Előadást letölteni
1
Korpusznyelvészet és releváns társterületeik Pintér Tibor

2
1. Korpuszok és társterületeik 2. A korpusznyelvészet és szociolingvisztika releváns érintkezési területei 3. A korpusznyelvészet és lexikográfia releváns érintkezési területei 5. EFNILEX-szótárak 6. Korpusznyelvészet és a saját kutatási téma közös vetületei 2016. 11. 14.2

3
Korpuszok és társterületeik Felhasználásuk a korpuszok fejlettségétől függ. kézzel készített korpuszok számítógépes korpuszok Annotáltság mértéke morfológia Szintaxis szemantika ?? corpus design (nem, kor, nyelvváltozatok stb.) 2016. 11. 14.3
")
4
Alapvetően a következő társterületek fontosak: Nyelvtörténet (19. század) diakrón változások egy nyelv (HHC) két nyelv (grimm-törvény bizonyítása) Nyelvtanírás (19. század) morfológia, szintaxis (gyakoriság) Somorjába ~ Somorjára, vonzatok, valencia a gyakori a jobb?? Google-helyesírás 2016. 11. 14.4
 diakrón változások egy nyelv (HHC) két nyelv (grimm-törvény bizonyítása) Nyelvtanírás (19. század) morfológia, szintaxis (gyakoriság) Somorjába ~ Somorjára, vonzatok, valencia a gyakori a jobb . Google-helyesírás")
5
Lexikográfia (lexikológia) regiszter, stílus, változatok fecstej (1; 1412764) fn föcstej Mezőg Tehénnek a borjazás utáni első, sűrű teje. | ritk Előtej. [« feccsen+tej] (ÉKSz 2 ) Oxford English Dictionary KWIC-konkordanciák Osiris Helyesírás – gyakoriság egy- és kétnyelvű szótárak (EFNILEX) 2016. 11. 14.5
 Oxford English Dictionary KWIC-konkordanciák Osiris Helyesírás – gyakoriság egy- és kétnyelvű szótárak (EFNILEX)")
6
Szociolingvisztika változatok minden szinten (annotációtól függ a kutatás tárgya) nyelvváltozatok (MNSz – mo~ht, regiszerek) gendernyelvészet szinkrónia ~ diakrónia diakrónia = ≠ nyelvtörténet 2016. 11. 14.6

7
Pszicholingvisztika 20. század – gyermeknyelv, nyelvelsajátítás idegennyelv-elsajátítás affáziakutatás Számítógépes nyelvészet NLP-alkalmazások fejlesztése gépi fordítás tanulókorpuszok párhuzamos koruszok – szövegszintű egyeztetés (alignment) 2016. 11. 14.7
")
8
A korpusznyelvészet és szociolingvisztika relaváns érintkezsi területei A (kvantitatív) szociolingvisztika alapelve az adatorientáltság, így elkerülhetetlenek a korpuszok. Első szociolingvisztikai céllal készüt koruszokat rég a számítógépes korpuszok előtt használták. 2016. 11. 14.8

9
Korpuszok használatának célja a szociolingvisztikában: változók változatainak keresése szociális státusz, nem, kor, nyelvváltozat, stílus, etnicitás (angol nyelvterület) saját korpus ~ közös korpusz 2016. 11. 14.9

10
Általában saját korpusz használatának előnyben részesítése a meglévők előtt. saját kutatási célra készített korpusz Bár általában azonosak a keresés paraméterei: szociális státusz, iskolázottság, nem, kor, nyelvváltozat, stílus, etnicitás (angol nyelvterület) Keresett fenomenon: szó, szókapcsolat, diskurzus, diskurzusjelölő 2016. 11. 14.10
 Keresett fenomenon: szó, szókapcsolat, diskurzus, diskurzusjelölő")
11
fő cél a beszélt nyelvi korpusz a leírt szövegekből könnyen lehet mennyiségi mutatót készíteni XML-annotáció bármi kódolható, az látszik, amit akarunk, könnyen kereshető, lekérdezhető 2016. 11. 14.11

12
Magyar nemzeti szövegtár struktúrája: regiszterek: publicisztikai szépirodalmi hivatalos nyelvi tudományos „élőnyelvi” területi nyelvváltozat: hu, er, fv, ka, va ??mv, őv, dr 2016. 11. 14.12

