Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék Alapfogalmak az adatelemzésben „Big Data” elemzési módszerek Kocsis Imre, Salánki Ágnes ikocsis@, salanki@ 2014. 09. 24.

2
Adatelemzés Adat Modell Többletinformáció

3
Modell Szakértői tudás o Elvárt összefüggések o Háttértudás a kísérletről o …

4
Modell Szakértői tudás o Elvárt összefüggések o Háttértudás a kísérletről o …

5
Adatelemzés Adat Modell Többletinformáció

6
Adat Nemstrukturált o Nincs előre rögzített tárolási/értelmezési modell Rekord/ megfigyelés Változó/ attribútum

7
Adat Széles Hosszú Nemstrukturált o Nincs előre rögzített tárolási/értelmezési modell

8
Adat Nemstrukturált o Nincs előre rögzített tárolási/értelmezési modell o Csak metaadat o Pl. e-mail, audio anyagok o Transzformáció strukturáltba?

9
Numerikus és kategorikus változók Numerikus (numerical) o az alapvető aritmetikai műveletek értelmesek o Pl. átlaghőmérséklet, kor Kategorikus (categorical) o Csak megkülönböztetés miatt o Pl. telefonszám, nem Változók Numerikus Kategorikus
 o Csak megkülönböztetés miatt o Pl. telefonszám, nem Változók Numerikus Kategorikus.")
10
Numerikus változók Folytonos o Mért – tetszőleges értéket felvehet adott tartományon belül adott pontosság mellett o Pl. a teremben ülők BigData jegyének átlaga Diszkrét o Számolt – véges sok értéket vehet fel adott tartományban o Pl. BigData előadáson ülők száma Változók Numerikus Kategorikus Folytonos Diszkrét

11
Kategorikus változók Rendezett o Teljes rendezés az értékeken Nem rendezett (reguláris) Rendezett Nem rendezett Változók Numerikus Kategorikus
 Rendezett Nem rendezett Változók Numerikus Kategorikus")
12
Adatelemzés Adat Modell Többletinformáció

14
Adatelemzés Adat Modell Többletinformáció Megerősítő Felderítő Tisztítás

15
Adatelemzés Felderítő analízis Cél: hipotézisek megfogalmazása Ismerkedés az adatokkal/doménnel Erősen ad-hoc Fő eszköz: leíró statisztika + adatbányászat, sok vizualizáció Felderítő analízis Cél: hipotézisek megfogalmazása Ismerkedés az adatokkal/doménnel Erősen ad-hoc Fő eszköz: leíró statisztika + adatbányászat, sok vizualizáció Megerősítő analízis Cél: hipotézisek tesztelése Előre megsejtett összefüggések ellenőrzése Fő eszköz: statisztikai tesztek + következtető módszerek Megerősítő analízis Cél: hipotézisek tesztelése Előre megsejtett összefüggések ellenőrzése Fő eszköz: statisztikai tesztek + következtető módszerek

16
Adatelemzés Pl. eloszláselemzés

17
Adatelemzés Pl. lineáris regresszió

18
Adatelemzés Adat Modell Többletinformáció Megerősítő Felderítő Tisztítás

19
Adattisztítás Adattisztítás! o Meglepően hosszú tud lenni o Legtöbbször nem tökéletes o Big Data? Inkonzisztenciák o Beviteli/mérési hibák, „hibás join”, részleges megfigyelés, hamisítás, … Kieső értékek (outliers) o =/= „durva hiba” (gross error) o Nem feltétlenül előnytelen, de klasszikusan az o Magas dimenziószámnál nehéz lehet detektálni o Alacsony dimenziós vizualizáció segíthet
 o =/= „durva hiba (gross error) o Nem feltétlenül előnytelen, de klasszikusan az o Magas dimenziószámnál nehéz lehet detektálni o Alacsony dimenziós vizualizáció segíthet.")
20
Adattisztítás Hiányzó adatok (missing data, „NA”, „null”) o Hol lehet probléma? o Mesterséges feltöltés („imputation”) Több változó, mint megfigyelés/minta o Génkifejeződési vizsgálatok o Műholdképek spektrális vizsgálata o …
 Több változó, mint megfigyelés/minta o Génkifejeződési vizsgálatok o Műholdképek spektrális vizsgálata o ….")
21
Leíró statisztika

