Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Adatbázisok tervezése, megvalósítása és menedzselése
Fájlszervezés Adatbázisok tervezése, megvalósítása és menedzselése

2
Kezdetek Célok: gyors lekérdezés,
gyors adatmódosítás, minél kisebb tárolási terület. Nincs általánosan legjobb optimalizáció. Az egyik cél a másik rovására javítható (például indexek használatával csökken a keresési idő, nő a tárméret, és nő a módosítási idő).
.")
3
Költségek Hogyan mérjük a költségeket?
Memória műveletek nagyságrenddel gyorsabbak, mint a háttértárolóról beolvasás, kiírás. Az író-olvasó fej nagyobb adategységeket (blokkokat) olvas be. A blokkméret függhet az operációs rendszertől, hardvertől, adatbázis-kezelőtől. A blokkméretet fixnek tekintjük. Oracle esetén 8K az alapértelmezés. Feltételezzük, hogy a beolvasás, kiírás költsége arányos a háttértároló és memória között mozgatott blokkok számával.
 olvas be. A blokkméret függhet az operációs rendszertől, hardvertől, adatbázis-kezelőtől. A blokkméretet fixnek tekintjük. Oracle esetén 8K az alapértelmezés. Feltételezzük, hogy a beolvasás, kiírás költsége arányos a háttértároló és memória között mozgatott blokkok számával.")
4
Blokkok A blokkok tartalmaznak: Feltesszük, hogy B darab blokkunk van.
leíró fejlécet (rekordok száma, struktúrája, fájlok leírása, belső/külső mutatók (hol kezdődik a rekord, hol vannak üres helyek, melyik a következő blokk, melyik az előző blokk, statisztikák (melyik fájlból hány rekord szerepel a blokkban)), rekordokat (egy vagy több fájlból), üres helyeket. Feltesszük, hogy B darab blokkunk van.
), rekordokat (egy vagy több fájlból), üres helyeket. Feltesszük, hogy B darab blokkunk van.")
5
Rekordok A fájl rekordokból áll.
A rekordok szerkezete eltérő is lehet. A rekord tartalmaz: leíró fejlécet (rekordstruktúra leírása, belső/külső mutatók, (hol kezdődik egy mező, melyek a kitöltetlen mezők, melyik a következő rekord, melyik az előző rekord), törlési bit, statisztikák), mezőket, melyek üresek, vagy adatot tartalmaznak. A rekordhossz lehet: állandó, változó (változó hosszú mezők, ismétlődő mezők miatt). Az egyszerűség kedvéért feltesszük, hogy állandó hosszú rekordokból áll a fájl, melyek hossza az átlagos rekordméretnek felel.
, törlési bit, statisztikák), mezőket, melyek üresek, vagy adatot tartalmaznak. A rekordhossz lehet: állandó, változó (változó hosszú mezők, ismétlődő mezők miatt). Az egyszerűség kedvéért feltesszük, hogy állandó hosszú rekordokból áll a fájl, melyek hossza az átlagos rekordméretnek felel.")
6
Milyen lekérdezések? Milyen lekérdezéseket vizsgáljunk?
A relációs algebrai kiválasztás felbontható atomi kiválasztásokra, így elég ezek költségét vizsgálni. A legegyszerűbb kiválasztás: A=a (A egy keresési mező, a egy konstans) Kétféle bonyolultságot szokás vizsgálni: átlagos, legrosszabb eset. Az esetek vizsgálatánál az is számít, hogy az A=a feltételnek megfelelő rekordokból lehet-e több, vagy biztos, hogy csak egy lehet. Fel szoktuk tenni, hogy az A=a feltételnek eleget tevő rekordokból nagyjából egyforma számú rekord szerepel. (Ez az egyenletességi feltétel.)
 Kétféle bonyolultságot szokás vizsgálni: átlagos, legrosszabb eset. Az esetek vizsgálatánál az is számít, hogy az A=a feltételnek megfelelő rekordokból lehet-e több, vagy biztos, hogy csak egy lehet. Fel szoktuk tenni, hogy az A=a feltételnek eleget tevő rekordokból nagyjából egyforma számú rekord szerepel. (Ez az egyenletességi feltétel.)")
7
Mivel foglalkozunk majd?
A következő fájlszervezési módszereket fogjuk megvizsgálni: kupac (heap) rendezett állomány elsődleges index (ritka index, sűrű index) másodlagos index (sűrű index) többszintű index B+-fa, B*-fa bitmap index. Módosítási műveletek: beszúrás (insert) frissítés (update) törlés (delete) Az egyszerűsített esetben nem foglalkozunk azzal, hogy a beolvasott rekordokat bent lehet tartani a memóriában, későbbi keresések céljára.
 rendezett állomány. elsődleges index (ritka index, sűrű index) másodlagos index (sűrű index) többszintű index. B+-fa, B*-fa. bitmap index. Módosítási műveletek: beszúrás (insert) frissítés (update) törlés (delete) Az egyszerűsített esetben nem foglalkozunk azzal, hogy a beolvasott rekordokat bent lehet tartani a memóriában, későbbi keresések céljára.")
8
Kupac szervezés A rekordokat a blokk első üres helyre tesszük a beérkezés sorrendjében. A=a esetén a keresési idő: B (a legrosszabb esetben), B/2 (átlagos esetben egyenletességi feltétel esetén). Beszúrás: utolsó blokkba tesszük a rekordot, 1 olvasás + 1 írás módosítás: 1 keresés + 1 írás törlés: 1 keresés + 1 írás (üres hely marad, vagy a törlési bitet állítják át)
, B/2 (átlagos esetben egyenletességi feltétel esetén). Beszúrás: utolsó blokkba tesszük a rekordot, 1 olvasás + 1 írás. módosítás: 1 keresés + 1 írás. törlés: 1 keresés + 1 írás (üres hely marad, vagy a törlési bitet állítják át)")
9
