Előadást letölteni
1
Dokumentum vektor modell, dokumentumok előfeldolgozása. PCA redukció

2
Szódokumentum mátrix előfordulás alapján

3
Szó-dokumentum mátrix előfordulás alapján
Eddig a szavak gyakoriságát nem vettük figyelembe Egy terminus előfordulásainak száma egy dokumentumban: szózsákmodell a dokumentum egy vektor az ℕv térben (egy oszlop)
")
4
Előfordulás vs. gyakoriság
Nézzük ismét a ides of march keresést Julius Caesar-ban 5-ször fordul elő az ides Más darabban nem fordul elő az ides march néhány tucat alkalommal fordul elő (több darabban) Minden daraban szerepel az of Ez alapján a legrelevánsabb a legtöbb of-ot tartalmazó darab lenne
 Minden daraban szerepel az of. Ez alapján a legrelevánsabb a legtöbb of-ot tartalmazó darab lenne.")
5
Terminus gyakoriság tf
További gond, hogy az előző mérték a hosszú dokumentumokat előnyben részesíti, mivel azok több szót tartalmaznak Első javítás: előfordulás (támogatottság) helyett gyakoriság (frekvencia) tft,d = a t terminus előfordulásainak száma d-ben osztva d szavainak számával Jó hír – a tf-ek szummája egy dokumentumra 1 lesz A dokumentumvektor L1 normája egy lesz Kérdés, hogy a nyers tf megfelel-e mértéknek?
 helyett gyakoriság (frekvencia) tft,d = a t terminus előfordulásainak száma d-ben osztva d szavainak számával. Jó hír – a tf-ek szummája egy dokumentumra 1 lesz. A dokumentumvektor L1 normája egy lesz. Kérdés, hogy a nyers tf megfelel-e mértéknek")
6
A terminus gyakoriság súlyozása: tf
Mi a relatív fontossága, ha egy szó egy dokumentumban 0-szor v. 1-szer fordul elő 1-szer v. 2-szer fordul elő 2-szer v. 3-szor fordul elő … Nem triviális: nyilván minél többször szerepel, annál jobb, de ez nem arányosan növekszik (márpedig a nyers tf-nél ez arányos) Használhatjuk mégis a nyers tf-et De vannak más, a gyakorlatban sokszor alkalmazott lehetőségek (The Kandy-Kolored Tangerine-Flake Streamline Baby) You’d have to let me know!
 Használhatjuk mégis a nyers tf-et. De vannak más, a gyakorlatban sokszor alkalmazott lehetőségek. (The Kandy-Kolored Tangerine-Flake Streamline Baby) You’d have to let me know!")
7
Skalárszorzat szerinti illeszkedés
Az illeszkedést a dokumentum és a keresőkifejezés skalárszorzataként határozzuk meg: [Megj: 0, ha merőlegesek (nincsenek közös szavak)] Az illeszkedés mértéke szerint rangsorolunk Alkalmazhatjuk a logaritmikus súlyozást (wf ) is a szorzatbana tf helyett Továbbra sem veszi figyelembe: A szó ritkaságát (megkülönböztető képességét) a dokumentumgyűjteményben (ides vs. of)
] Az illeszkedés mértéke szerint rangsorolunk. Alkalmazhatjuk a logaritmikus súlyozást (wf ) is a szorzatbana tf helyett. Továbbra sem veszi figyelembe: A szó ritkaságát (megkülönböztető képességét) a dokumentumgyűjteményben (ides vs. of)")
8
A szó fontossága függjön a korpuszbeli támogatottságától
Melyik informatívabb a dokumentum tartalmáról? Az adóalany szó 10 előfordulása? Az is 10 előfordulása? Korlátozni szeretnénk a gyakori szavak súlyát De mi számít gyakorinak? Ötlet: korpusztámogatottság (collection frequency - cf ) A terminus összes előfordulásainak száma a teljes gyűjteményben
 A terminus összes előfordulásainak száma a teljes gyűjteményben.")
9
Dokumentumtámogatottság (df)
Azonban a dokumentumtámogatottság (df ) jobbnak tűnik: Szó cf df ferrari insurance A két mérőszám megadása csak ismert (statikus) korpuszok esetén lehetséges. Hogyan használjuk ezután a df-et?
 jobbnak tűnik: Szó cf df. ferrari insurance A két mérőszám megadása csak ismert (statikus) korpuszok esetén lehetséges. Hogyan használjuk ezután a df-et")
10
tf-idf súlyozás tf-idf mérték komponensei: szógyakoriság (tf )
vagy wf, a szó sűrűségét határozza meg a dokumentumban inverz dokumentumtámogatottság (idf ) a szó megkülönböztető képességéet adja meg a korpuszbeli ritkasága alapján számolható egyszerűen a szót tartalmazó dokumentumok száma alapján (idfi = 1/dfi) de a leggyakoribb verzió: Papineni shows the above usually used scaled IDF is optimal for document self retrieval.
 a szó megkülönböztető képességéet adja meg a korpuszbeli ritkasága alapján. számolható egyszerűen a szót tartalmazó dokumentumok száma alapján (idfi = 1/dfi) de a leggyakoribb verzió: Papineni shows the above usually used scaled IDF is optimal for document self retrieval.")
11
Összefoglalás: tf-idf
Minden i szóhoz minden d dokumentumban rendeljük az alábbi súlyt Növekszik a dokumentumon belüli előfordulásokkal Növekszik a korpuszon belüli ritkasággal Mi annak a szónak a súlya, amely minden doksiban szerepel

