Előadást letölteni
0
Lineáris gépek márc. 5.

1
Gépi tanulási módszerek
eddig Bayes döntéselmélet Paraméteres osztályozók Nem paraméteres osztályozók Fogalom tanulás Döntési fák

2
Döntési felületek Most a döntési függvények/felületek alakjára teszünk feltevéseket, abból indulunk ki Nem optimális megoldások, de könnyen kezelhető eljárások Lineáris osztályozókat (gépeket) adnak eredményül
 adnak eredményül.")
3
Normális eloszláshoz tartozó döntési felület (i = esete)
")
4
A döntési fa döntési felületei

5
Lineáris diszkriminancia függvények és döntési felületek
két-kategóriás osztályozó: Válasszuk 1–et, ha g(x) > 0, 2–t, ha g(x) < 0 Válasszuk 1 –et, ha wtx > -w0 és 2 –t különben Ha g(x) = 0 bármelyik osztályhoz rendelhetjük x –et Lineáris gép = lineáris diszkriminancia függvény: g(x) = wtx + w0 w súlyvektor w0 konstans (eltolás, bias)
 > 0, 2–t, ha g(x) < 0. Válasszuk 1 –et, ha wtx > -w0 és 2 –t különben. Ha g(x) = 0 bármelyik osztályhoz rendelhetjük x –et. Lineáris gép = lineáris diszkriminancia függvény: g(x) = wtx + w0. w súlyvektor. w0 konstans (eltolás, bias)")
6
A g(x) = 0 definiálja azt a döntési felületet, amely elválasztja azokat a pontokat, amelyekhez 1-et rendelünk, azoktól, amelyekhez 2-t Ha g(x) lineáris függvény, akkor a döntési felület egy hipersík
 lineáris függvény, akkor a döntési felület egy hipersík.")
8
döntési felület távolsága az origótól:
A döntési felület irányát a w normál vektora határozza meg, míg a helyét a konstans

9
Ha több, mint 2 osztályunk van
c darab lineáris diszkriminancia függvényt definiálunk és az x mintát a i osztályhoz rendeljük, ha gi(x) > gj(x) j i; ha a legnagyobb értéknél egyenlőség van, határozatlan
 > gj(x) j i; ha a legnagyobb értéknél egyenlőség van, határozatlan.")
11
Ha több, mint 2 osztályunk van
Ri döntési tartomány: az a térrész ahol gi(x) értéke a legnagyobb A folytonos Ri és Rj döntési tartományokat a Hij hipersík egy része választja el a hipersík definíciója: gi(x) = gj(x) (wi – wj)tx + (wi0 – wj0) = 0 wi – wj merőleges (normál vektor) Hij -re és
 értéke a legnagyobb. A folytonos Ri és Rj döntési tartományokat a Hij hipersík egy része választja el. a hipersík definíciója: gi(x) = gj(x) (wi – wj)tx + (wi0 – wj0) = 0. wi – wj merőleges (normál vektor) Hij -re és.")
12
Konvexitás Könnyű megmutatni, hogy a lineáris géppel definiált döntési tartományok konvexek. Ez rontja az osztályozó flexibilitását és pontosságát… Az osztályokat elválasztó döntési felületek nem feltétlenül lineárisak, a döntési felület bonyolultsága gyakran magasabb rendű (nem lineáris) felületek használatát indokolja
 felületek használatát indokolja.")
13
Homogén koordináták

14
Lineáris gépek tanulása
14 Lineáris gépek tanulása

15
Lineáris gépek tanulása
15 Lineáris gépek tanulása Határozzuk meg a döntési felület paraméteres alakját Adott tanuló példák segítségével adjuk meg a „legjobb” felületet Ezt általában valamilyen kritériumfüggvény minimalizálásával tesszük meg Pl. tanulási hiba

