Előadást letölteni
1
Mintavételi hiba, hibaszámítás

2
MONITORING - VKI A monitoring célja az, hogy megalapozza a vízstátus egységes és átfogó felülvizsgálatát minden egyes vízgyűjtőkerületben és elősegítse a felszíni víztestek besorolását a megfelelő osztályba. Mérlegelni kell a monitoring költségét és a státus hibás besorolásának következményéből származó költségeket (többlet intézkedések). A vízgyűjtő gazdálkodási tervekben a konfidencia szinteket közölni kell.
. A vízgyűjtő gazdálkodási tervekben a konfidencia szinteket közölni kell.")
3
A víztest állapota hibás osztályozásának kockázata
(osztályozás megbízhatósága)
")
4
Kockázat A kedvezőtlen esemény bekövetkezésének esélye, VKI értelmezésében a hibás osztály besorolás valószínűsége. Az elfogadható kockázati szint befolyásolja a víztest állapotának meghatározásához szükséges monitoring időbeli és térbeli sűrűségét. Megbízhatóság (konfidencia) Annak a valószínűsége ( %-ban kifejezve), hogy a statisztikai paraméter valós értéke a számított és a jegyzett értékek közé esik (statisztikai bizonytalanság). Precizitás (pontosság) A valós állapot és a monitoring által talált állapot közti eltérés, adott konfidencia-tartomány szélességének felével megegyező statisztikai bizonytalanság mértéke.
 Annak a valószínűsége ( %-ban kifejezve), hogy a statisztikai paraméter valós értéke a számított és a jegyzett értékek közé esik (statisztikai bizonytalanság). Precizitás (pontosság) A valós állapot és a monitoring által talált állapot közti eltérés, adott konfidencia-tartomány szélességének felével megegyező statisztikai bizonytalanság mértéke.")
5
osztályba sorolás hibáját befolyásoló tényezők
Mérési adatsor: osztályba sorolás hibáját befolyásoló tényezők Mérési gyakoriság Vizsgálandó jellemzők időbeli változékonysága Eltérés mértéke a küszöbértékhez (osztályhatárhoz) képest Besoroláshoz figyelembe veendő jellemző (évi vagy évszakos átlag, trendek, 90 %-os tartósságú érték, stb.) t C t C t C Ch Ch Ch
 képest. Besoroláshoz figyelembe veendő jellemző (évi vagy évszakos átlag, trendek, 90 %-os tartósságú érték, stb.) t. C. t. C. t. C. Ch. Ch. Ch.")
6
Hibaszámítás elmélete (valószínűségelmélet)
Mintavétel, mérés valószínűségi változó valószínűségi sűrűségfüggvény Sokaság (véges, végtelen) Valószínűségi sűrűségfüggvény: f(x) Annak valószínűsége, hogy egy érték x1 és x2 közé essen: A valószínűségi sűrűségfüggvény integrálja a valószínűségi változó teljes értelmezési tartományára: Valószínűségi eloszlásfüggvény: a valószínűségi sűrűségfüggvény integrálfüggvénye: F(x) Annak a valószínűsége, hogy a valószínűségi változó értéke nem nagyobb, mint egy adott xi érték: P (x xi ) = F(xi) Az eloszlásfüggvénnyel megadhatjuk annak a valószínűségét, hogy a valószínűségi változó értéke x1 és x2 közé esik:
 Valószínűségi sűrűségfüggvény: f(x) Annak valószínűsége, hogy egy érték x1 és x2 közé essen: A valószínűségi sűrűségfüggvény integrálja a valószínűségi változó teljes értelmezési tartományára: Valószínűségi eloszlásfüggvény: a valószínűségi sűrűségfüggvény integrálfüggvénye: F(x) Annak a valószínűsége, hogy a valószínűségi változó értéke nem nagyobb, mint egy adott xi érték: P (x xi ) = F(xi) Az eloszlásfüggvénnyel megadhatjuk annak a valószínűségét, hogy a valószínűségi változó értéke x1 és x2 közé esik:")
7
A centrális határeloszlás tétele
A centrális határeloszlás tétele szerint bármilyen eloszlású sokaság esetén az n elemű minta számtani középértékének eloszlása a minta elemszámának növekedésével egy olyan normális eloszláshoz tart, melynek várható értéke megegyezik az eredeti eloszlás várható értékével. Ez azt jelenti, hogy ha már egyetlen mérési eredmény is átlagnak, pl. időátlagnak tekinthető, akkor várható, hogy az Gauss-eloszlású lesz. A mérési eredmények viszont nagyon gyakran ilyen átlagértékek. A gyakorlatban legtöbbször normális eloszlású mérési eredményekkel találkozunk.

