Előadást letölteni
1
Megerősítéses tanulás 8. előadás
Szita István, Lőrincz András

2
Ismétlés: miért jó a függvényapproximátor?
ha túl nagy az állapottér nincs időnk minden egyes állapot értékét becsülni csak egy töredékében járunk egyáltalán általánosítani kell kevés mintapontból minden állapotra tudunk valamit mondani kevesebb paramétert kell hangolni hagyományos megoldás: függvényillesztés (approximáció)
")
3
Függvényillesztés a lehető legjobban közelítő függvény
függvényérték néhány pontban a lehető legjobban közelítő függvény

4
Függvényillesztés formálisan
adatpontok: célértékek: függvénycsalád: cél: találjunk olyan *-t, hogy legyen minden i helyen mi a függvénycsalád, mi ? pl: neuronhálózatok: ha n neuronja van, n2-dimenziós vektor, ami leírja az egyes neuronok közötti kapcsolatok erősségét *: az a súlyvektor, amivel a neuronhálózat a legjobban közelíti az yi-ket. megtalálása: súlyvektort hangolgatjuk (pl. backpropagation). nem megyünk bele részletesen – külön óra témája
. nem megyünk bele részletesen – külön óra témája.")
5
Függvényilesztés: lineáris függvényapproximátorok
egyszerűbb példa: van egy csomó bázisfüggvényünk: a közelítő függvényt ezek lineáris kombinációjaként szeretném előállítani: ekkor tehát : k-dimenziós vektor, függvénycsalád: a bázisfüggvények lineáris kombinációi mennyire jó a lin. fapp.? attól függ, milyenek a bázisfüggvények

6
Bázisfüggvények megszabja, milyen módon általánosítunk példák:
halmaz karakterisztikus függvénye (pl. körön 1, kívül 0) radiális bázisfv a feladat lényeges jellemzői (pl. sakk: bábuk száma, van-e sakkban a király, üthető-e a királynő/bástya, stb. kulcsszerepe van a feladat megoldhatóságában ezzel mi viszünk be tudást a tanulórendszerbe lineáris bázisfv-knél kellenek még a kettes, hármas, stb kombinációk is
 radiális bázisfv. a feladat lényeges jellemzői (pl. sakk: bábuk száma, van-e sakkban a király, üthető-e a királynő/bástya, stb. kulcsszerepe van a feladat megoldhatóságában. ezzel mi viszünk be tudást a tanulórendszerbe. lineáris bázisfv-knél kellenek még a kettes, hármas, stb kombinációk is.")
7
Függvényillesztés még mindig – a módszer
minimalizáljuk az eltérést az adatpontok és a becslés között általában négyzetes hiba (könnyű vele számolni) bízunk benne, hogy az adatpontokon kicsi lesz a hiba a többi pontban is kicsi lesz a hiba (jó általánosítás) hogy éppen ezt a hibamrtéket szeretnénk minimalizálni a minimalizálás végrehajtása: gradiensmódszer
 bízunk benne, hogy. az adatpontokon kicsi lesz a hiba. a többi pontban is kicsi lesz a hiba (jó általánosítás) hogy éppen ezt a hibamrtéket szeretnénk minimalizálni. a minimalizálás végrehajtása: gradiensmódszer.")
8
Függvényillesztés – a gradiensmódszer
J( ) gradiense: a deriváltakból kapott vektor a legmeredekebb növekedés iránya -1-szerese a legmeredekebb csökkenés iránya gradiensmódszer: 0 tetszőleges, pici ismételjük, míg be nem érünk egy lokális minimumba
 gradiense: a deriváltakból kapott vektor. a legmeredekebb növekedés iránya. -1-szerese a legmeredekebb csökkenés iránya. gradiensmódszer: 0 tetszőleges, pici. ismételjük, míg be nem érünk egy lokális minimumba.")
9
Függvényillesztés – a gradiensmódszer
mennyire változik f, ha -t picit variálom kiszámolása függ a konkrét függvénycsaládtól neuronhálózatok: a backprop algoritmus mondja meg lineáris: triviálisan kapjuk