16
Két osztály, lineárisan elválasztható eset
16 Normalizáció: ha yi ω2-beli, helyettesítsük yi-t -yi -al Olyan a-t keresünk, hogy atyi>0 (normalizált változat) Nem egyértelmű a megoldás!
 Nem egyértelmű a megoldás!")
17
Iteratív optimalizálás
17 Iteratív optimalizálás Definiáljunk egy J(a) kritériumfüggvényt, amely minimális, ha a megoldásvektor. Minimalizáljuk J(a) –t iteratív módon a(k+1) Keresési irány Tanulási arány a(k)
 kritériumfüggvényt, amely minimális, ha a megoldásvektor. Minimalizáljuk J(a) –t iteratív módon. a(k+1) Keresési irány. Tanulási arány. a(k)")
18
18 Gradiens módszer Tanulási arány, k-től függ, pl. „hűtési stratégia”

19
19 Gradiens módszer

20
Tanulási arány? 20

21
Newton módszer Valós függvények zérushelyeinek iteratív, közelítő meghatározása

22
Newton módszer Hogyan válasszuk a h(k) tanulási arányt?
22 Newton módszer Hogyan válasszuk a h(k) tanulási arányt? J(a) minimális ha Hess mátrix
 tanulási arányt J(a) minimális ha. Hess mátrix.")
23
Gradiens és Newton összehasonlítása
23 Gradiens és Newton összehasonlítása

24
24 Perceptron szabály

25
Perceptron szabály Kritérium Függvény:
25 Perceptron szabály Y(a): a által rosszul osztályozott minták halmaza. Ha Y(a) üres, Jp(a)=0; különben, Jp(a)>0 Kritérium Függvény:
: a által rosszul osztályozott minták halmaza. Ha Y(a) üres, Jp(a)=0; különben, Jp(a)>0. Kritérium. Függvény:")
26
Perceptron szabály A Jp(a) gradiense:
26 Perceptron szabály A Jp(a) gradiense: A perceptron szabály gradiens módszerbeli alkalmazásával kapható:
 gradiense: A perceptron szabály gradiens módszerbeli alkalmazásával kapható:")
27
27 Perceptron szabály Az összes rosszul osztályozott minta a(k) szerint Perceptron konvergencia tétel: Ha a mintánk lineárisan szeparálható, akkor a fenti algoritmus súlyvektora véges számú lépésben megoldást ad.

28
Perceptron szabály Sztochasztikus gradiens módszer:
28 Perceptron szabály η(k)=1 egyesével vegyük a példákat Sztochasztikus gradiens módszer: gradienst – nem a teljes adatbázison – csak kis részminták sorozatán számolunk, modell gyakran frissül
=1. egyesével. vegyük a. példákat. Sztochasztikus gradiens módszer: gradienst – nem a teljes adatbázison – csak kis részminták sorozatán számolunk, modell gyakran frissül.")
29
29 Perceptron szabály Mozgassuk a hipersíkot úgy, hogy az összes mintaelem a pozitív oldalán legyen. a2 a2 a1 a1

30
Online vs offline tanuló algoritmus
Online tanuló algoritmus: tanító példák hozzáadásával frissül a modell Offline (kötegelt) tanuló algoritmus: tanító adatbázis egészét egyben dolgozza fel a tanuló Online előnye: - nem kell az egész adatbázist tárolni implicit adaptáció Online hátránya: - pontatlanabb tud lenni
 tanuló algoritmus: tanító adatbázis egészét egyben dolgozza fel a tanuló. Online előnye: - nem kell az egész adatbázist tárolni. implicit adaptáció. Online hátránya: - pontatlanabb tud lenni.")
31
Nem-szeparálható eset
31 Nem-szeparálható eset Alkalmazhatunk más kritériumfüggvényt: a kritériumfüggvény minden mintaelemet figyelembe vesz „jósági” mérték lehet például a döntési felülettől mért előjeles távolság

32
SVM

33
33 Melyik megoldás jobb?

