Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
a CPU gyorsítása, pipeline, cache

2
Processzor gyorsítási lehetőségek
Pipeline feldolgozás Cache gyorsító tár CISC vs. RISC... Bitszelet processzorok Co-processzorok Pédák processzorokra...

3
Órajelfrekvencia, idő, távolság
1 „normál” kapu kapcsolási idő ≈ 10ns 1200 MHz-es órajel => 1/(1200*10e6) s (két órajel közötti idő) ≈ 0.8ns „fénysebesség” ≈ km/s (300000*10e3 m/s) * (1/(1200*10e6s)) => ≈ 0.25m (utat tesz meg a fény két órajel között!)
 s (két órajel közötti idő) ≈ 0.8ns. „fénysebesség ≈ km/s. (300000*10e3 m/s) * (1/(1200*10e6s)) => ≈ 0.25m (utat tesz meg a fény két órajel között!)")
4
Processzor gyorsítási lehetőségek
művelet végzés gyorsítása ? utasítás végrehajtás gyorsítása ? párhuzamosítás !

5
Műveletvégzés gyorsítása
Összeadás átvitel-előrelátás (addition carry-lookahead)
")
6
Teljes összeadó „késleltetése” (ripple carry)
y3 x3 y2 x2 y1 x1 y0 x0 c0 c3 c2 c1 1+ 1+ 1+ 1+ c4 s3 s2 s1 s0 késleltetés (3dt) 1 dt = 1 kapu kapcsolási idő (kb. 10ns)
 1 dt = 1 kapu. kapcsolási idő (kb. 10ns)")
7
Gyorsított összeadás Ci+1= (Xi AND Yi) OR (Xi AND Ci) OR (Yi AND Ci)
Ci+1=(Xi * Yi) + (Xi * Ci) + (Yi * Ci) Ci+1=(Xi * Yi) + ((Xi + Yi ) * Ci) Gi = generate = Xi *Yi Pi = propagate =Xi + Yi Ci+1=Gi+Pi*Ci 16 bites összeadónál... 1 kapu késleltetése = dt (kb. 10ns) 15x2dt+3dt = 33dt = kb. 330ns -> túl sok 10ns=100MHz km/s 0.3*10e9m/s 1ns=10e-9s -> .3m/ns
 + (Xi * Ci) + (Yi * Ci) Ci+1=(Xi * Yi) + ((Xi + Yi ) * Ci) Gi = generate = Xi *Yi. Pi = propagate =Xi + Yi. Ci+1=Gi+Pi*Ci. 16 bites összeadónál... 1 kapu késleltetése = dt (kb. 10ns) 15x2dt+3dt = 33dt = kb. 330ns -> túl sok. 10ns=100MHz km/s. 0.3*10e9m/s. 1ns=10e-9s. -> .3m/ns.")
8
4bites átvitel-előrelátás („carry lookahead”)
Ci+1=Gi+Pi*Ci C1=G0+P0*C0 C2=G1+P1*C1 =G1+P1*G0+P1*P0*C0 C3=G2+P2*C2 =G2+P2*G1+P2*P1*G0+P2*P1*P0*C0 C4=G3+P3*C3 =G3+P3*G2+P3*P2*G1+P3*P2*P1*G0+P3*P2*P1*P0*C0 C1 behelyettesítve [Modern comp. pp 67] shiftelő áramkör C4 független C1..C3-tól, csak X1..4 , Y1..4 és C0-tól függ

