1
m pozitív egészre legyen a1, …, am különböző üzenetek halmaza. Az információ mérése m pozitív egészre legyen a1, …, am különböző üzenetek halmaza. Ha az ai üzenetet ki-szer fordul elő az adásban, akkor ai gyakorisága ki, relatív gyakorisága: m-es az üzenetek eloszlása. 2
A definíciókból nyilvánvaló, hogy az ai üzenet egyedi információtartalma: ahol r egy egynél nagyobb valós szám az információ egysége. r = 2 esetén beszélünk bitekről. Az üzenetek átlagos információtartama 3
ahol az eloszlás entrópiája Általánosítva: 4 egy m tagú eloszlás pozitív valós számokból álló p0, p1, …, pn sorozat, amelyre ahol az eloszlás entrópiája Tehát az átlagos információtartalom legfeljebb logr m bit.
Legyenek A, B nem üres halmazok a kódolandó ábécé, illetve a Betűnkénti kódolás 5 Legyenek A, B nem üres halmazok a kódolandó ábécé, illetve a kódoló ábécé betűinek halmaza. A megfelelő ábécéből képzett összes szó halmaza A+, illetve B+. legalább 1 hosszú Ha megengedjük az úgynevezett „üres” szót is, akkor A*, illetve B*. A betűnkénti kódolás tulajdonképpen egy : A → B* függvény, amelyet kiterjesztünk egy : A* → B* függvénnyé: injektív!
x = abc A* prefix szuffix infix Az üres szó és x triviális prefix, infix, szuffix. Kódfa a c b 6
Morse – ábécé 7
ha φ injektív, akkor ilyen Felbontható (egyértelműen dekódolható, veszteségmentes) kódok ha φ injektív, akkor ilyen Prefix kód: prefix mentes! Vesszős kód: a vessző olyan nemüres elem a kódszavak közül, amely minden kódszónak szuffixe, és egyetlen kódszónak sem prefixe, vagy infixe. Egyenletes (fix hosszúságú) kód: kódszavak hossza megegyezik. Észrevétel: egy betűnkénti kód pontosan akkor prefix, ha 8 a kódfának csak a levelei kódszavak.
Tétel (McMillan-egyenlőtlenség) 9 Legyen A = {a1, …, an}, |B| = r 2 és : A → B+ injektív leképezés. Ha a által meghatározott betűnkénti kódolás felbontható, és li = |(ai)|, akkor és fordítva, ha l1, …, ln olyan pozitív egészek, hogy akkor létezik az A halmaz elemeinek a B elemeivel való olyan prefix kódolása, hogy az ai betű kódjának a hossza li.
az átlagos szóhosszúság: Optimális kód 10 Az előbbi jelöléseket használva az átlagos szóhosszúság: Az optimális kódról beszélünk, ha egy felbontható betűnkénti kód átlagos szóhosszúsága minimális. Létezik optimális kód ? Ha egy tetszőleges felbontható kód átlagos szóhosszúsága l, akkor pili > l esetén a kód nem lehet optimális elég csak az li l/pi eseteket vizsgálni ilyen kódok véges sokan vannak.
Tétel (optimális kód konstrukciója) Az előző tétel jelöléseivel, legyen n > 1. Tekintsünk egy optimális prefix kódot és kódfáját, továbbá legyen a kódszavak hosszának maximuma L. 11 Ekkor
még a csonka csúcsokból is 12 még a csonka csúcsokból is Továbbá
(5) egy optimális prefix kód kódfájában nincs csonka csúcs, ha azaz ha egy csonka csúcs van, akkor annak m kifokára azaz trivi 13
akkor 14
két betű kódját felcserélve l csökken - Biz. 15 két betű kódját felcserélve l csökken - éllel együtt átrakjuk a csonka csúcsra, akkor a kódhossz L-ről t + 1-re változik, tehát az átlag csökken.
