Előadást letölteni
1
Rövid bevezetés a sokváltozós statisztikákba Összeállította: Elek Zoltán

2
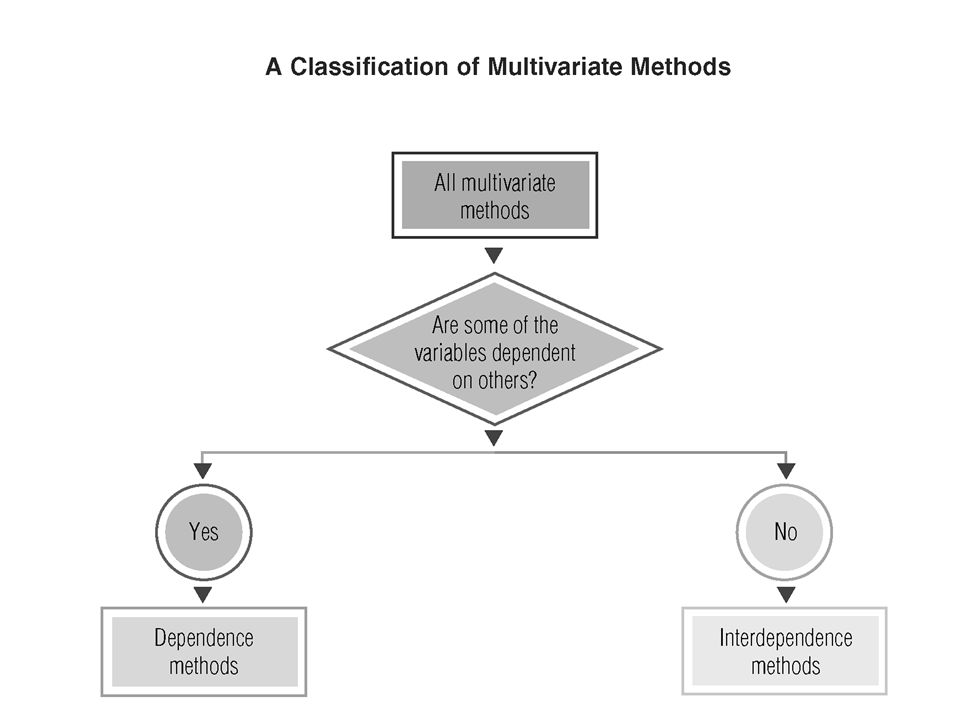
Sokváltozós módszerek Kiterjesztése az egyváltozós és kétváltozós módszereknek Egy idejű elemzés/kezelése a faj-minta- környezeti változó adatoknak