8
Normális eloszlás: azok a valószínűségi változók, melyek értékét sok kismértékű véletlenszerű hatás befolyásolja. „m” az eloszlás várható értéke, „s” a szórás Gauss-függvény: u = (x-m) / s normalizált Gauss-függvény: A normalizált Gauss-eloszláshoz tartozó valószínűségi eloszlásfüggvény: (hibaintegrál), F()=1. A normalizált Gauss-függvény (hibafüggvény):
 / s. normalizált Gauss-függvény: A normalizált Gauss-eloszláshoz tartozó valószínűségi eloszlásfüggvény: (hibaintegrál), F()=1. A normalizált Gauss-függvény (hibafüggvény):")
9
Alkalmazás: Milyen valószínűséggel esik a valószínűségi változó értéke a várható érték körüli, adott sugarú intervallumba? x1 = m-Δx és x2 = m+ Δx Transzformálás után (normalizált Gauss eloszláshoz) az intervallum: u = (x-m) / s u1 = - Δx/s = -v és u2 = Δx/s = v P(u1 u u2) = F(u2) - F(u1) = F (v) - F (-v) Szimmetria miatt: F (-v) = 1 - F(v) P(-vuv) = 2 F (v) - 1 Annak a valószínűsége, hogy a változó értéke kiessen az adott szimmetrikus intervallumból, tehát egy adott tűrésnél jobban eltérjen a várható értéktől: P(u -v u v) = 1- (2f(v)-1) = 2(1-f(v)).
 az intervallum: u = (x-m) / s. u1 = - Δx/s = -v és u2 = Δx/s = v. P(u1 u u2) = F(u2) - F(u1) = F (v) - F (-v) Szimmetria miatt: F (-v) = 1 - F(v) P(-vuv) = 2 F (v) - 1. Annak a valószínűsége, hogy a változó értéke kiessen az adott szimmetrikus intervallumból, tehát egy adott tűrésnél jobban eltérjen a várható értéktől: P(u -v. u v) = 1- (2f(v)-1) = 2(1-f(v)).")
10
Konfidencia intervallum, megbízhatósági szint megadása
Gauss-eloszlás esetén: a mérési eredmények a várható érték körüli egyszeres szórás (s) sugarú intervallumba 68,3%, a 2 s sugarú intervallumba 95,4 % valószínűséggel esnek. Adott P valószínűség (P konfidencia szint) : [m - k s , m + k s ] Konfidencia intervallum, melybe a mérési eredmények az adott P valószínűséggel beleesnek. P = 68,3% k = 1 P = 95,4% k = 2 P = 90% k = 1.65 P = 95% k = 1.96 u = S = 1 F(u) = P (-1 ≤ x ≤ 1) = F (1) – (1 – F(1))= 2 F(1) -1 = 0.683
 sugarú intervallumba 68,3%, a 2 s sugarú intervallumba 95,4 % valószínűséggel esnek. Adott P valószínűség (P konfidencia szint) : [m - k s , m + k s ] Konfidencia intervallum, melybe a mérési eredmények az adott P valószínűséggel beleesnek. P = 68,3% k = 1. P = 95,4% k = 2. P = 90% k = P = 95% k = u = S = 1. F(u) = P (-1 ≤ x ≤ 1) = F (1) – (1 – F(1))= 2 F(1) -1 =")
11
Konfidencia kis mintaszámnál:
A t paraméter meghatározása (Student-féle t-eloszlás) Mérési eredményeknél: a szórást sem ismerjük, csak becsüljük a középérték korrigált tapasztalati szórásával. Szórás is pontatlan → ugyanahhoz a valószínűséghez nagyobb számmal kell megszorozni a becsült szórást a konfidencia intervallum meghatározásánál, mint ezt egy ismert szórású Gauss-eloszlásnál tennénk. A Student-féle t paraméter értékei P konfidenciaszintnél és N mérésszámnál 0,8 0,9 0,95 0,975 0,99 0,995 2 3,078 6,314 12,706 25,452 63,657 127,32 3 1,886 2,920 4,303 6,205 9,925 14,089 4 1,638 2,353 3,182 4,176 5,841 7,453 5 1,553 2,132 2,776 3,495 4,604 5,598 6 1,476 2,015 2,571 3,163 4,032 4,773 7 1,440 1,943 2,447 2,969 3,707 4,317 8 1,415 1,895 2,365 2,841 3,499 4,029 9 1,397 1,860 2,306 2,752 3,355 3,832 10 1,383 1,833 2,262 2,685 3,250 3,690 20 1,328 1,729 2,093 2,433 2,861 3,174 1,282 1,645 1,960 2,241 2,576 2,807 X (mért mennyiség) = = t
 Mérési eredményeknél: a szórást sem ismerjük, csak becsüljük a középérték korrigált tapasztalati szórásával. Szórás is pontatlan → ugyanahhoz a valószínűséghez nagyobb számmal kell megszorozni a becsült szórást a konfidencia intervallum meghatározásánál, mint ezt egy ismert szórású Gauss-eloszlásnál tennénk. A Student-féle t paraméter értékei P konfidenciaszintnél és N mérésszámnál. 0,8. 0,9. 0,95. 0,975. 0,99. 0, ,078. 6, , , , , ,886. 2,920. 4,303. 6,205. 9, , ,638. 2,353. 3,182. 4,176. 5,841. 7, ,553. 2,132. 2,776. 3,495. 4,604. 5, ,476. 2,015. 2,571. 3,163. 4,032. 4, ,440. 1,943. 2,447. 2,969. 3,707. 4, ,415. 1,895. 2,365. 2,841. 3,499. 4, ,397. 1,860. 2,306. 2,752. 3,355. 3, ,383. 1,833. 2,262. 2,685. 3,250. 3, ,328. 1,729. 2,093. 2,433. 2,861. 3,174. 1,282. 1,645. 1,960. 2,241. 2,576. 2,807. X (mért mennyiség) = = t.")
