Adattárházak 2011.11.26. Láng András
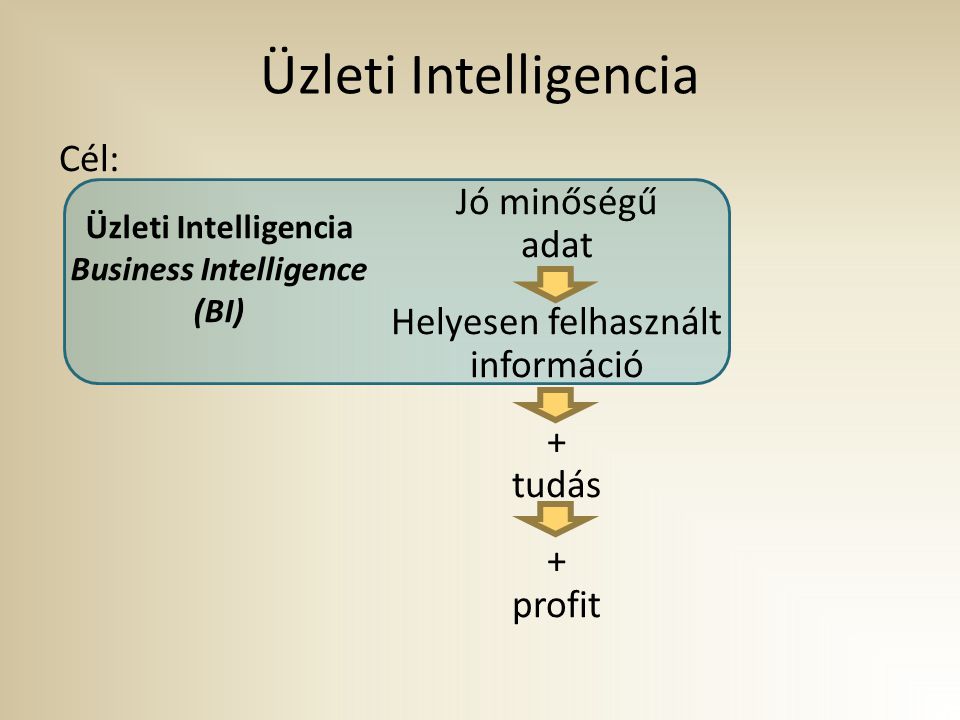
Business Intelligence (BI) Üzleti Intelligencia Cél: Jó minőségű adat Helyesen felhasznált információ + tudás profit Üzleti Intelligencia Business Intelligence (BI) A vállalati informatika akkor tud hatékonyan működni és a profitabilitást támogatni, ha a különböző informatikai rendszerekben lévő kulcsfontosságú adatok jó minőségűek, tisztaságuk megfelelő szintű a rendszerekből kinyert információkat helyesen (egyértelműen, konzekvensen, koherensen) használják fel ezért is célszerű adattárházat alkalmazni Az Üzleti Intelligencia olyan terület, amely a közepes méretű, illetve a nagyvállalatok működésében egyre nagyobb szerepet kap. Feladatköre sokrétűsége révén általában külön részlegként működik, a szervezeti felépítésben az IT egységek között foglal helyet. Sok esetben más a megnevezése ( pl. Üzleti Intelligencia Osztály helyett Adatvagyon Menedzsment Osztály)
Üzleti Intelligencia Adatvagyon menedzsment Adatminőség konszolidáció, adattisztítás Adatleltár adatkatalógusok, metaadat-kezelés Törzsadatok MDM, egyéb törzsadat nyilvántartások Központi riportfejlesztés és riportmenedzsment Adattárházból integrált, historikus forrásból Más rendszerekből forrásrendszerből, adatbázis linken keresztül Törzsadat mulplikátumok felderítése, számuk csökkentése Adatpótlás, helyesbítés érvényes adatokkal Zajok kiszűrése Technikai és üzleti metaadatok nyilvántartása Off-line, on-line metaadat karbantartás Törzsadat-kezelés (Master Data Management) Pl. Központ Ügyféltörzs Pl. címadatszótárak, cégnyilvántartások Az Üzleti Intelligencia terület feladatai lehetnek az alábbiak: Adatvagyon menedzsment: az üzleti felhasználás tekintetében jelentős adatok minőségének szabályozása (technikai adat: belső rendszeradat (pl. szekvencia, belső kulcs); üzleti adat (pl. ügyfél címe, termék megnevezése, fiókkód) Adatminőség menedzsment: az üzleti adatok egy részének konszolidációja illetve automatikus (algoritmizálható, így kötegelt) vagy manuális (nem algoritmizálható, így egyenkénti) adattisztítás (pl. az ügyfél-törzsadatoké), (preventív, detektív