3
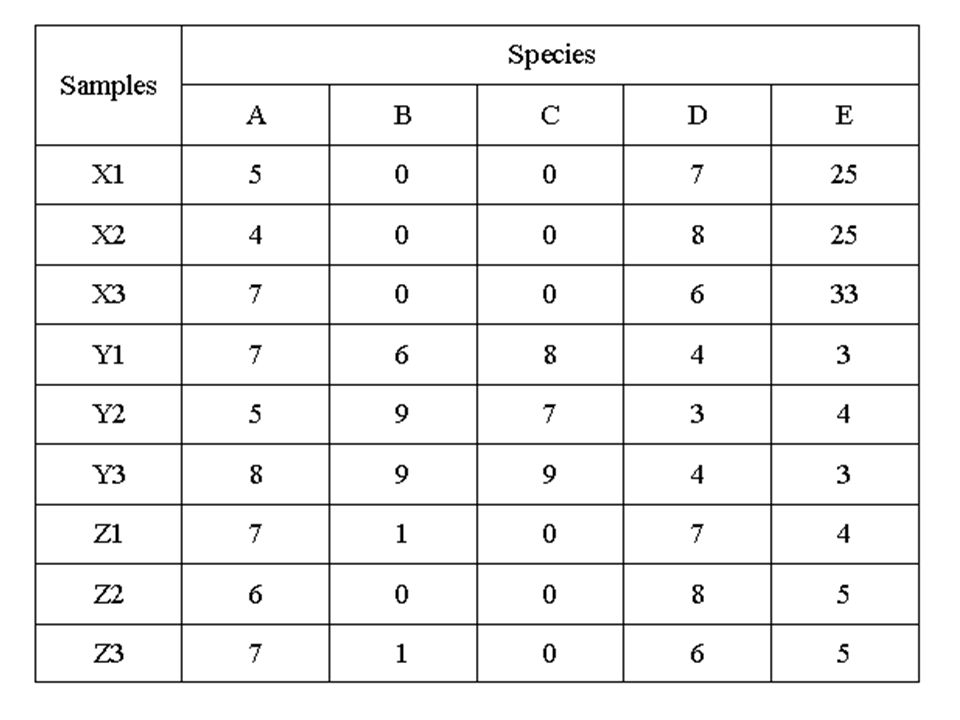
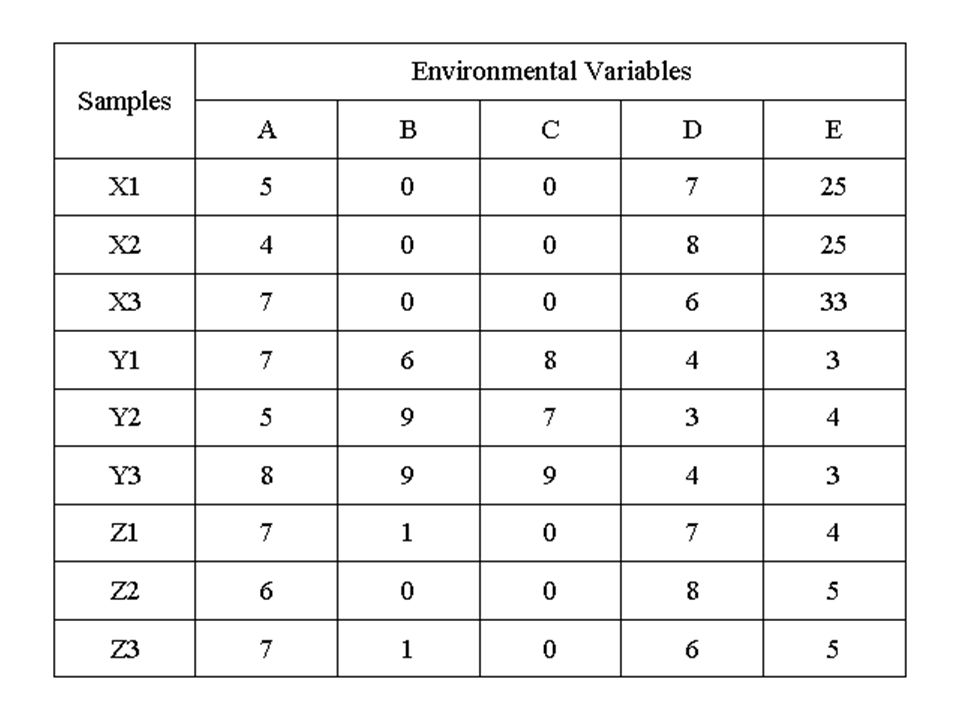
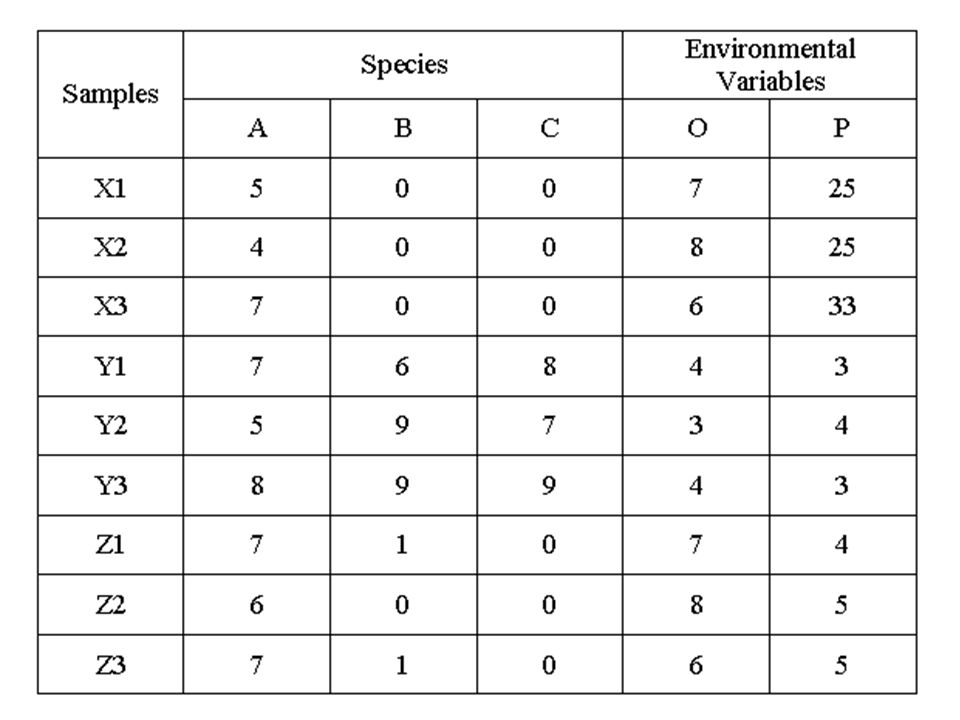
Sokváltozós adatok… Egyedek morfometriai adatai (pl.: hossz) Egyedek fiziológiai adatai (pl.: vérnyomás, pulzus) Környezeti adatok (pl.: légnyomás, hőmérséklet) Fajszám, egyedszám stb… Az adatok általános formulája → adatmátrix
 Egyedek fiziológiai adatai (pl.: vérnyomás, pulzus) Környezeti adatok (pl.: légnyomás, hőmérséklet) Fajszám, egyedszám stb… Az adatok általános formulája → adatmátrix")
7
Szimilaritás (S) a minták között 0 - 100 % vagy 0 - 1 S = 100%, teljes azonosság (identikus minták) S = 0, teljesen különböző minták (nincsenek közös fajok)
