Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Számítógépes Nyelvészet – nyelvi adatbázisok és használatuk
Mesterséges Intelligencia előadás

2
Tartalom A számítógépes szövegfeldolgozás célja
Nyelvi adatbázisok szerepe Szófaji kódolás - MSD kódrendszer Korpuszok és a treebank Szófaji egyértelműsítés Főnévi csoportok (NP) felismerés
 felismerés")
3
A Szövegfeldolgozás célja
Nagy mennyiségű elektronikusan tárolt, írott formátumú szöveg feldolgozása (fájlrendszer, adatbázis, web) Alapvetően információkezelési okokból: keresés, dokumentum visszakeresés, indexelés Fejlettebb módszereknél a tárolt információ tömör formában történő összegzése: csak a kívánt információ megjelenítése, kivonatolás, szövegbányászat
 Alapvetően információkezelési okokból: keresés, dokumentum visszakeresés, indexelés. Fejlettebb módszereknél a tárolt információ tömör formában történő összegzése: csak a kívánt információ megjelenítése, kivonatolás, szövegbányászat")
4
Nyelvi adatbázisok I. A nyelvi adatbázisok létrehozásának lehetséges céljai: számítógépes algoritmusok fejlesztése a segítségükkel, tanuló adatbázis, teszt adatbázis, eddig fel nem ismert jelenségek kutatása, a nyelv változásának követése A nyelvi adatbázisok fajtái: gyűjtött szöveg adott forrásból (újság, hírügynökség), lejegyzett szöveg (rádió, parlament), weben halmozódó blog, (hír)portál, jogszabályok gyűjteménye, tematikusan gyűjtött szöveg (gazdasági, jogi, EU, orvosi, stb.) Annotálás: nyelvi jelenségek megjelölése a szövegben. Kiválóan alkalmasak erre a célra az ún. Mark-up (jelölő) nyelvek (HTML, SGML, XML) Annotált nyelvi adatbázisok: szófaji kódolás és egyértelműsítés bemutatására, mondatelemzés bemutatása, információkinyerés bemutatása
, lejegyzett szöveg (rádió, parlament), weben halmozódó blog, (hír)portál, jogszabályok gyűjteménye, tematikusan gyűjtött szöveg (gazdasági, jogi, EU, orvosi, stb.) Annotálás: nyelvi jelenségek megjelölése a szövegben. Kiválóan alkalmasak erre a célra az ún. Mark-up (jelölő) nyelvek (HTML, SGML, XML) Annotált nyelvi adatbázisok: szófaji kódolás és egyértelműsítés bemutatására, mondatelemzés bemutatása, információkinyerés bemutatása")
5
Nyelvi adatbázisok II. Szakszóval korpusznak nevezik az adott célból gyűjtött elektronikus szövegtárakat. A korpusz adott nyelvi jelenségeket magába foglaló, tervezett elrendezésű, elegendően nagy méretű adattár. BNC (British National Corpus, OTA (Oxford Text Archive, Gutenberg project, ETCSL (Electronic Text Corpus of Sumerian Literature, PubMed ( JRC Acquis Corpus (

6
Nyelvi adatbázisok III.
Magyar szövegtárak MTSZ (Magyar Történelmi Szövegtár DIA (Digitális Irodalmi Akadémia, MEK (Magyar Elektronikus Könyvtár, Szószablya ( eMagyarország ( Parlament ( Újságok (

7
Nyelvi adatbázisok IV. Számítógépes nyelvészeti adatbázisok LDC (Linguistic Data Consortium, ELRA (European Language Resources Association, MNSZ (Magyar Nemzeti Szövegtár, Szeged Korpusz (

