Előadást letölteni
1
Budapesti Műszaki és Gazdaságtudományi Egyetem Méréstechnika és Információs Rendszerek Tanszék ‚Big Data’ elemzési módszerek 2013.09.09.

2
A félévről Előadók o dr. Pataricza András o Dr. Horváth Gábor o Kocsis Imre (op. felelős) ikocsis@mit.bme.hu ikocsis@mit.bme.hu, IB418, (+36 1 463) 2006 ikocsis@mit.bme.hu 1 ZH (~félév közepén) Kötelező házi feladat o Részletek: TBA
 IB418, ( ) 2006 1 ZH (~félév közepén) Kötelező házi feladat o Részletek: TBA.")
3
Google Trends: „Big Data” Ez is egy Big Data feladat

4
Definíció [1] Adatkészletek, melyek mérete nagyobb, mint amit regisztrálni, tárolni, kezelni és elemezni tudunk a „tipikus” (adatbáziskezelő) szoftverekkel.
![Definíció [1] Adatkészletek, melyek mérete nagyobb, mint amit regisztrálni, tárolni, kezelni és elemezni tudunk a „tipikus (adatbáziskezelő) szoftverekkel.](http://images.slideplayer.hu/8/2197199/slides/slide_4.jpg "Definíció [1] Adatkészletek, melyek mérete nagyobb, mint amit regisztrálni, tárolni, kezelni és elemezni tudunk a „tipikus (adatbáziskezelő) szoftverekkel.")
5
Hol van ennyi adat? Időben/populáción ismétlődő megfigyelések o Web logok o Telekommunikációs hálózatok o Kis(?)kereskedelem o Tudományos kísérletek (LHC, neurológia, genomika, …) o Elosztott szenzorhálózatok (pl. „smart metering”) o Járművek fedélzeti szenzorai o Számítógépes infrastruktúrák o … Gráfok, hálózatok o Közösségi szolgáltatások
kereskedelem o Tudományos kísérletek (LHC, neurológia, genomika, …) o Elosztott szenzorhálózatok (pl. „smart metering ) o Járművek fedélzeti szenzorai o Számítógépes infrastruktúrák o … Gráfok, hálózatok o Közösségi szolgáltatások.")
6
Hol van ennyi adat? Modern repülőgépek: ~10 TB/hajtómű/fél óra Facebook: 2.5 milliárd „like” egy nap Kollégiumi hálózat: pár GB-nyi Netflow rekord egy csendes hétvégén