Rendezett állomány I. A fájl egy rendező mező alapján rendezett, a blokkok láncolva vannak, és a következő blokkban nagyobb értékű rekordok szerepelnek, mint az előzőben. A = a esetén, ha a rendező mező és kereső mező nem esik egybe, akkor kupac szervezést jelent. Ha a rendező mező és kereső mező egybeesik, akkor bináris (logaritmikus) keresést lehet alkalmazni: beolvassuk a középső blokkot, ha nincs benne az A=a értékű rekord, akkor eldöntjük, hogy a blokklánc második felében, vagy az első felében szerepelhet-e egyáltalán, beolvassuk a felezett blokklánc középső blokkját, addig folytatjuk, amíg megtaláljuk a rekordot, vagy a vizsgálandó maradék blokklánc már csak 1 blokkból áll. Keresési idő: log2(B).
 keresést lehet alkalmazni: beolvassuk a középső blokkot, ha nincs benne az A=a értékű rekord, akkor eldöntjük, hogy a blokklánc második felében, vagy az első felében szerepelhet-e egyáltalán, beolvassuk a felezett blokklánc középső blokkját, addig folytatjuk, amíg megtaláljuk a rekordot, vagy a vizsgálandó maradék blokklánc már csak 1 blokkból áll. Keresési idő: log2(B).")
10
Rendezett állomány II. Beszúrás:
keresés + üres hely készítés miatt a rekordok eltolása az összes blokkban, az adott találati blokktól kezdve (B/2 blokkot be kell olvasni, majd az eltolások után visszaírni=B művelet) Ennek elkerülése érdekében túlcsordulási blokkokat használnak: az új, beszúrandó rekordok számára új blokkot nyitunk. Ha ez betelik, újabb blokkokat láncolunk az előzőekhez. A keresést 2 helyen végezzük: log2(B) költséggel keresünk a rendezett részben, és ha nem találjuk, akkor a gyűjtőben is megnézzük (G blokkművelet, ahol G a túlcsordulási blokkok száma). Ha a G túl nagy a log2(B) - hez képest, akkor újrarendezzük a teljes fájlt (a rendezés költsége B*log2(B)).
 Ennek elkerülése érdekében túlcsordulási blokkokat használnak: az új, beszúrandó rekordok számára új blokkot nyitunk. Ha ez betelik, újabb blokkokat láncolunk az előzőekhez. A keresést 2 helyen végezzük: log2(B) költséggel keresünk a rendezett részben, és ha nem találjuk, akkor a gyűjtőben is megnézzük (G blokkművelet, ahol G a túlcsordulási blokkok száma). Ha a G túl nagy a log2(B) - hez képest, akkor újrarendezzük a teljes fájlt (a rendezés költsége B*log2(B)).")
11
Rendezett állomány III.
Vagy: üres helyeket hagyunk a blokkokban: például félig üresek a blokkok: a keresés után 1 blokkművelettel visszaírjuk a blokkot, amibe beírtuk az új rekordot, tárméret 2*B lesz keresési idő: log2(2*B) = 1+log2(B) ha betelik egy blokk, vagy elér egy határt a telítettsége, akkor 2 blokkba osztjuk szét a rekordjait, a rendezettség fenntartásával. Törlés: keresés + a törlés elvégzése, vagy a törlési bit beállítása után visszaírás (1 blokkírás) túl sok törlés után újraszervezés. Módosítás: törlés + beszúrás
 = 1+log2(B) ha betelik egy blokk, vagy elér egy határt a telítettsége, akkor 2 blokkba osztjuk szét a rekordjait, a rendezettség fenntartásával. Törlés: keresés + a törlés elvégzése, vagy a törlési bit beállítása után visszaírás (1 blokkírás) túl sok törlés után újraszervezés. Módosítás: törlés + beszúrás.")
12
Indexek Indexek használata: Az indexrekordok szerkezete:
keresést gyorsító segédstruktúra, több mezőre is lehet indexet készíteni, az index tárolása növeli a tárméretet, nem csak a főfájlt, hanem az indexet is karban kell tartani, ami plusz költséget jelent, ha a keresési kulcs egyik indexmezővel sem esik egybe, akkor kupac szervezést jelent. Az indexrekordok szerkezete: (a,p), ahol a egy érték az indexelt oszlopban, p egy blokkmutató, arra a blokkra mutat, amelyben az A=a értékű rekordot tároljuk. az index mindig rendezett az indexértékek szerint.
, ahol a egy érték az indexelt oszlopban, p egy blokkmutató, arra a blokkra mutat, amelyben az A=a értékű rekordot tároljuk. az index mindig rendezett az indexértékek szerint.")
13
Elsődleges index I. A fájl is rendezett a keresési kulcsra nézve (szekvenciális fájl). Ritka indexek: a főfájl minden blokkjának legkisebb értékű rekordjához készítünk indexrekordot. (Ez a legelső a blokkban.) Indexrekordok száma megegyezik a fájl blokkjainak számával. Indexrekordból sokkal több fér egy blokkba, mint a főfájl rekordjaiból. Keresési idő: az indexfájlban nem szerepel minden érték, ezért csak fedő értéket kereshetünk, a legnagyobb olyan indexértéket, amely a keresett értéknél kisebb vagy egyenlő fedő érték keresése az index rendezettsége miatt bináris kereséssel történik: log2(B(I)) a fedő indexrekordban szereplő blokkmutatónak megfelelő blokkot még be kell olvasni. 1+log2(B(I)) << log2(B) (rendezett eset)
 Indexrekordok száma megegyezik a fájl blokkjainak számával. Indexrekordból sokkal több fér egy blokkba, mint a főfájl rekordjaiból. Keresési idő: az indexfájlban nem szerepel minden érték, ezért csak fedő értéket kereshetünk, a legnagyobb olyan indexértéket, amely a keresett értéknél kisebb vagy egyenlő. fedő érték keresése az index rendezettsége miatt bináris kereséssel történik: log2(B(I)) a fedő indexrekordban szereplő blokkmutatónak megfelelő blokkot még be kell olvasni. 1+log2(B(I)) << log2(B) (rendezett eset)")
14
Elsődleges index II. Sűrű index: a főfájl minden rekordjához tartozik egy indexrekord, tehát az indexrekordok száma és a fájl rekordjainak száma megegyezik A ritka index nyilvánvaló előnye, hogy kevesebb helyet foglal. Hátránya, hogy a beolvasott blokkban keresni kell. További hátránya, hogy az olyan lekérdezéseknél, amelyekben csak a keresési kulcs attribútumai szerepelnek, elegendő az index megfelelő rekordjait beolvasni, ez azonban csak sűrű index esetén lehetséges.

