WP-Dyna: tervezés és megerősítéses tanulás jól tervezhető környezetekben Szita István és Takács Bálint ELTE TTK témavezető: dr. Lőrincz András Információs Rendszerek Tanszék
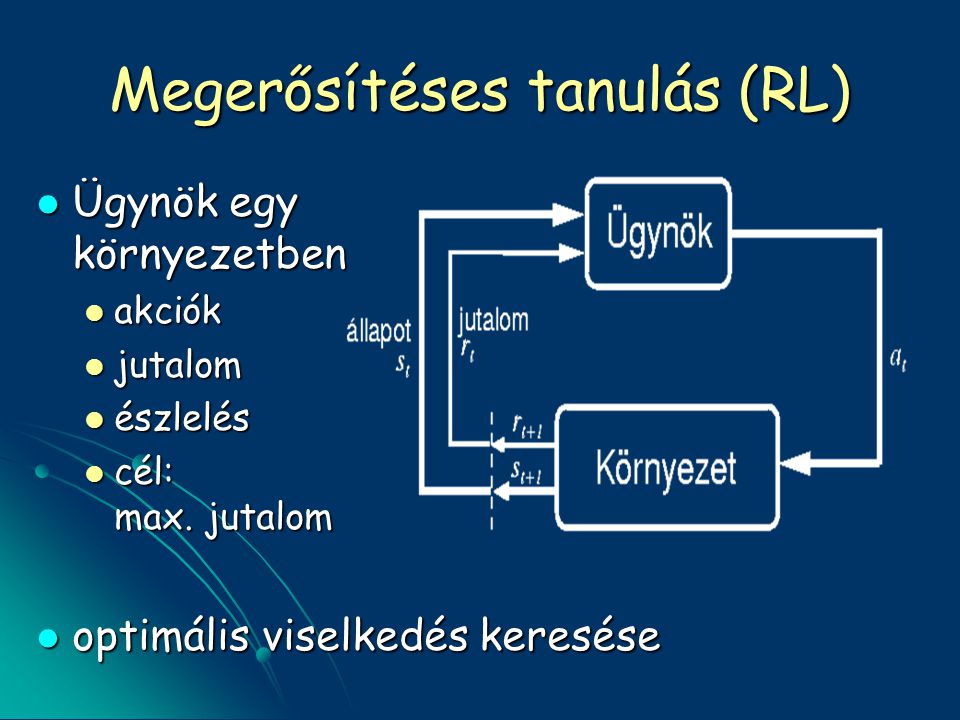
Megerősítéses tanulás (RL) Ügynök egy környezetben Ügynök egy környezetben akciók akciók jutalom jutalom észlelés észlelés cél: max. jutalom cél: max. jutalom optimális viselkedés keresése optimális viselkedés keresése
Megerősítéses tanulás – hogyan? Markov döntési folyamatok, értékelőfüggvény Markov döntési folyamatok, értékelőfüggvény Az ügynök tapasztalatokat gyűjt (állapot, akció, hatásai) Az ügynök tapasztalatokat gyűjt (állapot, akció, hatásai) modellt tanul (átmeneti valószínűségek) modellt tanul (átmeneti valószínűségek) értékelőfüggvényt tanul értékelőfüggvényt tanul értékelőfüggvény alapján lép értékelőfüggvény alapján lép optimális viselkedéshez konvergál (pl. értékiteráció, politikaiteráció, SARSA, Q- learning) optimális viselkedéshez konvergál (pl. értékiteráció, politikaiteráció, SARSA, Q- learning)
Megerősítéses tanulás – előnyök Általános formalizmus Általános formalizmus Elméletileg megalapozott Elméletileg megalapozott hatékony tanulási módszer hatékony tanulási módszer játékok játékok optimalizálás, szabályozás optimalizálás, szabályozás intelligens web-barangoló intelligens web-barangoló kép-, hangfelismerés kép-, hangfelismerés
Megerősítéses tanulás – problémák ha nő a feladat mérete -> nagyon lassú a tanulás ha nő a feladat mérete -> nagyon lassú a tanulás sokféle módon próbálják javítani sokféle módon próbálják javítani „emlékező nyomok” „emlékező nyomok” tervezés tervezés makrók makrók hierarchikus módszerek hierarchikus módszerek faktorizált feladatreprezentáció faktorizált feladatreprezentáció
Megerősítéses tanulás – új megközelítésmód fő probléma: az általánosság fő probléma: az általánosság minden teljesen sztochasztikus lehet ritkán használjuk ki minden teljesen sztochasztikus lehet ritkán használjuk ki ötlet: determinisztikus közelítő modell ötlet: determinisztikus közelítő modell okosan: csak ott, ahol már amúgy is majdnem determinisztikus okosan: csak ott, ahol már amúgy is majdnem determinisztikus „jól-tervezhető” (well-plannable) tartományok – WP modell „jól-tervezhető” (well-plannable) tartományok – WP modell
Hogyan segít a WP modell? megoldás: a Dyna általánosítása megoldás: a Dyna általánosítása az RL ügynök gyűjti a tapasztalatokat az RL ügynök gyűjti a tapasztalatokat tanulja a modellt tanulja a modellt pontosítja az értékelőfüggvényt pontosítja az értékelőfüggvényt a (pontatlan) modell alapján fiktív tapasztalatot gyűjt a (pontatlan) modell alapján fiktív tapasztalatot gyűjt ez alapján pontosítja az értékelőfüggvényt (tervez) ez alapján pontosítja az értékelőfüggvényt (tervez) Önmagában túl pontatlan Önmagában túl pontatlan
