Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Számítástudományi módszerek a webes szolgáltatásokban Rácz Balázs 2009. október 20.

2
Áttekintés Matematikai módszer: min-hash fingerprinting Alkalmazás: perszonalizáció a Google News szolgáltatásban SimRank hasonlósági függvény Személyre szabott PageRank

3
Min-hash fingerprinting On the resemblance and containment of documents, A. Broder, 1997. Dokumentum: szavak halmaza Két dokumentum hasonlósága: Jaccard-együttható Véletlenített módszer a Jaccard-együtthatók torzítatlan becslésére

4
Min-hash fingerprinting Legyen h egy véletlen függvény a szavak halmazán A D dokumentum ujjlenyomata Az ujjlenyomatok megegyezési valószínűsége egy adott h függvény esetén pont a Jaccard-együttható Monte Carlo közelítés: N független ujjlenyomatból átlagolva torzítatlan becslés a hasonlósági mértékre

5
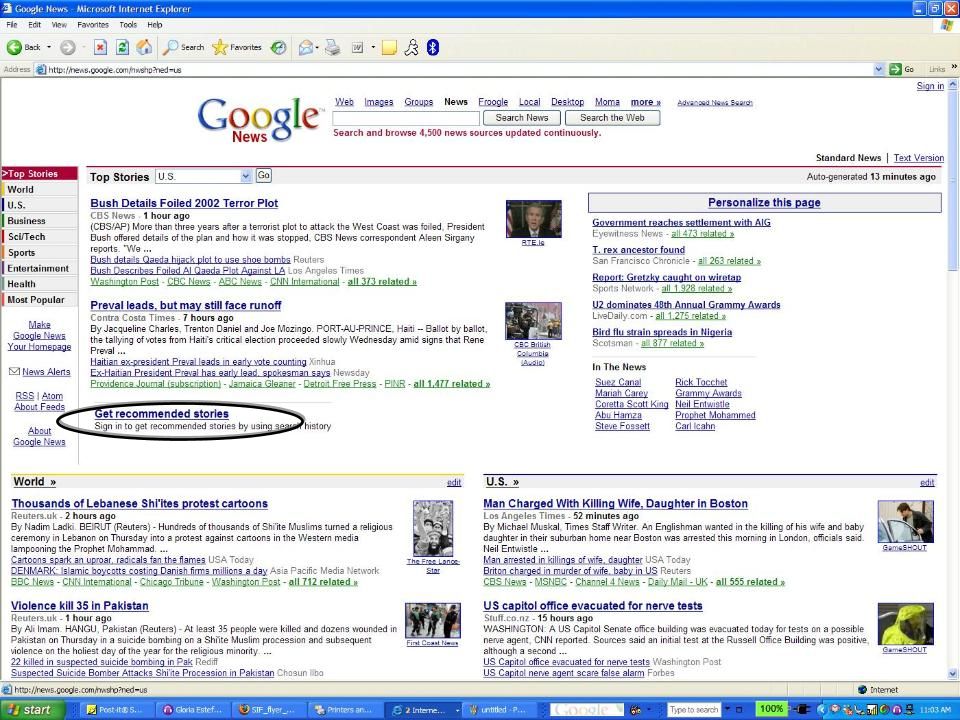
Users reading (clicking on) news stories
 news stories")
6
Users reading news stories Represent a user u by all the stories they clicked on: Find similar users and recommend their clicks to u User similarity = Sim(U 1, U 2 ) = Translation: Out of all the stories either user has ever clicked on, the more clicks they have in common, the more similar they are
 = Translation: Out of all the stories either user has ever clicked on, the more clicks they have in common, the more similar they are")
7
Min-hash fingerprinting alkalmazása Jaccard-együtthatóval definiáljuk a felhasználók hasonlóságát N véletlen permutációból számított ujjlenyomattal közelíthető, ezek letárolhatóak Hasonló felhasználók által olvasott híreket javasolunk

9
[screenshot of Google News showing personalized stories]
![[screenshot of Google News showing personalized stories]](http://images.slideplayer.hu/8/2089939/slides/slide_9.jpg "[screenshot of Google News showing personalized stories]")
10
Introduction / Motivation Similarity search on the Web

