Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Az SNP adatbázisok Adrienne Kitts és Stephen Sherry nyomán készítette: Priskin Katalin és Szécsényi Anita

2
Nukleotidpolimorfizmusok a genom meghatározott pontjain fordulnak elő. Hozzájárulnak az egyedi fenotipikus jellegek kialakításához. Ezeknek a mindenki által elérhető gyűjteménye a dbSNP, amely tartalmaz egy bázist érintő cseréket, kisméretű inszerciókat és deléciókat (DIP), valamint STR szekvenciákat.
, valamint STR szekvenciákat..")
3
A dbSNP… … elérési címe: www.ncbi.nlm.nih.gov/SNP. …olyan biológiai problémák megoldására hozták létre, mint a fizikai térképezés, funkcionális analízis, farmakogenomika, asszociációs- és evolúciós kutatások. ….Genbank részeként fejlesztették ki, így számos organizmusról tartalmaz szekvencia információkat, jelenleg főként humán és egér szekvenciákat.

5
Fizikai térképezés: Polimorfizmusok pozicionális markerként szerepelnek, hasonlóan az STS és mikroszatelit markerekhez. Funkcionális analízis: A gének funkcionálisan fontos vagy nemkodoló régióiban található SNP-k jelentős változásokat indukálhatnak a komplementer szekvenciák transzkriptumaiban, ami a fehérjeexpresszió és ezen keresztül fenotipikus változásokhoz vezethet. Az adatbázisban a variációk lehetséges következményeire nézve is találunk információkat, pl. hogyan változik meg az mRNS transzkriptum. Asszociációs kutatások: A polimorfizmusok, és a komplex genetikai jellegek közti összefüggés nem olyan egyértelmű, mint az egyszerű génmutációk. Evolúciós kutatások: Az adatbázisban található SNP-k jelenleg nagy genomdiverzitást mutatnak. Pl. a humán adatok az SNP Konzorciumtól, a HUGO során detektált variációkból, közleményekből származnak. NoVariation Record: Az átfogó vizsgálatok során sikerült kimutatni nem variábilis szekvenciákat. Ezek ‘No Variation record’ névvel kerülnek be az adatbázisba. A beadott adat tartalmazza a szekvenciát, a vizsgált populációt, és a mintaszámot.

6
KERESÉS AZ ADATBÁZISBAN

8
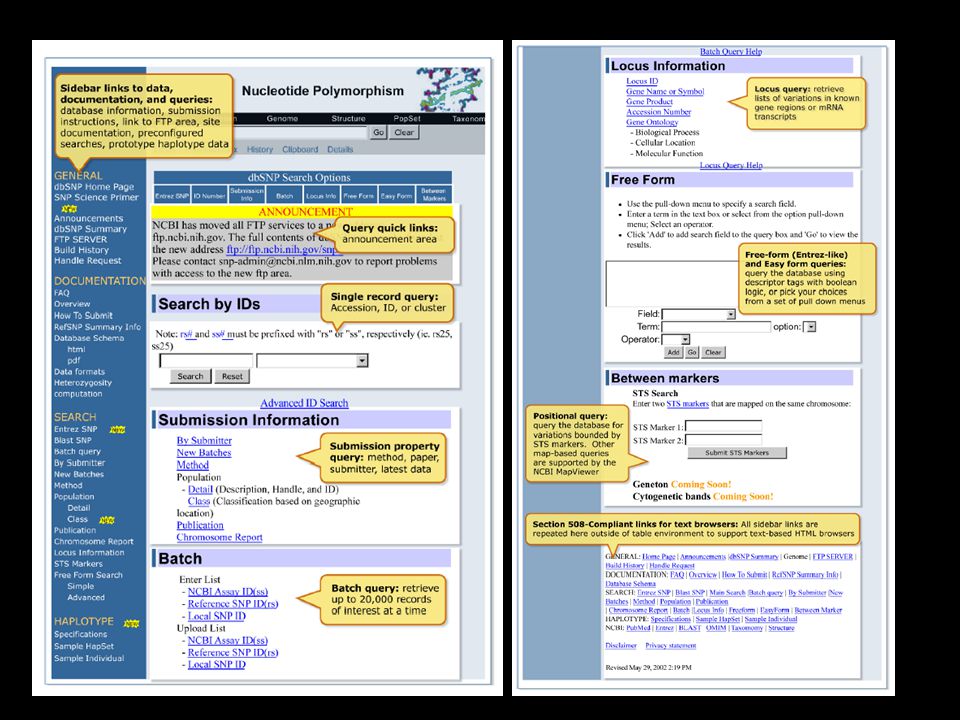
ENTREZ SNP : A dbSNP az ENTREZ kereső rendszer része, számos különböző szempont szerint végezhető keresés 28 különböző mezőben.