8
Nyelvi adatbázisok IV. A nyelvi adatbázisok létrehozásának lehetséges céljai: számítógépes algoritmusok fejlesztése a segítségükkel, tanuló adatbázis, teszt adatbázis, eddig fel nem ismert jelenségek kutatása, a nyelv változásának követése A nyelvi adatbázisok fajtái: gyűjtött szöveg adott forrásból (újság, hírügynökség), lejegyzett szöveg (rádió, parlament), weben halmozódó blog, (hír)portál, jogszabályok gyűjteménye, tematikusan gyűjtött szöveg (gazdasági, jogi, EU, orvosi, stb.) Annotálás: nyelvi jelenségek megjelölése a szövegben. Kiválóan alkalmasak erre a célra az ún. Mark-up (jelölő) nyelvek (HTML, SGML, XML) Annotált nyelvi adatbázisok: szófaji kódolás és egyértelműsítés bemutatására, mondatelemzés bemutatása, információkinyerés bemutatása
, lejegyzett szöveg (rádió, parlament), weben halmozódó blog, (hír)portál, jogszabályok gyűjteménye, tematikusan gyűjtött szöveg (gazdasági, jogi, EU, orvosi, stb.) Annotálás: nyelvi jelenségek megjelölése a szövegben. Kiválóan alkalmasak erre a célra az ún. Mark-up (jelölő) nyelvek (HTML, SGML, XML) Annotált nyelvi adatbázisok: szófaji kódolás és egyértelműsítés bemutatására, mondatelemzés bemutatása, információkinyerés bemutatása")
9
Szófaji kódolás Multext-East EU projekt ( A morfoszintaktikai leírás (MorphoSyntactic Description = MSD) magyar nyelvre alkalmazható változata Jellemzői: Az MSD-kódolásban a tulajdonságok kódolása egy adott pozíción történik Az értékek egyetlen karakterrel vannak kódolva
 magyar nyelvre alkalmazható változata. Jellemzői: Az MSD-kódolásban a tulajdonságok kódolása egy adott pozíción történik. Az értékek egyetlen karakterrel vannak kódolva")
10
MSD kódrendszer Példa: Főnevek (Noun) – N
asztalt: MSD=Nc-sa, Gábornak : MSD=Np-sg vagy MSD=Np-sd Pozíció Attribútum Lehetséges értékek Kód Toldalékok (jelek, ragok) Példa 2 Típus köznév (common) tulajdonnév (proper) c p 3 Nem - 4 Szám egyes (singular) többes (plural) s p Ø -k; -i, -ai/-ei, -jai/-jei; -ék asztal(om) asztalok, asztalaim szomszédék 5 Eset alany (nominative) tárgy (accusative) birtokos (genitive) részes (dative) n a g d Ø -t Ø, -nak/-nek -nak/-nek asztal(om) asztal(oma)t asztalnak asztalnak
 Példa. 2. Típus. köznév (common) tulajdonnév (proper) c p. 3. Nem Szám. egyes (singular) többes (plural) s p. Ø -k; -i, -ai/-ei, -jai/-jei; -ék. asztal(om) asztalok, asztalaim szomszédék. 5. Eset. alany (nominative) tárgy (accusative) birtokos (genitive) részes (dative) n a g d. Ø -t Ø, -nak/-nek -nak/-nek. asztal(om) asztal(oma)t asztalnak asztalnak")
11
MSD kódrendszer Példa: Igék (Verb) – V