11
Approaches / Related Results Text-based Classic IR Min-hash fingerprinting (Broder ’97) Pure link-based Single-step: cocitation, bibliographic coupling, … Multi-step: Companion (Dean, Henzinger, ‘98) SimRank (Jeh, Widom, ‘02) Hybrid Anchor text based (Haveliwala et al. ‘02) random access quadratic
 random access quadratic.")
12
Skálázhatóság: a probléma mérete Hány lap van a weben? Végtelen sok Indexelhető lapok száma 2004: 11,5 milliárd; ma: legalább 60 milliárd Más források: 120 milliárd Mennyi a hasznos lapok száma? Átlagos fokszám Legalább 10

13
Skálázhatóság: követelmények Előfeldolgozás (indexelés) Input konstans sok végigolvasása futási idő < 1 nap Indexadatbázis mérete Lineáris Lekérdezés Konstans sok adatbázishozzáférés; <1 sec Párhuzamosíthatóság Akár 1000 kisebb gép alkalmazása
 Input konstans sok végigolvasása futási idő < 1 nap Indexadatbázis mérete Lineáris Lekérdezés Konstans sok adatbázishozzáférés; <1 sec Párhuzamosíthatóság Akár 1000 kisebb gép alkalmazása")
14
SimRank Jeh and Widom, 2002 “the similarity of two pages is the average similarity of their referring pages” Formalized as a PageRank-like equation: Power iteration: quadratic storage and time Goal: quadratic linear

15
Randomization For pages u and v, start two random walks from them, following the links backwards. Let τ be the first meeting time Jeh, Widom:sim(u,v)=expected value of c τ Our algorithm: Monte Carlo method simulate N independent pair of random walks approximate sim with the average of c τ Index DB: N random walk for each page Query: calculate meeting times
=expected value of c τ Our algorithm: Monte Carlo method simulate N independent pair of random walks approximate sim with the average of c τ Index DB: N random walk for each page Query: calculate meeting times.")
16
Derandomization (partially) trick #1: pair-wise independence is enough trick #2: anything after the first meeting is irrelevant coalescing (sticky) walks Allows very efficient representation
 trick #1: pair-wise independence is enough trick #2: anything after the first meeting is irrelevant coalescing (sticky) walks Allows very efficient representation")
17
Gains V=no. of pages (~10 9 ) N=no. of indep. simulations (100) Indexing: stream access to the graph, V cells of memory (or external memory) Index Database size: N·V (~500 GB) Query: 2N disk seeks, time proportional to the number of results Parallelizable to N machines (5 GB storage, 2 disk seeks/query each)
 Indexing: stream access to the graph, V cells of memory (or external memory) Index Database size: N·V (~500 GB) Query: 2N disk seeks, time proportional to the number of results Parallelizable to N machines (5 GB storage, 2 disk seeks/query each).")
18
Ipari alkalmazhatóság Párhuzamosíthatóság Minden számítógép egy független ujjlenyomat Hibatűrés N-1 ujjlenyomatból számítjuk az eredményt Terheléselosztás Nagy terhelés esetén csökkentjük N-et Inkrementális indexelési algoritmusok Klaszter kapacitása a gépek számában lineárisan nő

19
PSimRank SimRankPSimRank random walksindependentcoupled Pr(first step meet) next edge choiceuniformmin-hash Coupling walks “attract” each other, like they were walking towards the same goal Still, PSimRank can be computed within the same Monte Carlo similarity search framework (all scalability properties still hold!)
 next edge choiceuniformmin-hash Coupling walks attract each other, like they were walking towards the same goal Still, PSimRank can be computed within the same Monte Carlo similarity search framework (all scalability properties still hold!)")
20
Konvergenciasebesség N ujjlenyomat átlagából számított értékekre Rögzített abszolút hiba Hibavalószínűség exponenciálisan 0 Uniform: a csúcsoktól függetlenül A gráftól függetlenül Hasonlóan a toplista-felidézésre is Következmény: N tekinthető aszimptotikusan konstansnak

21
Alsó becslés Van-e pontos algoritmus? Nincs. Tétel Az egzakt feladathoz D = Ω(V 2 ) méretű index kell Tétel A közelítő feladathoz D = Ω(V) méretű index kell Lehet-e javítani ez utóbbit? A mi algoritmusunk D = O(V logV) méretű adatbázist igényel a 2.3. tézis által adott kódolással
 méretű index kell Tétel A közelítő feladathoz D = Ω(V) méretű index kell Lehet-e javítani ez utóbbit. A mi algoritmusunk D = O(V logV) méretű adatbázist igényel a 2.3. tézis által adott kódolással.")
22
Experimental evaluation Evaluation methodology: Haveliwala et al. ’02 Uses Open Directory Project (dmoz.org) Ground truth similarity in directory familial distance: documents in the same class are more similar as those in different classes Compare orderings of familial distance and calculated similarity Stanford WebBase: 80M pages; including 200K ODP pages
 Ground truth similarity in directory familial distance: documents in the same class are more similar as those in different classes Compare orderings of familial distance and calculated similarity Stanford WebBase: 80M pages; including 200K ODP pages.")
23
Experiments #1: path length Multi-step similarity does make sense!...