13
Korlátok, korlátozások mindent azért nem lehet. Miért? 1. a korpuszok általában a nyelv írott változatait dolgozzák fel, és standardközpontúak. Elsősorban grammatikai és lexikológiai kutatásokat segítenek. 2. a korpuszok általában azokat a fontos információkat nem tartalmazzák, amire a szociolingvistának szüksége van státusz, kor, iskolázottság, nem stb. 2016. 11. 14.13

14
A korpusznyelvészet és lexikográfia releváns érintkezési területei A mai szótárak készítésénél elképzelhetetlen a korpusz használata. 1.kvalitatív és kvantitatív bizonyítás 2.címszóválasztás 3.korpuszkezelő eszközök 2016. 11. 14.14

15
A korpuszok használata különbözik/különbözhet szótártípusonként: kommunikáció-orientált szótárak általános korpusz tudásorientált szótárak speciális korpusz A korpusz kiválasztásánál szükséges ismerni a szótár célközönségének kívánalmait. 2016. 11. 14.15

16
Ezek befolyásolják a korpusz kiválasztását milyen típusú szövegek kellenek egyéb kritériumok: autenticitás, kiegyensúlyozottság, adatgyűjtés módszere, reprezentativitás (??) a kinyert adatok formáját (címszó + jelentések + grammatikai információ) 2016. 11. 14.16

17
Mekkora korpusz kell a lexikográfusoknak? Den Danske Odbog – 68 millió token Digitales Wörterbuch der deutschen Sprache – 1000 millió token Magyar értelmező kéziszótár – 187 millió token A magyar nyelv nagyszótára – 400 millió token BNC (British National Corpus) – 100 millió token Käding, F. W. (1897), Häufigkeitswörterbuch der deutschen Sprache. Berlin: Privately published. – 11 millió token (80 ember gyűjtése) 2016. 11. 14.17
 – 100 millió token Käding, F. W. (1897), Häufigkeitswörterbuch der deutschen Sprache. Berlin: Privately published. – 11 millió token (80 ember gyűjtése)")
18
Korpusz kihasználása: a szótár címszavainak nem szabadna a korpuszban 5-nél kevesebbszer előfordulni (kicsit sántít az összehasonlítás, mert nem volt korpusz, sok benne a nyelvjárási szó) Éksz 2 (MNSZ) 0: 4684 1: 2639 2: 1997 3: 1679 4: 1469 5: 1268 2016. 11. 14.18

19
Korpusz kihasználása: egy 50 000 – 60 000 címszavas szótárhoz 60 – 100 millió szavas korpusz elég Éksz 2 : MNSZ = 76 000: 187 000 000 Speciális szótárak: 1-2 ezer vagy pár száz címszó Ezért fontos a megfelelő célkorpusz kiválasztása. 2016. 11. 14.19

20
Kétnyelvű szótárak: párhuzamos korpuszok Valóban jók? pontos párhuzamosítás – általában mondatszinten, utána szószinten Valóban jók? a fordítás általában egy vagy kevés számú fordítóhoz kötött a fordítás milyenségét befolyásolja a kontextus 2016. 11. 14.20

21
Internet mint potencionális adatforrás: két fő probléma: nem megfelelő minőség kevés és rendszertelen metaadat szövegek inkonzisztenciája sok az ismétlés, redundancia, más szövegek idézése 2016. 11. 14.21

22
Címszó kiválasztása: gyakori indok, hogy a friss szóanyagot feldolgozó korpusz friss címszólistát ad felkapott lekszikográfiai reklámfogás az új szavak és divatszavak felvétele Gyakoriság a címszóválasztásnál: így viszont a divatszók nem találhatók meg 2016. 11. 14.22

23
Fontos, hogy a gyakorisági mutatók mellett egyéb metaadatokat is tartalmaznak: pl. stílus, regiszter, megjelenés ideje, szerző A gyakorisági listát óvatosan kell kezelni: figyelni kell a betűk proporcionális megoszlására (szófajokéra is) nem kezeli tisztességesen a hominímiát (poliszémiát sem) csak egy-egy szóra ad választ, általában nem kezeli a szintaktikai egységeket (vonzatok) 2016. 11. 14.23
 nem kezeli tisztességesen a hominímiát (poliszémiát sem) csak egy-egy szóra ad választ, általában nem kezeli a szintaktikai egységeket (vonzatok)")
24
Viszont segít a peldamondatok kiválasztásánál: teljes átvétel módosítás értelmezőszótár? Éksz 2 ? A magyar nyelv nagyszótára? kétnyelvű szótárak? Irodalmi vs. köznyelvi példák 2016. 11. 14.24