12
Valós értékű szó-dokumentum mátrix
A szóelőfordulások függvénye: szózsákmodell Minden dokumentumok egy valós reprezentál ℝv -ben Logaritmikusan skálázott tf.idf Nagyobb lehet 1-nél!

13
Szózsákmodell-reprezentációról
Nem tesz különbséget a Nitzsche mondta: Isten halott és az Isten mondta: Nitzsche halott mondatok között. Gondot jelent ez nekünk?

14
Vektortér modell

16
Dokumentumvektorok Minden dokumentumot egy vektornak tekintünk wfidf értékek alapján, ahol az elemek a szavakhoz tartoznak Van tehát egy vektorterünk Ennek a tengelyei a szavak/terminusok Dokumentumok a vektortér pontjai Még szótövezéssel is bőven 20,000-nél nagyobb lesz a vektortér dimenziója (Ha a mátrixot a másik irányból nézzük, akkor a dokumentumok lehetnek a tengelyek, és a szavak vannak a vektortér elemei)
")
17
Dokumentumvektorok (2)
Minden q keresőkifejezés is a vektortér vektoraként fogható fel (általában nagyon ritka) Az illeszkedést a vektorok közelsége alapján határozzuk meg Ezután minden dokumentumhoz hozzárendelhető egy relevanciaérték a q keresőkifejezés esetén
 Az illeszkedést a vektorok közelsége alapján határozzuk meg. Ezután minden dokumentumhoz hozzárendelhető egy relevanciaérték a q keresőkifejezés esetén.")
18
Miért jó, ha dokumentumvektoraink vannak?
Egy lehetséges alkalmazás: mintadokumentum alapján keresünk Adott egy D dokumentum, keresünk hasonlókat (pl. plágiumkeresés) Ekkor tehát D egy vektor, és hasonló (közeli) vektorokat keresünk
 Ekkor tehát D egy vektor, és hasonló (közeli) vektorokat keresünk.")
19
És a hipotézis ami mögötte van
d2 d3 d1 θ φ t1 d5 t2 d4 Hipotézis: azok a dokumentumok, amelyek a vektortérben vannak egymáshoz hasonló témájúak

