatjuk ki, nincs átfedés) Pattern Classification, Chapter 2
 = P(2 ) (egyenletes a priori) P(1 ) + P( 2 ) = 1. (csak ezeket foghatjuk ki, nincs átfedés) Pattern Classification, Chapter 2.")
4
Osztályozás csak a priori ismeret alapján
4 Osztályozás csak a priori ismeret alapján Csak az a priori valószínűségeket használva: Válasszuk 1-et, ha P(1) > P(2) különben 2-t (mindig ugyanaz a döntés!!!) Pattern Classification, Chapter 2
 > P(2) különben 2-t. (mindig ugyanaz a döntés!!!) Pattern Classification, Chapter 2.")
5
A posteriori valószínűség
5 A posteriori valószínűség prior P(j | x) = P(x | j ) · P (j ) / P(x) cél: P(j | x) modellezése bizonyíték likelihood Pattern Classification, Chapter 2 (Part 1)
 = P(x | j ) · P (j ) / P(x) cél: P(j | x) modellezése. bizonyíték. likelihood. Pattern Classification, Chapter 2 (Part 1)")
6
Osztályonkénti likelihoodok
6 Osztályonkénti likelihoodok

7
Osztályonkénti posteriorik
Pattern Classification, Chapter 2 (Part 1)
")
8
Bayes döntési szabály Ha x egy megfigyelés, amelyre:
8 Bayes döntési szabály Ha x egy megfigyelés, amelyre: P(1 | x) > P(2 | x) akkor a valós állapot = 1 P(1 | x) < P(2 | x) akkor a valós állapot = 2 P(x | j ) és P (j )-ket modellezük P(x) nem kell a döntéshez, ill.
 > P(2 | x) akkor a valós állapot = 1. P(1 | x) < P(2 | x) akkor a valós állapot = 2. P(x | j ) és P (j )-ket modellezük. P(x) nem kell a döntéshez, ill.")
9
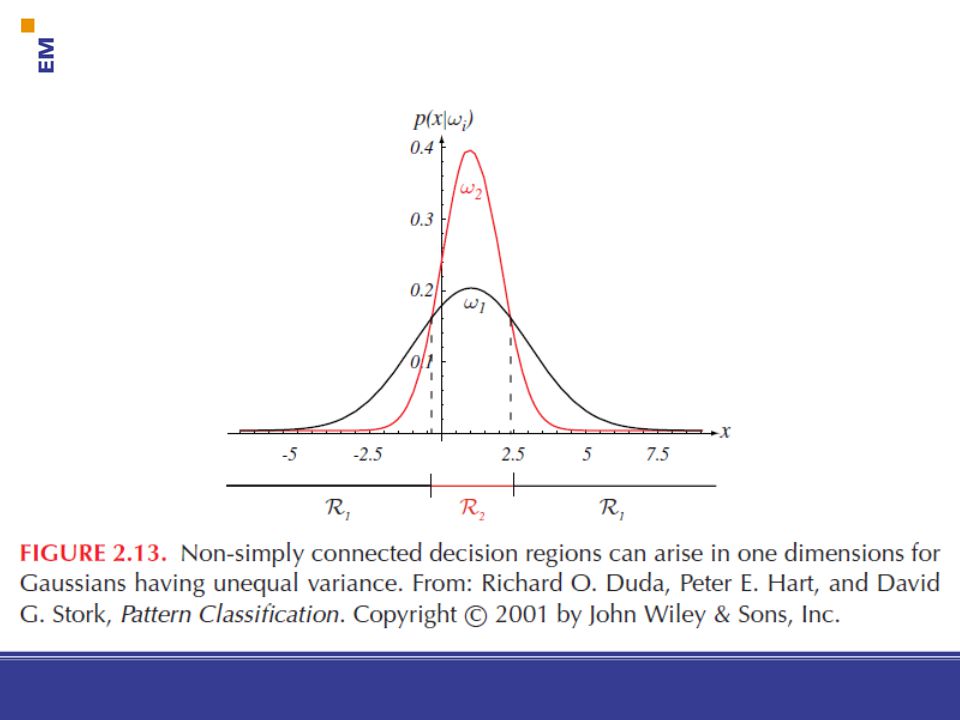
Hiba valószínűsége P(hiba | x) = min [P(1 | x), P(2 | x)]
9 Hiba valószínűsége Ekkor az x megfigyelés mellett a hiba valószínűsége: P(hiba | x) = P(1 | x) ha 2-t választottunk P(hiba | x) = P(2 | x) ha 1-t választottunk azaz P(hiba | x) = min [P(1 | x), P(2 | x)] A „Bayes döntési szabály” minimalizálja a hiba átlagos valószínűségét.