9
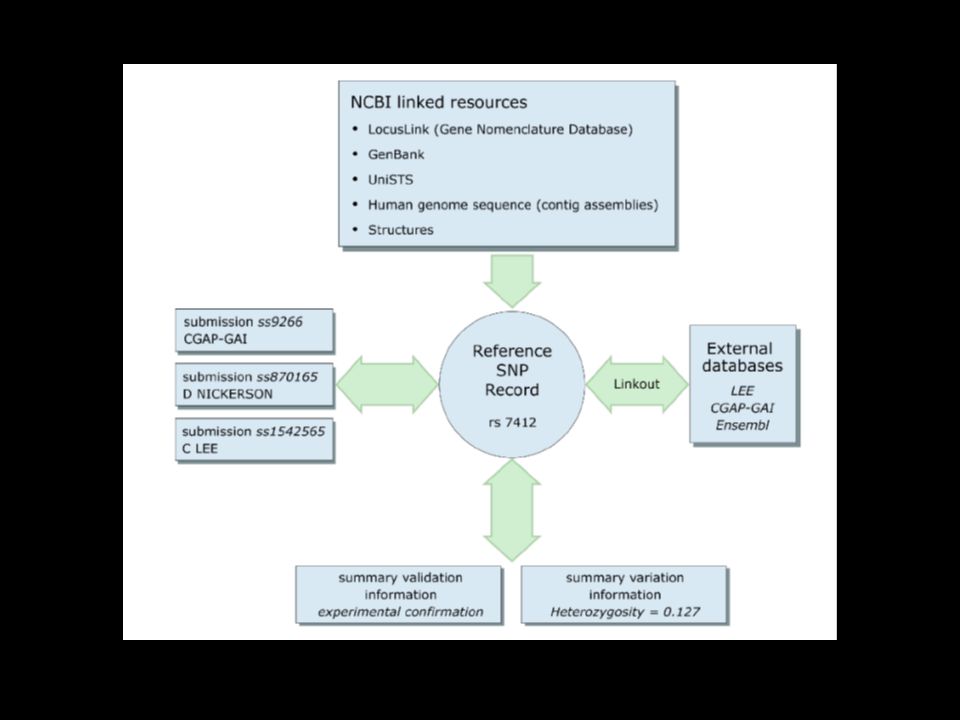
Keresés azonosító szám alapján: Minden SNP rendelkezik a refSNP klaszter azonosítójával (rsID), a beadott SNP elérési számával (ssID), és egy helyi azonosítóval. Keresés a beadott adatok alapján: E bben a módban kereshetünk a beadó labor, a detektálás módszerei, a vizsgált populáció földrajzi elhelyezkedése, vagy publikáció alapján. Keresés lókusz információk alapján: Az NCBILocusLink tartalmát használja fel. Lehetőség van a gén neve, jele, valamint a géntermék ill. az elérési száma alapján is keresni. Batch Query

10
„Free form” keresés: A keresés összetett keresési mezőben történik. Itt bármilyen adat megadható, a rendszer válogatja szét részhalmazokra. „Easy form” keresés: Annyiban különbözik az előzőtől, hogy itt a legördülő menükből választhatók ki legnépszerűbb keresési mezők. Markerek közti, pozícionális keresés: Két ismert pozíciójú STS marker közti szakaszon lévő SNP-ket kereshetjük.