15
Elsődleges index III. Adatállomány Ritka index
Az adatfájl rendezett, ezért elég a blokkok első rekordjaihoz tartozó indexrekordokat tárolni. 20 10 10 30 50 70 40 30 90 110 130 150 60 50 80 70 170 190 210 230 100 90

16
Elsődleges index IV. Adatállomány Sűrű index
Minden rekordhoz tartozik indexrekord. 20 10 10 20 30 40 40 30 50 60 70 80 60 50 80 70 90 100 110 120 100 90

17
Változások megoldása Stratégiák szekvenciális fájlok változásainak (beszúrás, törlés, módosítás) megvalósítására: túlcsodulásblokkok létrehozatala új blokkok beszúrása a szekvenciális fájlba sorok átcsúsztatása szomszédos blokkokba Művelet Sűrű index Ritka index üres túlcsordulásblokk létrehozása semmi üres túlcsordulásblokk törlése üres szekvenciális blokk létrehozása beszúrás üres szekvenciális blokk törlése törlés rekord beszúrása módosítás (?) rekord törlése rekord mozgatása módosítás
 rekord törlése. rekord mozgatása. módosítás.")
18
Beszúrás ritka indexbe I.
Vigyük be a 34-es rekordot! 20 10 10 30 40 30 34 Szerencsére volt üres hely! 60 50 40 60

19
Beszúrás ritka indexbe II.
Vigyük be a 15-ös rekordot! 20 10 15 20 30 10 30 40 30 60 50 40 60 Azonnal újrarendeztük az állományt. Másik változatban túlcsordulási blokkot láncolunk a blokkhoz.

20
Beszúrás ritka indexbe III.
Vigyük be a 25-ös rekordot! 20 10 25 10 30 40 30 60 50 40 60 Túlcsordulási blokkot nyitunk, és későbbre halasztjuk az újrarendezést.

21
Törlés ritka indexből I.
Töröljük a 40-es rekordot! 20 10 10 30 50 40 30 70 60 50 90 110 130 80 70 150

22
Törlés ritka indexből II.
Töröljük a 30-as rekordot! 20 10 10 40 30 50 40 30 70 60 50 90 110 130 80 70 150

23
Törlés ritka indexből III.
Töröljük a 30-as és 40-es rekordot! 20 10 10 50 70 30 50 40 30 70 60 50 90 110 130 80 70 150

24
Töröljük a 30-as rekordot!
Törlés sűrű indexből Töröljük a 30-as rekordot! 20 10 10 20 40 40 30 30 40 40 60 50 50 60 70 80 70 80

25
Ismétlődő értékek I. Sűrű index 10 10 20 10 20 10 30 20 30 20 30 30 45
megoldás: Minden rekordhoz tárolunk egy indexrekordot. 45 40 45 40

26
Ismétlődő értékek II. Ritka index 10 10 20 20 30 30 40 45 Hogyan
változik itt a keresési stratégia? 10 20 30 20 10 40 30 20 30 45 40 2. megoldás: Rendezett állomány esetén csak az értékek első előforduláshoz tárolunk egy indexrekordot.

27
Ismétlődő értékek III. 10 10 20 30 20 10 40 30 20 30 45 40 2. megoldás (egy másik változat): Az adatállomány blokkjait láncoljuk is .

28
Ismétlődő értékek III. Vigyázat! A fedőértéknek megfelelő blokk előtti és utáni blokkokban is lehetnek találatok. Például, ha a 20-ast vagy a 30-ast keressük. 10 10 Hogyan változik itt a keresési stratégia? 10 ! 20 20 10 30 30 20 30 ! 3. megoldás: Rendezett állomány esetén a blokk első rekordjához tároljuk a megfelelő indexrekordot. 45 40

29
Másodlagos indexek I. Főfájl rendezetlen (az indexfájl mindig rendezett). Több másodlagos indexet is meg lehet adni. A főfájl minden rekordjához indexrekordot kell készíteni. (Csak sűrű másodlagos index létezik.) Indexrekordból itt is általában sokkal több fér egy blokkba, mint a főfájl rekordjaiból. Keresési idő: az indexben keresés az index rendezettsége miatt bináris kereséssel történik: log2(B(I)). A talált indexrekordban szereplő blokkmutatóknak megfelelő blokkokat még be kell olvasni (k db). k+log2(B(I)) << log2(B) (a jobboldal a rendezett esethez tartozó keresési idő)
 Indexrekordból itt is általában sokkal több fér egy blokkba, mint a főfájl rekordjaiból. Keresési idő: az indexben keresés az index rendezettsége miatt bináris kereséssel történik: log2(B(I)). A talált indexrekordban szereplő blokkmutatóknak megfelelő blokkokat még be kell olvasni (k db). k+log2(B(I)) << log2(B) (a jobboldal a rendezett esethez tartozó keresési idő)")
30
Másodlagos indexek II. Beszúrás:
a főfájl kupac szervezésű, az index esetén viszont rendezett fájlba kell beszúrni. Megoldás: üres helyeket hagyunk az indexfájl blokkjaiban. Ezzel az index tárolásának mérete duplázódhat. Ha a főfájl is rendezett, akkor a korábban tárgyalt stratégiák egyike alkalmazható ott is (túlcsordulási blokkok, helyet hagyunk a blokkokban, csúsztatjuk az értékeket).
.")
31
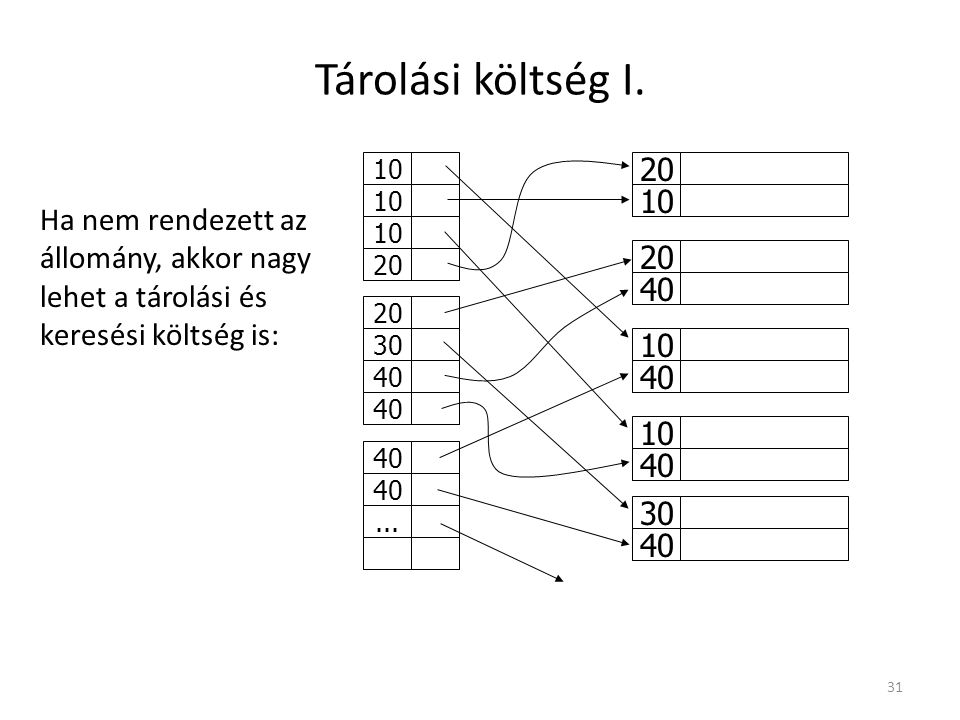
Tárolási költség I. 10 20 10 20 Ha nem rendezett az állomány, akkor nagy lehet a tárolási és keresési költség is: 40 20 20 30 40 40 10 40 10 40 ... 40 30
32
Tárolási költség II. 10 20 10 Egy lehetséges megoldás, hogy az indexrekordok szerkezetét módosítjuk: (indexérték, mutatóhalmaz). 40 20 20 40 10 30 40 40 10 Probléma: változó hosszú indexrekordok keletkeznek. 40 30
 Probléma: változó hosszú indexrekordok keletkeznek")
33
Tárolási költség III. 20 10 20 40 10 40 10 40 30 Probléma: 40 10 20 30
10 20 30 40 40 20 40 10 50 60 ... 40 10 40 30 Probléma: a rekordokhoz egy új, mutató típusú mezőt kell adnunk, ezt a láncot követni kell.