12
Mintavételi gyakoriság megválasztása
Ha a cél: Átlag (középérték) meghatározása Trend detektálása Folytonos idősor visszaállítása
 meghatározása. Trend detektálása. Folytonos idősor visszaállítása.")
13
Torzítatlan és torzított becslés
A mintavétel és mérés célja, hogy információt kapjunk a sokaságon az adott tulajdonság eloszlásáról, azaz meg tudjuk becsülni az eloszlás paramétereket a sokaság elemszámánál sokkal kisebb minta alapján. Egy becslés torzítatlan, ha a becsült és valóságos várható értékek megegyeznek, azaz: A hiba várható értéke 0 (a becsült paramétereket hullámvonal jelöli). A várható érték becslése A várható értéket úgy vezettük be véges elemű, diszkrét sokaságra, mint a sokaságra vett átlagát az adott tulajdonságnak. Ha most nem az egész sokaságot vesszük, csak egy mintát belőle, becsülhetjük úgy az egész sokaságra vonatkozó átlagot, hogy csak a mintára átlagolunk, azaz a várható értéket a következőképp becsüljük: , a becslés torzítatlan
. A várható érték becslése. A várható értéket úgy vezettük be véges elemű, diszkrét sokaságra, mint a sokaságra vett átlagát az adott tulajdonságnak. Ha most nem az egész sokaságot vesszük, csak egy mintát belőle, becsülhetjük úgy az egész sokaságra vonatkozó átlagot, hogy csak a mintára átlagolunk, azaz a várható értéket a következőképp becsüljük: , a becslés torzítatlan.")
14
A középérték eloszlásának tulajdonságai
Egy n mérésből álló minta (egyes mérések eredményei) x1,...,xn valószínűségi változók. Az x1,...,xn valószínűségi változó számtani közepe: szintén valószínűségi változó, tehát tartozik hozzá egy f(x1,...,xn) valószínűségi sűrűségfüggvény. Az egyes mérési eredmények függetlenek egymástól, f(x1,...,xn) = f(x1)...f(xn). Mivel ugyanazt a mérést ismételjük, az egyes mérési eredmények várható értéke E[xi] = m és varianciája Var[xi] = s2 azonos minden egyes mérésre. Az összeg és konstansszoros várható értékére és varianciájára vonatkozó formulákat alkalmazva kapjuk, hogy: Azaz a középérték várható értéke megegyezik az egyes mérések várható értékével, varianciája viszont n-ed része az egyes mérésének.
 x1,...,xn valószínűségi változók. Az x1,...,xn valószínűségi változó számtani közepe: szintén valószínűségi változó, tehát tartozik hozzá egy f(x1,...,xn) valószínűségi sűrűségfüggvény. Az egyes mérési eredmények függetlenek egymástól, f(x1,...,xn) = f(x1)...f(xn). Mivel ugyanazt a mérést ismételjük, az egyes mérési eredmények várható értéke E[xi] = m és varianciája Var[xi] = s2 azonos minden egyes mérésre. Az összeg és konstansszoros várható értékére és varianciájára vonatkozó formulákat alkalmazva kapjuk, hogy: Azaz a középérték várható értéke megegyezik az egyes mérések várható értékével, varianciája viszont n-ed része az egyes mérésének.")
15
Variancia és szórás meghatározása
Torzítatlan becslés varianciáját becsülhetjük az egyes mérések hibanégyzetének átlagával : Torzított becslésnél a variancia n-szeresének becsült értéke a valóságos variancia (n-1)-szerese: Azaz a variancia becslése a mérési eredményekből: A mérési eredmények korrigált tapasztalati szórása és a középérték tapasztalati szórása („standard deviation”): Mivel a középérték varianciája az egyes mérések varianciájának n-ed része
-szerese: Azaz a variancia becslése a mérési eredményekből: A mérési eredmények korrigált tapasztalati szórása és a középérték tapasztalati szórása („standard deviation ): Mivel a középérték varianciája az egyes mérések varianciájának n-ed része.")
16
az átlag várható értéke az torzítatlan becslését adja.
Ha a sokaság véges elemű, azaz N független elemet tartalmazó halmazból 1 ≤ n ≤ N független mintát emelünk ki visszahelyezés nélkül véletlenszerűen kiválasztva és az eljárást sokszor ismételve, az átlag várható értéke az torzítatlan becslését adja. A becslés varianciája: n] az ahol N → ∞ esetén Az átlag szórása végtelen és ismert elemszámú sokaság esetén: (Cochran, 1962)
")
17
A középérték várható értékének és hibájának számítása
Szórás becslése