7
Tárolási kapacitás a világon [1]
![Tárolási kapacitás a világon [1]](http://images.slideplayer.hu/8/2197199/slides/slide_7.jpg "Tárolási kapacitás a világon [1]")
8
Számítási kapacitás a világon [1]
![Számítási kapacitás a világon [1]](http://images.slideplayer.hu/8/2197199/slides/slide_8.jpg "Számítási kapacitás a világon [1]")
9
Nagyvállalatok által tárolt adatok [1]
![Nagyvállalatok által tárolt adatok [1]](http://images.slideplayer.hu/8/2197199/slides/slide_9.jpg "Nagyvállalatok által tárolt adatok [1]")
10
Néhány alkalmazási minta Létező szenzor-instrumentáció kiaknázása ‚IT for IT’: loganalízis, diagnosztika, hibaelőrejelzés, kapacitásmenedzsment, … Közösségi média elemzése o Pl. PeerIndex Csalásfelderítés (fraud detection) o ‚Ki vesz jegygyűrűt hajnal 4-kor?’ o N.B. ritka események; az algoritmika részben újszerű
 o ‚Ki vesz jegygyűrűt hajnal 4-kor ’ o N.B. ritka események; az algoritmika részben újszerű.")
11
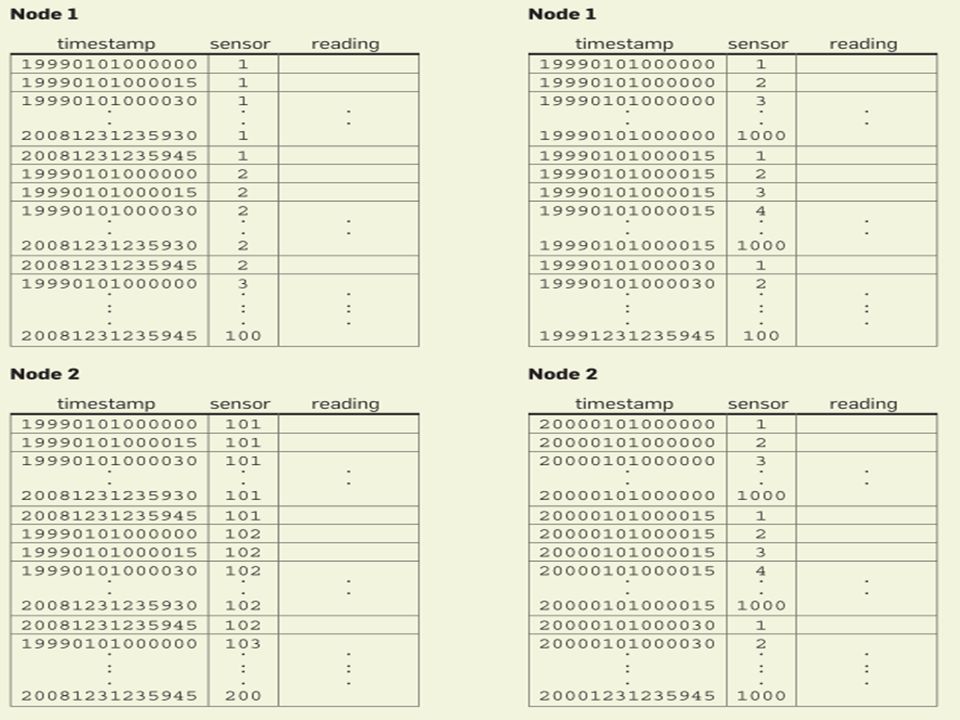
Virtual Desktop Infrastructure: kapacitástervezés ~2 dozen VM/host ~20 ESX metrics/VM (CPU, memory, net) ~2 dozen VM/host ~20 ESX metrics/VM (CPU, memory, net) ~1 dozen host/cluster ~50 ESX metrics/host ~1 dozen host/cluster ~50 ESX metrics/host Cluster: ~70 metrics (derived by aggregation)
 ~2 dozen VM/host ~20 ESX metrics/VM (CPU, memory, net) ~1 dozen host/cluster ~50 ESX metrics/host ~1 dozen host/cluster ~50 ESX metrics/host Cluster: ~70 metrics (derived by aggregation)")
12
Példa: kapacitástervezés