(3) Tfh, hogy van olyan csonka csúcs, amelyből csak 1 él indul. … 1 2 (4) Tfh, van két csonka csúcs (2) mindkettő az L – 1–edik szinten van az egyik csonka csúcshoz tartozó leveleket éllel együtt átrakjuk a másikra … 16
(5) Tfh, n levél van a kódfában 17 (5) Tfh, n levél van a kódfában töröljük az egyik csúcshoz tartalmazó összes levelet mert +1 keletkezik is ha van csonka csúcs, azzal kezdjük ha t levelet töröltünk, akkor t – 1-gyel csökken a levelek száma …végül s lépés után csak a gyökér marad. Ekkor azaz
Huffman-kód (példa): |A| = 9, r = 4. 4 9 (mod 3) lesz csonka csúcs! eloszlás a: 0.20 a: 0.20 k: 0.45 l: 1.00 b: 0.19 b: 0.19 a: 0.20 c: 0.16 c: 0.16 b: 0.19 j: 0.15 l d: 0.11 c: 0.16 e: 0.10 d: 0.11 k a b c f: 0.09 e: 0.10 d e f j g: 0.06 f: 0.09 g h i h: 0.05 Mennyit kell összefogni? i: 0.04 m 2 + (7 mod (3)) m = 2 + 1. 18
(7) Helyettesítsük az ak betű kódját m kódszóval, úgy hogy a 19 (7) Helyettesítsük az ak betű kódját m kódszóval, úgy hogy a a levelek száma prefix tulajdonság megmaradjon. Ekkor a kódolandó ábácé nőtt m – 1 betűvel. A kapott kódot jelöljük φ –vel. Indirekte tfh, az állítás nem igaz, és legyen φ* a
Az általánosság megsértése nélkül feltehetjük, hogy Konstrukció + (5) φ és φ* kódfájában egyszerre van csonka csúcs, és ha van, akkor a kifoka ugyanannyi mindkét kódolásnál: m, ha nincs, akkor m = r. φ* optimális + (1), (2) az m db legkisebb valószínűséghez tartozó kódszó a legmagasabb szinten van a kódfában, és ugyanezen szinten vannak azok a kódszavak, amelyek a csonka csúcshoz tartoznak. 20
feltehetjük, hogy mindkét kódfában Azonos szinten lévő kódszavak cseréje nem változtatja meg az átlag kódhosszt feltehetjük, hogy mindkét kódfában 21 az m db legkisebb valószínűségű kódszóhoz tartozó levél ugyanahhoz a csúcshoz tartozik.
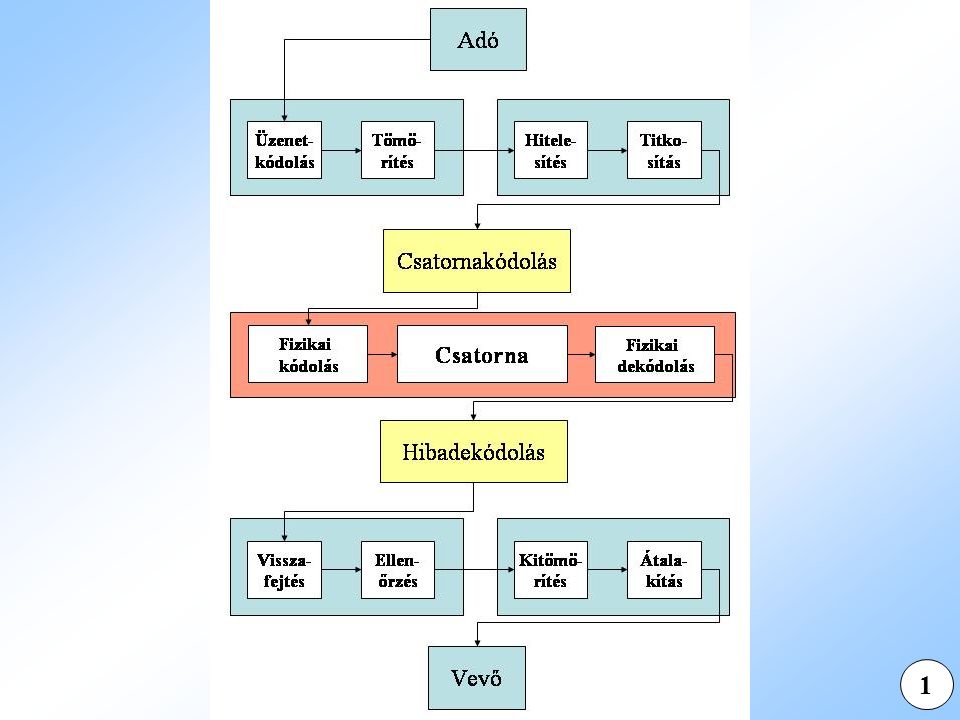
Hibakorlátozó kódolás 22 Hibakorlátozó kódolás Példák Paritásbit Ismétléses kód A hibakorlátozó kódok elméleti vizsgálata során fel szokás tenni, hogy nincsenek elveszett bitek, tehát ugyanannyi bit érkezik, mint amennyit elküldtünk. Fontos feltétel továbbá, hogy egyenletes kódról van szó, tehát minden kódszó egyforma hosszú. Def. Egy kódot t-hibajelzőnek nevezünk, ha minden olyan esetben jelez, ha a vett kódszó legfeljebb t helyen változik meg. Def. A kód pontosan t-hibajelző, ha t-hibajelző, de nem t + 1 hibajelző, azaz van olyan t + 1 hiba, amelyet a kód nem jelez.