![Hiba valószínűsége P(hiba | x) = min [P(1 | x), P(2 | x)]](http://slideplayer.hu/slide/2102884/8/images/9/Hiba+val%C3%B3sz%C3%ADn%C5%B1s%C3%A9ge+P%28hiba+%7C+x%29+%3D+min+%5BP%28%EF%81%B71+%7C+x%29%2C+P%28%EF%81%B72+%7C+x%29%5D.jpg "9. Hiba valószínűsége. Ekkor az x megfigyelés mellett a hiba valószínűsége: P(hiba | x) = P(1 | x) ha 2-t választottunk. P(hiba | x) = P(2 | x) ha 1-t választottunk. azaz. P(hiba | x) = min [P(1 | x), P(2 | x)] A „Bayes döntési szabály minimalizálja a hiba átlagos valószínűségét.")
10
Bayes döntéselmélet - általánosítások
10 Bayes döntéselmélet - általánosítások Több, mint egy tulajdonság (d-dimenziós tulajdonságvektor) Több, mint két osztály (c osztály) Nemcsak döntések, hanem egyéb tevékenységek (akciók) megengedése Veszteségfüggvény (loss function) bevezetése (ez a hibavalószínűségnél általánosabb fogalom lesz) Pattern Classification, Chapter 2 (Part 1)
 Több, mint két osztály (c osztály) Nemcsak döntések, hanem egyéb tevékenységek (akciók) megengedése. Veszteségfüggvény (loss function) bevezetése (ez a hibavalószínűségnél általánosabb fogalom lesz) Pattern Classification, Chapter 2 (Part 1)")
11
Bayes döntéselmélet - jelölések
11 Legyenek {1, 2,…, c } a természet lehetséges állapotai egy kísérletnél (osztályok, kategóriák) Legyenek {1, 2,…, a } a lehetséges cselekvések (akciók, tevékenységek) Jelölje (i | j ) azt a veszteséget, amellyel az i cselekvés jár, amennyiben a természet állapota (osztály) j volt. Pattern Classification, Chapter 2 (Part 1)
 Legyenek {1, 2,…, a } a lehetséges cselekvések (akciók, tevékenységek) Jelölje (i | j ) azt a veszteséget, amellyel az i cselekvés jár, amennyiben a természet állapota (osztály) j volt. Pattern Classification, Chapter 2 (Part 1)")
12
Bayes döntéselmélet - Példa
Tőzsdei kereskedő algoritmus 1: emelkedni fog az árfolyam (néhány napon belül) 2: csökkeni fog az árfolyam 3: nem változik sokat az árfolyam -t nem ismerjük! 1: vásárlunk a részvényből 2: nem vásárlunk a részvényből x: jelenlegi és múltbeli árfolyamok x-et meg tudjuk figyelni (ismert) : egy tranzakcióval mennyit veszítünk/keresünk
 2: csökkeni fog az árfolyam. 3: nem változik sokat az árfolyam. -t nem ismerjük! 1: vásárlunk a részvényből. 2: nem vásárlunk a részvényből. x: jelenlegi és múltbeli árfolyamok. x-et meg tudjuk figyelni (ismert) : egy tranzakcióval mennyit veszítünk/keresünk.")