foglalnának: Vmcp3p Pozíció Attribútum Lehetséges értékek Kód Toldalékok (jelek, ragok) Példa 2 Típus fő (main) segéd (auxiliary) m a fog 3 Mód/forma kijelentő (indicative) felszólító (imperative) feltételes (conditional) főnévi igenév (infinitive) i m c n Ø -j, -jj, -gy, -ggy -(n)na/-(n)ne, -ana/-ene -ni 4 Idő jelen (present) múlt (past) p s -t/-tt/-ott/-ett 5 Személy első (1) második (2) harmadik (3) 1 2 3 várok vársz vár
 Példa. 2. Típus. fő (main) segéd (auxiliary) m a. fog. 3. Mód/forma. kijelentő (indicative) felszólító (imperative) feltételes (conditional) főnévi igenév (infinitive) i. m. c. n. Ø. -j, -jj, -gy, -ggy. -(n)na/-(n)ne, -ana/-ene. -ni. 4. Idő. jelen (present) múlt (past) p s. -t/-tt/-ott/-ett. 5. Személy. első (1) második (2) harmadik (3) várok vársz vár")
12
A Szintaxis modellezése
Frázis struktúra (ágrajz) A kötetlen szórend miatt a magyar nyelvben ez nehézséget okoz. A mondatrészek nem minden esetben rendezhetők fába. Dependencia struktúra (függőségi fa) Minden szónak van egy hierarchiában felette álló őse. Az egész mondat felett áll egy virtuális ROOT (gyökér) csomópont, ami alá tartoznak a mondat szavai. Lazább szerkezet,
 A kötetlen szórend miatt a magyar nyelvben ez nehézséget okoz. A mondatrészek nem minden esetben rendezhetők fába. Dependencia struktúra (függőségi fa) Minden szónak van egy hierarchiában felette álló őse. Az egész mondat felett áll egy virtuális ROOT (gyökér) csomópont, ami alá tartoznak a mondat szavai. Lazább szerkezet,")
13
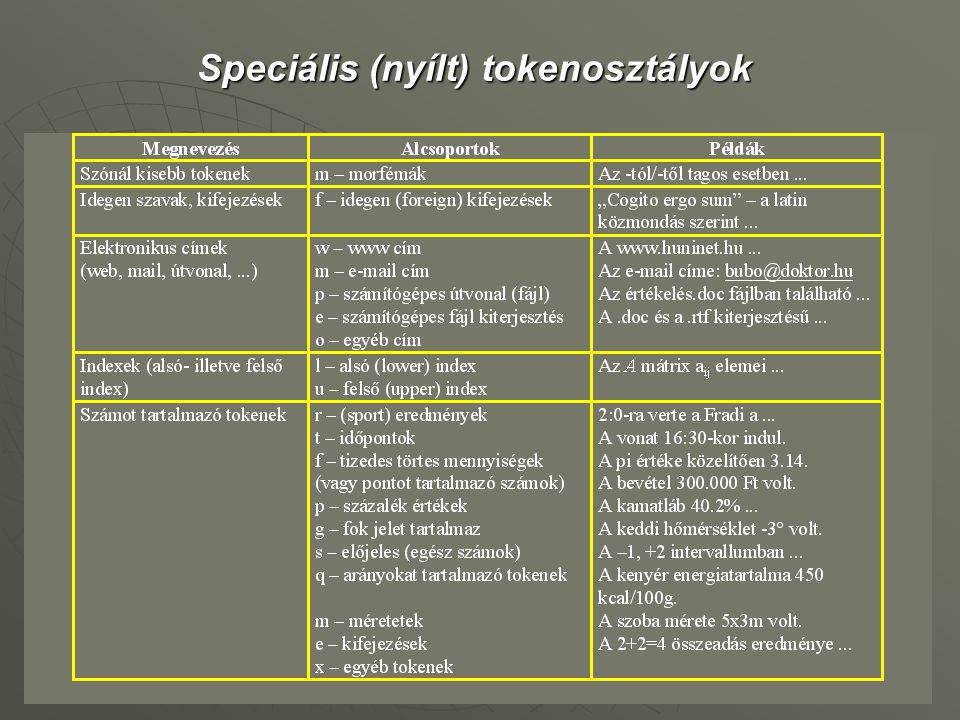
Speciális (nyílt) tokenosztályok
14
Tulajdonnevek Az alábbi fontosabb csoportok automatikus felismerésére készül egy szabályrendszer a CLaRK (ingyenes) XML alapú korpusz fejlesztő eszközzel. A cél: automatikus tulajdonnév felismerő rendszer készítése. személynevek (a kereszt és vezetéknevek adatbázisát felhasználva, az id. ifj. özv. dr. prof. asszonynév (-né), ... képzési formákat cégnevek (akroním, hosszú név, tevékenység, cégforma [rt. kft. bt.]). Intézmények (iskola, gimnázium, főiskola, egyetem, intézet, minisztérium, hivatal, ...) földrajzi nevek (ismert nevek, továbbá az utca, út, dülő, patak, hegy, domb, falu, rét, ösvény, fasor, ... egyéb tulajdonnevek
 XML alapú korpusz fejlesztő eszközzel. A cél: automatikus tulajdonnév felismerő rendszer készítése. személynevek (a kereszt és vezetéknevek adatbázisát felhasználva, az id. ifj. özv. dr. prof. asszonynév (-né), ... képzési formákat. cégnevek (akroním, hosszú név, tevékenység, cégforma [rt. kft. bt.]). Intézmények (iskola, gimnázium, főiskola, egyetem, intézet, minisztérium, hivatal, ...) földrajzi nevek (ismert nevek, továbbá az utca, út, dülő, patak, hegy, domb, falu, rét, ösvény, fasor, ... egyéb tulajdonnevek.")
16
Annotáció Többszintű NP struktúrák jelölése <NP> és </NP>
A tagmondatok jelölése <CP> tagekkel A nem egyértelmű annotáció jele <XP comment=„”> Részletes útmutató alapján dolgozó annotátorok Egy fájlt 2 személy egymástól függetlenül annotált