 a minták között % vagy S = 100%, teljes azonosság (identikus minták) S = 0, teljesen különböző minták (nincsenek közös fajok)")
8
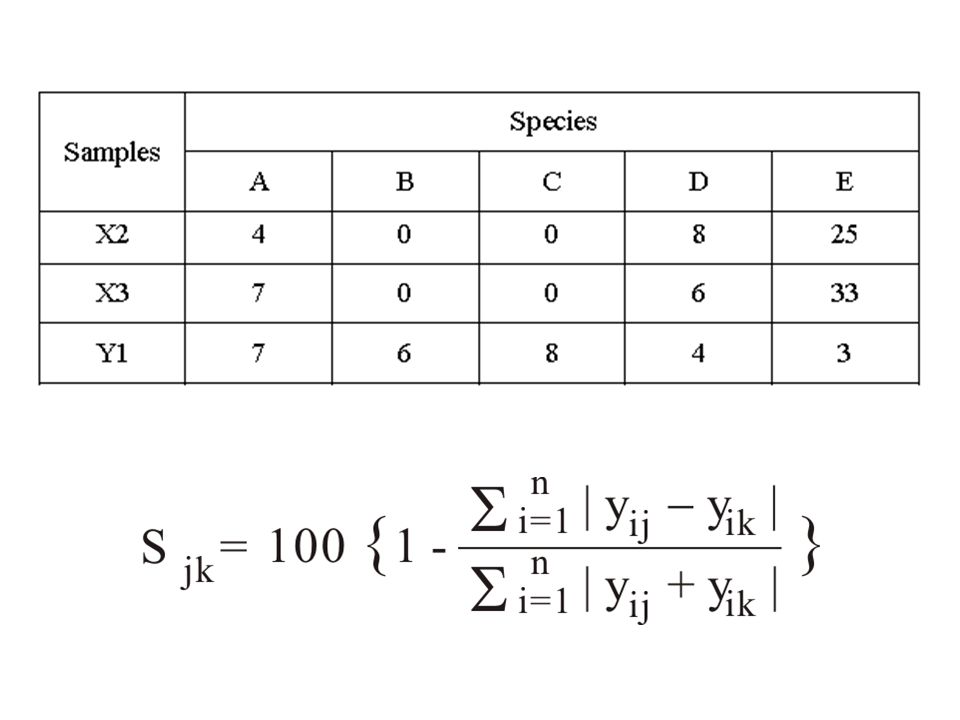
Bray-Curtis koefficiens (Bray & Curtis, 1957) Első terresztriális ökológiai rendszerekre kifejlesztett szimilaritás függvény ahol, y ij - „i”faj egyedszáma a „j” mintában, y ik - „i”faj egyedszáma a „k” mintában, n - teljes mintászám
 Első terresztriális ökológiai rendszerekre kifejlesztett szimilaritás függvény ahol, y ij - „i faj egyedszáma a „j mintában, y ik - „i faj egyedszáma a „k mintában, n - teljes mintászám")
10
S X2 X3 = 100 { 1 - 3+0+0+2+8 11+0+0+14+58 } = 84 S X3 Y1 = 100 { 1 - 0+6+8+2+30 14+6+8+10+36 } = 38