13
Bayes kockázat (x) = argmin R(i | x)
13 Bayes kockázat feltételes kockázat (veszteség): R(i | x) (x) = argmin R(i | x) Pattern Classification, Chapter 2 (Part 1)
: R(i | x) (x) = argmin R(i | x) Pattern Classification, Chapter 2 (Part 1)")
14
Két kategóriás osztályozó
14 Két kategóriás osztályozó 1 : válasszuk 1-t 2 : válasszuk 2 -t ij = (i | j ) jelöli azt a veszteséget, amit i választása jelent, ha a természet állapota j Feltételes kockázat: R(1 | x) = 11P(1 | x) + 12P(2 | x) R(2 | x) = 21P(1 | x) + 22P(2 | x) Pattern Classification, Chapter 2 (Part 1)
 jelöli azt a veszteséget, amit i választása jelent, ha a természet állapota j. Feltételes kockázat: R(1 | x) = 11P(1 | x) + 12P(2 | x) R(2 | x) = 21P(1 | x) + 22P(2 | x) Pattern Classification, Chapter 2 (Part 1)")
15
Két kategóriás osztályozó – döntési szabály
15 ha R(1 | x) < R(2 | x) akkor az 1 cselekvés: “döntés: 1” „döntés 1 ”, ha”: (21- 11 ) P(x | 1 ) P(1 ) > (12- 22 ) P(x | 2 ) P(2 ) különben „döntés 2” Pattern Classification, Chapter 2 (Part 1)
 < R(2 | x) akkor az 1 cselekvés: döntés: 1 „döntés 1 , ha : (21- 11 ) P(x | 1 ) P(1 ) > (12- 22 ) P(x | 2 ) P(2 ) különben „döntés 2 Pattern Classification, Chapter 2 (Part 1)")
16
Likelihood hányados akkor akció 1 (döntés: 1),
16 Likelihood hányados Az előző szabály ekvivalens a következővel: akkor akció 1 (döntés: 1), különben akció 2 (döntés: 2) Pattern Classification, Chapter 2 (Part 1)
, különben akció 2 (döntés: 2) Pattern Classification, Chapter 2 (Part 1)")
17
Nulla-Egy veszteségfüggvény
17 Nulla-Egy veszteségfüggvény Ekkor a feltételes kockázat: Pattern Classification, Chapter 2 (Part 1)
")
18
A több osztályos osztályozó – általános eset (nem csak Bayes döntéselmélet!)
18 Diszkriminancia függvények halmaza: gi(x), i = 1,…, c Az osztályozó egy x tulajdonságvektorhoz az i osztályt rendeli, ha: gi(x) = max gk(x) Pattern Classification, Chapter 2 (Part 1)
, i = 1,…, c. Az osztályozó egy x tulajdonságvektorhoz az i osztályt rendeli, ha: gi(x) = max gk(x) Pattern Classification, Chapter 2 (Part 1)")
19
gi(x) = ln P(x | I ) + ln P(I )
19 Bayes osztályozó Legyen gi(x) = - R(i | x) (a legnagyobb diszkriminancia érték a minimális kockázatnak felel meg!) Nulla-egy veszteségfüggvénnyel: gi(x) = P(i | x) A legnagyobb diszkriminancia a maximális a posteriori valószínűségnek felel meg: gi(x) = P(x | I ) P(I ) gi(x) = ln P(x | I ) + ln P(I ) Pattern Classification, Chapter 2 (Part 1)
 = - R(i | x) (a legnagyobb diszkriminancia érték a minimális kockázatnak felel meg!) Nulla-egy veszteségfüggvénnyel: gi(x) = P(i | x) A legnagyobb diszkriminancia a maximális a posteriori valószínűségnek felel meg: gi(x) = P(x | I ) P(I ) gi(x) = ln P(x | I ) + ln P(I ) Pattern Classification, Chapter 2 (Part 1)")
20
Két osztályos Bayes osztályozó
20 Két osztályos Bayes osztályozó egyetlen diszkriminancia fgv: döntés: g(x) > 0 Pattern Classification, Chapter 2 (Part 1)
 > 0. Pattern Classification, Chapter 2 (Part 1)")
21
Diszkriminanciafügvények Bayes osztályozó és normális eloszlás esetén

22
A normális eloszlás Egyváltozós eset Ahol: = az X várható értéke