25
Korpuszeszközök a lexikográfiában gyakorisági listák konkordanciakészítők kontextus metaadatok (találatokéi) Amit az eszközöknek minimálisan tudni kell: tokenizálás (szó- és mondathatárok felismerése) tövesítés szófajosítás (part-of-speech tagging) 2016. 11. 14.25

26
Konkordanciák: általában korpuszonként változik, hogy mire lehet keresni (keresési opciók) fontos, hogy a gyakorisági listák mellett a metaadatokat is közöljék XML + reguláris kifejezések.?*\/^ 2016. 11. 14.26

27
2016. 11. 14.27

28
2016. 11. 14.28
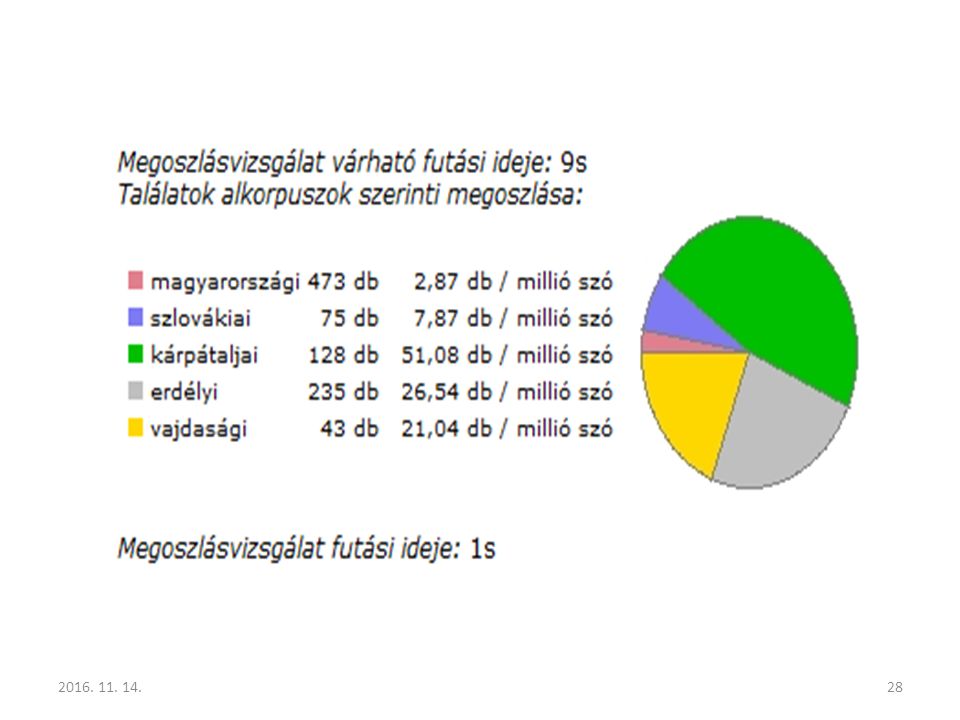
29
Korpusznyelvészet profitálása a lexikográfiából: NLP – nyelvtanok és szótárak felhasználása szófajok annotálása, vonzatkeresés 2016. 11. 14.29