18
A mintanagyság meghatározása átlagbecsléshez egyszerű véletlen mintánál
Ha tudjuk, hogy az átlag becslésében nem akarunk egy megengedhető hibánál nagyobbat adott valószínűséggel megengedni, a szükséges mintaszám meghatározható a középérték hibájából. A megengedhető hiba lényegében a P valószínűséghez tartozó konfidencia intervallum: A hiba %-ban kifejezve: ahol A mintaszám független mintavétel esetén, végtelen sokaságra: Mintavétel véges sokaságra: Autokorrelált (nem független) mintáknál: N → N* és σ → σ*v
 mintáknál: N → N* és σ → σ*v.")
19
MINTASZÁM CSÖKKENTÉSÉNEK HATÁSA
minta / év Mintaszámtól (n) függő tényező: Heti / napi: 2.7 Kétheti / napi: 3.8 Havi / napi: 5.5 Szezonális / napi: 9.6 Havi / kétheti: 1.5 Szezonális / kétheti: 2.5
 függő tényező: Heti / napi: 2.7. Kétheti / napi: 3.8. Havi / napi: 5.5. Szezonális / napi: 9.6. Havi / kétheti: 1.5. Szezonális / kétheti: 2.5.")
20
Vízminőség paraméterek változékonysága (szórás szerepe)
Függ: vízhozam, szezonális hatások (biológia), szennyezések
, szennyezések.")
21
Vízminőségi jellemzők relatív szórása
Víztípusok