22 A normális eloszlás Egyváltozós eset Kezelhető sűrűségfüggvény Folytonos Nagyon sok eloszlás aszimptotikusan normális Centrális határeloszlás-tétele Ahol: = az X várható értéke 2 = szórásnégyzet (variancia) Pattern Classification, Chapter 2 (Part 1)
 Pattern Classification, Chapter 2 (Part 1)")
23
23 Pattern Classification, Chapter 2 (Part 1)
")
24
Többváltozós normális eloszlás
24 Többváltozós normális eloszlás sűrűségfüggvénye ahol: x = (x1, x2, …, xd)t = (1, 2, …, d)t a várható érték vektor = d*d a kovariancia-mátrix || illetve -1 a determináns illetve az inverz mátrix Pattern Classification, Chapter 2 (Part 1)
t. = (1, 2, …, d)t a várható érték vektor. = d*d a kovariancia-mátrix. || illetve -1 a determináns illetve az inverz mátrix. Pattern Classification, Chapter 2 (Part 1)")
25
A normális eloszláshoz tartozó diszkriminancia függvények
25 gi(x) = ln P(x | I ) + ln P(I ) Többváltozós normális eloszlásnál Pattern Classification, Chapter 2 (Part 1)
 = ln P(x | I ) + ln P(I ) Többváltozós normális eloszlásnál. Pattern Classification, Chapter 2 (Part 1)")
26
i = 2I esete I az egységmátrix 26
Pattern Classification, Chapter 2 (Part 1)
")
27
Ri: azon térrész ahol gi(x) maximális
27 Ri: azon térrész ahol gi(x) maximális Döntési felület: Ri-t és Rj-t elválasztó felület Pattern Classification, Chapter 2 (Part 1)
 maximális. Döntési felület: Ri-t és Rj-t elválasztó felület. Pattern Classification, Chapter 2 (Part 1)")
28
Pattern Classification, Chapter 2 (Part 1)
")
29
29 Pattern Classification, Chapter 2 (Part 1)
")
30
i = esete a kovarianciamátrixok azonosak, de tetszőlegesek!
Az Ri és Rj közti döntési felület hipersík,de általában nem merőleges a várható értékeket összekötő egyenesre!

31
31 Pattern Classification, Chapter 2 (Part 1)
")
32
32 Pattern Classification, Chapter 2 (Part 1)
")
33
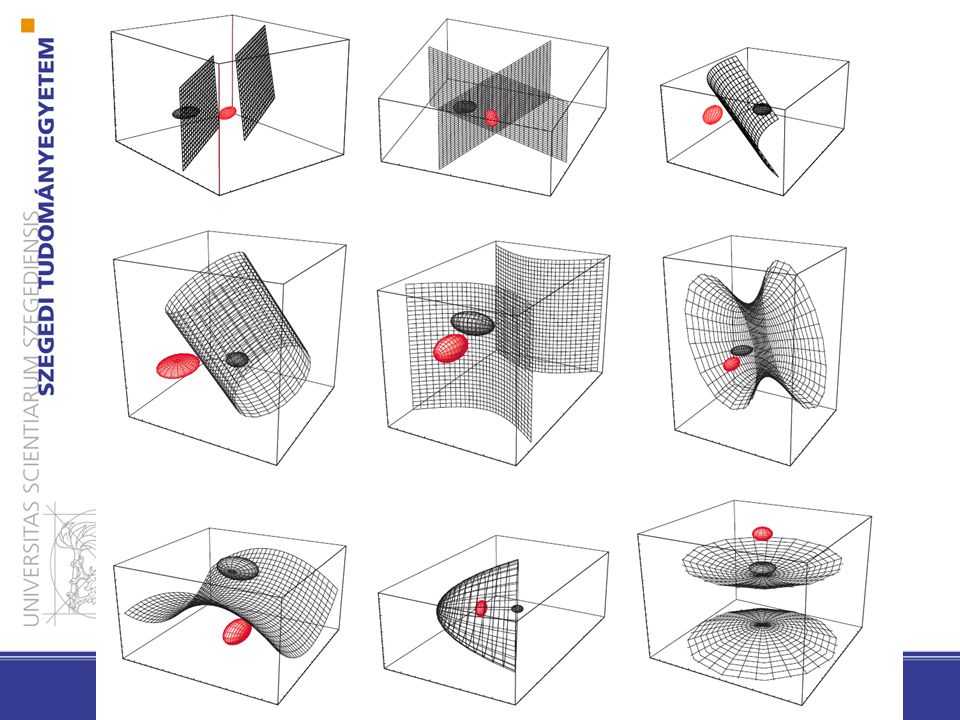
33 i tetszőleges A kovarianciamátrixok minden osztálynál különbözőek (Hiperkvadratikusok: hipersíkok, hipersíkok párjai, hipergömbök, hiperellipszoidok, hiperparaboloidok, hiperboloidok) Pattern Classification, Chapter 2 (Part 1)
 Pattern Classification, Chapter 2 (Part 1)")
35
35 Pattern Classification, Chapter 2 (Part 1)
")
36
36 Pattern Classification, Chapter 2 (Part 1)
")
38
Eloszlások paramétereinek becslése Maximum-likelihood illetve Bayes-módszerrel

39
Osztályozó készítése tanítópéldákból
39 Osztályozó készítése tanítópéldákból A Bayes döntési szabály Optimális osztályozót tudnánk készíteni az alábbiak ismeretében: P(i) (a priori valószínűségek) P(x | i) (likelihood) Azonban a gyakorlatban ezek a legritkább esetben ismertek! – Általában csak példáink vannak Az a priori eloszlás becslése nem okoz gondot Az osztályonkénti eloszlás becslése nehéz! (magas dimenziószám, gyakran kevés példa) Pattern Classification, Chapter 3
 (a priori valószínűségek) P(x | i) (likelihood) Azonban a gyakorlatban ezek a legritkább esetben ismertek! – Általában csak példáink vannak. Az a priori eloszlás becslése nem okoz gondot. Az osztályonkénti eloszlás becslése nehéz! (magas dimenziószám, gyakran kevés példa) Pattern Classification, Chapter 3.")
