Előadást letölteni
1
Dobos László Komplex Rendszerek Fizikája Tanszék

2
Tartalom 1. Adatcunami 2. Adatfeldolgozásra optimalizált hardver 3. Tudományos adatbázisok RDBMS tudományos alkalmazásai 4. noSQL adattárak 5. RDBMS fejlesztési irányok 6. Tömbadatbázisok

3
Moore-törvény

4
Exponenciális növekedés Elektronika Detektor- technika Adatmennyiség

5
Csillagászati adatbázisok mérete SDSS PanSTARRSLSST

6
Diszkek tárolókapacitása Forrás: Wikipedia GMR: giant magnetoresistance PMR: perpendicular magnetic recording PMR technológia GMR technológia

7
Tudományos adatok Csillagászat Égtérképek: nagy statisztikus minták Részecskefizika Tű keresése a szénakazalban Biológia Fehérjehálózatok: gráfanalízis Genetika: mintaillesztés Ökológia: szenzorhálózatok Képadatbázisok (CT, MR, PET stb.) Internet kutatása Szociális hálózatok, hálózattomográfia Geofizika, meteorológia Sokrétegű képek, idősor analízis, turbulens jelenségek
 Internet kutatása Szociális hálózatok, hálózattomográfia Geofizika, meteorológia Sokrétegű képek, idősor analízis, turbulens jelenségek")
8
A negyedik paradigma KísérletElméletSzimuláció Adat- bányászat

10
Adattárházak

11
Problémák Nem nő minden exponenciálisan Adatátvitel sebessége Algoritmusok skálázása Ha nagyobb, mint o(n), akkor az exponenciálisan növekedő adatmennyiség egészére nem lesz lefuttatható Problémák particionálása
, akkor az exponenciálisan növekedő adatmennyiség egészére nem lesz lefuttatható Problémák particionálása")
12
Adattároló egységek RAM Gyors $$$$$ Diszk Lassú $ SSD Írás? $$$

13
Diszk = szalag =

14
1 TB-os lemez elolvasása Szekvenciálisan:4,5 óra Random módon:15-150 nap

15
Gene Amdahl törvényei Törvények kiegyensúlyozott rendszerek esetére (1965) Teljes probléma:1 = P + S Max gyorsulás:a = 1 / (S + P / N) Amdahl-szám:1 bit IO / s 1 utasítás / s Memória:1 bájt memória 1 utasítás / s
 Teljes probléma:1 = P + S Max gyorsulás:a = 1 / (S + P / N) Amdahl-szám:1 bit IO / s 1 utasítás / s Memória:1 bájt memória 1 utasítás / s")
16
Amdahl-féle kiegyensúlyozott rendszerek Blue Gene: A IO = 0,013 Graywulf:A IO = 0,5 Amdahl:A IO = 1,25 OPSRAMIO Byte/s # of 100 Mb/s disks Disks × RAM # of 1 TB disks Giga10 09 Gigabyte10 8 110 11 1 Tera10 12 Terabyte10 11 1,00010 14 100 Peta10 15 Petabyte10 14 1000,00010 17 100,000 Exa10 18 Exabyte10 17 1000,000,00010 20 100,000,000

18
Amdahl-klaszter

19
ELTÉn levő rendszerek Regionális Egyetemi Tudásközpont 3 × Dell PowerEdge 2950, 8 core Xeon, 16 GB RAM 6 × Dell MD1000 SAS, összesen kb. 45 TB SQL Server 2008 R2, 3GB/s szekvenciális IO JHU Graywulf rendszer node-jaival azonos Klimatizálás örök probléma „Jim Gray” klaszter az Informatikai karon 4 × Supermicro SuperServer SYS-6036ST-6LR „2 gép egy házban” konfiguráció Összesen 96 mag, 192 GB RAM, 112 TB diszk IO rendszer sebessége még nem ismert

20
Jim Gray törvényei Scale-out: Az adatfeldolgozás csak masszív párhuzamosítással oldható meg Az számolást kell vinni az adathoz és nem az adatot a számoláshoz