22
Mintavétel hibája a szórás függvényében
Víztípusok

23
Kívánt pontosság eléréséhez szükséges éves mintaszám
Heti Kétheti Szezonális Kívánt pontosság eléréséhez szükséges éves mintaszám

24
Kívánt pontosság eléréséhez szükséges éves mintaszám

25
Ellenőrzés: valóban normál eloszlású a hiba?
A vízhozamok általában erősen, a vízminőségi változók komponenstől függően különböző mértékben mutatnak pozitív ferdülést, leggyakrabban lognormál eloszlásúak. Példa: Adatsorok ritkítása → becslés hibájának eloszlása (Monte Carlo szimulációval) A Zala és a Tetves-patak éves átlagos összes P terhelésének becslésében elkövetett relatív hiba Monte Carlo szimulációból nyert empirikus eloszlása (N=365, n=12)
 A Zala és a Tetves-patak éves átlagos összes P terhelésének becslésében elkövetett relatív hiba Monte Carlo szimulációból nyert empirikus eloszlása (N=365, n=12)")
26
Éves átlagok becslésében elkövetett relatív hiba (α, %) p = 95%
M P N E S Duna (Medve) Zala (Zalaapáti) Relatív szórás Havi mintavételezés hibája Relatív szórás Heti mintavételezés hibája Ter-helés Konc. Analiti- kus Monte Carlo Terhe-lés Analíti- Kus Q 0.39 17 % 0.92 23 % 26 % 51 % 54 % ÖN 0.45 0.23 22 % 1.18 30 % 36 % 66 % 70 % oldP 0.47 0.29 24 % 0.96 0.38 25 % 53 % ÖP 0.64 0.35 32 % 34 % 1.07 0.52 27 % 35 % 59 % 65 %
 Zala (Zalaapáti) Relatív szórás. Havi mintavételezés hibája. Relatív. szórás. Heti mintavételezés hibája. Ter-helés. Konc. Analiti- kus. Monte Carlo. Terhe-lés. Analíti- Kus. Q % % 26 % 51 % 54 % ÖN % % 36 % 66 % 70 % oldP % % 53 % ÖP % 34 % % 35 % 59 % 65 %")
27
Adott tartósságú érték meghatározásának hibája
Relatív hiba: 1-p 0.1 0.5 1 5 10 20 31.6 14.1 9.9 4.4 3.0 2.0 30 40 50 60 70 80 90 1.5 1.2 1.0 0.8 0.7 0.3 90%-os tartósságú koncentráció becslési hibája a középérték hibájának háromszorosa!

28
Autokorreláció Egy idősor jelenlegi és későbbi értékei közötti kapcsolat mértékét fejezi ki, Idősoron belüli kapcsolat szorosságát jellemzi, Autokorrelációs tényező ( x(t) idősor, várható érték): Általános (k lépés): Autokorrelációs függvény: Egy idősor autokorreláció függvénye a = 0 .. n értékekhez tartozó r autokorreláció tényezőkből áll.
 idősor, várható érték): Általános (k lépés): Autokorrelációs függvény: Egy idősor autokorreláció függvénye a = 0 .. n értékekhez tartozó r autokorreláció tényezőkből áll.")
29
Tipikus autokorreláció függvények
-2 -1.5 -1 -0.5 0.5 1 1.5 2 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 -1 -0.8 -0.6 -0.4 -0.2 0.2 0.4 0.6 0.8 1 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Véletlenszerű (normális eloszlású független sorozat) -0.3 -0.2 -0.1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 -1 -0.8 -0.6 -0.4 -0.2 0.2 0.4 0.6 0.8 1 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Autokorrelált (véletlen sorozat mozgóátlaga) -1.5 -1 -0.5 0.5 1 1.5 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 -1 -0.8 -0.6 -0.4 -0.2 0.2 0.4 0.6 0.8 1 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Periodikus (szinusz függvény, zajmentes)
 Autokorrelált. (véletlen sorozat mozgóátlaga) Periodikus. (szinusz függvény, zajmentes)")
30
Fehér zaj autokorreláció függvénye:
Az xt stacionárius sztochasztikus folyamat gaussi fehérzaj, ha minden t-re standard normális eloszlású. Az xt sztochasztikus folyamat akkor stacionárius, ha az xt ( t [ t1; t2 ] T ) eloszlása független a [ t1; t2 ] kiválasztásától. Fehér zaj autokorreláció függvénye: -1 -0.8 -0.6 -0.4 -0.2 0.2 0.4 0.6 0.8 1 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Egy xt gaussi fehérzaj folyamat autokorreláció függvénye a Dirac-féle egységugrás függvény. if(t==0) r[t]=1; else r[t]=0; -1 -0.8 -0.6 -0.4 -0.2 0.2 0.4 0.6 0.8 1 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Egy valós fehérzaj folyamat autokorreláció függvénye csak a 0 helyen lép ki az Anderson-féle konfidencia intervallumból.
 eloszlása független a [ t1; t2 ] kiválasztásától. Fehér zaj autokorreláció függvénye: Egy xt gaussi fehérzaj folyamat autokorreláció függvénye a Dirac-féle egységugrás függvény. if(t==0) r[t]=1; else r[t]=0; Egy valós fehérzaj folyamat autokorreláció függvénye csak a 0 helyen lép ki az Anderson-féle konfidencia intervallumból.")
31
Autokorrelációs függvény