40
Paraméteres tanulóalgoritmusok
40 Paraméteres tanulóalgoritmusok A priori feltételezés a tanulandó eloszlásról: Pl. feltételezzük, hogy P(x | i) ~ N( i, i) Így csak a 2 paramétert kell megbecsülni Paraméterbecslési módszerek: Maximum-Likelihood (ML) becslés, illetve Bayes-becslés Hasonló eredményre vezetnek, de más elvi háttéren alapulnak Bármelyiket válasszuk is, a kapott P(x| i) becslést ugyanúgy használjuk osztályozáskor Pattern Classification, Chapter 3
 ~ N( i, i) Így csak a 2 paramétert kell megbecsülni. Paraméterbecslési módszerek: Maximum-Likelihood (ML) becslés, illetve Bayes-becslés. Hasonló eredményre vezetnek, de más elvi háttéren alapulnak. Bármelyiket válasszuk is, a kapott P(x| i) becslést ugyanúgy használjuk osztályozáskor. Pattern Classification, Chapter 3.")
41
Pattern Classification, Chapter 3
41 Maximum likelihood becslés: Feltételezi, hogy a paraméterek értéke rögzített, csak számunkra ismeretlen Legjobb paraméterértéknek azt az értéket tekinti, ami legjobban magyarázza (max. valószínűséget rendeli) a tanítópéldákat Bayes-becslés: A paramétereket is valószínűségi változóként kezeli, így azok eloszlását keresi Ehhez kiindul egy feltételezett a priori eloszlásból, melyet a tanítópéldák segítségével pontosít Pattern Classification, Chapter 3
 a tanítópéldákat. Bayes-becslés: A paramétereket is valószínűségi változóként kezeli, így azok eloszlását keresi. Ehhez kiindul egy feltételezett a priori eloszlásból, melyet a tanítópéldák segítségével pontosít. Pattern Classification, Chapter 3.")
42
Maximum-likelihood becslés
42 Maximum-likelihood becslés Modellezési feltevések Tfh. c osztályunk van, és mindegyik eloszlását egy-egy normális eloszlással közelítjük: P(x | j) ~ N( j, j) A tanulandó paramétereket egy adott osztály esetén jelölje Pattern Classification, Chapter 3
 ~ N( j, j) A tanulandó paramétereket egy adott osztály esetén jelölje. Pattern Classification, Chapter 3.")
43
Pattern Classification, Chapter 3
43 Tanító adatbázis Tanítópéldák Tfh a D tanító-adatbázis n mintából áll: (x1, 1), (x2, 2),…, (xn, n) „iid” feltevés: az elemek egymástól függetlenek és ugyanabból a megtanulandó eloszlásból származnak Pattern Classification, Chapter 3
, (x2, 2),…, (xn, n) „iid feltevés: az elemek egymástól. függetlenek és. ugyanabból a megtanulandó eloszlásból származnak. Pattern Classification, Chapter 3.")