34
Tárolási költség IV. 20 10 20 40 10 40 10 40 30 40 Kosarak 10 20 30 40
50 60 ... 40 10 40 10 40 30 A mutatókat külön blokkokban is tárolhatjuk, így nem kell változó hosszú indexrekordokat kezelni. ELŐNY: több index esetén a logikai feltételek halmazműveletekkel kiszámolhatók. Kosarak

35
Mutatókosarak előnye osztály_index dolgozó emelet_index 2
select * from dolgozó where osztály='büfé' and emelet=2; osztály_index dolgozó emelet_index büfé 2 A büféhez és a 2-höz tartozó kosarak metszetét kell képezni, hogy megkapjuk a keresett mutatókat.

36
Klaszter Klaszterszervezés esetén a két tábla közös oszlopain megegyező sorok egy blokkban, vagy fizikailag egymás utáni blokkokban helyezkednek el. CÉL: összekapcsolás esetén az összetartozó sorokat soros beolvasással megkaphatjuk.

37
Példa klaszterre Film (cím, év, hossz, stúdiónév)
Stúdió (név, cím, elnök) 1. stúdió 2. stúdió 3. stúdió 1. stúdióban készült filmek. 2. stúdióban készült filmek. 3. stúdióban készült filmek. Pl. gyakori a: SELECT cím, év FROM film, stúdió WHERE cím LIKE ‘%Moszkva%’ AND stúdiónév = név; jellegű lekérdezés.
 1. stúdió. 2. stúdió. 3. stúdió. 1. stúdióban. készült filmek. 2. stúdióban. készült filmek. 3. stúdióban. készült filmek. Pl. gyakori a: SELECT cím, év. FROM film, stúdió. WHERE cím LIKE ‘%Moszkva%’ AND stúdiónév = név; jellegű. lekérdezés.")
38
Ritka (vagy sűrű) index 1. szint
Többszintű index I. Ha nagy az index, akkor az indexet is indexelhetjük. 20 10 10 90 170 250 10 30 50 70 40 30 90 110 130 150 330 410 490 570 60 50 80 70 170 190 210 230 Ritka index (2. szint) 100 90 Ritka (vagy sűrű) index 1. szint
 Ritka (vagy sűrű) index 1. szint.")
39
Többszintű indexek II. Az indexfájl is fájl, ráadásul rendezett, így ez is indexelhető. t-szintű index: az indexszinteket is indexeljük, összesen t szintig Keresési idő: a t-ik szinten bináris kereséssel keressük meg a fedő indexrekordot követjük a mutatót, minden szinten, és végül a főfájlban: log2(B(I(t)))+t blokkolvasás ha a legfelső szint 1 blokkból áll, akkor t+1 blokkolvasást jelent. (t=?)
))+t blokkolvasás. ha a legfelső szint 1 blokkból áll, akkor t+1 blokkolvasást jelent. (t= )")
40
Ha t. szinten 1 blokk van, akkor 1=B/bf(I)t, azaz
FŐFÁJL 1. szint 2. szint ... t. szint blokkok száma B B/bf(I) B/bf(I)2 B/bf(I)t rekordok száma T B/bf(I)(t-1) blokkolási faktor bf bf(I) Ha t. szinten 1 blokk van, akkor 1=B/bf(I)t, azaz a keresés t=logbf(I)B ideig tart, vagyis jobb a rendezett fájlszervezésnél. (Itt bf azt adja meg, hogy egy blokkba hány rekord fér.) logbf(I)B < log2(B(I)) is teljesül általában, így az egyszintű indexeknél is gyorsabb
 B/bf(I)2. B/bf(I)t. rekordok száma. T. B/bf(I)(t-1) blokkolási faktor. bf. bf(I) Ha t. szinten 1 blokk van, akkor 1=B/bf(I)t, azaz. a keresés t=logbf(I)B ideig tart, vagyis jobb a rendezett fájlszervezésnél. (Itt bf azt adja meg, hogy egy blokkba hány rekord fér.) logbf(I)B < log2(B(I)) is teljesül általában, így az egyszintű indexeknél is gyorsabb.")
41
Feladatok I. Minden blokkba 3 rekord, vagy 10 indexrekord (érték-mutató pár) fér. Összesen n rekordunk van. Hány blokkos az adatfájl, a sűrű index és a ritka index? Minden blokkba 30 rekord, vagy 200 indexrekord (érték-mutató pár) fér. Összesen n rekordunk van. Semelyik blokk telítettsége nem lehet több, mint 80%. Hány blokkos az adatfájl, a sűrű index és a ritka index? Minden blokkba 3 rekord, vagy 10 indexrekord (érték-mutató pár) fér. Összesen n rekordunk van. Többszintű indexünk legfelső szintje csak 1 blokkból áll. Hány blokkos az indexfájl, ha az első szinten sűrű az index, és ha az első szinten ritka az index?
 fér. Összesen n rekordunk van. Hány blokkos az adatfájl, a sűrű index és a ritka index Minden blokkba 30 rekord, vagy 200 indexrekord (érték-mutató pár) fér. Összesen n rekordunk van. Semelyik blokk telítettsége nem lehet több, mint 80%. Hány blokkos az adatfájl, a sűrű index és a ritka index Minden blokkba 3 rekord, vagy 10 indexrekord (érték-mutató pár) fér. Összesen n rekordunk van. Többszintű indexünk legfelső szintje csak 1 blokkból áll. Hány blokkos az indexfájl, ha az első szinten sűrű az index, és ha az első szinten ritka az index")
42