kontrollok; örökölt rossz adatok) Adatleltár bevezetése és karbantartása: egyes rendszerek adatkatalógusának és metaadat-kezelés kialakítása és naprakészen tartása Adatkatalógus: technikai (sémanév, adattípus, megszorítás, kitöltöttség stb.) és üzleti (üzleti objektum, üzleti felelős, felhasználó, stb.) leíró adatok rendszerszinten, modulszinten - sémaszinten, objektum (tábla, nézet, stb.) szinten és mezőszinten egy nyilvántartásban Metaadat-kezelés: off-line – adatkatalógusok manuális frissítésével, on-line – állandó rendszerkapcsolat segítségével automatikusan frissülő Törzsadat-kezelés: külön integrált törzsadat-kezelő rendszer(ek), különböző adatszótárok alkalmazása egyénileg vagy hozzáillesztve Központi riportfejlesztés: a BI elsődleges alapfeladata, ami szinte minden nagyobb szervezetben szokásos Adattárház menedzsment: fejlesztés, fejlesztések szervezése, rendelkezésre állás biztosításának támogatása Riportolás egyéb rendszerekből: a feladatkör ua. mint az előbbinél, a felhasznált rendszerek: alaprendszerek, riportkészítő alkalmazások (pl. Cognos, Business Object)
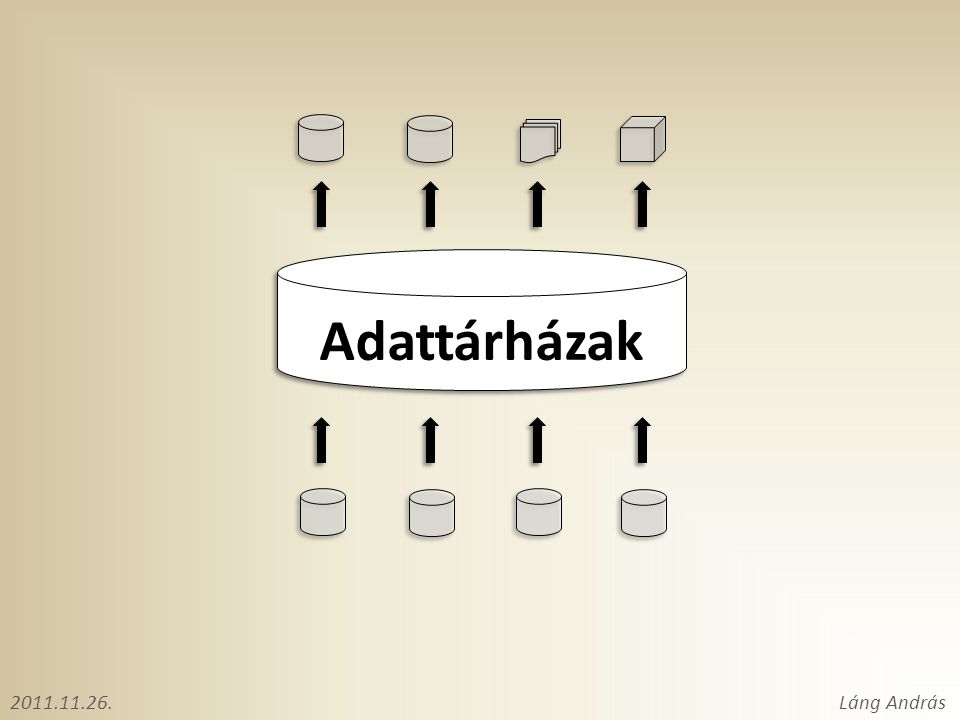
Adattárházak létjogosultsága Egymástól elszigetelt rendszerek Lekérdezés csak az adott rendszer adataira készíthető Operatív rendszerek Általában csak aktuális adatok Normalizált struktúrák Adattárház Integrált Historikus Denormalizált adatszerkezet Miért érdemes adattárházat működtetni? Habár jellemzően létezik egy (vagy több) központi rendszer, és az üzleti folyamatok optimalizálása érdekében a többi rendszer egy része össze van kötve ezzel, mégis kijelenthető, hogy az egyes rendszerek rendelkeznek olyan adatokkal, amelyek bizonyos szempontból kulcsfontosságúak, de csak az adott rendszerben vannak eltárolva, ezért ezek az adatok csak az adott rendszerből kérdezhetők le. Az operatív rendszerek habár eltárolják a változtatások túlnyomó többségét (logok), jellemzően csak az aktuális adatokat tartalmazzák könnyen (kevés erőforrással) lekérdezhető struktúrában, és az adatok integritásának érdekében normalizált szerkezetben tárolják az adatokat (3NF, BCNF). Ráadásul ezen rendszerek sok adatot érintő