11
A beadott adatok ( submitted content)
")
12
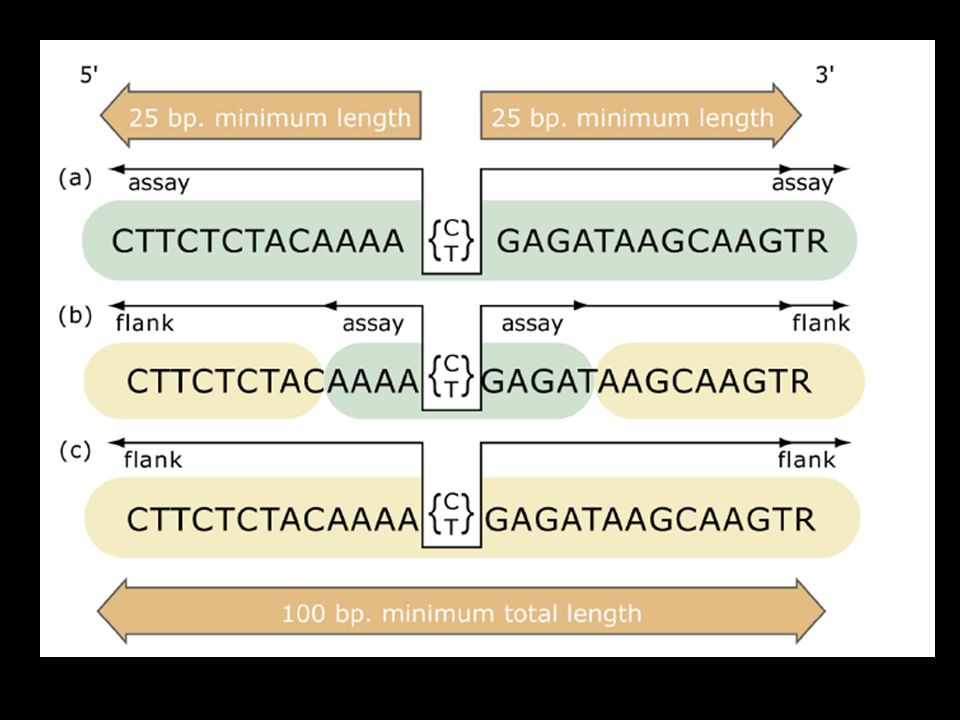
A dbSNP két fő osztályból áll: 1.: A benyújtott adat, azaz az eredeti SNP 2.: A „build cycle” során létrehozott adat A beadott SNP-k a következő 10 adatelemet kell, hogy tartalmazzák: 1.: A flanking szekvencia: DNS v. cDNS, de a beadott szekvencia el kell érjen egy minimális hosszt (minimum- hossz feltétel). 2.: Allélek: Variációs osztályokat jelölnek,melyek mindegyike egy kóddal rendelkezik( pl. A/T szubsztitúció: 1 ). A beadványoknak határozott sémája van, melyben a IUPAC kódok használata nem megengedett, kivéve akkor, ha az SNP közvetlen közelében egy másik is előfordul.
. 2.: Allélek: Variációs osztályokat jelölnek,melyek mindegyike egy kóddal rendelkezik( pl. A/T szubsztitúció: 1 ). A beadványoknak határozott sémája van, melyben a IUPAC kódok használata nem megengedett, kivéve akkor, ha az SNP közvetlen közelében egy másik is előfordul..")
13
3.: Módszer: A beadó ismerteti a detektálási módszert, vagy azt a technikát, amivel megbecsülték az allélgyakoriságot, mely szintén egy-egy kódnak felel meg. 4.: Populáció : A beadó megjelöli azt a populációt, amelyből a vizsgálati egyedeket kiválasztotta. 5.: Minta nagyság: Erre vonatkozóan 2 mező áll rendelkezésre: „SNPASSAY sample size”:az SNP keresése során megvizsgált kromoszómák száma, „SNPPOPUSE sample size”: az a kromoszómaszám, mely nevezőként szolgál az allélgyakoriság kiszámítása során. 6.: Populációspecifikus allélgyakoriság: Az allélgyakoriság a különböző populációkban nagymértékben különbözhet. Az allélgyakoriságot intervallumban adják meg, mert a kül. mérési technikák alkalmazásával kül. adatot kaphatunk.