44
A „likelihood” célfüggvény
44 A „likelihood” célfüggvény „maximum-likelihood” becslésén azt az értéket fogjuk érteni, amely maximizálja P(D | )-t “Az a érték, amely legjobban magyarázza az aktuálisan megfigyelt tanítópéldákat” A „log-likelihood” célfüggvény l() = ln P(D | ) (optimuma ugyanott van, de egyszerűbb kezelni!) Pattern Classification, Chapter 3
-t. Az a érték, amely legjobban magyarázza az aktuálisan megfigyelt tanítópéldákat A „log-likelihood célfüggvény. l() = ln P(D | ) (optimuma ugyanott van, de egyszerűbb kezelni!) Pattern Classification, Chapter 3.")
45
Pattern Classification, Chapter 3
45 Tanítópéldák és négy „jelölt” A likelihood-fgv. ( a változó, nem eloszlás!!!) A log-likelihood-fgv. Pattern Classification, Chapter 3
 A log-likelihood-fgv. Pattern Classification, Chapter 3.")
46
A (log-)likelihood maximalizálása
46 A (log-)likelihood maximalizálása Keressük azt a -t, amely maximalizálja az l() log-likelihood-ot: jelölje a gradiens operátort (p az ismeretlen paraméterek száma): l()-ra alkalmazva:
likelihood maximalizálása. Keressük azt a -t, amely maximalizálja az l() log-likelihood-ot: jelölje a gradiens operátort. (p az ismeretlen paraméterek száma): l()-ra alkalmazva:")
47
A (log-)likelihood maximalizálása
47 A (log-)likelihood maximalizálása Az optimumhelyhez szükséges feltétel: l = 0 (megj: esetünkben a vizsgált függvények jellege miatt elégséges is lesz) Pattern Classification, Chapter 3
likelihood maximalizálása. Az optimumhelyhez szükséges feltétel: l = 0. (megj: esetünkben a vizsgált függvények jellege miatt elégséges is lesz) Pattern Classification, Chapter 3.")
48
Pattern Classification, Chapter 3
48 Példa: egyváltozós Gauss-eloszlás, és ismeretlen azaz = (1, 2) = (, 2) Pattern Classification, Chapter 3
 = (, 2) Pattern Classification, Chapter 3.")
49
Pattern Classification, Chapter 3
49 Az összes példára összegezve: Kombinálva (1)-et és (2)-t, azt kapjuk hogy: Pattern Classification, Chapter 3
-et és (2)-t, azt kapjuk hogy: Pattern Classification, Chapter 3.")
50
Pattern Classification, Chapter 3
50 Bayes becslés -t is valószínűségi változóként kezeli, nem pedig rögzített de ismeretlen paraméterként A P() kezdeti eloszlását a priori tudásként ismertnek tekintjük A D tanítópéldák alapján keressük P( | D)-t Majd ennek segítségével írjuk fel P(x | D)-t Pattern Classification, Chapter 3
 kezdeti eloszlását a priori tudásként ismertnek tekintjük. A D tanítópéldák alapján keressük P( | D)-t. Majd ennek segítségével írjuk fel P(x | D)-t. Pattern Classification, Chapter 3.")
51
Pattern Classification, Chapter 3
51 Bayes becslés P(x | D) becsülhető minden olyan esetben, amikor a sűrűségfüggvényt parametrikus formában keressük Az alapvető feltevések: P(x | ) formája ismert, csak pontos értéke ismeretlen -ra vonatkozó ismereteink P() ismeretének formájában állnak rendelkezésre Összes többi -ra vonatkozó ismeretünket n db P(x) -ből származó D={ x1, x2, …, xn } minta tartalmazza Pattern Classification, Chapter 3
 becsülhető minden olyan esetben, amikor a sűrűségfüggvényt parametrikus formában keressük. Az alapvető feltevések: P(x | ) formája ismert, csak pontos értéke ismeretlen. -ra vonatkozó ismereteink P() ismeretének formájában állnak rendelkezésre. Összes többi -ra vonatkozó ismeretünket n db P(x) -ből származó D={ x1, x2, …, xn } minta tartalmazza. Pattern Classification, Chapter 3.")