9
Szorzás ROM-ból kiolvasással
X Y Z 0* 0* 0* 0* 1* 1* 1* 2* 2* 2* 2* 3* 3* 3* 3* X MEM 16x 4bit Y Z 2x 2 bites szorzó : 2e4x 4bit = 16x 4bit (8byte) 2x 8 bites szorzó : 2e16x 16bit = 64x 16bit = 128Kbyte 2x 16 bites szorzó : 2e32x 32bit =32x 4Mbit =16Mbyte 2x 32 bites szorzó : 2e64x 64bit =nagyon sok (tényleg) gyors, egyszerű, olcsó tetszőleges függvényre csak kisméretben alkalmazható
 2x 8 bites szorzó : 2e16x 16bit = 64x 16bit = 128Kbyte. 2x 16 bites szorzó : 2e32x 32bit =32x 4Mbit =16Mbyte. 2x 32 bites szorzó : 2e64x 64bit =nagyon sok (tényleg) gyors, egyszerű, olcsó. tetszőleges függvényre. csak kisméretben alkalmazható.")
10
(csővezeték, futószalag feldolgozás)
Pipeline feldolgozás (csővezeték, futószalag feldolgozás)
")
11
„Pipelining” részfázisokra bontás
független részfázisok, önálló erőforrásokkal az egyik fázis eredménye a következő induló adata

12
Utasítások egymás utáni végrehajtása
1. utasítás feldolgozása előkészítés dekodolás végrehajtás tárolás 1. utasítás feldolgozása 2. utasítás feldolgozása 3. utasítás feldolgozása idő

13
Utasítás végrehajtás fokozatokra bontása
előkészítés dekódolás végrehajtás tárolás 1. utasítás feldolgozása 2. utasítás feldolgozása tárolás végrehajtás dekódolás előkészítés 1 2 1 2 1 2 idő 1 2

14
Csővezetékszerű utasítás végrehajtás (pipelined)
feldolgozása 2. utasítás feldolgozása 1. utasítás feldolgozása tárolás végrehajtás dekódolás előkészítés 1 utasítás végrehajtási ideje nem változik utasítások végrehajtásának a frekvenciája n (ahol n a fokozatok száma) szeresére nő 1 2 3 4 5 1 2 3 4 5 ... 1 2 3 4 5 6 ... idő ... 1 2 3 4 5 6 7
 szeresére nő idő")
15
Csővezetékszerű utasítás végrehajtás
? nem egyenlő hosszú fokozatok nem egyenlő hosszú fokozatok tárolás végrehajtás dekódolás előkészítés 1 utasítás végrehajtási ideje nem változik utasítások végrehajtásának a frekvenciája n (ahol n a fokozatok száma) szeresére nő 1 2 3 4 1 2 3 4 1 2 3 4 idő 1 2 3 4 5 6 7 8 9
 szeresére nő idő")
16
Problémák a pipeline-vel
tárolóhivatkozás : lassú memória miatt várni kell az operandusokra egyszerre kéne ugyanabból a tárból adatot és utasítást elérni vezérlés átadó utasítások... megszakítások... [Cserny pp 135-] folyamatos pipeline feldolgozás megszakítása, felfüggesztése

17
Memória utasítások a pipeline-ben
„Várakoztató utasítások” beiktatása - „lyukak” a pipeline-ben késleltetett memória utasítás - utasítások átrendezése, üres utasítás beiktatása load R1, (A) load R2, (B) add R1,R2,R3
 load R2, (B) add R1,R2,R3.")
18
Elágazások kezelése a pipeline-ben
az ugrási cím csak az utasítás feldolgozása után lesz ismert... ha „rossz” ágat utasításait kezdi el feldolgozni akkor a pipeline-t (és az utasítások hatásait) törölni kell... delayed branch (NOP utasítással feltöltés)
 törölni kell... delayed branch (NOP utasítással feltöltés)")
19
Adatok felhasználása a pipeline-ben
ütközések : írás utáni írás : 2. írás után ír az 1. írás utáni olvasás : 2. előbb olvas mint az 1. ír olvasás utáni írás : 2. előbb ír mint az 1. olvas olvasás utáni olvasás :-) adat függőség add (M1),R2,R3 sub R3,R0,R3 add R1,R2,R3 sub R3,R0,R4 add (M1),R2,R3 sub R2,R0,R2 instruction scheduling... internal forewarding... scoreboarding...
 adat függőség. add (M1),R2,R3. sub R3,R0,R3. add R1,R2,R3. sub R3,R0,R4. add (M1),R2,R3. sub R2,R0,R2. instruction scheduling... internal forewarding... scoreboarding...")
20
Pipeline összefoglalás
egyszerű elv bonyolult, „trükkös” megvalósítás sokat segíthet a fordítóprogram