32
Autokorrelációs függvény

33
Autokorreláció figyelembe vétele a mintavételezésnél
Az idősor elemei nem függetlenek Az észlelési adatok száma (elemszám, N) helyettesítendő N*-gal: ahol r(t) a t eltolású autokorrelációs tényező A szórás számítása: Vagyis, az effektív mintaszám egymástól nem független megfigyelési adatok esetén (Bayley & Hammersley, 1946): N* = N σ / σ*
 helyettesítendő N*-gal: ahol r(t) a t eltolású autokorrelációs tényező. A szórás számítása: Vagyis, az effektív mintaszám egymástól nem független megfigyelési adatok esetén (Bayley & Hammersley, 1946): N* = N σ / σ*")
34
Lettenmaier (1976) egylépéses autoregresszív modellel meghatározta az n és n* közötti összefüggést:
n* < n Ahol: n a mintaszám, k a mintavételek közti intervallum, ρ az autokorrelációs tényező Effektív mintaszám (n*) az autokorrelációtól függően: n k ρ= 0,9 ρ= 0,7 ρ= 0,5 ρ= 0,3 ρ= 0,1 365 1 20 65 122 197 299 183 2 63 110 153 179 3 60 95 116 91 4 19 56 80 90 73 5 52 69 61 6 48 59 7 44 51 26 14 17 12 30 11
 az autokorrelációtól függően: n. k. ρ= 0,9. ρ= 0,7. ρ= 0,5. ρ= 0,3. ρ= 0,")
35
független és autokorrelált adatsor esetén
Éves átlag becslésére vonatkozó standard hiba változása az effektív mintaszámtól függően, független és autokorrelált adatsor esetén ρ =0 ρ =0.3 ρ =0.5 ρ =0.7 n Sn/S1 n* 365 1,0 197 122 65 183 1,4 153 1,1 110 63 1,7 116 1,3 95 60 91 2,0 90 1,5 80 1,2 56 73 2,2 1,6 69 52 61 2,4 1,8 59 48 2,6 1,9 51 44 26 3,7 2,8 12 5,5 4,1 3,2 2,3 n - mintaszám, n* - effektív mintaszám, ρ - autokorrelációs tényező, S1 – éves átlag standard hibája n=365 mérési adatból, Sn – éves átlag standard hibája n (n*) mérési adatból
 mérési adatból.")
36
Trend detektálásához szükséges adatszám
A trend detektálásának erőssége: lépésköz, illetve lineáris trendnél a növekmény: tr = N*t0 szórás Lettenmaier (1976), Somlyódy et al. (1986)
, Somlyódy et al. (1986)")
37
Trend detektálásához szükséges adatszám (független minták száma az N0 időtartam alatt)
autokorrelációs tényező lépésköz (intervallum) szórás Lettenmaier (1976), Somlyódy et al. (1986)
 szórás. Lettenmaier (1976), Somlyódy et al. (1986)")
38
Folytonos idősor előállítása diszkrét észlelésekből
Nyquist tétele: Egy adott, frekvenciakorlátos spektrumú, folytonos idősor, amely az fk határfrekvencián túl nem tartalmaz spekrtális összetevőket, egyértelműen visszaállítható a t=fk/2 intervallumnál kisebb mintavételezési idejű diszkrét idősorból (Szőlősi-Nagy, 1976). A határfrekvencia (spektrumfüggvény) az idősor autokorreláció függvényének Fourier transzformáltjából állítható elő. Nyquist intervallum: Maximális időintervallum, mely esetén egyenlő időközönkénti mintavétellel a jel meghatározható. A mintában szereplő jel legmagasabb frekvenciájú összetevője kétszeresének a reciproka. folytonos jel, a jel Fourier transzformáltja: A jel sávszélessége (B), ahol Mintavételi frekvencia (határfrekvencia): Mintavételi időköz:
. A határfrekvencia (spektrumfüggvény) az idősor autokorreláció függvényének Fourier transzformáltjából állítható elő. Nyquist intervallum: Maximális időintervallum, mely esetén egyenlő időközönkénti mintavétellel a jel meghatározható. A mintában szereplő jel legmagasabb frekvenciájú összetevője kétszeresének a reciproka. folytonos jel, a jel Fourier transzformáltja: A jel sávszélessége (B), ahol. Mintavételi frekvencia (határfrekvencia): Mintavételi időköz:")
39
Források: METROLÓGIA ÉS HIBASZÁMíTÁS (www.fke.bme.hu)
Homolya András: Óravázlat a Geodézia II. tantárgy gyakorlataihoz ( Cochran (1962): Sampling technics
: Sampling technics.")
40
Idősorok elemzése Determinisztikus és sztochasztikus komponensek, előrejelzés autoregresszív modellel Forrás: Hidrológia II HEFOP oktatási segédanyag (