14
7.: Populáció-specifikus genotípus gyakoriság: Hasonlóan az allélgyakorisághoz, azt is meg lehet adni az dbSNP-ben. 8.: Populáció-specifikus heterozigozitás becslése: Bizonyos módszerek, mint pl. a DHPLC alkalmasak arra, hogy egy DNS fragmentumban detektálhassuk az SNP létezését, anélkül, hogy a konkrét szekvencia információt megfejthessük. 9.: Egyedi genotípusok 10.: Validációs infó: Amikor lehet, megkülönböztetik a magasan validált adatokat a megerősítetlenektől.

15
A dbSNP build cycle

16
Az eddigi kategóriák alapján jellemzett beadvány a ciklus során beépül az adatbázisba, betérképeződik az adott genom megfelelő pozíciójába, klaszterbe sorolják. A ciklusnak 12 lépése van.

17
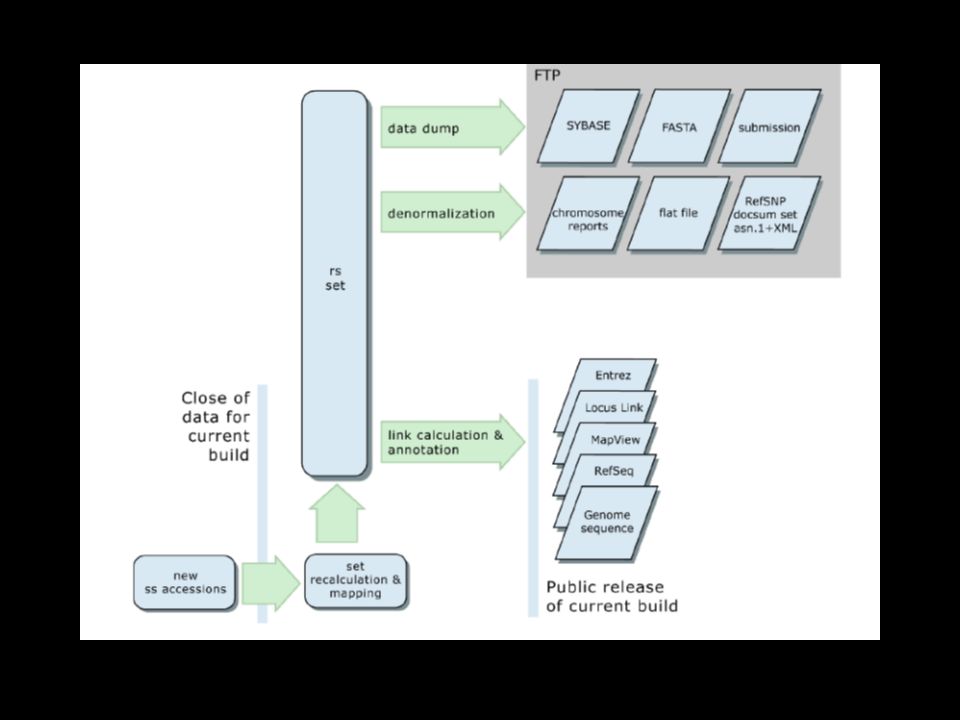
1. Újonnan beadott adatok térképezése és újracsoportosítás: Az új beadványokat egy adatcsomag definiálja, amely alapján a MEGABLAST seg.vel betérképezhető a genomba, hogy elvégezhető legyen a reclustering és az annotáció. 2. refSNP cluster set: Itt annotáltak a nem –redundáns variánsokat a ref.genom seq.kontigokban, chromosomákon, mRNAkon, proteineken. Ez után kiszámolják az összegzett jellegeit mindegyik refSNP clusternek, és ezt használják arra hogy frissítsék a dbSNPt az entrezben, és a variációs térképet az NCBI MAp Viewerben. Végül frissitik a linkeket az egyes adatbázisok közt( dbSNP-dbMHC, UniSTS, Locuslink, Pubmed, Unigene.