lekérdezésekkel történő terhelése nem célszerű. Céljuk sem ez, sokkal inkább az operáció támogatása. Az adattárházak olyan, jellemzősen réteges felépítésű adatbázisok, amelyek az elemzésre szánt adatokat integráltan: több forrásrendszer bevonásával, historikusan: nem csak aktuális, hanem visszamenőleges adatok is rendelkezésre állnak, elemzésre optimalizált formában (legalábbis a kiaknázási szinten): denormalizáltan, OLAP struktúrában tartalmazzák.
Komplexitás, erőforrás igény Sokrétű felhasználás Adatbányászat Rejtett összefüggések algoritmus segítségével vagy manuálisan történő feltérképezése, számszerűsítése. Mutatószámok képzése Kulcsfontosságú (KPI) mutatószámok előállítása és prezentálása közérthető, esztétikus formában. Elemzések készítése Nagy mennyiségű információ megjelenítése úgy, hogy az szükség szerint szűrhető, kategorizálható legyen. Riportok, jelentések készítése Táblázatos vagy azzá alakítható formátumú, rögzített adattartalommal rendelkező lekérdezések eredménytáblái. Operatív/front-end rendszerek ellátása adatokkal Jellemzően tételes, könnyen származtatható adatok előállítása és továbbítása. Általában kiemelt fontosságú a rendelkezésre állás. Komplexitás, erőforrás igény ID Name Type Relevant 324 Szabó C y 321 Hajnal B n Az operatív rendszerek adatokkal történő ellátásától eltekintve tulajdonképpen minden esetben valamilyen riport előállítása a végső cél. A legegyszerűbb feladat valamely információs rendszer tételes adatokkal való ellátása. Ennél valamivel bonyolultabb felhasználási mód a riportkészítés, még bonyolultabb az adatkockák előállítása (struktúraváltás). A mutatószámok kalkulálása általában nagy mennyiségű adatra támaszkodik. Az adatbányászat gyakorlata sok vállalatnál még gyerekcipőben jár, és csak néhány részleg él a lehetőséggel – ha egyáltalán van ilyen. Mindazonáltal, hogy összetettség és aggregálás szempontjából az operatív rendszerek töltése a legegyszerűbb feladat, az adattárház eredeti funkcióitól ez a felhasználás merőben eltér – ugyanis nem elemzés, riport előállítása a cél. A rendelkezésre állás biztosítását tekintve az erőforrás igény itt a legnagyobb.