10
RL alkalmazás: fix stratégia kiértékelése
utána használhatom p: súlyozás – a gyakori állapotok értéke jobban számít úgyis mintavételezni fogunk – gyakori állapotokból többet, úgyhogy ezt könnyebb is mintavételezni m darab minta (pl. m lépésen át követem -t)
")
11
fix stratégia kiértékelése
online gradiens-számolás: követjük a stratégiát (ettől online) aktuális állapot: st nem szummázunk, csak az aktuális állapotot vesszük figyelembe következő probléma: nem ismerjük V(st)-t mintavételezzük pl. Monte Carloval: V(st) helyett Rt, E(Rt | st) = V(st) Rt-k független véletlen mennyiségek sztochasztikus gradiensbecslés
 aktuális állapot: st. nem szummázunk, csak az aktuális állapotot vesszük figyelembe. következő probléma: nem ismerjük V(st)-t. mintavételezzük pl. Monte Carloval: V(st) helyett Rt, E(Rt | st) = V(st) Rt-k független véletlen mennyiségek. sztochasztikus gradiensbecslés.")
12
fix stratégia kiértékelése
a sztochasztikus gradiensmódszer konvergál, t ! *, ha V mintavételezettjei függetlenek, torzítatlanok (pl. Rt) st-ket a stratégia alapján választjuk t „szépen” tart 0-hoz kijön a sztochasztikus becslés-tételből
 st-ket a stratégia alapján választjuk. t „szépen tart 0-hoz. kijön a sztochasztikus becslés-tételből.")
13
RL+függvényillesztés = sok probléma
TD becslés: se nem független, se nem torzítatlan… bizony elképzelhető, hogy nem konvergál ugyanez igaz DP becslésre is: még ha konvergál is: * csak lokális minimum elképzelhető, hogy nagyon rossz közelítése lesz V-nek neuronhálók használata esetén pl. sok a lokális minimum

14
RL+függvényillesztés = sok probléma
nem is biztos, hogy azt minimalizáljuk, amit kellett… döntéskor majd a relatív nagyságok kellenek lehet, hogy a négyzetes hiba pici, de a relatív nagyságok rosszak nem tudunk jobbat… V v

15
Mit csináljunk a problémákkal?
legegyszerűbb: semmit gyakorlatban működik, elmélet meg nem lesz lényegében az összes sikeres RL alkalmazás neuronhlókat használ függvényapproximátorként… megszorítjuk a függvénycsaládot: lineáris fapp-ok bázisfüggvények: tömör jelölés: a gradiens egyszerű: TD becslés:

16
Lineáris függvényapproximáció
lineáris fapp-ra a négyzetes hibafüggvény ( J ) kvadratikus, tehát egyértelmű globális minmuma van megmutatható, hogy a TD módszer is konvergál ha st-ket a stratégiát követve kapom de nem *-hoz! ehelyett valami máshoz: t ! 1 erről csak azt tudjuk, hogy nem túl rossz:
 kvadratikus, tehát egyértelmű globális minmuma van. megmutatható, hogy a TD módszer is konvergál. ha st-ket a stratégiát követve kapom. de nem *-hoz! ehelyett valami máshoz: t ! 1. erről csak azt tudjuk, hogy nem túl rossz:")
17
egy ellenpélda ha nem -t követem, még mindig elszállhat
TD helyett DP (az egyszerűség kedvéért) minden állapot azonos súllyal szerepel nem szerinti súlyozás 6 állapot, 7 bázisfv (bázisfüggvények: lin. függetlenek)
 minden állapot azonos súllyal szerepel. nem szerinti súlyozás. 6 állapot, 7 bázisfv. (bázisfüggvények: lin. függetlenek)")
18
egy ellenpélda