11
Faj szimilaritás mátrix

12
Transzformációk Megfelelő adatok paraméteres próbákhoz (pl.: variancia heterogenitás és ANOVA) Súlyozni a ritka és a gyakori fajok hozzájárulását nem-paraméteres sokváltozós elemzésekben
 Súlyozni a ritka és a gyakori fajok hozzájárulását nem-paraméteres sokváltozós elemzésekben")
13
Miért? Súlyozni a ritka és a gyakori fajok hozzájárulását A transzformálatlan és transzformált adatok eltérő eredményeket adhatnak diszimilaritás számítása során (minták között) Hatás az nMDS-re.
 Hatás az nMDS-re..")
14
Transzformáció sokváltozós statisztikákban négyzetgyök negyedikgyök / Log (1+y) Prezencia/Abszencia bizonytalanság Közepes gyakoriságú fajok Ritka fajok Nem túl gyakori
 Prezencia/Abszencia bizonytalanság Közepes gyakoriságú fajok Ritka fajok Nem túl gyakori")
15
Faj szimilaritás mátrix - transzformált

16
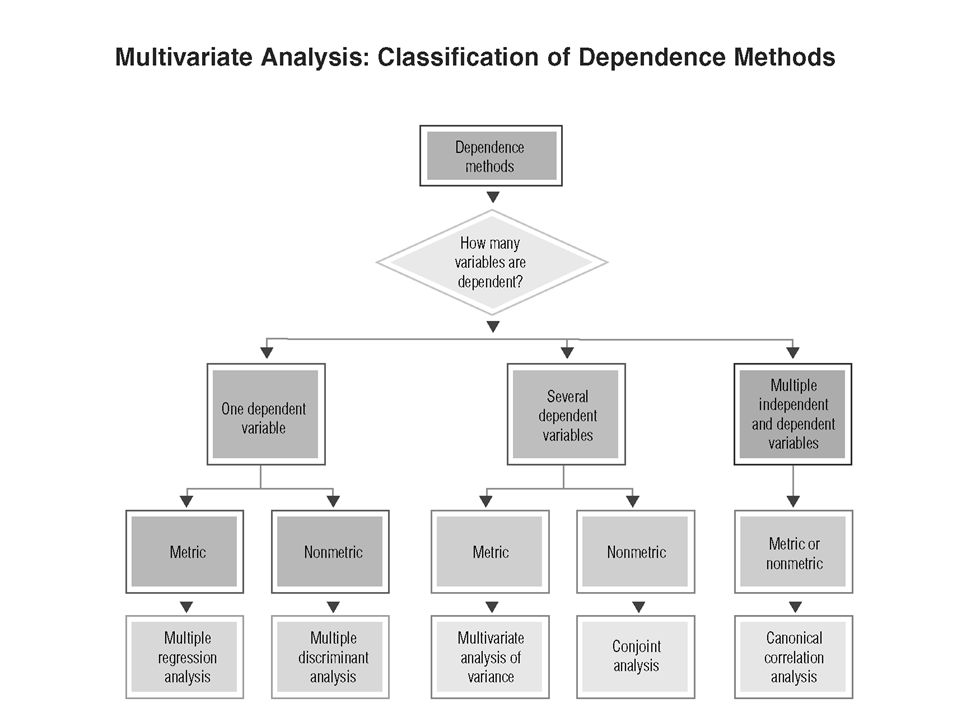
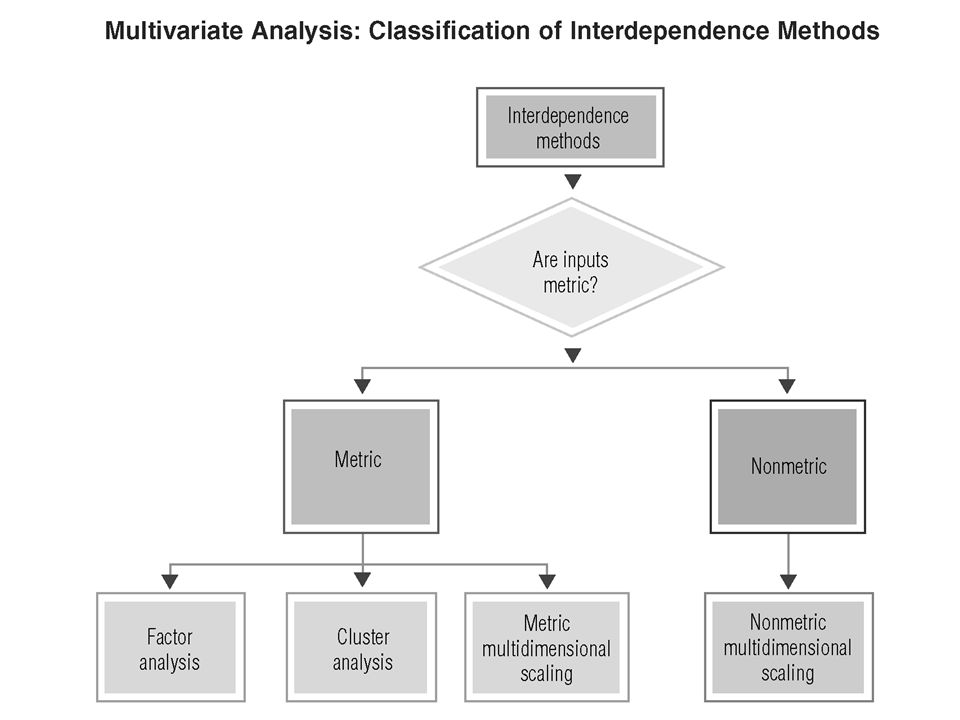
Sokváltozós technikák A leggyakoribbak: Klaszter elemzés Ordináció Pl.: diszkriminancia elemzés