41
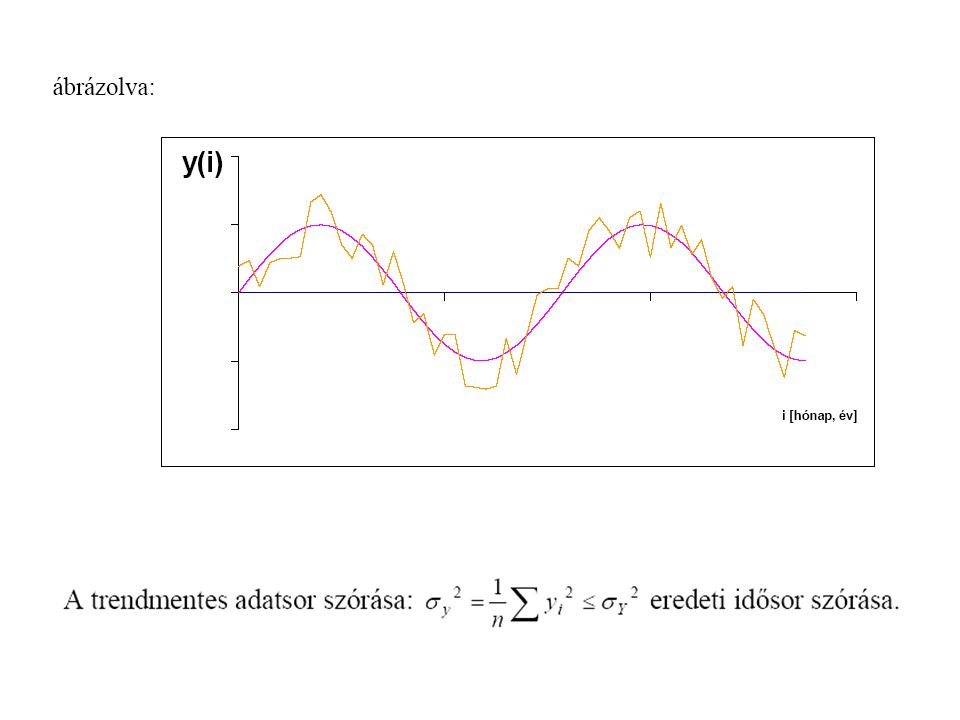
Idősorok felbontása: Y(i) = T(i) + P(i) + A(i) T(i) trend komponens
P(i) periodikus tag A(i) maradéktag determinisztikus sztochasztikus (autoregresszív és véletlen)
 periodikus tag. A(i) maradéktag. determinisztikus. sztochasztikus (autoregresszív és véletlen)")
42
Trendszámítás Lineáris: T(i)=a0 + a1 i
Nem lineáris: T(i)=a0 + a1 i + a2 i2 + … + an in Lineáris trend:
=a0 + a1 i + a2 i2 + … + an in. Lineáris trend:")
44
Példa: vízminőségi trend számítás
Segédtáblázat: Évszám c [mg/l] t [év] ci-cátlag ti-tátlag (ci-cátlag)2 (ti-tátlag)2 (ci-cátlag) (ti-tátlag) 1991 1992 …. 2000 20,3 12,7 1 2 10 +/- értékeket kapunk cátlag = tátlag = = A trendvonal egyenlete:
2. (ti-tátlag)2. (ci-cátlag) (ti-tátlag) … ,3. 12, /- értékeket. kapunk. cátlag = tátlag = = A trendvonal egyenlete:")
45
A trend mértéke: P < 3 %/év kismértékű 3 < P < 7 %/év nagymértékű 7 < P < 15 %/év igen nagymértékű P > 15 %/év rendkívül nagymértékű -1.8 % /év +1.6 % /év