a WP-Dyna algoritmus két értékelőfüggvény két értékelőfüggvény „alap”: valódi tapasztalatok valódi tapasztalatok az alap RL alg. tanulja az alap RL alg. tanulja lassan konvergál lassan konvergál aszimpt. optimális aszimpt. optimális„tervező”: fiktív tapasztalatok fiktív tapasztalatok WP modell alapján tanuljuk WP modell alapján tanuljuk gyorsan konvergál gyorsan konvergál nem optimális nem optimális azt használjuk, amelyik „többet ígér” azt használjuk, amelyik „többet ígér”
WP-Dyna - tulajdonságok elvárás: elvárás: a „tervező” értékelőfüggvény gyorsan jó közelítést ad a „tervező” értékelőfüggvény gyorsan jó közelítést ad az „alap” értékelőfüggvény irányít hosszútávon az „alap” értékelőfüggvény irányít hosszútávon igazoltuk: a WP-Dyna valóban igazoltuk: a WP-Dyna valóban aszimptotikusan optimális aszimptotikusan optimális gyors gyors
a WP-Dyna optimális bebizonyítottuk: ha az alap RL optimális viselkedéshez konvergál -> a WP-Dyna majdnem-optimálishoz konvergál bebizonyítottuk: ha az alap RL optimális viselkedéshez konvergál -> a WP-Dyna majdnem-optimálishoz konvergál korlátot adtunk a hibára korlátot adtunk a hibára módosítás: módosítás: bebizonyítottuk: a diszkontált WP-Dyna optimális viselkedéshez konvergál bebizonyítottuk: a diszkontált WP-Dyna optimális viselkedéshez konvergál
matematikai apparátus Markov döntési folyamatok elmélete Markov döntési folyamatok elmélete Robbins-Monro iterált átlagolási tétele Robbins-Monro iterált átlagolási tétele dinamikus programozás dinamikus programozás kontrakciós fixponttételek kontrakciós fixponttételek -MDP-k elmélete -MDP-k elmélete
a WP-Dyna gyors: számítógépes szimuláció egyszerű tesztprobléma: „labirintus” egyszerű tesztprobléma: „labirintus”
Futtatási eredmények =0.95 =0.9
A modellparaméter hatása
a WP modell jelentősége releváns-e az előző példánk? releváns-e az előző példánk? inkább szabály, mint kivétel inkább szabály, mint kivétel „mérnöki” irányítási problémák „mérnöki” irányítási problémák determinisztikusak determinisztikusak zajos megfigyelés / irányítás zajos megfigyelés / irányítás itt a WP modell jó közelítés -> a WP- Dyna hatékony itt a WP modell jó közelítés -> a WP- Dyna hatékony
WP-Dyna – Összefoglalás gyakorlatilag bármilyen RL algoritmust kiegészíthet gyakorlatilag bármilyen RL algoritmust kiegészíthet kihasználja a feladatban rejlő determinisztikus struktúrát kihasználja a feladatban rejlő determinisztikus struktúrát más algoritmus nem használja ezt ki más algoritmus nem használja ezt ki szinte minden releváns feladatban jelen van szinte minden releváns feladatban jelen van jelentős gyorsítást ér el – az optimalitás megőrzésével jelentős gyorsítást ér el – az optimalitás megőrzésével
Köszönöm a figyelmet!
További kutatási irányok faktorizált reprezentációjú feladatok faktorizált reprezentációjú feladatok alkalmazás változó környezetekben alkalmazás változó környezetekben együttműködés robusztus kontrollerekkel együttműködés robusztus kontrollerekkel