18
3. Publikussá tétel : Egy új elem publikussá tétele során frissítik az eddigi közös adatbázissal, valamint egy új file-sorozatot hoznak létre az FTP serveren. Majd jelentést küldenek a dbSNP levelező listára, ha egy egy új elem nyilvánosan elérhetővé válik. 4. refSNP Clusterek besorolása Non-Redundáns adatszettekbe: az adatokat, melyeket beküldtek az adatbázisba, rendszerezik clusterekbe, és Ezeket a clustereket fenntartják, mint refclustereket a bdSNPben párhuzamosan a mögötte lévő adatokkal.A ref SNPket a vizsgált SNPktől úgy különítik el, hogy a ref.nek az asccession n.je rsACC, szemben az ss(submitted SNP)Egy refSNP adott számú tulajdonsággal rendelkezik, amelyek a kluszter összes tagjánál egyaránt meg vannak határozva. A ref SNP setet exportálhatjuk több repport fomátumba is az FTP serveren.Mind a refSNPt, és a beadottat megtartják, mint FASTA adatbázis BLAST keresshez 5. Adatok Összegzett mérése: Kiszámolják az összegzett értékeket minden refSNPre, hogy integrálhassák a független beküldők adatait.
Egy refSNP adott számú tulajdonsággal rendelkezik, amelyek a kluszter összes tagjánál egyaránt meg vannak határozva. A ref SNP setet exportálhatjuk több repport fomátumba is az FTP serveren.Mind a refSNPt, és a beadottat megtartják, mint FASTA adatbázis BLAST keresshez 5. Adatok Összegzett mérése: Kiszámolják az összegzett értékeket minden refSNPre, hogy integrálhassák a független beküldők adatait..")
19
6. The ref SNP clusterező eljárás : A beküldők tetszőlegesen definiálhatják a variációkat bármelyik DNS szálon. Ezért a a refSNP clusterben a beadvány lehet, hogy a forward, lehet, h a reverse szálon jelölt. Így a refSNP orientációja és ennél fogva a szekvenciája a cluster példa alapján van beállítva. Konvenció alapján a clusterezési folyamat vesz egy mintát a clusterből, ami a cluster azon tagja, amelyik a leghosszabb. Az azutáni buildekben, ez a szek. Lehet, hogy reverz poz.ban lesz az érvényben lévő refszek.hez képest. Ilyenkor igyekeznek megőrizni a refszek. rientációját. 7. A variációk összegzett értéke A variációk diverzitását a kül. Populációk közt legjobban az átlagos heterozigozitással lehet jellemezni. Ez az érték annak az ált.valószinűségét adja meg, hogy mindkét allél megtalálható egy diploid regyedben, v két kromoszómán. Az átlasgos heterozigozitás becslésének van egy mindig jelen lévő hibája, amely a minta nagyságból fakad

20
8. Referencia genom szekvenciához térképezés: Amikor egy ref genom összeszerelésre kerül, és elérhetővé válik, a bd ezt használja mint rögzített szekvenciát, és a refClustereket beillesztik a genomba. RepeatMasker seg.vel eltáv. a flankingeket, majd a MegaBLAST segítségével újratérképezik az adott genom legutóbbi változatába. 9. Újracsoportosítás: előfeltétele az, hogy az NCBI frissítse az aktuális genomszerkezetet. Ekkor a db rögtön blasztolja az összes meglévő ref. És újonnan beadott SNP-it. 10. NCBI kontig bejegyzés: az NCBI RefSeq kromoszomákon, kontigszekvenciákon, mRNS-eken és proteineken a refSNP-k 2 értékekkel szerepelhetnek: 2-es értékűek bizonytalan térképezési eredményt jelentenek. Az ennél magasabb értékűek használhatósága eléggé bizonytalan, de ezek is elérhetőek.

21
11. GenBank és más RefSeq recordok bejegyzése: a GenBank recordokata RefSeq-kel ellentétben kizárolag az eredeti szerző jegyezheti be.

Hasonló előadás
















 Bihari Péter.>")
.>")