17
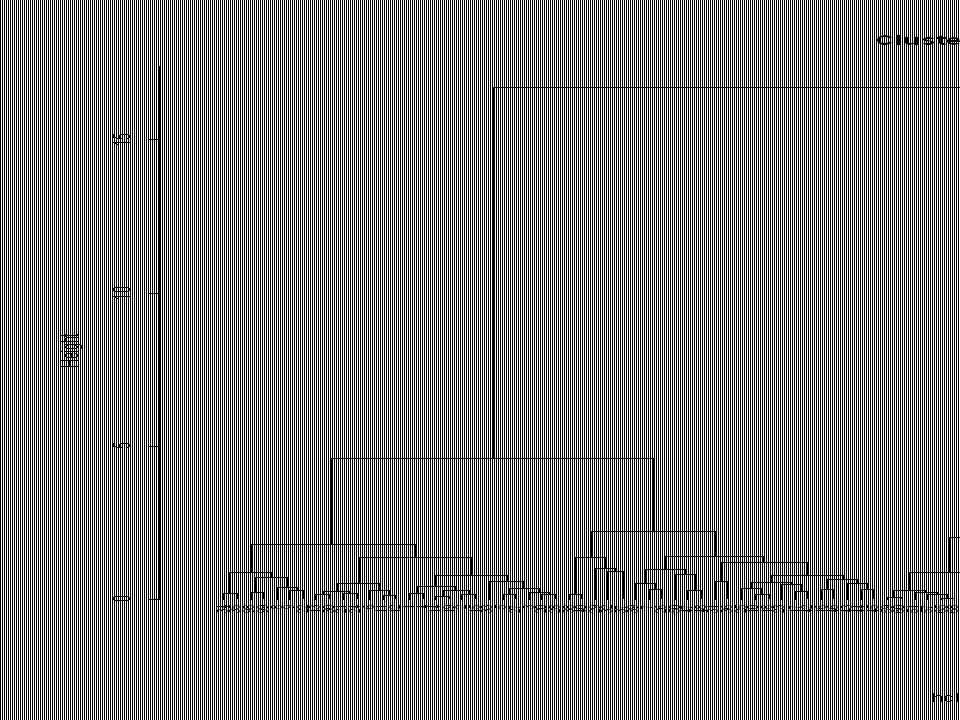
Klaszter elemzés A minták csoportokba helyezése (terület, fajok, vagy környezeti változók) a hasonlóságuk alapján. A minták a csoportokon belül jobban hasonlítanak, mint a csoportok között