21
Cache „gyorsító” tár

22
Cache memória Probléma : a központi memória általában sokkal lassabb (5x-10x-...) mint a processzor... Kicsi, gyors (drága!), puffer memória a központi memória és a processzor közé... Központi memória CDC STAR 100 : processzor 40ns , memória 1280 ns (32x) Első megvalósítás IBM 360/85 Motorola MC68020, Intel processzor on-board cache Cache memória CPU
, puffer memória a központi memória és a processzor közé... Központi. memória. CDC STAR 100 : processzor 40ns , memória 1280 ns (32x) Első megvalósítás IBM 360/85. Motorola MC68020, Intel processzor on-board cache. Cache. memória. CPU.")
23
„Tipikus” cache 64 Mbyte memóriához 64 Kbyte cache 20x gyorsabb
1/1000 méret 98% cache találat

24
Cache működés (olvasás)
CPU által generált memóriacím küldése a cache-nek : 1. ha az adat a cache-ben van (cache hit, cache találat) : adat elküldése a CPU-nak 2. ha az adat nincs a cache-ben (cache miss, cache „nemtalálat”, „találat hiba”) : a generált memóriacím küldése közp. memóriának adat kiolvasása a központi memóriából, adat elküldése a CPU-nak, és a cache-be
 : adat elküldése a CPU-nak. 2. ha az adat nincs a cache-ben (cache miss, cache „nemtalálat , „találat hiba ) : a generált memóriacím küldése közp. memóriának. adat kiolvasása a központi memóriából, adat elküldése a CPU-nak, és a cache-be.")
25
Cache a memória és a cache között blokkos adatátvitel (4-64 szó) => programok lokalitása teli cache esetén egy cache blokkot fel kell szabadítani (helyettesítési eljárások)
")
26
Cache hatása az átlagos elérési időre és a hatékonyságra (példa)
Adatok : cache elérési idő tc = 160ns memória elérési idő tm = 960ns átlagos cache találati arány h = 90% Kérdés : mennyi az átlagos elérési idő ? (ta) mekkora a hatékonyság növekedés ? (g)
 mekkora a hatékonyság növekedés (g)")
27
Cache hatása az átlagos elérési időre és a hatékonyságra (példa)
ta = h*tc + (1-h)*(tc+tm) = 0.9* *( ) = 256 ns (átlagos elérési idő) r = tm/tc = 960/160 = 6 g = 1/(1+r*(1-h)) =1/(1+6*0.1) = 0.625 = 62.5% (hatékonyság növekedés)
*(tc+tm) = 0.9* *( ) = 256 ns (átlagos elérési idő) r = tm/tc = 960/160 = 6. g = 1/(1+r*(1-h)) =1/(1+6*0.1) = = 62.5% (hatékonyság növekedés)")
28
Cache hatása (SuperSPARC példa)
CPU 0.75 CPI (cycles per instruction) 3% cache miss memória késleltetés 10 ciklus 1.33 memória referencia / utasítás cache miss „büntetés” 0.4 CPI ,75*1,33*3%*10 35% teljesítmény csökkenés /(1+3%*(10+1))
 3% cache miss. memória késleltetés 10 ciklus memória referencia / utasítás. cache miss „büntetés 0.4 CPI 0,75*1,33*3%*10. 35% teljesítmény csökkenés 1-1/(1+3%*(10+1))")
29
Memória „leképzése” a cache-ra
Teljesen asszociatív cache Közvetlen leképzésű cache Csoport asszociatív cache