21
Scale-up Platform skálázása, memória használat

22
Scale-out (SMP) Algoritmusok párhuzamosítása nehéz
 Algoritmusok párhuzamosítása nehéz")
23
Scale-out (klaszter) Hálózat lassú!
 Hálózat lassú!")
25
Hagyományos eszközök R, matlab, IDL stb. Memória mérete korlátozó tényező Gyenge háttértár kihasználás Adatok fájlokban (sokszor csak TXT) Minimális adatbázis támogatás Ki kell húzni az adatot a feldolgozáshoz
 Minimális adatbázis támogatás Ki kell húzni az adatot a feldolgozáshoz.")
26
Adatbázis-szerverek RDBMS Adatok RDBMS újításai DW célokra noSQL

27
RDBMS Üzleti célra fejlesztve Tranzakció kezelés és adattárház egyben Tudunk-e profitálni az adattárház funkciókból tudományos céllal? Elegendő-e a relációs adatmodell? Tudományban sokdimenziós adatok Elegendő-e a funkcionalitás? Matek könyvtárak?

28
OLTP vs. DW Sok kicsi, random művelet Kis késleltetés Szinkron redundancia Nagy vas elegendő Nagy, sok adatot érintő műveletek A gyors válasz annyira nem fontos Aszinkron redundancia elég Egy gépen nem fér el az adat

29
RDBMS nagy előnyei Deklaratív programozhatóság A szerver optimalizálni tudja a lekérdezést Rengeteg előre megírt fizikai operátor Minden query végrehajtható (kérdés milyen gyorsan) Készen kapjuk: Párhuzamos query futtatás Optimalizált szekvenciális IO Optimalizált memória használat
 Készen kapjuk: Párhuzamos query futtatás Optimalizált szekvenciális IO Optimalizált memória használat")
30
RDBMS további előnyei Saját kód futtatása a folyamaton belül Nincsen kommunikációs költségtöbblet Matek könyvtárak integrálhatók Speciális indexek implementálhatók Standard API (ODBC, JDBC, OleDB) Széleskörű, üzleti színvonalú támogatás
 Széleskörű, üzleti színvonalú támogatás")
31
RDBMS hátrányai A relációs adatmodell gyakran nem elég Tömbök (pl. nagy képek, adatkockák) Gráfok Üzleti szempontok szerint fejlődik Olyan irányba fejlődnek, ahonnan a pénz várható Nem elosztott rendszerek
 Gráfok Üzleti szempontok szerint fejlődik Olyan irányba fejlődnek, ahonnan a pénz várható Nem elosztott rendszerek.")
33
Web 2.0 Keresők, óriásáruházak, közösségi oldalak Dinamikus növekedés A nagy vasak nem bővíthetők a végtelenségig Hatalmas adatmennyiség Kevésbé strukturált adatok Magas rendelkezésre állás Nem baj, ha nem teljesen konzisztens RDBMS

34
Elosztott rendszerek Elosztott rendszerekre nagy igény lett 1000+ nódus olcsó szerverekből A nódusok meghibásodás a napi rutin része RDBMS-nél máig megoldatlan a több gépre történő scale-out Fő probléma: elosztott JOIN Próbálkozások vannak, pl. MySQL Cluster, Graywulf stb. Megoldás: új megközelítésű adatbázisok

35
noSQL adatbázisok Igény elosztott rendszerekre Sürgős fejlesztési kényszer Az RDBMS nagyon bonyolult Legyen egyszerűbb, de elosztott! Min lehet spórolni? Egyszerűsített tranzakciós modell Nincsen ACID Nincsenek scan és join műveletek Imperatív programozás (nincsen optimalizációs logika)
.")
36
Két fontos terület Nagy mennyiségű adat feldolgozása Rendszeres műveletek Sok adat redukálása Nagy számú felhasználó kiszolgálása Terhelés megosztása Random műveletek Adatok replikálása ○ Adatbiztonsági okokból ○ Terhelésmegosztás miatt

