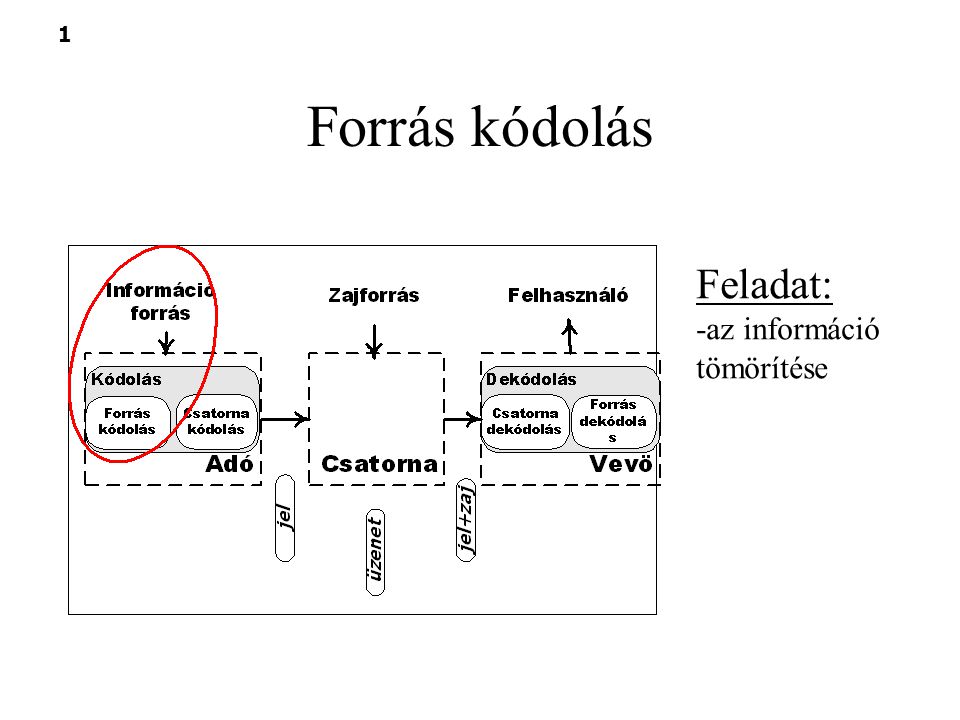
Forrás kódolás Feladat: -az információ tömörítése
Tömörítés Veszteségmentes (entrópia) kódolás Veszteséges Sorozathossz kódolás (Run Lengh Encoding , RLE). Statisztikai kódolás (szótár alapú) Huffman LZW Aritmetikai Prediktív kódolás (veszteség mentes verzió) Veszteséges
Redundancia tipusok Térbeli redundancia a szomszédos pixelek körötti korreláció következtében Spektrális redundancia a különböző szín-síkok, vagy spektrum sávok közötti korreláció következtében Időbeni redundancia az egymást követő frame-ek közötti korreláció következtében
Veszteséges kódolási technikák Blokk csonkolásos kódolás Veszteséges prediktiv kódolás DPAM ADPCM Delta modulation Transformációs kódolás DFT DCT Haar Hadamard Subband kódolás Subbands Wavelets Fractal kódolás Vector kvantálás
Szimmetrikus Aszimmetrikus A kompresszió és a dekompresszió nagyjából azonos idő és erőforrás igényű. Az adatátviteli feladatoknál szokásos, ahol a tömörítés-kitömörítés menetközben történik. Aszimmetrikus Leggyakoribb olyan esetekben, mikor a kódolás többszörösen időigényesebb, mint a dekódolás
- Nem adaptiv Adaptiv Szemi-adaptiv Statikus, előre megadott szótárat tartalmaz a gyakran előforduló kódsorozat részekre. Adaptiv A szótár építés menet közben történik. Szemi-adaptiv Az első menetben felépít egy optimális szótárat Az második menetben megtörténik a tömörítés.