34
Ezek a legnehezebben osztályozható minták.
34 Szegély: a döntési felület körüli üres terület, amelyet a legközelebbi pont(ok) (= támasztó vektor(ok)) segítségével definiálunk Ezek a legnehezebben osztályozható minták.
 (= támasztó vektor(ok)) segítségével definiálunk. Ezek a legnehezebben osztályozható minták.")
35
35

36
SVM (support vector machine)
36 SVM (support vector machine) támasztó vektorok módszere, szupport vektor gép Az SVM olyan lineáris gép ahol a kritérium függvény legyen az osztályok közötti szegély maximalizálása! Ez jó általánosítást szokott biztosítani A tanítás ekvivalens egy lineáris feltételekkel adott kvadratikus programozási feladattal
 támasztó vektorok módszere, szupport vektor gép. Az SVM olyan lineáris gép ahol a kritérium függvény legyen az osztályok közötti szegély maximalizálása! Ez jó általánosítást szokott biztosítani. A tanítás ekvivalens egy lineáris feltételekkel adott kvadratikus programozási feladattal.")
37
lineárisan elválasztható eset
SVM lineárisan elválasztható eset

38
Lineáris SVM: az elválasztható eset
38 Tanító adatbázis: Keressük w-t, hogy Normalizált változat:

39
Lineáris SVM: az elválasztható eset
39 Lineáris SVM: az elválasztható eset Tfh a margó mérete ρ Az xk pontnak az elválasztó hipersíktól való távolságára teljesülnie kell: Az egyértelműség biztosítására: ρ maximalizálása = minimalizálása

40
Lineáris SVM: az elválasztható eset
40 Lineáris SVM: az elválasztható eset A szegély maximalizálása:

41
Lineáris SVM: az elválasztható eset
41 Lineáris SVM: az elválasztható eset Alkalmazzunk Lagrange optimalizálást: (konvex kvadratikus optimalizálási feladat)
")
42
Lineáris SVM: az elválasztható eset
42 Lineáris SVM: az elválasztható eset Duális feladat (könnyebb megoldani): feltéve
: feltéve.")
43
Lineáris SVM: az elválasztható eset
43 Lineáris SVM: az elválasztható eset A megoldás a következő alakú: bármely t-ből Megmutatható, hogy akkor és csak akkor ha xt támasztóvektor A döntési felület a tanító példák „súlyozott átlaga” csak a támasztóvektorok járulnak hozzá a megoldáshoz!!

45
lineárisan nem elválasztható eset
SVM lineárisan nem elválasztható eset

46
Lineáris SVM: a nem-elválasztható eset
46 Lineáris SVM: a nem-elválasztható eset A ξ hibaváltozó bevezetésével hibás osztályozást is megenged („puha szegély”): ξt=0 ha helyes az osztályozás, egyébként a margótól mért távolság Szabályozhatjuk a téves osztályozások számát vs. margó méretét
: ξt=0 ha helyes az osztályozás, egyébként a margótól mért távolság. Szabályozhatjuk a téves osztályozások számát vs. margó méretét.")
48
Lineáris SVM: a nem-elválasztható eset
48 Lineáris SVM: a nem-elválasztható eset Lagrange paraméterekkel:

49
SVM nem lineáris eset

50
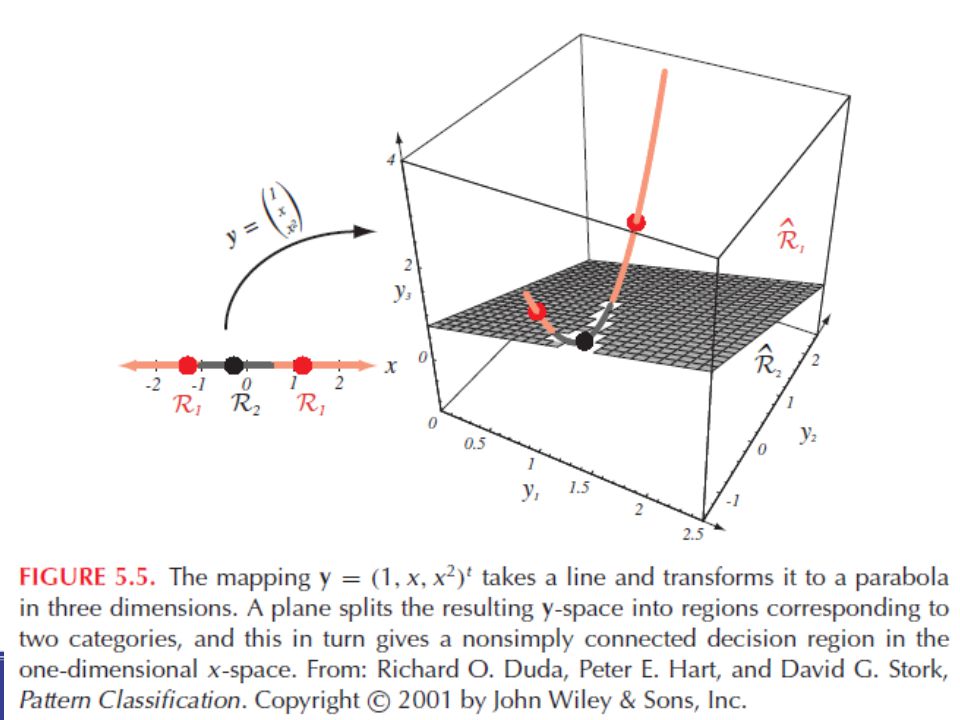
Általánosított lineáris diszkriminancia függvények
Kvadratikus döntési függvények: Általános lineáris döntési függvények: ahol az yi: Rd → R tetszőleges függvények x-ben nem lineáris, de yi-ben g(y) igen (az y-térben g(x) hipersík)
 igen. (az y-térben g(x) hipersík)")
51
Példa