Feladatok II. Minden blokkba 3 rekord, vagy 10 indexrekord (érték-mutató pár) fér. Hány adatblokkot kell átlagosan beolvasni az összes adott értékű rekord eléréséhez, ha rendezett állományunk van, egy érték 1,2 vagy 3-szor szerepelhet 1/3, 1/3, 1/3 valószínűségekkel, és olyan sűrű indexünk van, amelyben csak az első előforduláshoz tartozik indexrekord? Feltesszük, hogy tudjuk előre, hogy mennyi előfordulásunk van az adott értékből.
 fér. Hány adatblokkot kell átlagosan beolvasni az összes adott értékű rekord eléréséhez, ha rendezett állományunk van, egy érték 1,2 vagy 3-szor szerepelhet 1/3, 1/3, 1/3 valószínűségekkel, és olyan sűrű indexünk van, amelyben csak az első előforduláshoz tartozik indexrekord Feltesszük, hogy tudjuk előre, hogy mennyi előfordulásunk van az adott értékből.")
43
Feladatok III. Minden blokkba 3 rekord, vagy 10 indexrekord (érték-mutató pár) fér. Hány blokkot kell átlagosan beolvasni az összes adott értékű rekord eléréséhez, ha egy érték 1,2 vagy 3-szor szerepelhet 1/3, 1/3, 1/3 valószínűségekkel, és olyan sűrű indexünk van, amelyben minden előforduláshoz tartozik indexrekord? Feltesszük, hogy már kiszámoltuk, hogy melyik indexblokkban van az első keresett indexérték, és tudjuk, hogy hány van belőle.
 fér. Hány blokkot kell átlagosan beolvasni az összes adott értékű rekord eléréséhez, ha egy érték 1,2 vagy 3-szor szerepelhet 1/3, 1/3, 1/3 valószínűségekkel, és olyan sűrű indexünk van, amelyben minden előforduláshoz tartozik indexrekord Feltesszük, hogy már kiszámoltuk, hogy melyik indexblokkban van az első keresett indexérték, és tudjuk, hogy hány van belőle.")
44
Feladatok IV. Minden blokkba 3 rekord, vagy 10 indexrekord (érték-mutató pár), vagy 50 mutató fér. Tegyük fel, hogy átlagosan 10-szer szerepel minden indexérték. Összesen 3000 rekordunk van. Másodlagos indexet készítünk, úgy, hogy az egy indexértékhez tartozó mutatókat kosarak blokkjaiban tároljuk. Mekkora az állomány mérete összesen, beleértve az adatokat, indexeket és mutatókat tartalmazó blokkokat?
, vagy 50 mutató fér. Tegyük fel, hogy átlagosan 10-szer szerepel minden indexérték. Összesen 3000 rekordunk van. Másodlagos indexet készítünk, úgy, hogy az egy indexértékhez tartozó mutatókat kosarak blokkjaiban tároljuk. Mekkora az állomány mérete összesen, beleértve az adatokat, indexeket és mutatókat tartalmazó blokkokat")
45
B-fák A többszintű indexek közül a B+-fák, B*-fák a legelterjedtebbek.
B+-fa: Minden blokk legalább 50%-ban telített. A többszintű indexek közül a B+-fák, B*-fák a legelterjedtebbek. 100 B*-fa: Minden blokk legalább 66%-ban telített. 120 150 180 30 3 5 11 120 130 30 35 100 101 110 180 200 150 156 179

46
Köztes (nem-levél) csúcs szerkezete
k < 57 57 k<81 81k< k 57 81 95 n+1 mutató n indexérték Ahol k a mutató által meghatározott részgráfban szereplő tetszőleges indexérték.

47
Levél csúcs szerkezete
köztes csúcs 57 81 95 a sorrendben következő levél n+1 mutató n indexérték 57 indexértékű rekord 81 indexértékű rekord 95 indexértékű rekord

48
Felépítésre vonatkozó szabályok
Szabályok (feltesszük, hogy egy csúcs n értéket és n+1 mutatót tartalmazhat): a gyökérben legalább két mutatónak kell lennie (kivéve, ha a B-fa (B+-fa) egyetlen bejegyzést tartalmaz), a levelekben az utolsó mutató a következő (jobboldali) levélre mutat, legalább (n+1)/2 mutatónak használatban kell lennie, köztes pontokban minden mutató a B-fa következő szintjére mutat, közülük legalább (n+1)/2 darabnak használatban kell lennie, ha egy mutató nincs használatban úgy vesszük, mintha NILL mutató lenne.
: a gyökérben legalább két mutatónak kell lennie (kivéve, ha a B-fa (B+-fa) egyetlen bejegyzést tartalmaz), a levelekben az utolsó mutató a következő (jobboldali) levélre mutat, legalább (n+1)/2 mutatónak használatban kell lennie, köztes pontokban minden mutató a B-fa következő szintjére mutat, közülük legalább (n+1)/2 darabnak használatban kell lennie, ha egy mutató nincs használatban úgy vesszük, mintha NILL mutató lenne.")
49
Beszúrás I. Ha van szabad hely az új kulcs számára a megfelelő levélben, beszúrjuk. Ha nincs, kettévágjuk a levelet, és szétosztjuk a kulcsokat a két új levél között, így mindkettő félig lesz telítve, vagy éppen csak egy kicsit jobban. Az eggyel feljebb lévő szint megfelelő csúcsát ennek megfelelően kell kiigazítani.