Kódok távolsága és súlya 23 Legyen u, v a kódábécé két szava. Ekkor d(u, v) a két szó Hamming-távolsága, az azonos pozícióban lévő különböző jegyek száma. Általánosítva a C kódhalmazra, d(C) a kód távolsága, legalább 2 elem esetén az összes kódszó-pár távolságának minimuma. A Hamming-távolság rendelkezik a következő tulajdonságokkal:
Ha A kódábécé Abel-csoport, akkor legyen az u kódszó Hamming-súlya w(u), a nullától különböző jegyek száma u-ban. Az előbbiekhez hasonlóan w(C) jelenti a kód súlyát, azaz a nem nulla kódszavak súlyának minimumát. Észrevételek d(u, v) = w(u – v) , w(u) = d(u, 0). Csoport kódról beszélünk, ha C An, azaz ha C is Abel-csoport. Ekkor d(C) = w(C). 24
A fentebb bevezetett fogalmakkal: Észrevételek A fentebb bevezetett fogalmakkal: egy kód akkor és csak akkor t-hibajelző, ha t < d, és csak akkor pontosan t-hibajelző, ha t = d – 1. paritásbites kód: a kódszavak legalább 1 bitben különböznek ha az eltérés pont 1 bit két közleményszóban a paritásbit különbözik Hamming-távolság 2, ha az eltérés pont 2 bit két közleményszóban a paritásbit ugyanaz ha Hamming-távolság 2 pontosan 1-hibajelző. 25
Minimális távolságú dekódolás 26 hibát észleltünk: nem létező kódszót kaptunk feladat: a hibás kódszóhoz keressük meg a „jót” döntési függvény: pontosan egy kódszót rendel a hibás szóhoz döntési hiba: nem a jó kódszót rendeli hozzá cél: hibalehetőség a lehető legkisebb legyen Önkényesen feltételezzük, hogy a kapott kódszóban több a jó bit, mint a hibás, még akkor is, ha ez sajnos a valóságban nem mindig teljesül, tehát azt várjuk a döntési függvénytől, hogy a kapott, esetleg hibás szóhoz azt a kódszót rendelje, amelynek a tőle vett távolsága minimális. Minimális távolságú dekódolás
Mi van, ha több ilyen kódszó is van? 27 Adunk egy algoritmust, amely „következetesen” választ egy kódszót, vagy nem döntünk, csak jelezzük a hibát.