37
noSQL adatmodellek Key-Value (Redis, MongoDB, Scalien) Value lehet sokféle ○ Dokumentum (bináris, xml stb.) ○ String, lista, hash-tábla stb. BigTable (Google, Hbase, Cassandra) Sorok kulccsal Oszlopcsaládok (előre definiált) Oszlopok (nem előre definiált) Valójában key-value kompozit kulccsal
 Sorok kulccsal Oszlopcsaládok (előre definiált) Oszlopok (nem előre definiált) Valójában key-value kompozit kulccsal.")
38
Másodlagos indexek Alapművelet: adat megtalálása kulcs alapján Nincsen scan művelet Kereséshez mindenképp kell index

39
Hadoop Elosztott fájlrendszer Futtatókörnyezet Map és Reduce függvényt lehet implementálni Ebből kell összerakni az adatfeldolgozó programot

41
Elosztott adatbázis Adat particionálás (sharding) Vertikális particionálás Kulcs tartományok külön szervereken Funkcionális particionálás Függőleges particionálás Bizonyos oszlopok külön szervereken Redundancia Magas rendelkezésre állás Nem kell külön back-up Terheléselosztás + ezek kombinációi
 Vertikális particionálás Kulcs tartományok külön szervereken Funkcionális particionálás Függőleges particionálás Bizonyos oszlopok külön szervereken Redundancia Magas rendelkezésre állás Nem kell külön back-up Terheléselosztás + ezek kombinációi")
42
Konzisztencia Biztonsági mentés helyett replikáció Az adatok több példányban tárolódnak Mi biztosítja, hogy a replikák konzisztensek maradnak? Kell valami replikációs protokoll Általában aszinkron Konzisztencia ablak Mennyi idő után válik a rendszer konzisztenssé

43
Rendelkezésre állás Az adatok folyton elérhetőek Több belépési pont Nincsen egyetlen kritikus elem sem Geo-redundancia A válasz legyen gyors Minimális késleltetés Még akkor is, ha a visszaadott adat nem konzisztens

44
Partíció tűrés Elosztott rendszer Hálózati kapcsolat (lassú, törékeny) Több belépési pont A rendszer akkor is működőképes marad, ha egyes részei nem látják egymást Elosztott funkcionalitás
 Több belépési pont A rendszer akkor is működőképes marad, ha egyes részei nem látják egymást Elosztott funkcionalitás")
45
CAP-tétel A háromból egyszerre csak kettő teljesíthető! C AP

46
Tranzakciós modell lazítása ACID elosztott rendszernél nagyon drága (2PC) Hiba esetén nem lehet tranzakciót érvényesíteni Helyette: BASE basically available, soft-state, eventually consistent Eleve olyan rendszert feltételez, ahol vannak hibák A hibákat optimista módon kezeli A tranzakciók hatásai nem egy időben jelennek meg ehhez kellene a kétlépéses érvényesítés üzenet formájában, véges idő alatt terjednek
 Hiba esetén nem lehet tranzakciót érvényesíteni Helyette: BASE basically available, soft-state, eventually consistent Eleve olyan rendszert feltételez, ahol vannak hibák A hibákat optimista módon kezeli A tranzakciók hatásai nem egy időben jelennek meg ehhez kellene a kétlépéses érvényesítés üzenet formájában, véges idő alatt terjednek")
47
BASE BA: Basically available Főleg CP rendszer esetében Legalább a rendszer egy része maradjon elérhető Soft-state A változások véges ideig tartó üzenetekkel történnek A rendszer állapota akkor is változhat, ha épp nincsen input Minden adatra lehet egy érvényességi idő Ha ez lejárt, akkor meg kell vizsgálni, hogy konzisztens-e még Eventually consistent Főleg AP rendszer esetében A változások aszinkron propagálnak „Egy idő után” konzisztenssé válik Konzisztencia ablak

48
Konfliktusok feloldása Hiba miatt inkonzisztens állapot Fel kell oldani Gossip (pletyka) Paxos
 Paxos")
49
RDBMSBigTableHadoop Deklaratív nyelv, optimalizáló Optimalizált scan Optimális kulcs szerinti elérés Join műveletek Párhuzamos végrehajtás Klaszterezhetőség TranzakciókACIDBASE Redundancia Load balancing Nem strukturált adat Szabványos API

51
RDBMS fejlesztési irányok Elosztott JOIN Column store Ferris wheel (óriáskerék) Tömb adatmodell
 Tömb adatmodell")
52
Elosztott JOIN JOIN műveletek két

53
Graywulf Szalay Sándor Johns Hopkins Egyetem, Baltimore ELTE közreműködéssel SQL Server klaszterek tudományos célú felhasználása Load-balancing, probabilistic join, distributed join, array database stb. SkyQuery, turbulencia, stb.