Az adattárházak felhasználási területei (példák) A kinyert információ felhasználása Végfelhasználó Rövid- és hosszútávú stratégiai döntések meghozatalához szükséges jelentések Felső- és középvezetők, a menedzsment Jelentésszolgálat a felügyeleti szervek felé A jelentéseket szolgáltató területek dolgozói (illetve később természetesen az érintett felügyeleti szerv dolgozói) Multinacionális vállalatok esetén adatszolgáltatás az anyavállalat felé Az anyavállalatnál dolgozó elemzők illetve a csoportszintű menedzsment tagjai A szervezet normális működéséhez szükséges elemzések például egy bankban a hitelkockázat-elemzési területen dolgozók
Az adattárház helye PS: Operatív rendszer (Production System) ED (TS) IS (TS) ED IS (TS) PS (TS,SS) PS: Operatív rendszer (Production System) SS: Forrásrendszer (Source System) TS: Célrendszer (Target System) IS: Információs rendszer (Information System) ED: Elektronikus dokumentum (Electronic Document) IS PS DWH PS Az információs rendszerekben adatmódosítás nem történik, céljuk az információszolgáltatás. Ettől eltérően az operatív rendszerek egyik alapvető célja éppen az adatmódosítás, adatbevitel biztosítása. A sokrétű felhasználás következtében az adattárház a szervezet informatikai infrastruktúrájának ez egyik középponti eleme – vagy legalábbis azzá válik idővel, ahogy egyre szélesebb körben alkalmazzák. Természetesen előfordulhatnak olyan rendszerek, amelyekből nem töltődnek adatok az adattárházba – és talán nem is fognak soha (pl. beléptető rendszer, belső ellenőrzés valamilyen alkalmazása). Nem ritkán az is tapasztalható, hogy a forrásadatok nem az alaprendszerből közvetlenül, hanem valamilyen közbeiktatott rendszerből származnak. A visszacsatolás (célrendszer és forrásrendszer egyben) sem ritka jelenség. ED (SS) PS PS (SS) PS (SS) PS (SS) PS (SS) PS (SS) ED PS
Az adattárház típusai adatpiac réteg transzformációs réteg Célrendszerek információs rendszerek adatpiac réteg transzformációs réteg háromrétegű staging réteg Adattárház adattisztítás, historizálás, struktúraváltás, kalkulációk, szűrés adatpiac réteg Az adattárházak felépítésére vonatkozóan többféle megoldás létezik: Van, aki az adatpiacokat (az adatpiac réteget) nem tekinti az adattárház részének. Ennek oka elsősorban az, hogy az adatpiacok egymástól függetlenek, és előfordulhat, hogy a kiszolgálandó alkalmazás (információs rendszer) szállítója fejleszti magát az adatpiacot is. Ezért szervezési szempontból ésszerűbb külön rendszerként kezelni azt – még akkor is, ha az adatbázis ugyanaz. Az is elképzelhető, hogy a bemeneti (staging) réteg más alkalmazásokat is kiszolgál (amelyek a DWH mellett egyazon adatbázisban foglalnak helyet). Tehát ez az adatállomás nem tekinthető csak a DWH részének, ezért az előbbihez hasonlóan külön rendszernek minősül. A technológiai fejlődésnek köszönhetően megfontolandó, hogy a transzformációk a staging és az adatpiac réteg között közvetlenül elvégezhetők-e. Háromrétegű adattárházat alapul véve az első kettő kitétel oda vezet, hogy egy egyrétegű DWH-ról beszélünk. Amennyiben a harmadik feltételezést is komolyan vesszük (az előbbi kettő mellett), oda jutunk, hogy az adattárházunk nem más, mint egy transzformáció gyűjtemény, a platformtól eltekintve a transzformációs logikák összessége. Önkiszolgáló adattárházat kapunk, ha az első feltevést fogadjuk el. Ebben az esetben ugyanis a DWH egy „adatmedencét” (data pool) testesít meg, melyből tetszés szerint szolgálhatja ki magát valamely terület. Egyébként az is megállapodás kérdése, hogy melyik adattárház réteg(ek)et tekinthetjük kiaknázási szintnek. kétrétegű staging réteg Forrásrendszerek operatív és egyéb rendszerek