24
Experiments #3: number of simul. N Note: recall (# of results) grows linearly.
 grows linearly.")
25
Similarity search with SimRank Approximation algorithm for multi-step/ recursive similarity functions Uses simulated random walks Monte Carlo method Scalable New similarity functions First sight of these on real(ly big) web data Yes, they do make sense!
 web data Yes, they do make sense!")
26
Perszonalizált PageRank PageRank(Brin,Page,’98) PV PageRank vektor, r egyenletes eloszlás vektora Globális minőségértékelés Előfeldolgozás: hatványiterációval kiszámítjuk PV-t Lekérdezés: PV értékei alapján rendezzük a találatokat Personalized PageRank(Brin,Page,’98) r felhasználó preferenciavektora, lekérdezési időben adott PPV(r):=PV személyes minőségértékelés Előfeldolgozás: r nem ismert. Mit számítsunk ki? Lekérdezés: hatványiteráció. 5 óra válaszidő!!!

27
Teljes személyre szabás Monte Carlo szimuláció, nem hatványiteráció Előállítunk közelítő PPV(r i )-t minden kezdőlaphoz Skálázhatóság: kvázilineáris előfeldolgozás & konstans lekérdezés Linearitás:
-t minden kezdőlaphoz Skálázhatóság: kvázilineáris előfeldolgozás & konstans lekérdezés Linearitás:")
28
Alapötlet Tétel (Jeh, Widom ’03, Fogaras ’03) Indítsunk egy véletlen sétát az u csúcsból Egyenletes lépés 1-c, megállunk c val.séggel PPV(u,v)=Pr{ a megállási pont v } Monte Carlo algoritmus Előfeldolgozás Az u-ból szimulálunk N független véletlen sétát Indexadatbázis ujjlenyomatokból: A megállási pontok az összes kiinduló csúcsra Lekérdezés PPV(u,v) : = # ( u→v séták ) / N Lineáris kombinációval tetszőleges r vektorokra
 Indítsunk egy véletlen sétát az u csúcsból Egyenletes lépés 1-c, megállunk c val.séggel PPV(u,v)=Pr{ a megállási pont v } Monte Carlo algoritmus Előfeldolgozás Az u-ból szimulálunk N független véletlen sétát Indexadatbázis ujjlenyomatokból: A megállási pontok az összes kiinduló csúcsra Lekérdezés PPV(u,v) : = # ( u→v séták ) / N Lineáris kombinációval tetszőleges r vektorokra")
29
Külső táras indexelés Cél: N független séta, minden egyes pontból Bemenet: webgráf V ≈ 10 10, E ≈ 10 11 V+E > memória Hozzáférés az élekhez: Adatfolyam: az élek végigolvasása Az élek a kiindulópont szerint rendezettek

30
Külső táras indexelés (2) Cél: N független séta, minden egyes pontból Szimuláljuk az összes sétát egyidőben Ciklus: 1 lépés = 1 futam Rendezzük Rendezzük az utak végeit Összefésül Összefésül a gráffal megáll Minden séta megáll c vszg-gel E E( #séták ) = (1-c) k ∙N∙V k iteráció után
 Cél: N független séta, minden egyes pontból Szimuláljuk az összes sétát egyidőben Ciklus: 1 lépés = 1 futam Rendezzük Rendezzük az utak végeit Összefésül Összefésül a gráffal megáll Minden séta megáll c vszg-gel E E( #séták ) = (1-c) k ∙N∙V k iteráció után")
31
Elosztott indexelés M számítógép gyors helyi hálózatba kötve memória < V+E ≤ M∙(memória) Párhuzamosítás: N∙V séta A gráf részei memóriában Üzenetküldés: csomagok M=3
 Párhuzamosítás: N∙V séta A gráf részei memóriában Üzenetküldés: csomagok M=3")
32
Példa: gyakorlati alkalmazhatóság Web-gráf 10 milliárd csúccsal Külső táras indexelés 256 TB I/O 60 diszk * 24 óra Elosztott indexelés 100 számítógép memóriája elegendő 48 TB hálózati forgalom ~1 óra

33
Köszönöm a figyelmet!

Hasonló előadás