22
Vizsgált adatok alapvető jellemzői o Kvantitatív o Erősen absztrahál, „összefoglal” Egyfajta ellentéte: következtető (inferential) stat. o Megfigyelt mintán túlmutató következtetések o Pl. populáció tulajdonságaira következtetés mintából N.B.: ez egy erősen mérnöki szemléletű kurzus

23
(Folytonos) megfigyelések jellemzése
 megfigyelések jellemzése")
24
Kvartilisek szerepe „68–95–99.7 rule”

25
Boxplot (Box and whisker plot) Ez már nem fog menni Excelben. (?)
 Ez már nem fog menni Excelben. ( )")
26
Centrális tendencia és diszperzió Centrális jelleg jellemzői: o Átlag, medián, multimodalitás (illetve módus) „Diszperzió” jellemzői o Percentilisek, szórás(ok), variancia Melyik mennyire érzékeny a kiugró értékekre? Megj.: a mintaátlag vs. populáció-átlag jellegű kérdésekkel itt nem foglalkozunk o (Mi minek hogyan milyen becslője…)
.")
27
Robusztus mérőszámok Alaphalmaz o 1000 pont ~ U(1, 5) egyenletes eloszlás átlag = medián = 3 ms 3ms ± 2 ms Válaszidő Vál. medián Vál. átlag 1 pont: 20 s Új medián: sort(resp. times)[501] = 3.02 ms Új átlag: (2 * 10^4 + 3 * 10^3 )/ 1001 = 25 ms! Robusztus Nem rob.
[501] = 3.02 ms Új átlag: (2 * 10^4 + 3 * 10^3 )/ 1001 = 25 ms. Robusztus Nem rob..")
28
Minta-variancia; minta kovariancia-mátrix Mennyire robosztusak? Breakdown point (becslőé): „rossz” megfigyelések max. aránya, ami után már tetszőlegesen rossz eredményt ad
: „rossz megfigyelések max. aránya, ami után már tetszőlegesen rossz eredményt ad.")
29
Variancia, kovariancia: példa

31
Normalizálás (szórások szorzatával): Pearson-féle lineáris korrelációs koefficiens
: Pearson-féle lineáris korrelációs koefficiens")
32
Lineáris korrelációs koefficiens Egyenest most még nem illesztünk

33
Eloszlás jellemzése? {RPT: 609, 613, 913, …} {location: Peyton, Durham, …} Változók Numerikus Kategorikus Változók Numerikus Kategorikus

34
Oszlopdiagram (bar chart) Ábrázolt összefüggés: Kategorikus változó egyes értékeinek abszolút gyakorisága Adategység: Oszlop – magassága: adott érték gyakorisága Tervezői döntés: Értékkészlet darabolása?
 Ábrázolt összefüggés: Kategorikus változó egyes értékeinek abszolút gyakorisága Adategység: Oszlop – magassága: adott érték gyakorisága Tervezői döntés: Értékkészlet darabolása")
35
Hisztogram Ábrázolt összefüggés: Folytonos változó egyes értékeinek abszolút gyakorisága Adategység: Oszlop – magassága: adott érték gyakorisága Tervezői döntés: Oszlopszélesség/kezdőpont? Fontos percentilisek?

36
Sűrűségfüggvény Ha mégis kevésbé akarunk absztrahálni Problémák 1. Biztos, hogy normál eloszlású a populáció? 2. Paramétereket kell becsülnünk a mintából