50
Beszúrás II. Egy csúcs szétvágása tehát hatással lehet a fölötte lévő szintre is. Itt az előbbi két pontban megadott stratégiát alkalmazzuk rekurzívan. Itt viszont: ha N olyan belső csúcs, aminek kapacitása n kulcs, n+1 mutató és most az (n+2). mutatót illesztenénk be, akkor szintén létrehozunk egy új M pontot. N-ben most marad n/2 kulcs, M-ben lesz n/2 kulcs, a "középen lévő" kulcs pedig az eggyel fentebbi szintre kerül, hogy elválassza N-t és M-t egymástól. Ha a gyökérbe nem tudunk beszúrni, mert nincs hely, akkor szétvágjuk a gyökeret két új csúcsra, és „fölöttük” létrehozunk egy új gyökeret, aminek két bejegyzése lesz.
. mutatót illesztenénk be, akkor szintén létrehozunk egy új M pontot. N-ben most marad n/2 kulcs, M-ben lesz n/2 kulcs, a középen lévő kulcs pedig az eggyel fentebbi szintre kerül, hogy elválassza N-t és M-t egymástól. Ha a gyökérbe nem tudunk beszúrni, mert nincs hely, akkor szétvágjuk a gyökeret két új csúcsra, és „fölöttük létrehozunk egy új gyökeret, aminek két bejegyzése lesz.")
51
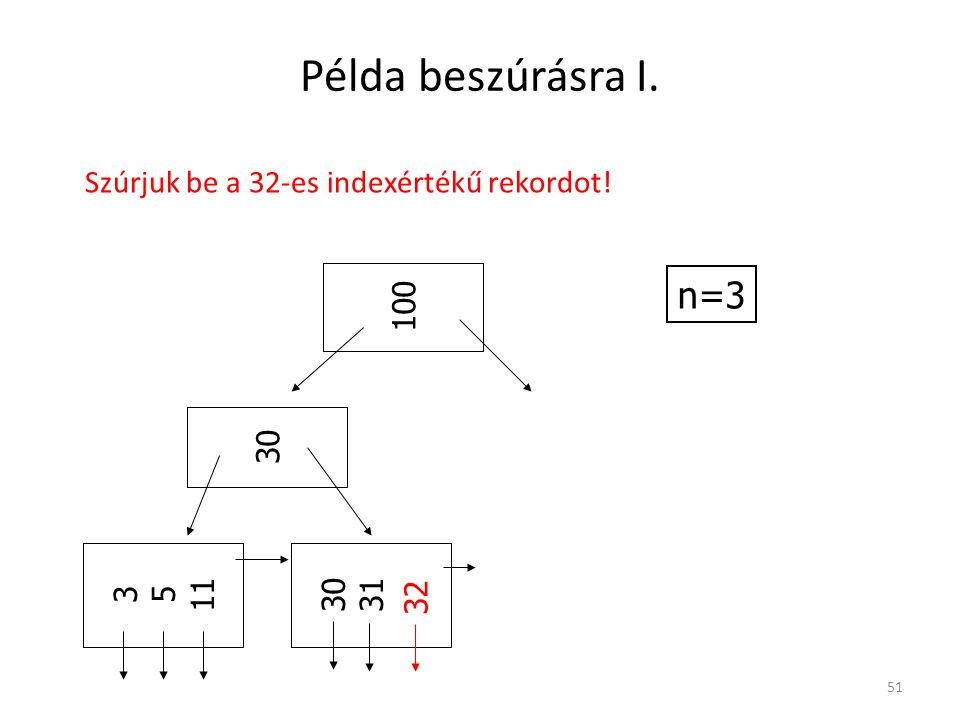
Példa beszúrásra I. n=3 Szúrjuk be a 32-es indexértékű rekordot! 100
30 3 5 11 30 31 32
52
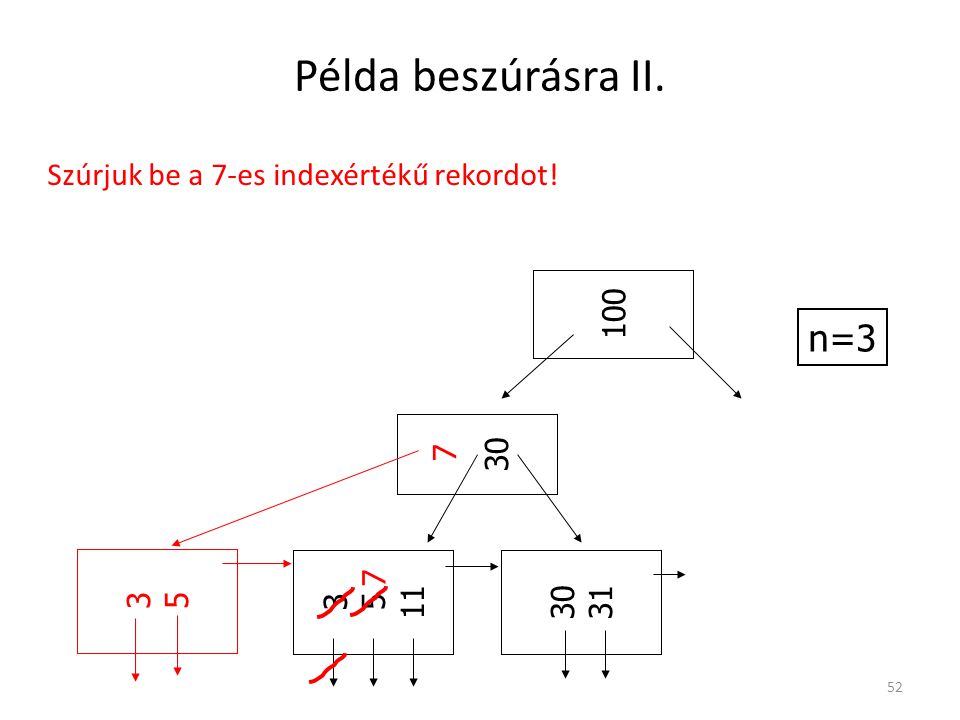
Példa beszúrásra II. n=3 Szúrjuk be a 7-es indexértékű rekordot! 100
30 7 3 5 11 30 31 3 5 7
53
Példa beszúrásra III. n=3 Szúrjuk be a 160-as indexértékű rekordot!
100 160 n=3 120 150 180 180 150 156 179 180 200 160 179