19
Optimális stratégia tanulása függvényapproximátorral
a problémák csak sokasodnak… a V célfüggvény folyton változik pedig amúgy is csak közelítettük egy ilyen kétszeres közelítést kellene jól eltalálni a fapp-pal… ráadásul nekünk Q(s,a)-t kell közelíteni (hogy tudjunk egyszerűen döntést hozni) S helyett S£A-n illesztünk függvényt probléma: minden lépésben maximális értékű akciót kell keresni a mohó lépésben– ez lépésenként egy maximalizálás probléma: a maximum helye eltolódhat minden a-ra külön fapp – véges sok akcióra ez a legtisztább
-t kell közelíteni (hogy tudjunk egyszerűen döntést hozni) S helyett S£A-n illesztünk függvényt. probléma: minden lépésben maximális értékű akciót kell keresni a mohó lépésben– ez lépésenként egy maximalizálás. probléma: a maximum helye eltolódhat. minden a-ra külön fapp – véges sok akcióra ez a legtisztább.")
20
Optimális stratégia tanulása
TD hiba (Sarsa): TD hiba (Q-learning): paraméter-állítás láttuk, hogy ha nem az aktuális stratégiát követjük, elszállhat a paraméterbecslés a Q-learning nem az aktuális stratégiát használja! (hanem a mohót) van példa, amire elszáll pedig táblázatos tanulásra a Q-learning konvergenciája volt a legegyszerűbb…
: TD hiba (Q-learning): paraméter-állítás. láttuk, hogy ha nem az aktuális stratégiát követjük, elszállhat a paraméterbecslés. a Q-learning nem az aktuális stratégiát használja! (hanem a mohót) van példa, amire elszáll. pedig táblázatos tanulásra a Q-learning konvergenciája volt a legegyszerűbb…")
21
Optimális stratégia tanulása fapp-pal – mit tudunk?
nemlineáris fapp (pl. neuronháló): divergálhat lineáris fapp + Q-learning: divergálhat lineáris fapp + Sarsa: korlátos marad nem feltétlenül konvergál egy pontba kóvályoghat egy tartományon belül lineáris fapp + „óvatos” RL algoritmus: konvergens csak bonyolult Sarsa/Q-learning + lineáris fapp speciális bázisfüggvényekkel: konvergens a gyakorlat szempontjából mindegy: mindegyik jól használható
: divergálhat. lineáris fapp + Q-learning: divergálhat. lineáris fapp + Sarsa: korlátos marad. nem feltétlenül konvergál egy pontba. kóvályoghat egy tartományon belül. lineáris fapp + „óvatos RL algoritmus: konvergens. csak bonyolult. Sarsa/Q-learning + lineáris fapp speciális bázisfüggvényekkel: konvergens. a gyakorlat szempontjából mindegy: mindegyik jól használható.")
22
Backgammon (vagy Ostábla)
")

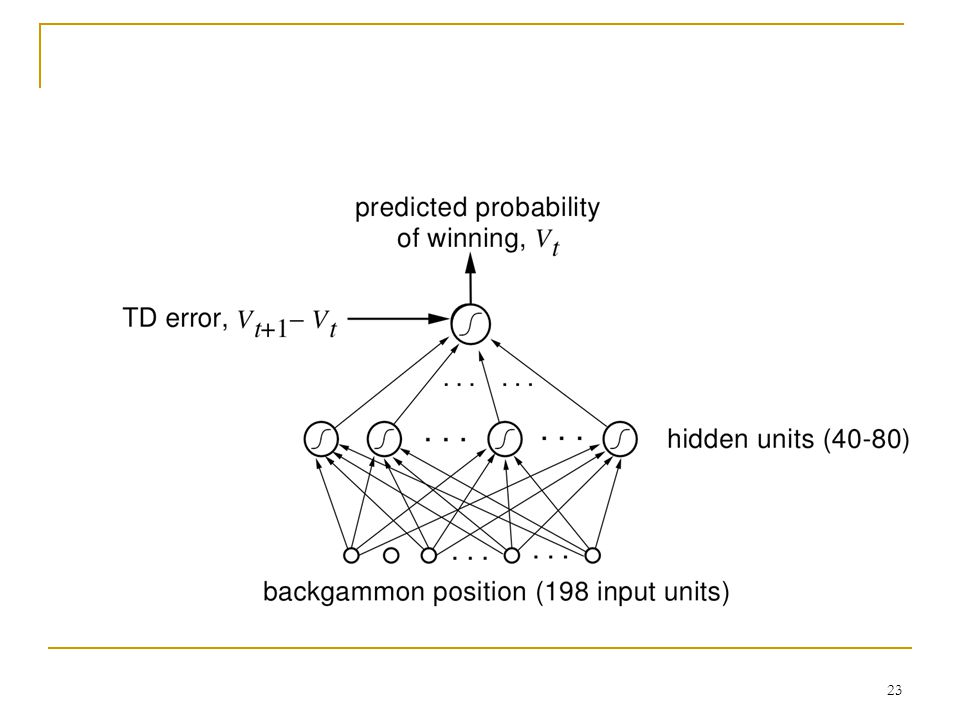





 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")


>")







.>")