37
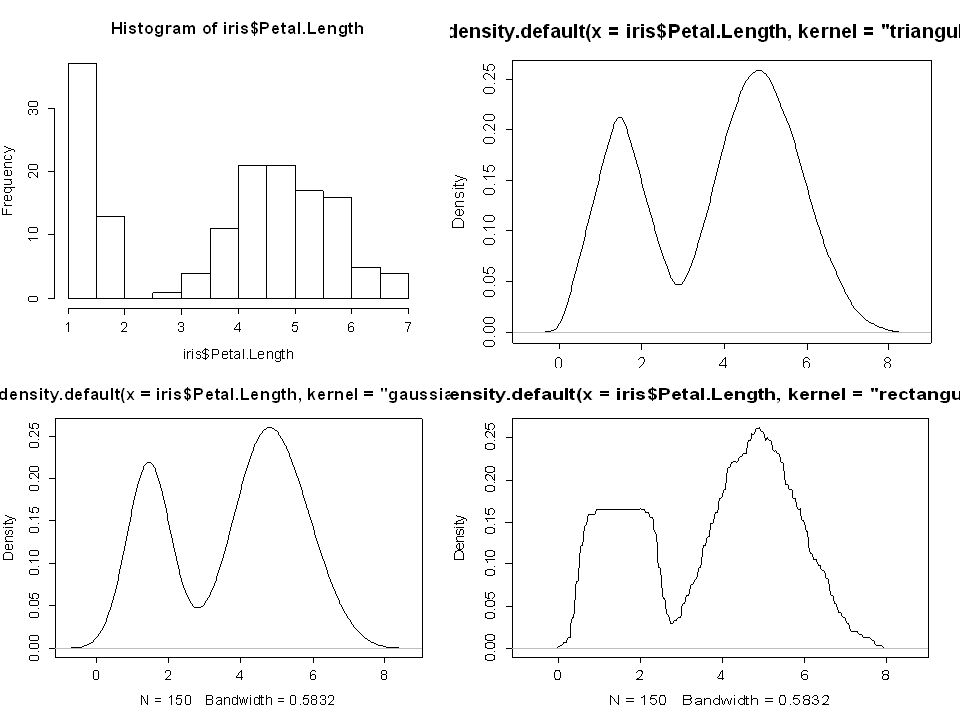
Nemparametrikus sűrűségbecslés

39
Kernel-módszerek Részletek kicsit később…

40
Problémák a hisztogrammal? Általánosságban nem elfogulatlan Akkor konzisztens, ha nem csökkentjük túl gyorsan a bin-méretet (Ronda „zárt” alak) Érzékeny például az „origó” választására A „query value” a határon „ugrik” Az ismert algoritmusok ellenére a gyakorlatban jórészt manuálisan paraméterezzük Vagy „darabos”, vagy „nem folytonos”
 Érzékeny például az „origó választására A „query value a határon „ugrik Az ismert algoritmusok ellenére a gyakorlatban jórészt manuálisan paraméterezzük Vagy „darabos , vagy „nem folytonos .")
41
Bin-szélesség hatása A többváltozós hisztogramokkal itt nem foglalkoztunk

42
Big Data és leíró statisztika? A MapReduce programozási modellt láttuk. [5]
![Big Data és leíró statisztika A MapReduce programozási modellt láttuk. [5]](http://images.slideplayer.hu/9/2653638/slides/slide_42.jpg "Big Data és leíró statisztika A MapReduce programozási modellt láttuk. [5]")
43
MapReduce és leíró statisztika? MIN/MAX/AVG… o Folytonos esetben? o Diszkrét esetben? Oszlopdiagram? Hisztogram? Kernel sűrűség-közelítés nagy adatra? o Tényleg nagy adatra drága „lekérdezni”: O(n) tag! o SIGMOD 2013: approximáció a minták csak egy mintáján számolással
 tag. o SIGMOD 2013: approximáció a minták csak egy mintáján számolással.")
44
Leíró statisztikák MapReduce becslése Közelítő hisztogram újrahasznosítása o Kvantilisek becslése o Medián becslése o … De hogyan? Faktor/nominális változók: wordcount! Variancia/szórás: pl. két menetben o Empirikus átlag kell hozzá Kovariancia, korreláció: két menetben, egy változó- párra egyszerű

45
Következtető statisztika

47
Mintavételezés Minta kiértékelés Adatfelvétel Teljes populáció Reprezentatív minta EDA Hipotézis Val.ség, konf. int. stb. Következtetés Adatsor

48
Ökölszabályok LLN (Law of Large Numbers) o Ha a kísérletek száma tart a végtelenhez, az előfordulási gyakoriság az elméleti valószínűséghez konvergál
 o Ha a kísérletek száma tart a végtelenhez, az előfordulási gyakoriság az elméleti valószínűséghez konvergál")
49
Ökölszabályok

50
? Magyarországi kamaszlányok Békés Heves Vas

51
? Magyarországi kamaszlányok Békés Heves Vas

52
Következtető statisztika Mintavételezés Minta kiértékelés Adatfelvétel Teljes populáció Reprezentatív minta EDA Hipotézis Val.ség, konf. int. stb. Következtetés Adatsor

53
Minta kiértékelés EDA ~ nyomozás Kiértékelés ~ a per maga o H 0 : alapfeltevés a vádlott ártatlan o H A : alapfeltevés ellentéte a vádlott bűnös o Kiértékelés: ha az alapfeltevés igaz, mennyire valószínű, hogy a kapott adatot tároltuk el?