46
Ellenőrzés (regresszió számításból):
Reziduális szórás (abszolút hiba) kifejezi, hogy a regressziós becslések átlagosan mennyivel térnek el az y megfigyelt értékeitől. Relatív szórás (relatív hiba) kifejezi, hogy a regressziós becslések átlagosan hány %-al térnek el az y megfigyelt értékeitől. Pearson-féle lineáris korrelációs együttható: Kovariancia Determinációs együttható:
 kifejezi, hogy a regressziós becslések átlagosan mennyivel térnek el az y megfigyelt értékeitől. Relatív szórás (relatív hiba) kifejezi, hogy a regressziós becslések átlagosan hány %-al térnek el az y megfigyelt értékeitől. Pearson-féle lineáris korrelációs együttható: Kovariancia. Determinációs együttható:")
47
A trend mértéke: P < 3 %/év kismértékű 3 < P < 7 %/év nagymértékű 7 < P < 15 %/év igen nagymértékű P > 15 %/év rendkívül nagymértékű -1.8 % /év → dC = / 10év +1.6 % /év → dC = 0.1 / 10év D = r2 = 0.25, Se = 0.46 (dC = -0.82) D = r2 = 0.12, Se = (dC = 0.1)
 D = r2 = 0.12, Se = 0.16 (dC = 0.1)")
48
Power trend Általános formula: Linearizált: Szórás (hiba):
:")
49
Periodikus komponens meghatározása

51
Sztochasztikus összetevők
Véletlen tag (zaj) Autoregresszív komponens
 Autoregresszív komponens.")
52
Egylépéses autokorrelációs tényező
Egylépéses AR modell: Kétlépéses AR modell:

53
AR, MA és ARMA modellek AR ( p ) : MA ( q ) : ARMA ( p, q ) :
Stacionárius folyamat (kritériumok: állandó átlag és szórás) leírására szolgálnak. Az idősor zt aktuális eleme az előző elemek (AR) illetve az a normális eloszlású véletlen sorozat előző tagjainak (MA) lineáris kombinációjaként számítható ki. AR ( p ) : MA ( q ) : ARMA ( p, q ) : Az AR(0) modellt fehér zaj modellnek is nevezik :
 leírására szolgálnak. Az idősor zt aktuális eleme az előző elemek (AR) illetve az a normális eloszlású véletlen sorozat előző tagjainak (MA) lineáris kombinációjaként számítható ki. AR ( p ) : MA ( q ) : ARMA ( p, q ) : Az AR(0) modellt fehér zaj modellnek is nevezik :")
54
Előrejelzés idősor modellekkel

55
Thomas-Fiering modell (Balaton természetes vízkészlet változásának előrejelzése)
")














>")