54
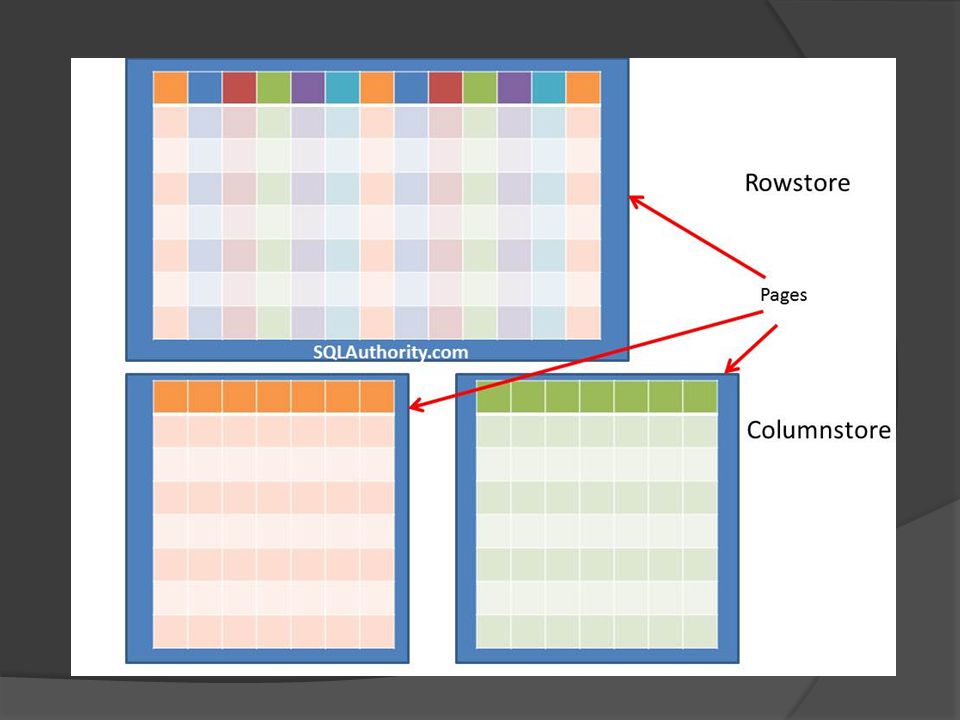
Column store RDMBS hagyományosan sorokat tárol B-fa struktúra, lapok, klaszterezett index stb. OLTP esetében ez az optimális Lap méret tradicionálisan kicsi (8k) Nagy scan műveletekre nem túl optimális Gond: széles táblák, keskeny queryk Felesleges beolvasni egy csomó dolgot Ötlet: tároljuk a táblát oszloponként!
 Nagy scan műveletekre nem túl optimális Gond: széles táblák, keskeny queryk Felesleges beolvasni egy csomó dolgot Ötlet: tároljuk a táblát oszloponként!.")
56
Oszloponkénti tárolás Cél: felesleges oszlopokat ne olvassuk Tárolási modell: oszloponként folytonosan Jó nagy darabokban Minden oszlop azonos sorrendben Nem kell kulcsot tárolni, mint az indexek esetében Csak egy sorrendben hatékony a keresés Egyes oszlopokat több sorrendben is érdemes tárolni JOIN indexek is kellhetnek Könnyebb tömörítés CPU gyors, lemez lassú, így gyorsítható OLTP-re nem jó (beszúrás, törlés drága) Megpatkolható, pl. c-store, vertica

57
Ferris wheel

58
Tömb alapú adatbázisok Elsősorban tudomány célra Tábla helyett array az alap típus Tárolási modell: chunkok

59
SciDB









 Budapest>")





 ÁRVAI ZOLTÁN KITCHEN BUDAPEST.>")











 egy XML-alapú nyelv a Web szolgáltatások leírására és azok.>")