54
Mit tesztelünk tipikusan? Parametrikus tesztek o Egy minta eloszlás egy paraméterét próbáljuk kitalálni o Két minta eloszlásának a paramétere megegyezik-e? Nemparametrikus tesztek o Illeszkedésvizsgálat adott eloszlású-e egy minta? o Függetlenségi vizsgálat független-e két minta? o Homogenitásvizsgálat két minta eloszlása megegyezik-e?

55
Következtető statisztika Mintavételezés Minta kiértékelés Adatfelvétel Teljes populáció Reprezentatív minta EDA Hipotézis Val.ség, konf. int. stb. Következtetés Adatsor

56
Következtetés Döntési bemenet o Valami küszöbérték Adatsor típusa o Megfigyelési tanulmány (observational study) o Kísérlet (experiment) Különbség: a köztes változók eliminálása
 o Kísérlet (experiment) Különbség: a köztes változók eliminálása")
57
Esettanulmány Forrás: http://usatoday30.usatoday.com/news/health/2005-09-08-cereal-slimming_x.htm „Girls who ate breakfast of any type had a lower average body mass index, a common obesity gauge, than those who said they didn't. The index was even lower for girls who said they ate cereal for breakfast.„

58
Esettanulmány Forrás: http://usatoday30.usatoday.com/news/health/2005-09-08-cereal-slimming_x.htm 1. „Breakfast, cereal keep girls slim” 2. „Being slim causes girls to eat breakfast„ ? 3. „A confounding variable is responsible for both”

59
Következtetés Döntési bemenet o Valami küszöbérték Adatsor típusa o Megfigyelési tanulmány (observational study) A köztes változók kiléte bizonytalan Csak korreláció, kauzális következtetések nem o Kísérlet (experiment) A köztes változókat kiszűrtük (mintavételezés!) Kauzális következtetések is
 A köztes változók kiléte bizonytalan Csak korreláció, kauzális következtetések nem o Kísérlet (experiment) A köztes változókat kiszűrtük (mintavételezés!) Kauzális következtetések is")
60
Adatelemzési módszerek

61
Adatbányászati építőkövek Asszociációs szabályok Regresszió Klaszterezés Osztályozás

62
Klaszterezés

63
Asszociációs szabályok

64
Osztályozás

65
Regresszió

66
Adatok Adat: nyers tények o Numerikus érték, szöveg, görbe, 2D kép, … Többváltozós adat(készlet), multivariate data: o Mérések, megfigyelések, válaszok sokasága kiválasztott változók egy készletén Többváltozós adatelemzésben tipikusan: táblák o data matrix, data array, data frame, spreadsheet… o ! Ez „csak” a „klasszikus” többváltozós statisztika o r x n mátrix (megfigyelés/változó)
.")
67
Adattípusok Indexelő (indexing) vagy azonosító (identifier) változók o Különleges eset: elsődleges és idegen kulcsok Bináris (indikátor) Bool: „nem ismert” érték is lehet Nominális o Sztring o Általában osztályozás és kategorizálás címkéi Ordinális o (Lineárisan) rendezett Egészértékű, folytonos (numerikus/decimális)
 vagy azonosító (identifier) változók o Különleges eset: elsődleges és idegen kulcsok Bináris (indikátor) Bool: „nem ismert érték is lehet Nominális o Sztring o Általában osztályozás és kategorizálás címkéi Ordinális o (Lineárisan) rendezett Egészértékű, folytonos (numerikus/decimális)")
68
„The Curse of Dimensionality”