17
Az NP (névszói szerkezet) annotálásának fontosabb alapelvei
Egy névszói szerkezet alapvetően egy (ragozott) főnévből és az előtte álló bővítményekből áll. A névszói szerkezetek lehetnek egymásba ágyazottak, de a belső névszói szerkezet teljes egészében benne van az őt tartalmazó névszói szerkezetben. A főnév bővítményei a névelő, számnevek és a jelzők. A főnév után álló névutó, határozószó már nem része a főnévhez tartozó névszói szerkezetnek.
 főnévből és az előtte álló bővítményekből áll. A névszói szerkezetek lehetnek egymásba ágyazottak, de a belső névszói szerkezet teljes egészében benne van az őt tartalmazó névszói szerkezetben. A főnév bővítményei a névelő, számnevek és a jelzők. A főnév után álló névutó, határozószó már nem része a főnévhez tartozó névszói szerkezetnek.")
18
Egy NP-szerkezet ágrajza
NP NP NP Ritkán vette (tudomásul) {[(az ablak) előtt ülő asszony] jelenlétét} .
 {[(az ablak) előtt ülő asszony] jelenlétét}")
19
Az NP-annotált szövegrészlet vázlata
1 Ritkán 2 vette <NP> 3 tudomásul </NP> 4 az 5 ablak 6 előtt 7 ülő 8 asszony 9 jelenlétét 10 .

20
Az gazdagított szerkezet ágrajza
ADVP V’ NP* NP** HEAD CHILDREN NP v NODE NODE ADJP NP* NP** PP NP Ritkán vette (tudomásul) {[(az ablak) előtt ülő asszony] jelenlétét} .
 {[(az ablak) előtt ülő asszony] jelenlétét}")
21
A gazdagított annotálás XML-struktúrája
<ADVP> 1 Ritkán </ADVP> <V'> <HEAD VERB_INDEX="#8875"> <V> 2 vette </V> </HEAD> <CHILDREN> <NODE ARGS=„3" type="NP"/> <NODE ARGS=„ " type="NP"/> </CHILDREN> </V'> <NP> 3 tudomásul </NP> <ADJP> <PP> 4,5 az ablak 6 előtt </PP> 7 ülő </ADJP> 8 asszony 9 jelenlétét 10 .

Hasonló előadás






HTML.>")







,>")