30
Teljesen asszociatív cache (fully associative cache)
központi memória blokk „i” (0<=i<=M-1) leképezhető bármelyik „j” (0<=j<=N-1) cache blokkra memória M=2m N=2n tag érték N darab m bites összehasonlítás (hasonlító) !!! idő... j „i” x i ... x N-1 m M-1 k blokkméret : k
 leképezhető bármelyik „j (0<=j<=N-1) cache blokkra. memória. M=2m. N=2n. tag. érték. N darab m bites összehasonlítás (hasonlító) !!! idő... j. „i x. i. ... x. N-1. m. M-1. k. blokkméret : k.")
31
Közvetlen leképzésű cache (direct mapping cache)
egy-egy memória blokk csak meghatározott helyre kerülhet (I-way set associative cache) memória i MOD N i DIV N x i x N-1 M-1 m-n k k
 memória. i MOD N. i DIV N. x. i. x. N-1. M-1. m-n. k. k.")
32
Közvetlen leképzésű cache (direct mapping cache)
Pld. 10-es számrendszer, M=1000, N=10 memória i=785 i MOD N i DIV N 785. x i 5. 78 x N-1 M-1 k m-n k

33
Közvetlen leképzésű cache (direct mapping cache)
Pld. 2-es számrendszer, M=1024=210, N=8=23 memória i= i MOD N i DIV N x i 011 x N-1 M-1 k m-n k

34
Közvetlen leképzésű cache címformátuma
memória blokk cím M=2m m bit m-n bit n-bit N=2n „tag” cache blokk cím

35
Közvetlen leképzésű cache
a memória cím „alsó” n bitje a memória cím „felső” m-n bitje memória „tag” közvetlenül megvan a cache cím csak 1 összehasonlítás kell N nagyságú ugrásoknál nem teli cache-nél is kiüti... i MOD N. i DIV N i N-1 M-1 m-n k k

36
Csoport asszociatív cache (set associative cache)
S csoport blokkonként S=2s a memória cím „alsó” n-s bitje a memória cím „felső” m-n+s bitje memória blokk csoport „tag” cache csoport cím j ... N/S-1 M-1 N-1 m-n+s k k

37
Cache-ben lévő adat megváltoztatása
cache - memória koherencia fenntartása ! azonnali átírás (write-through) : blokk tartalom módosítás esetén a blokk visszaírása a memóriába visszamásolási eljárás (write back) : a frissen betöltött blokk „dirty” („piszkos”) bitje = 0 blokk tartalom módosítás esetén dirty bit = 1 blokk cache-ból törlésekor : ha dirty bit = 1 akkor vissza kell írni a memóriába (különben nem)
 : blokk tartalom módosítás esetén. a blokk visszaírása a memóriába. visszamásolási eljárás (write back) : a frissen betöltött blokk „dirty („piszkos ) bitje = 0. blokk tartalom módosítás esetén dirty bit = 1. blokk cache-ból törlésekor : ha dirty bit = 1 akkor vissza kell írni a memóriába. (különben nem)")
38
CISC vs. RISC processzorok
CISC = Complet Instruction Set Computer (teljes utasítás készletű számítógép) RISC = Reduced Instruction Set Computer (csökkentett utasítás készletű számítógép)
 RISC = Reduced Instruction Set Computer. (csökkentett utasítás készletű számítógép)")
39
CISC vs. RISC processzorok
„könnyebb programozás” összetett utasítások, sokféle címzési mód utasítás végrehajtás több órajel alatt mikroprogramozott ... RISC egyszerűbb, gyorsabb optimalizált fordítók kevés utasítás és címzési mód rögzített utasítás forma utasítás végrehajtás 1 órajel alatt kevés memória hozzáférés sok regiszter huzalozott vezérlő pipeline feldolgozás [Modern comp. pp 51-] RISC füzet...