69
MapReduce és hisztogram (közelítés) Tfh. Nem feltételezhetjük az ún. range partitioning-et a vizsgált változóra o Pl. óriási CSV-t dolgozunk fel – Hadoop + HDFS o Különben nem lenne problémánk Partition Incremental Discretization (PiD) [4] o Módosítva [5] Layer1 o Párhuzamosan több hisztogram építése o Azonos (igen kicsi) szélességű bin-ekkel kezdünk feltételezett intervallumon o Egy bin átlép egy thresholdot: split o N.B. adatfolyamra is működik Layer2: Layer1 hisztogramok összefűzése
 [4] o Módosítva [5] Layer1 o Párhuzamosan több hisztogram építése o Azonos (igen kicsi) szélességű bin-ekkel kezdünk feltételezett intervallumon o Egy bin átlép egy thresholdot: split o N.B. adatfolyamra is működik Layer2: Layer1 hisztogramok összefűzése.")
70
Layer1 karbantartás [5]
![Layer1 karbantartás [5]](http://images.slideplayer.hu/9/2653638/slides/slide_70.jpg "Layer1 karbantartás [5]")
71
Layer1 karbantartás [4]
![Layer1 karbantartás [4]](http://images.slideplayer.hu/9/2653638/slides/slide_71.jpg "Layer1 karbantartás [4]")
73
Összefűzés - hibaforrások Csak a Layer1 töréspontjai Split pontatlan számlálók + „split” az összefűzés során

74
Adattípusok Fix (fixed): o Tudatosan előre rögzített, vagy o „Kauzális” a jelenség tekintetében o Ált. indexelő Stochasztikus: o Véletlenszerűen kerül(t) kiválasztásra az ért. tartományból o Lásd pl. Bevezetés a matematikai statisztikába Bemeneti (input, predictor, „X”): o Statisztikai kísérlet rögzíti vagy vezérli Kontextus – a kísérletet jellemzi Viselkedési – maga a mért érték Kimeneti (output, response, „Y”): o Stochasztikus és a bemenettől függ
 kiválasztásra az ért. tartományból o Lásd pl. Bevezetés a matematikai statisztikába Bemeneti (input, predictor, „X ): o Statisztikai kísérlet rögzíti vagy vezérli Kontextus – a kísérletet jellemzi Viselkedési – maga a mért érték Kimeneti (output, response, „Y ): o Stochasztikus és a bemenettől függ.")
75
Magfüggvény-példák [4]
![Magfüggvény-példák [4]](http://images.slideplayer.hu/9/2653638/slides/slide_75.jpg "Magfüggvény-példák [4]")
77
Források [1] Izenman, A. J. (2008). Modern Multivariate Statistical Techniques. New York, NY: Springer New York. doi:10.1007/978-0-387-78189-1 [2] Zheng, Y., Jestes, J., Phillips, J. M., & Li, F. (2013). Quality and efficiency for kernel density estimates in large data. In Proceedings of the 2013 international conference on Management of data - SIGMOD ’13 (p. 433). New York, New York, USA: ACM Press. doi:10.1145/2463676.2465319 [3] Rajaraman, A., & Ullman, J. D. (2011). Mining of Massive Datasets. Cambridge: Cambridge University Press. doi:10.1017/CBO9781139058452 [4] Gama, J., & Pinto, C. (2006). Discretization from data streams. In Proceedings of the 2006 ACM symposium on Applied computing - SAC ’06 (p. 662). New York, New York, USA: ACM Press. doi:10.1145/1141277.1141429 [5] http://www.slideshare.net/Hadoop_Summit/creating-histograms-from-data- stream-via-map-reducehttp://www.slideshare.net/Hadoop_Summit/creating-histograms-from-data- stream-via-map-reduce
![Források [1] Izenman, A. J. (2008). Modern Multivariate Statistical Techniques.](http://images.slideplayer.hu/9/2653638/slides/slide_77.jpg "New York, NY: Springer New York. doi: / [2] Zheng, Y., Jestes, J., Phillips, J. M., & Li, F. (2013). Quality and efficiency for kernel density estimates in large data. In Proceedings of the 2013 international conference on Management of data - SIGMOD ’13 (p. 433). New York, New York, USA: ACM Press. doi: / [3] Rajaraman, A., & Ullman, J. D. (2011). Mining of Massive Datasets. Cambridge: Cambridge University Press. doi: /CBO [4] Gama, J., & Pinto, C. (2006). Discretization from data streams. In Proceedings of the 2006 ACM symposium on Applied computing - SAC ’06 (p. 662). New York, New York, USA: ACM Press. doi: / [5] stream-via-map-reducehttp:// stream-via-map-reduce.")
Hasonló előadás














.>")

>")




 3., mintavételi információk alapján megállapítások, következtetések.>")