Az adattárház egy lehetséges felépítése Információs rendszerek … IS1 IS2 IS3 IS4 ISn Információ kinyerése Adatpiacok (ROLAP vagy MOLAP struktúrában) Kocka- generálás, Adatpiacosítás Historikus adatok (ROLAP struktúrában) Metaadat-kezelő rendszer Adattárház Delta-képzés (historizálás) Integrált előző napi adatok (ROLAP struktúrában) Struktúraváltás, tisztítás, transzformálás Forrásrendszerek előző napi lenyomata (OLTP struktúrában) Szűrés, közös platformra hozás Forrásrend-szerek … PS1 PS2 PS3 PS4 PSn
Az adattárházak fejlesztése Kétféle fejlesztési metódus: Big Bang A Big Bang fejlesztés során felmérik a szervezek különböző egységeiben az aktuális és lehetséges (releváns) igényeket, majd felépítik az adattárházat, beleértve az adatpiacokat is. Inkrementális Az inkrementális fejlesztés alkalmazásánál egy igény jelentkezése során felépítenek egy (esetleg több) adatpiacot. Az igénynek nyilvánvalóan olyannak, kell lennie, amely kielégítése adattárház igénybe vételével lenne célszerű. Az előbbi értelemszerűen hosszabb átfutási idejű ás költségesebb fejlesztést igényel, mint az utóbbi. (Természetesen a változáskövetéssel elkészülő újabb adatpiac verziók is fejlesztés révén valósulnak meg.) Inmon - Don't do anything until you've designed everything. (Big Bang, TOP-DOWN APPROACH) Pros: easy to maintain, tightly integrated Cons: takes way too long to deliver first projects, rigid Kimball - Let everybody build what they want, when they want it, we'll integrate it all when and if we need to. (Inkrementális, BOTTOM-UP APPROACH) Pros: fast to build, quick ROI, nimble Cons: harder to maintain as an enterprise resource, often redundant, often difficult to integrate data marts (Forrás: http://it.toolbox.com/blogs/confessions/kimball-vs-inmonor-how-to-build-a-data-warehouse-10987)
Az adattárházak fejlesztése Az inkrementális fejlesztés ábráján az egy nem egy adatforrást jelez, hanem a fejlesztéshez felhasznált forrásrendszerek halmazát. 1. inkremens 2. inkremens 3. inkremens DM DM DM DM DM DM DWH DWH PS PS PS PS PS PS Inkrementális Big Bang PS
Az adattárházak fejlesztése Előny (+)/Hátrány (-) Big Bang Inkrementális Igények felmérése - Az egyes szervezeti egységek nem biztos, hogy szükségét érzik a fejlesztésnek, ezért az együttműködés csorbát szenvedhet. + Mivel az érintett terület nyújtotta be az igényt, bizonyosan teljes mértékben együttműködik. Többletmunka újabb igények felmerülése esetén Általában már tartalmazza az adattárház a szükséges adatokat. Gyakran nem tartalmazza még az adattárház a szükséges adatokat. Fejlesztési, üzemeltetési költségek Fejlesztés időigénye Sokszorosa az inkrementálisnak. Töredéke a Big Bang-nek. Tárhely igény Már a kezdetekkor nagy. Eleinte kevesebb, az egyes inkrementumok beépülésével nő.