20
A vektortérmodell A keresőkifejezés egy vektor
Rövid dokumentumnak tekintjük Azok a dokumentumok lesznek találatok, amelyek – vektorként – közel helyezkednek el a keresőkifejezéshez Első alkalmazása a Salton féle SMART rendszerben - Salton's Magical Automatic Retriever of Text (1970)
")
21
Objektumok hasonlósága
A szövegfeldolgozás során szükség lehet a leíró elemek hasonlóságának mérésére Tipikus műveletek: a mintához hasonlító dokumentumok keresése a dokumentumok rangsorolása dokumentumok csoportosítása dokumentumok osztályozása hasonlóság alapú szó keresés dokumentumok tisztítása A hasonlóság mérése távolság alapon történi Euklédeszi távolság az euklédeszi térben:

22
Közelség fogalmának követelményei
Ha d1 közel van d2-höz, akkor d2 közel legyend1-hez (szimmetria). Ha d1 közeli d2-höz, és d2 közeli d3-hoz, akkor d1 ne legyen messze d3-tól (kvázi háromszög-egyenlőtlenség) Nincs olyan dokumentum, amely közelebb lenne d-hez mint önmaga (reflexív).
. Ha d1 közeli d2-höz, és d2 közeli d3-hoz, akkor d1 ne legyen messze d3-tól (kvázi háromszög-egyenlőtlenség) Nincs olyan dokumentum, amely közelebb lenne d-hez mint önmaga (reflexív).")
23
Első megközelítés A d1 és d2 vektorok távolsága legyen a különségük hossza|d1 – d2|. Euklideszi-távolság Mi a baj ezzel? Nem foglalkoztunk még a hossz-normalizálással Hosszú dokumentumok a hosszuk miatt hasonlóbbak lesznek egymáshoz témától függetlenül Könnyen elvégezhetjük a hossznormalizálást, ha a vektorok által bezárt szöget tekintjük

24
Koszinuszhasonlóság Két vektor, d1 és d2 hasonlóságát a köztük lévő szög koszinusza adja meg. Megjegyzés – ez nem távolság, hanem hasonlóság, mivel a háromszög-egyenlőtlenség nem teljesül rá t 1 d 2 d 1 t 3 t 2 θ

25
Koszinuszhasonlóság (2)
A vektorok által bezárt szög koszinusza A nevező tartalmazza a hossznormalizálást.

26
Koszinuszhasonlóság (3)
A dokumentumvektor hosszát az alábbiak szerint definiáljuk Egy vektor úgy normalizálható normalized (a hossza 1), ha minden elemét elosztjuk a hosszával – itt L2 normát használunk Ez a vektorokat az egységgömbre képezi le: Azaz, Hosszabb dokumentumoknak nem lesz nagyobb súlya
, ha minden elemét elosztjuk a hosszával – itt L2 normát használunk. Ez a vektorokat az egységgömbre képezi le: Azaz, Hosszabb dokumentumoknak nem lesz nagyobb súlya.")
27
Normalizált vektorok Normalizált vektorok esetében a koszinuszhasonloság a skalárszorzattal egyezik meg.

28
dimenzió redukció

29
Dokumentum reprezentáció redukálása
A nagy méret, összetettség több problémát is okoz Cél: a dokumentumok feldolgozási költéségnek csökkentése, a feldolgozás minőségének javítása Megoldás: az elhagyható elemek redukálása. A elem elhagyható, ha nem független másoktól nem diszkriminatív (nem releváns a probléma szempontjából)
")
30
Redukciós eljárások statisztikai eljárások a vektormodellre
PCA SVD relevancia alapú, discrimination analysis TFIDF tartomány stop words domain specifikus szűrés szótár alapú szűrés nyelv alapú szűrés szótövezés szinonímák használata

31
PCA módszer A módszer lényege, hogy báziscserével az objektumokat egy alacsonyabb dimenziószámú vektortérbe viszi át Cél a minimális információ veszteség biztosítása A lényegesnek tekintett információ klaszterezéshez, osztályozáshoz: az objektumok egymás közötti távolság viszonyai Olyan új koordinátatengelyek kellenek, ahol a nagy az objektumok távolság értékeinek szórása nem csak dimenzió elhagyás történik, hanem új dimenzió tengely kijelölés