Ha minimális hosszúságú dekódolással dolgozunk, Def. Egy kódot t-hibajavítónak nevezünk, ha minden olyan esetben helyesen javít, amikor a vett kódszó legfeljebb t helyen változik meg. Def. A kód pontosan t-hibajavító, ha t-hibajavító, de nem t + 1 hibajavító, azaz van olyan t + 1 hiba, amelyet a kód nem javít, vagy helytelenül javít. Ha minimális hosszúságú dekódolással dolgozunk, akkor a d távolságú kód minden esetén t-hibajavító, és ekkor pontosan hibajavító. 28
2-hibajelző és 1-hibajavító Ismétléses kód 29 Kódszó: Duplázás: 1-hibajelző 2-hibajelző és 1-hibajavító Triplázás:
paritásbitek páratlanra Kétdimenziós paritásellenőrzés paritásbitek páratlanra m darab n-bites üzenet paritásbitek párosra 1-hibajavító kódolás. 30
Def. Legyen A és S nem üres véges halmaz, n > 0 egész, φ: A S+ injektív, Im(φ) = C Sn. Ekkor C egy blokk-kód (n, M, d)S jelöléssel, ahol |C| = M és d = d(C). Def. Ha S Abel-csoport, és C Sn a komponensenkénti S-beli művelettel, akkor C csoportkód. Def. Ha Sn egyben egy test feletti vektortér, és C ennek egy k-dimenziós altere (k 0 egész), akkor a kód lineáris. Jel.: [n, k, d]q, ahol q a test elemszáma. Def. Ha [n, k, d]q kódban bármely s0s1…sn – 2sn – 1 kódszó esetén sn – 1s0s1…sn – 2 is eleme a kódnak, akkor C ciklikus kód. 31
q elemű ábácé és n hosszú kódszavak esetén, ha C t-hibajavító, akkor Hamming-korlát q elemű ábácé és n hosszú kódszavak esetén, ha C t-hibajavító, akkor két kódszóra a tőlük legfeljebb t távolságra lévő szavak halmazai diszjunktak Mivel egy kódszótól pontosan j távolságra pontosan szó van, kapjuk, hogy Egyenlőség esetén tökéletes kód. 32
Ha q elemű ábácé és n hosszú szavaiból álló C kód távolsága d, akkor Singleton-korlát Ha q elemű ábácé és n hosszú szavaiból álló C kód távolsága d, akkor kódszóból d – 1 betűt ( ugyanarról a d – 1 helyről) elhagyva a kódszavak még mindig különböznek, de csak n – d + 1 hosszúak mindkét oldallogaritmusát véve Lineáris kód esetén a Singleton-korlát alakja: 33 k n – d + 1.
Egyenlőség esetén maximális távolságú szeparábilis kód, ekkor ahol k = n – d + 1. Miért szeparábilis? rögzített d – 1 = n – k helyen álló betűket elhagyva qk különböző szó marad ezekre képezzük le az üzeneteket, a megmaradt d – 1 = n – k helyekre ellenőrző betűket írunk, így kódoló és ellenőrző betűk elválaszthatók lesznek. 34
A gyakorlatban általában ilyeneket használnak. Lineáris kód 35 A gyakorlatban általában ilyeneket használnak. A test feletti n-esek, vagyis az alakú kódszavak tulajdonképpen ugyanezen test feletti alakú polinomoknak tekinthetők.