Sorozathossz kódolás (Run Lengh Encoding , RLE). Ismétlődő jelsorozatokat helyettesít (jel, szám) formátumú számkettősökkel (tuple) pl. aaaaazz kódolva (a,5) (z,2) U.n. „horizontális” jelsorozatok esetén kedvező
Huffman kódolás A jelek előfordulási gyakoriságán alapszik Kód-könyv A gyakrabban előforduló információ kódolásához kevesebb bitet használ A kódokat „kód-könyvben” tárolja Kód-könyv minden adathalmazra (képre) újra létrehozza Átvitelre kerül a kódolt adathalmazzal együtt a vevő oldalra
Huffman kódolás Rendezzük az elemeket az előfordulásuk valószínűségeik (gyakoriságaik) sorrendjében. A két legvalószínűtlenebb szimbólumból együttes (szülő) szimbólumot képezünk és ezt beírjuk az eredeti szimbólumok közé a valószínűségi sorba. Az új (szülő) szimbólum valószínűsége egyenlő a két (gyermek) szimbólum valószínűségeinek összegével. A 2-es eljárást addig ismételjük míg két elemű nem lesz a forrás. Ekkor az egyik elemhez 1-et a másikhoz 0-t rendeljük. Visszatérünk az előző összevont szimbólumhoz. A nagyobb valószínűségűhöz 1-et, a kisebb valószínűségű szimbólumhoz 0-t rendelünk. Az eljárást addig ismételjük, amíg vissza nem jutunk az eredeti legkisebb valószínűségű szimbólumig.
Huffman kódolás A szimbólumok a bináris fa levelei lesznek a b c d e gyakoriság 19 10 8 5 A szimbólumok a bináris fa levelei lesznek a b c d e Csökkenő gyakoriság szerit rendezve Kapcsold a kisebb gyakoriság az ágakat d e 8 5 13
Huffman kódolás = 1 1 1 1 a e d c b 50 Szimbolum Huffman kód a b 111 c 1 Szimbolum Huffman kód a b 111 c 110 d 101 e 100 31 = 1 13 18 1 1 a e d c b
Huffman kód A tömöritési arány mindig nagyobb mint 1.0 bit/minta A kód előre tervezett Kötött kódtábla Ha a valószinüségek eltérnek a tervezés során felvettektől, akkor adat kiterjedés is felléphet. Gyakorlati megvalósítások:– két menetes implementáció Blokk adaptiv (kód tábla adat blokkonként) Rekurziv Huffman (a kód tábla folyamatosan változik)
Lempel-Ziv-Welch (LZW) szótár alapú kódolás Az algoritmus része a kódtábla építés, a kódtáblát a tömörítés közben állítja elő. minden új bitsorozatot felvesz a kódtáblába A dekódoláshoz nem szükséges a kódtábla megléte Használja: GIF, TIFF, V.42bis modem tömörítési szabvány, PostScript Level 2
Lempel-Ziv kódolás algoritmusa Inicializálás: a szótár fel van töltve az összes alap szimbólummal, W üres. 2. K a kódolandó üzenet következő karaktere. 3. A W+K jelsorozat megvan már a szótárban ? a./ igen, W := W+K (W –t egészíts ki K -val); b./ nem Add a kimenő üzenethez a W-hez rendelt kódot; vedd fel a szótárba a W+K jelsorozat; W := K (W most csak a K karaktert tartalmazza); c./ van még kódolandó karakter ? Ha igen, kezeld le (lásd 2. Pont); Ha nincs több: Add a kimenő üzenethez a W-hez rendelt kódot ;
Lempel-Ziv kódolás példa Lempel-Ziv kódolás példa A jelkészlet :{A,B,C} Az üzenet:[ABABAAA] A következő karakter Az ABLAK tartalma Ismert ? Szótár Kimenet Új ABLAK tartalom Inicializálás [] #1 = ’A’ #2 = ‘B’ #3 = ‘C’ Iteráció A [A] Igen (#1) B [AB] nem #4 = ‘AB’ #1 [B] [BA] #5 = ‘BA’ #2 igen (#4) [ABA] #6 = ‘ABA’ #4 [AA] #7 = ‘AA’ igen (#7) Vége üres #7