54
54 Nemlineáris SVM

55
55 Nemlineáris SVM Φ legyen (jóval) magasabb k dimenziószámú térbe leképezés: Bármilyen adathalmaz, megfelelően nagy dimenzióba történő alkalmas leképezéssel lineárisan elválasztható lesz az új térben!

56
56 Nemlineáris SVM Lineáris SVM a leképzett térben:

57
57 A kernel trükk A belső szorzatokat egy magfüggvény (kernel) segítségével számoljuk! A kernel használatának előnyei Nem kell ismerni Φ()-t !! A diszkriminancia a következő alakú: g(x)=
-t !! A diszkriminancia a következő alakú: g(x)=")
58
Példa: polinomiális kernel
58 Példa: polinomiális kernel K(x,y)=(x y) p d=256 (eredeti dimenziószám) p=4 h= (új tér dimenziószáma) a kernel ismert (és gyorsan számítható) a leképezés nem…
=(x y) p. d=256 (eredeti dimenziószám) p=4. h= (új tér dimenziószáma) a kernel ismert (és gyorsan számítható) a leképezés nem…")
59
Egy kernel több leképezésnek is megfelel
59 Egy kernel több leképezésnek is megfelel Ezek is megfelelőek:

60
Kernelek a gyakorlatban
60 Kernelek a gyakorlatban A projektált tér nem egyértelmű és nem ad támpontot kernel tervezéshez…

61
61 Példa: XOR

62
62 Példa: XOR

63
63 Példa:XOR

64
64 Példa: XOR

65
Megjegyzések az SVM-hez
65 Megjegyzések az SVM-hez Globális optimalizálás, nem lokális (pontos optimum, nem közelítés). Az SVM hatékonysága a kernel és paramétereinek választásától függ Egy adott problémához a legjobb kernel választása „művészet”
. Az SVM hatékonysága a kernel és paramétereinek választásától függ. Egy adott problémához a legjobb kernel választása „művészet")
66
Megjegyzések az SVM-hez
66 Megjegyzések az SVM-hez A komplexitása a támasztó vektorok számától, és nem a transzformált tér dimenziójától függ A gyakorlatban kis mintánál is jó általánosítási tulajdonságok Többosztályos SVM: one-vs-all (legnagyobb g()) one-vs-one (legtöbb győzelem) direkt optimalizáció
) one-vs-one (legtöbb győzelem) direkt optimalizáció.")
67
Összefoglalás Lineáris gépek Gradiens és Newton módszer Perceptron SVM
Szeparálható eset Nem szeparálható eset Nem lineáris eset (magfüggvény)
")










 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")


![Egy f R[x] polinom cS -beli helyettesítési értéke](/8/2091984/big_thumb.jpg "Egy f R[x] polinom cS -beli helyettesítési értéke>")



, Kernel „trükk”.>")

 osztályozó a Bayes világból>")




.>")