Tehát kapunk egy G kn-es mátrixot. Def. A kód generátormátrixa az altér egy bázisa lesz, úgy hogy k darab sorvektorként írjuk a báziselemeket. Tehát kapunk egy G kn-es mátrixot. Az előbbi k-dimenziós altér ortogonális altere rendelkezik azzal a tulajdonsággal, hogy a benne lévő vektorok szorzata egy altérbeli vektorral mindig 0-t ad. Hasonlóan G-hez, megkonstruálunk egy H (n – k)n-es ellenőrző mátrixot, amelyben az ortogonális altér bázisvektorai vannak. Ekkor ahol GT a G mátrix transzponáltja. 36
Hogyan azonosítjuk a kódszavakat? Tegyük fel, hogy a kapott szavunk v Kn. Szorzunk a H ellenőrző mátrixszal, kódszó esetén azt kell kapjuk, hogy szindróma (hibajellemző) Megfelelően megkonstruált kód esetén, valamennyi hiba erejéig a kapott szorzat vektor el is tudja árulni, hogy hol keressük a hibát. 37
Cyclic Redundancy Check (CRC) 38 F2-ből indulunk ki, tehát a kételemű testből, így az üzenetszó, illetve a kódszó is bitekből fog állni. Legyen a kódolni kívánt üzenet k hosszú, ekkor redundáns bitek száma Veszünk egy m-edfokú polinomot, amely az úgynevezett g kódpolinom. A k hosszúságú üzenetszót kiegészítjük jobbról m 0-val n hosszúságúra. Az így kapott szót (polinomot) osztjuk a kódpolinommal maradékosan, a maradékot beírjuk az előbbi 0-k helyére az üzenetszó után.
Kapjuk a kódszót, amely rendelkezik azzal a jó tulajdonsággal, hogy osztható a kódpolinommal hibaellenőrzéskor a kapott szót, azaz a neki megfelelő polinomot osztani kell a kódpolinommal, és ha a maradék polinom 0, akkor kódszót kaptunk. Kihasználtuk, hogy a kételemű testben 1 = – 1: Tehát, ha az üzenetpolinom p(x): p(x) xm = q(x) g(x) + r(x) a kódpolinom: q(x) g(x) = p(x) xm – r(x) = p(x) xm + r(x) . 39
továbbá az üzenet 101, és a kódpolinom Példa: legyen továbbá az üzenet 101, és a kódpolinom p(x) p(x) xm r(x) redundáns bitek végül a kódszó: 40 q(x) g(x)
Végezzük el a hibaellenőrzést is. A kódszónak megfelelő polinom Ezt a polinomot osztjuk most a kódpolinommal maradékosan: 41 Példák a mindennapi életben gyakran használt CRC-kódpolinomra.
A kódot, amely pontosan 1-hibajavító, példán keresztül mutatjuk be. Hamming-kód 42 A kódot, amely pontosan 1-hibajavító, példán keresztül mutatjuk be. F2 felett dolgozunk, így vektoraink komponensei bitek. Legyen Készítünk egy rn-es mátrixot az oszlopokba alulról felfelé vezető nullákkal ellátva felírjuk a számokat egytől n-ig, bináris formában. Tehát r = 3 esetén: Ez lesz a H ellenőrző mátrix, de a kódokat is ezzel generáljuk, hiszen azok a v vektorok kerülnek be a kódba, amelyekre H v = 0.
Vegyük észre, hogy a kettő hatványokban (2m) pontosan 1 darab 1-es van, mégpedig az m-edik helyen. Az rr-es egységmátrix tartalmazza a redundáns biteket, a többi soronként k darab bit lesz a „közlemény”. Könnyen ellenőrizhető, hogy a szó kódszó, mivel 43
szóval? u nem kódszó, és a hibavektor Mi a helyzet az 44 szóval? u nem kódszó, és a hibavektor azaz Végezzük el a számolást: Az 111 bitsorozat tízes számrendszerben felírva 7. 7 0 hiba van. Azt is megkaptuk, hogy a hiba a 7. helyen van a kapott szóban, tehát tudunk javítani.
A kódszavakat hogyan határozhatjuk meg? 45 Ha a k hosszúságú üzenet b1…bk, akkor az n bit hosszú kódszóba először tegyük be kiszámítandó redundáns biteket a pontosan r = n – k darab 2-hatvány helyre. Ez az előző példában az 1., 2., 4. helyet jelenti. A maradék helyekre pedig beszúrjuk az üzenet k darab bitjét. Ekkor a kapott c vektor transzponáltját H-val szorozva: A Hamming-kód esetén a maximális üzenethosszak azaz