52
A Bayes becslés két lépése
52 A Bayes becslés két lépése 1. P( | D) levezetése Bayes-formula, illetve a függetlenségi feltevés kell: 2. P(x | D) levezetése Megj.: ez sokszor nem vezethető le zárt képlettel, ezért numerikusan (pl. Gibbs algorithm), vagy simán a maximumával közelítik Pattern Classification, Chapter 3
 levezetése. Bayes-formula, illetve a függetlenségi feltevés kell: 2. P(x | D) levezetése. Megj.: ez sokszor nem vezethető le zárt képlettel, ezért numerikusan (pl. Gibbs algorithm), vagy simán a maximumával közelítik. Pattern Classification, Chapter 3.")
53
Pattern Classification, Chapter 3
53 Bayes becslés - Példa P(x|) egyváltozós Gauss-eloszlás, ismert, csak -t keressük amit keresünk, az ismeretlen paraméter(eloszlás): Tobábbá -nek ismert az a priori eloszlása: Pattern Classification, Chapter 3
 egyváltozós Gauss-eloszlás, ismert, csak -t keressük. amit keresünk, az ismeretlen paraméter(eloszlás): Tobábbá -nek ismert az a priori eloszlása: Pattern Classification, Chapter 3.")
54
Pattern Classification, Chapter 3
Példa – P( | D) levezetése 54 feltesszük: … Pattern Classification, Chapter 3
 levezetése. 54. feltesszük: … Pattern Classification, Chapter 3.")
55
Pattern Classification, Chapter 3
55 Értelmezés: - 0 A legjobb a priori becslésünk -re, 0 kifejezi a bizonytalanságunk n képlete súlyozott összegzéssel kombinálja 0-t és az adatok átlagát Ha n ∞, 0 súlya egyre kisebb, σn (a bizonytalanság) egyre csökken Pattern Classification, Chapter 3 55
 egyre csökken. Pattern Classification, Chapter")
56
Pattern Classification, Chapter 3
Példa – P(x | D) kiszámítása 56 P( | D) megvan, P(x | D) még kiszámítandó! Levezethető, hogy P(x | D) normális eloszlás az alábbi paraméterekkel: Tehát n lesz a várható érték, σ-hoz pedig hozzáadódik σn, kifejezve a -re vonatkozó bizonytalanságot Többváltozós eset: Pattern Classification, Chapter 3
 kiszámítása. 56. P( | D) megvan, P(x | D) még kiszámítandó! Levezethető, hogy P(x | D) normális eloszlás az alábbi paraméterekkel: Tehát n lesz a várható érték, σ-hoz pedig hozzáadódik σn, kifejezve a -re vonatkozó bizonytalanságot. Többváltozós eset: Pattern Classification, Chapter 3.")
57
MLE vs. Bayes becslés Ha n→∞ akkor megegyeznek!
57 MLE vs. Bayes becslés Ha n→∞ akkor megegyeznek! maximum-likelihood becslés egyszerű, gyors(abb) /grádiens keresés vs. multidim. integrálás/ Bayes becslés ha a feltevéseink bizonytalanok bizonytalanságot a P()-val modellezhetjük
 /grádiens keresés vs. multidim. integrálás/ Bayes becslés. ha a feltevéseink bizonytalanok. bizonytalanságot a P()-val modellezhetjük.")
58
Összefoglalás Bayes döntéselmélet Bayes osztályozó
Egy nagyon általános keret valószínűségi döntések meghozatalához Bayes osztályozó Az osztályozás egy speciális döntés (1 : válasszuk 1-t) Nulla-Egy veszteségfüggvény figyelmen kívül hagyható Normális eloszlású likelihood esetén a Bayes osztályozó
 Nulla-Egy veszteségfüggvény. figyelmen kívül hagyható. Normális eloszlású likelihood esetén a Bayes osztályozó.")
59
Összefoglalás Paraméterbecslések
Általános módszer paraméteres eloszlások paramétereinek becslésére egy minta alapján (nem csak Bayes!) Egy lehetséges módja a Bayes döntéselmélet gyakorlatban történő megvalósításához (gépi tanulás)
 Egy lehetséges módja a Bayes döntéselmélet gyakorlatban történő megvalósításához (gépi tanulás)")
Hasonló előadás









 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")






 algebrai struktúra gyűrű, ha + és · R-en binér műveletek, valamint I. (R, +) Abel-csoport, II. (R, ·) félcsoport, és III.>")


 osztályozó a Bayes világból>")