54
Példa beszúrásra IV. n=3 Szúrjuk be a 45-ös indexértékű rekordot! 30
új gyökér n=3 10 20 30 40 1 2 3 10 12 20 25 30 32 40 40 45

55
Törlés Ha a törlés megtörtént az N pontban, és N még mindig megfelelően telített, akkor készen vagyunk. Ha N már nem tartalmazza a szükséges minimum számú kulcsot és mutatót, akkor: ha N valamelyik testvérével összevonható, akkor vonjuk össze. A szülőcsúcsban törlődik ekkor egy elem, s ez további változtatásokat eredményezhet. Ha nem vonható össze, akkor N szomszédos testvérei több kulcsot és mutatót tartalmaznak, mint amennyi a minimumhoz szükséges, akkor egy kulcs-mutató párt áttehetünk N-be. (Baloldali testvér esetén a legutolsó, jobboldali testvér esetén a legelső kulcs-mutató párt.) A változást a szülő csúcson is „regisztrálni kell”.
 A változást a szülő csúcson is „regisztrálni kell .")
56
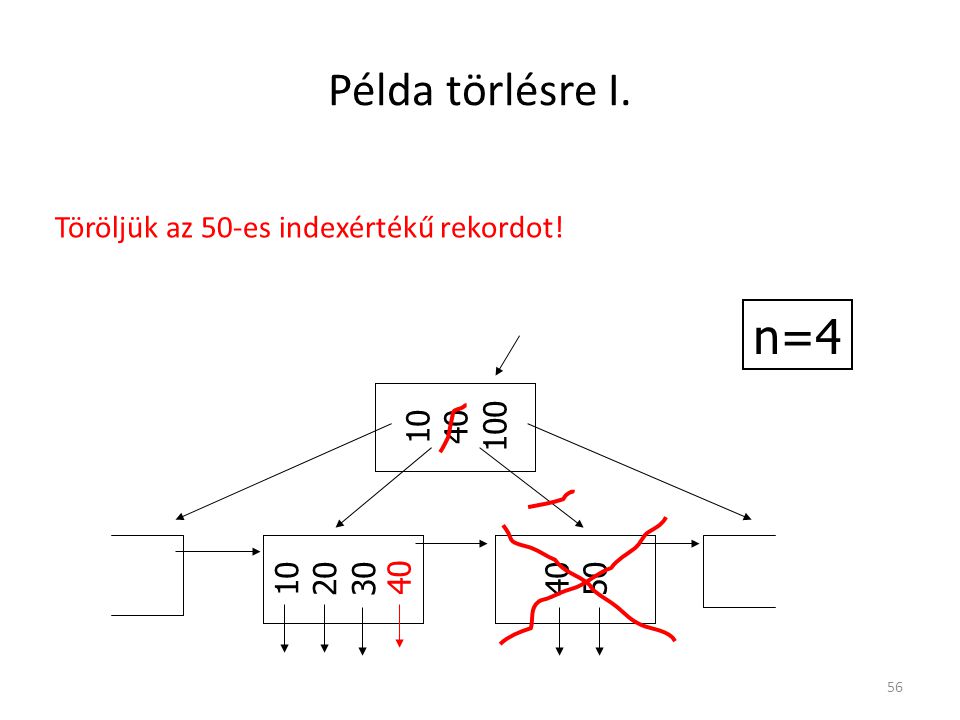
Példa törlésre I. n=4 Töröljük az 50-es indexértékű rekordot! 10 40
100 40 10 20 30 40 50
57
Példák törlésre II. n=4 Töröljük az 50-es indexértékű rekordot! 10 40
100 35 10 20 30 35 40 50
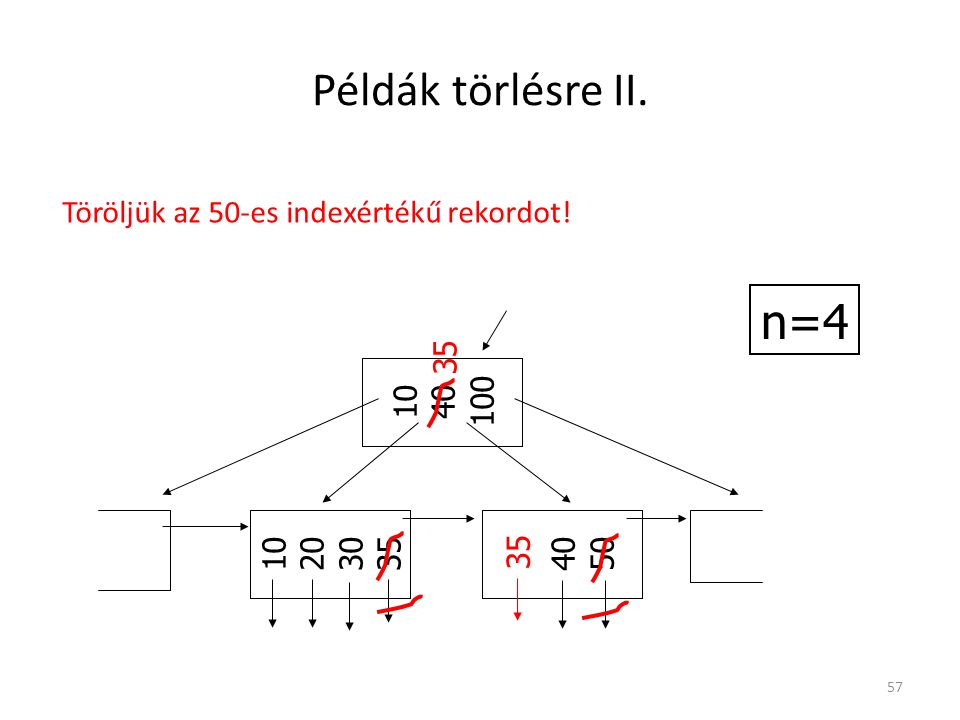
58
Törlés III. n=4 Töröljük a 37-es indexértékű rekordot! 25 25 új gyökér
10 20 30 40 40 30 25 26 1 3 10 14 20 22 30 37 40 45
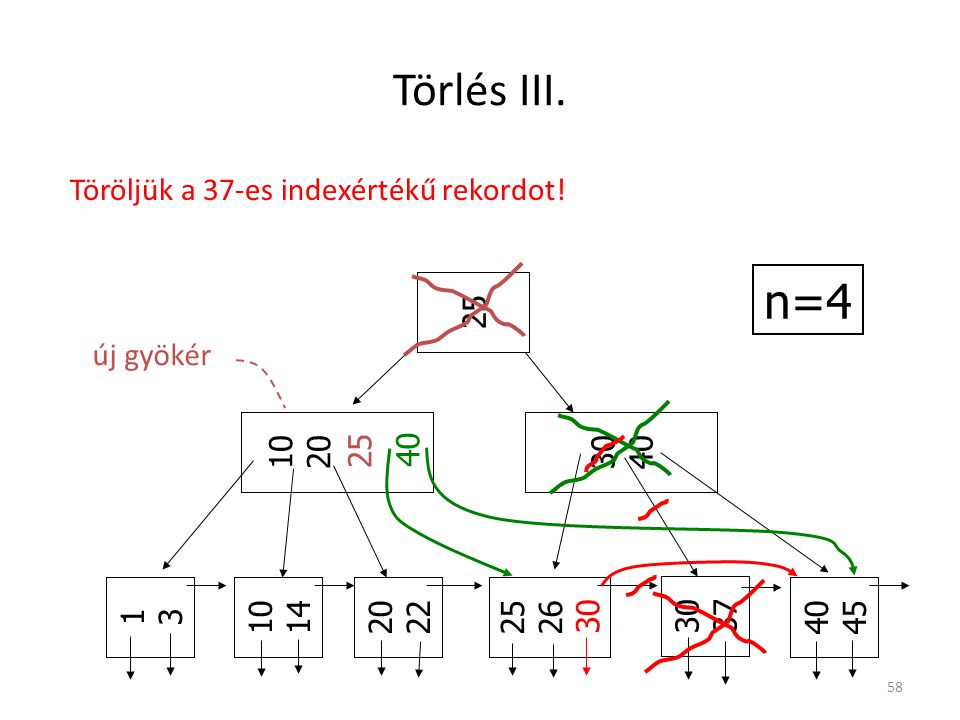
59
Feladat Legyen a rekordok száma , és az indexelt oszlopban minden érték különböző. Sűrű indexre készítünk B-fát. Egy blokkba 10 rekord vagy (99 kulcs és 100 mutató) fér. Legyen a telítettség 70%, azaz legalább 69 kulcs és 70 mutató szerepel az indexblokkban. Mekkora az adatfájl és az index együttes mérete? Mennyi a keresés blokkolvasási költsége?
 fér. Legyen a telítettség 70%, azaz legalább 69 kulcs és 70 mutató szerepel az indexblokkban. Mekkora az adatfájl és az index együttes mérete Mennyi a keresés blokkolvasási költsége")
60
Bitmap indexek Személy név nem kor kereset Péter férfi 57 350000 Dóra
25 30000 Salamon 36 Konrád 21 Erzsébet 20 Zsófia 35 160000 Zsuzsanna érték vektor férfi nő érték vektor 30000 160000 350000