Az adattárházak fejlesztése A fejlesztés menete (mindkét esetben): Igények felmérése, követelmények meghatározása Logikai adatmodell elkészítése (az igények lefordítása) Forrásadatok megkeresése, forrásrendszerek feltérképezése Fizikai adatmodell elkészítése (platformfüggően valamennyi objektumra) Megvalósítás Tesztelés (felhasználói – adattartalmi, performanciális, regressziós) Ősfeltöltés (az adattárház feltöltése a régebbi adatokkal pl. archív adatbázisokból) Élesítés A két legalapvetőbb különbség a hagyományos és az adattárház fejlesztés között a fenti 3. és 7. pont. A 3. pont a forrásrendszerek integrálásából , a 7. pont az adatok historikus mivoltából adódik. A fejlesztés minden esetben az előállítandó információk pontos meghatározásával indul, beleértve az időintervallumot, a töltési frekvenciát, a számszerű adatok pontosságát, minden egyes adatnál a megjelenítés pontos meghatározását, az egyéb elvárt funkciókat, a preferált eszközt (valamelyik szállítótól például) stb. A specifikációt a megrendelő készíti, ennek a fázisnak az eredményessége elsősorban az ő felelőssége. A fejlesztő az adatigény alapján elkészíti az egyes adattárház rétegek logikai adatmodelljét, azaz az entitások attribútumainak felvétele, az entitások közötti relációk megadása attribútum szinten. A kimeneti réteg tekintetében – a félreértések elkerülése végett – célszerű a megrendelő terület közreműködésével elvégezni a feladatot. A fejlesztő felméri és meghatározza a forrásadatok körét, más területekkel karöltve felderíti a forrásadatok pontos helyét a forrásrendszer(ek)ben. Nagy valószínűséggel a forrásadatok egy részét már tartalmazza az adattárház, és elképzelhető (habár kicsi rá az esély), hogy valamely forrásadat nem áll rendelkezésre egyik rendszerben sem. A fejlesztő elkészíti a fizikai adatmodellt. Az egyes adatbázis objektum elnevezése és típusának pontos meghatározásán kívül megadja azt is, hogy milyen transzformációs és szűrési logikára lesz szükség az egyes adattárház rétegek között (Extract-Transform-Load, röviden ETL algoritmusok), és hogy ezek milyen programegységekben lesznek megvalósítva. A fejlesztő elvégzi a fizikai adatmodell lekódolását, leprogramozását a fejlesztői környezetben, majd sikeres fejlesztői teszt esetén átadja azokat. A tesztelési fázis során előre meghatározott teszteseteken keresztül a megrendelői terület elvégzi a kimeneti rétegen előállt (vagy az információs rendszerbe áttöltött) adatok tesztelését. Sok esetben azonban (amikor erőforrás igényes feldolgozásról van szó) performanciális tesztelésre is szükség lehet, amit az adattárház üzemeltetését végző/támogató terület végez el. Mivel a fejlesztés módosítja az adattárház struktúráját és/vagy adattartalmát, célszerű leellenőrizni a már meglévő adatpiacok töltésének helyességét. A regressziós teszt egy jól szervezett (esetleg metaadat-kezelt) adattárház esetében mellőzhető. Ugyan csak az utolsó lépésként jelöltem meg, az ősfeltöltést még az élesítés előtt el kell végezni (valamelyik tesztkörnyezetben), és külön tesztelést kell végezni rá. Azért érdemes csak a tesztelési fázist követően elvégezni ezt a lépést, mert ha esetleg nem elfogadható valamelyik teszt eredménye, akkor a nagy helyet foglaló visszamenőleges adatok és a betöltésükből adódó többlet időszükséglet kiküszöbölhető. Elfogadható teszteredmények esetén a fejlesztés élesbe állítható. Vannak esetek, amikor a helyes működés csak bizonyos idő elteltével állapítható meg (mert csak valamennyi idő elteltével kerülnek át bizonyos jellemzővel rendelkező adatok). Ilyenkor pilot (figyelemmel kísérendő) üzemmódba kerül a fejlesztés az éles környezetben.