13
Alternatív definíció: Big Data jellemzők [2] ‚Volume’: igen nagy mennyiségű adat ‚Variety’: nagyszámú forrás és/vagy nemstrukturált/részben strukturált adatok ‚Velocity’: a ‚Return on Data’ (ROD) a lassú feldolgozással csökken o Főleg ‚streaming’ problémáknál o Ellentéte: ‚at rest’ Big Data problémák ‚Veracity’: nagymennyiségű zaj o Pl. Twitter ‚spam’
![Alternatív definíció: Big Data jellemzők [2] ‚Volume’: igen nagy mennyiségű adat ‚Variety’: nagyszámú forrás és/vagy nemstrukturált/részben strukturált adatok ‚Velocity’: a ‚Return on Data’ (ROD) a lassú feldolgozással csökken o Főleg ‚streaming’ problémáknál o Ellentéte: ‚at rest’ Big Data problémák ‚Veracity’: nagymennyiségű zaj o Pl.](http://images.slideplayer.hu/8/2197199/slides/slide_13.jpg "Twitter ‚spam’.")
14
RDBMS? ‚Big Data’ problémáknál általában létezik természetes (részleges) rendezési szempont o Természetes: a nemtriviális analízisek ebben a sorrendben működnek o Pl. idő (idősor-analízisek) Relációs modell: sorok sorrendje anatéma Következmény: véletlenszerű hozzáférés diszkről Az „optimális” hozzáférési mintához képest lassú
 rendezési szempont o Természetes: a nemtriviális analízisek ebben a sorrendben működnek o Pl. idő (idősor-analízisek) Relációs modell: sorok sorrendje anatéma Következmény: véletlenszerű hozzáférés diszkről Az „optimális hozzáférési mintához képest lassú.")
15
Normalizált séma: lassíthat! [3]
![Normalizált séma: lassíthat! [3]](http://images.slideplayer.hu/8/2197199/slides/slide_15.jpg "Normalizált séma: lassíthat! [3]")
16
Nagyvállalati adattárházak? Jellemzően igen komoly ETL „Válaszidő”-követelmények o Régi adatok aggregálása/törlése/archiválása Strukturálatlan adatok nem jellemzőek Drágák… Nem lehet későbbi analízisre „leborítani” az adatokat

17
Analízis eszközök? Példa: R Kulcsrakész függvények mediántól a neurális hálókig De: csak memóriában tárolt adattípusok, nem hatékony memóriakezelés

18
Vizualizáció? A klasszikus megoldások erősen támaszkodnak létező tárolási és analízis-megoldásokra Jellemzően statisztikai leképezések o Önmagában Big Data problémára vezethető vissza Feltáró adatanalízis (EDA): GPU támogatás?
: GPU támogatás .")
21
Elosztott számítástechnika Big Data: a ma alkalmazott stratégia COTS elosztott rendszerek alkalmazása o Kivételek vannak; lásd IBM Netezza 8 db nyolcmagos gép jóval olcsóbb, mint egy 64 magos Modern hálózati technológiák: o Memóriánál lassabb o Helyi diszk áteresztőképességénél/válaszidejénél nem feltétlenül! A tárolás és a feldolgozás is elosztott

22
Felhő számítástechnika A „számítási felhők” egy modell, amely lehetővé teszi a hálózaton keresztül való, kényelmes és széles körű hozzáférést konfigurálható számítási erőforrások egy megosztott halmazához.

23
Amazon Web Services

24
Alapvető kérdések Elosztott platformon párhuzamosítás szükséges Hatékony feldolgozáshoz továbbra is referenciális lokalitás kell Bár a feldolgozás „közel vihető az adathoz”, az adatterítés logikája befolyásolja a teljesítményt o Pl. csak egy csomópont dolgozik

26
Big Data == Hadoop? Google MapReduce és GFS Apache Hadoop Nyílt forráskódú, Java alapú keretrendszer Hadoop Distributed File System (HDFS) MapReduce programozási paradigma Ráépülő/kiegészítő projektek: Cassandra, Chukwa, Hbase, Hive, Mahout, Pig, ZooKeeper…
 MapReduce programozási paradigma Ráépülő/kiegészítő projektek: Cassandra, Chukwa, Hbase, Hive, Mahout, Pig, ZooKeeper….")
27
HDFS ~Klasszikus állományrendszer Nagy (64MB) blokkok, szétterítve és replikálva ~Klasszikus állományrendszer Nagy (64MB) blokkok, szétterítve és replikálva
 blokkok, szétterítve és replikálva ~Klasszikus állományrendszer Nagy (64MB) blokkok, szétterítve és replikálva")
28
Hadoop