30
2016. 11. 14.30

31
2016. 11. 14.31
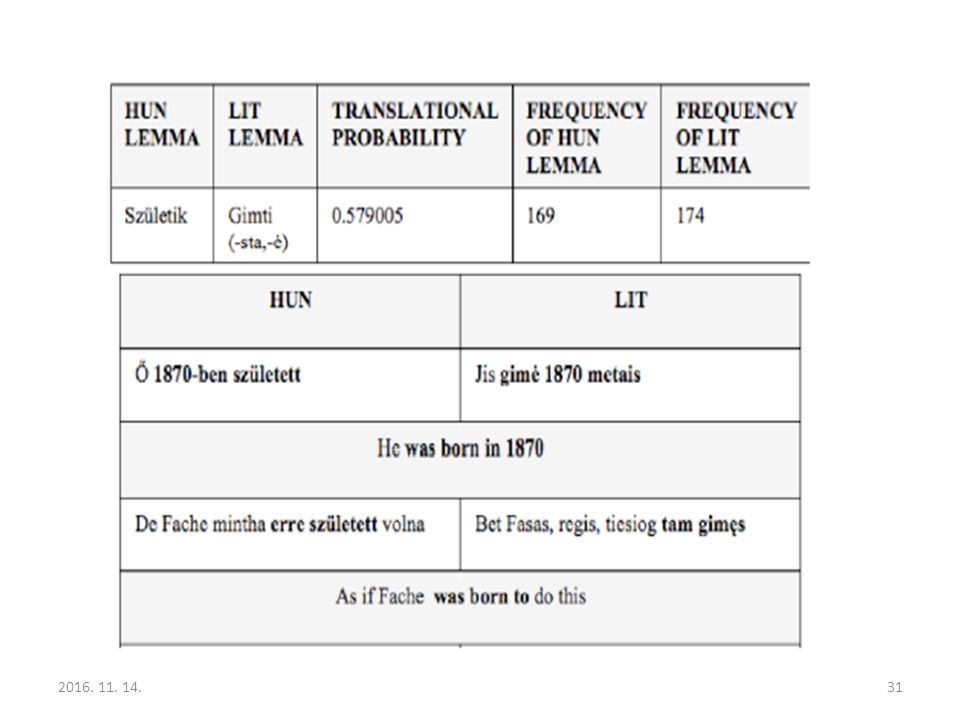
32
2016. 11. 14.32
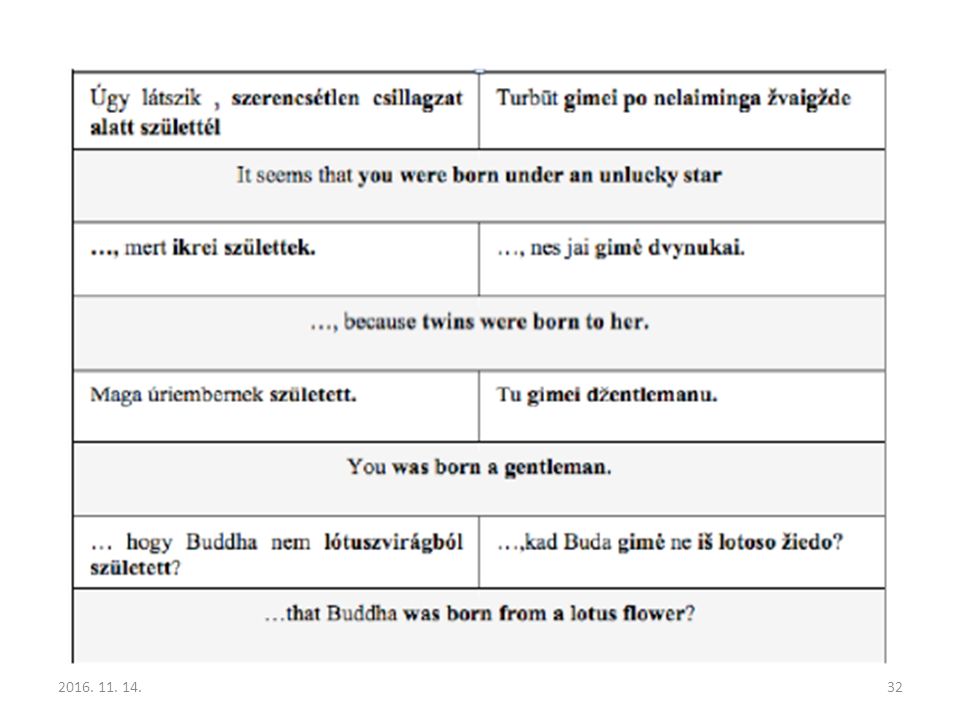
33
Magyar nemzeti szövegtár corpus.nytud.hu/mnsz Termini magyar-magyar szótár ht.nytud.hu/htonline 2016. 11. 14.33

34
Kutatási téma? Kérdések? 2016. 11. 14.34





