40
CISC vs. RISC CISC (VAX) 14 féle címzési mód 250 utasítás RISC
32 (50) regiszter... 30-40 utasítás
 regiszter utasítás.")
41
Bit-szelet processzorok
Bit-szelet (bit slice) processzor példa : AM 2901 4 bites ALU + regisztertömb 3 aritmetikai, 5 logikai művelet 9 bites vezérlés állapot jelek [Modern comp. arc. pp 89-94]
 processzor. példa : AM bites ALU + regisztertömb. 3 aritmetikai, 5 logikai művelet. 9 bites vezérlés. állapot jelek. [Modern comp. arc. pp 89-94]")
42
Segédprocesszorok co-processzorok
gyorsabb lebegőpontos, mátrix, grafikai műveletek új utasítások, adattípusok, regiszterek együttműködés a processzorral

43
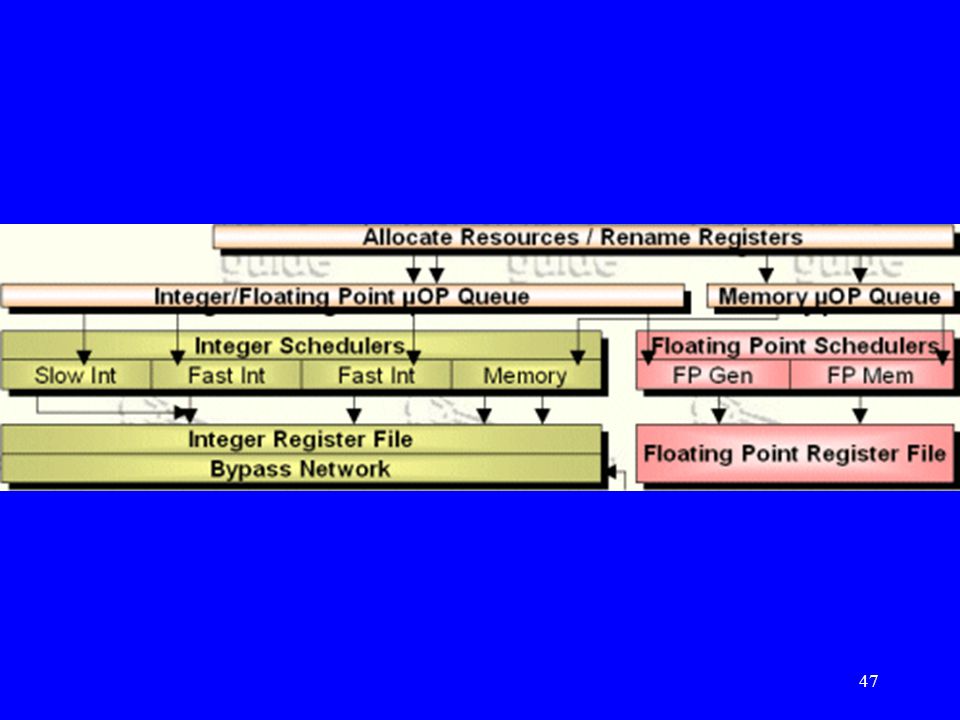
Végrehajtó egységek (Execution Units)
")
44
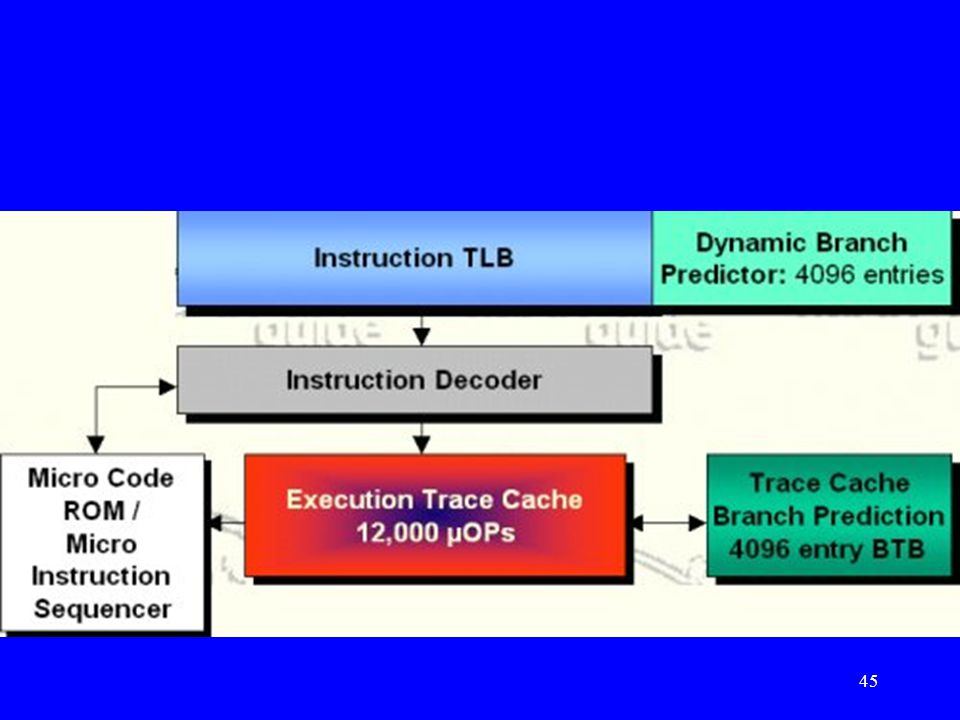
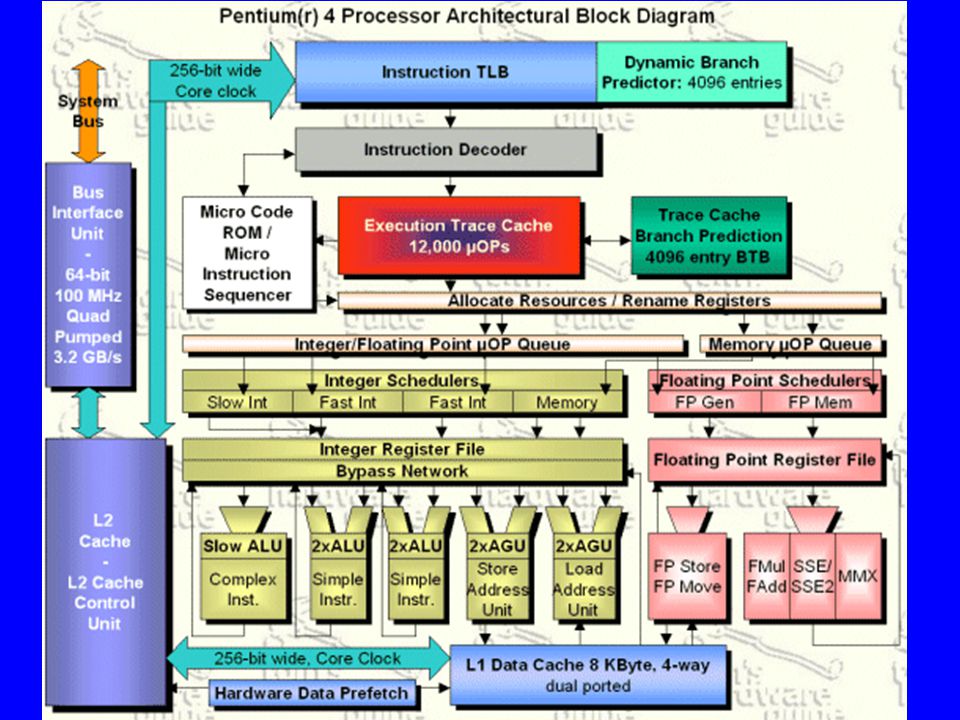
Pentium 4 Processzor adat-útvonalak (Data Stream of Pentium 4 Processor)
")
48
Intel Pentium XEON

49
MIPS R16000

50
Sorrendet nem megtartó végrehajtó egység csővezeték (Out-of-order execution engine detailed pipeline)
")
Hasonló előadás










>")