29
MapReduce [6]
![MapReduce [6]](http://images.slideplayer.hu/8/2197199/slides/slide_29.jpg "MapReduce [6]")
30
MapReduce: szavak számolása szövegben [7]
![MapReduce: szavak számolása szövegben [7]](http://images.slideplayer.hu/8/2197199/slides/slide_30.jpg "MapReduce: szavak számolása szövegben [7]")
31
MapReduce, mint párhuzamosítási minta Számos probléma jól megfogalmazható MapReduce szemléletben o Mátrix-mátrix és mátrix-vektor szorzás o Relációalgebra o Korreláció o … Ezekről később beszélünk

32
Hadoop ökoszisztéma: egyszerűsített áttekintés

33
Big Data =/= Hadoop (ökoszisztéma) Adatfolyamok! o Hadoop: batch & ‚at rest’
 Adatfolyamok! o Hadoop: batch & ‚at rest’")
34
Big Data =/= Hadoop (ökoszisztéma) Elemző eszközök kiterjesztései o ‚File backed’ o Adatbázis-integrált o Vitatható, hogy ‚igazi’ Big Data-e Célhardver o IBM Netezza Gráfproblémák kezelése o Nem csak paraméterbecslés és tulajdonságvizsgálat; mintaillesztés is
 Elemző eszközök kiterjesztései o ‚File backed’ o Adatbázis-integrált o Vitatható, hogy ‚igazi’ Big Data-e Célhardver o IBM Netezza Gráfproblémák kezelése o Nem csak paraméterbecslés és tulajdonságvizsgálat; mintaillesztés is")
35
Lehetőségek [1]
![Lehetőségek [1]](http://images.slideplayer.hu/8/2197199/slides/slide_35.jpg "Lehetőségek [1]")
36
Források [1] Manyika, J., Chui, M., Brown, B., & Bughin, J. (2011). Big data: The next frontier for innovation, competition, and productivity. Retrieved from http://www.citeulike.org/group/18242/article/9341321 [2] Zikopoulous, P., Deroos, D., Parasuraman, K., Deutsch, T., Corrigan, D., & Giles, J. (2013). Harness the Power of Big Data. McGraw-Hill. Retrieved from http://medcontent.metapress.com/index/A65RM03P4874243N.pdf [3] Jacobs, A. (2009). The pathologies of big data. Communications of the ACM, 52(8), 36. doi:10.1145/1536616.1536632 [4] http://www.ibm.com/developerworks/library/wa-introhdfs/http://www.ibm.com/developerworks/library/wa-introhdfs/ [5] Borkar, V., Carey, M. J., & Li, C. (2012). Inside “Big Data management.” In Proceedings of the 15th International Conference on Extending Database Technology - EDBT ’12 (pp. 3–14). New York, New York, USA: ACM Press. doi:10.1145/2247596.2247598 [6] Rajaraman, A., & Ullman, J. D. (2011). Mining of Massive Datasets. Cambridge: Cambridge University Press. doi:10.1017/CBO9781139058452 [7] http://research.google.com/archive/mapreduce-osdi04-slides/index.htmlhttp://research.google.com/archive/mapreduce-osdi04-slides/index.html
![Források [1] Manyika, J., Chui, M., Brown, B., & Bughin, J.](http://images.slideplayer.hu/8/2197199/slides/slide_36.jpg "(2011). Big data: The next frontier for innovation, competition, and productivity. Retrieved from [2] Zikopoulous, P., Deroos, D., Parasuraman, K., Deutsch, T., Corrigan, D., & Giles, J. (2013). Harness the Power of Big Data. McGraw-Hill. Retrieved from [3] Jacobs, A. (2009). The pathologies of big data. Communications of the ACM, 52(8), 36. doi: / [4] [5] Borkar, V., Carey, M. J., & Li, C. (2012). Inside Big Data management. In Proceedings of the 15th International Conference on Extending Database Technology - EDBT ’12 (pp. 3–14). New York, New York, USA: ACM Press. doi: / [6] Rajaraman, A., & Ullman, J. D. (2011). Mining of Massive Datasets. Cambridge: Cambridge University Press. doi: /CBO [7]")




 Budapest>")

