61
Bitmap indexek haszna SELECT COUNT(*) FROM személy
WHERE nem=‘nő’ and kereset = ; AND = , az eredmény: 2. SELECT név WHERE kereset > ; (160000) OR (350000) = , azaz az 1., 3., 6. és 7. rekordokat tartalmazó blokko(ka)t kell beolvasni.
 OR (350000) = , azaz az 1., 3., 6. és 7. rekordokat tartalmazó blokko(ka)t kell beolvasni.")
62
Tömörítés I. Ha a táblában n rekord van, a vizsgált attribútum pedig m különböző értéket vehet fel, ekkor, ha m nagy, a bitmap index túl naggyá is nőhet (n*m méret). Ebben az esetben viszont a bitmap indexben az egyes értékekhez tartozó rekordokban kevés az 1-es. A tömörítési technikák általában csak ezeknek az 1-eseknek a helyét határozzák meg. Tegyük fel, hogy i db 0-t követ egy 1-es. Legegyszerűbb megoldásnak tűnik, ha i-t binárisan kódoljuk. Ám ez a megoldás még nem jó: (a és vektorok kódolása is 111 lenne). Tegyük fel, hogy i binárisan ábrázolva j bitből áll. Ekkor először írjunk le j-1 db 1-est, majd egy 0-t, és csak ez után i bináris kódolását. Példa: a kódolása: , a kódolása:
. Ebben az esetben viszont a bitmap indexben az egyes értékekhez tartozó rekordokban kevés az 1-es. A tömörítési technikák általában csak ezeknek az 1-eseknek a helyét határozzák meg. Tegyük fel, hogy i db 0-t követ egy 1-es. Legegyszerűbb megoldásnak tűnik, ha i-t binárisan kódoljuk. Ám ez a megoldás még nem jó: (a és vektorok kódolása is 111 lenne). Tegyük fel, hogy i binárisan ábrázolva j bitből áll. Ekkor először írjunk le j-1 db 1-est, majd egy 0-t, és csak ez után i bináris kódolását. Példa: a kódolása: , a kódolása:")
63
Tömörítés II. Állítás: a kód így egyértelművé válik.
Tegyük fel, hogy m=n, azaz minden rekordérték különböző a vizsgált attribútumban. Ekkor, mivel a bitmap indexekben n hosszú rekordokról van szó, egy rekord kódolása legfeljebb 2log2n. Az indexet alkotó teljes bitek száma pedig 2nlog2n, n2 helyett.

Hasonló előadás


 Budapest>")












 Láncolt lista File kezelés 1.>")