32
Vektortérmodell Egy {v1,v2,...,vn} vektorrendszer függő, ha valamely eleme lineráisan kombinálható a többi elemtől Vektorér bázisa: azon független {v1,v2,...,vn} , melyből a tér összes eleme lineárisan kombinálható A tér minden bázisa azonos dimenziójú Vektortér dimenziója: a bázisainak dimenziószáma Vektor koordinátái egy adott bázis esetén: a bázisra vonatkozó lineáris kombinációban szereplő együtthatók

33
Lineáris leképzés Ha V1, V2 két vektortér, akkor a
Φ:V1 →V2 lineáris leképezés, ha teljesül. Ha {v1,..,vn} a V1 bázisa, {u1,..,um} a V2 bázisa, akkor a lineáris transzformáció egy mátrixszal adható meg.

34
PCA fő komponens elemzés
PCA matematikai hátterének több ekvivalens megközelítése van, a legegyszerűbbek: azon tengelyt keressük, ahol a vetületek szórása a legnagyobb azon tengelyt keressük, amelytől mért távolságok összege minimális

35
A PCA módszer Dokumentum leíró mátrix
az igényelt új bázis egy tengelyének egység irányvektora: w a választás célfüggvénye: a vetületek varianciája (négyzetösszege) maximális legyen
 maximális legyen.")
36
Folytatás: ora_07.pdf


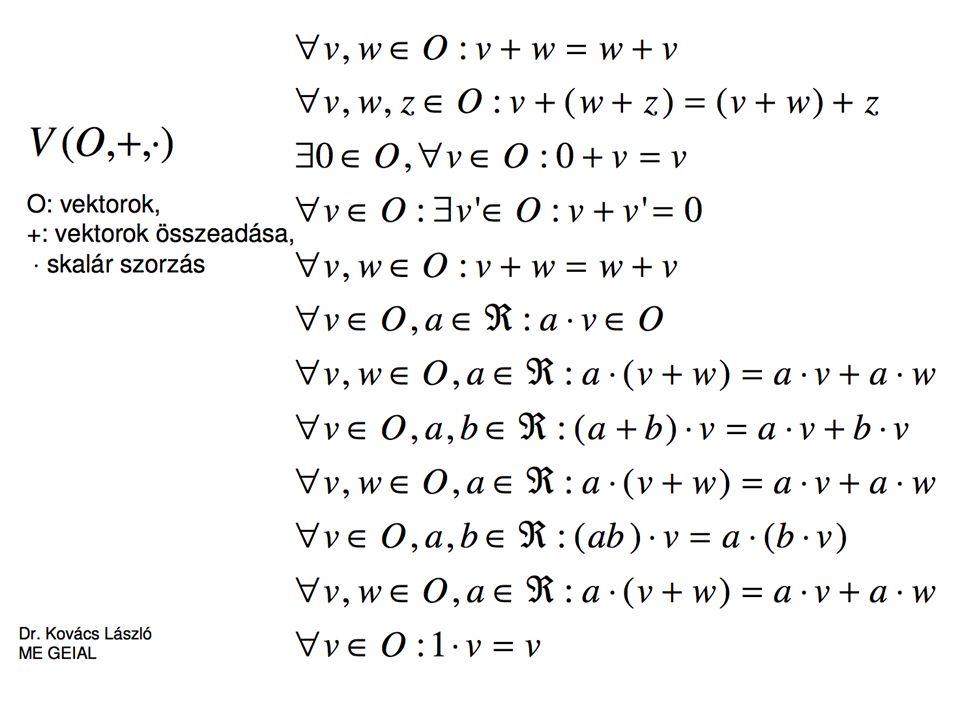








 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")