18
Dendrogram Minták

19
Ordináció Grafikus technika Ordinációs ábra (általában két vagy három dimenziós) A pontok közötti relatív távolság arányos a minták között számított hasonlósággal
 A pontok közötti relatív távolság arányos a minták között számított hasonlósággal")
20
Az ordináció típusai Indirekt grádiens elemzés Csak biológiai adatok - faj/abundancia, minta mátrix A környezeti adatokat ez követően lehet korreláltani a tengelyekkel Direkt grádiens elemzés Környezeti és faj/abundancia adatok

21
Including: Principle Component Analysis (PCA) Correspondence Analysis (CA) Detrended Correspondence Analysis (DCA) Non-metric Multi-dimensional Scaling (nMDS) Indirekt grádiens elemzés Direct gradient analysis Including: Redundancy Analysis (RD) Canonical Correspondence Analysis (CCA) Detrended Canonical Correspondence Analysis (DCCA) Főkomponens analízis (PCA) Nem-metrikus skálázás (nMDS)
 Correspondence Analysis (CA) Detrended Correspondence Analysis (DCA) Non-metric Multi-dimensional Scaling (nMDS) Indirekt grádiens elemzés Direct gradient analysis Including: Redundancy Analysis (RD) Canonical Correspondence Analysis (CCA) Detrended Canonical Correspondence Analysis (DCCA) Főkomponens analízis (PCA) Nem-metrikus skálázás (nMDS)")
22
PCA Eredeti adatok Első tengely (PC1) Best-fit curve Source: Clarke, K. R. & Warwick, R. M. (1994) Change in Marine Communities: an Approach to Statistical Analysis and Interpretation. Plymouth Marine Laboratory, Plymouth: 144pp.
 Change in Marine Communities: an Approach to Statistical Analysis and Interpretation. Plymouth Marine Laboratory, Plymouth: 144pp..")
23
Második tengely (PC2) – merőleges a PC1 (i.e. korrelálatlan / ortogonális) forgatás
 – merőleges a PC1 (i.e. korrelálatlan / ortogonális) forgatás")
24
Harmadik tengely (PC3)
")
26
Eigenvalues PC Eigenvalues %Variation Cum.%Variation 1 3.39 67.8 67.8 2 0.92 18.4 86.1 3 0.56 11.2 97.4 4 0.11 2.1 99.5 5 0.02 0.5 100.0 Eigenvectors (Coefficients in the linear combinations of variables making up PC's) Variable PC1 PC2 PC3 PC4 PC5 A 0.269 0.823 0.485 -0.088 -0.092 B 0.521 -0.264 -0.018 -0.143 -0.799 C 0.515 -0.226 0.082 -0.635 0.523 D -0.499 0.227 -0.292 -0.739 -0.261 E -0.377 -0.388 0.820 -0.150 -0.109 Species
 Variable PC1 PC2 PC3 PC4 PC5 A B C D E Species")
28
PCA feltételek Lineális összefüggés a változók között A változók normalitása Az ökológiai adatok ritkán felelnek meg ezeknek a feltételeknek…

29
Sokdimenziós skálázás (MDS) Sokváltozós adatelemzési technika, A minták közötti összefüggések vizualizálása, alacsony (két) dimenziós térben Két típus: metrikus és nem-metrikus
 Sokváltozós adatelemzési technika, A minták közötti összefüggések vizualizálása, alacsony (két) dimenziós térben Két típus: metrikus és nem-metrikus")
30
Metrikus MDS: - Adatok-intervallum vagy arányskála - kvantitatív nem-metrikus MDS (nMDS) - Rang-jellegű adatok - kvantitatív vagy kvalitatív
 - Rang-jellegű adatok - kvantitatív vagy kvalitatív")
31
Előnyök - nMDS Az ordináció rang-jellegű szimilraritás/diszimilaritás adatokon alapszik a mintákra vonatkoztatva Ordinális skálás adatok is használhatók

32
Bray-Curtis similarity from Clarke & Warwick, 1994

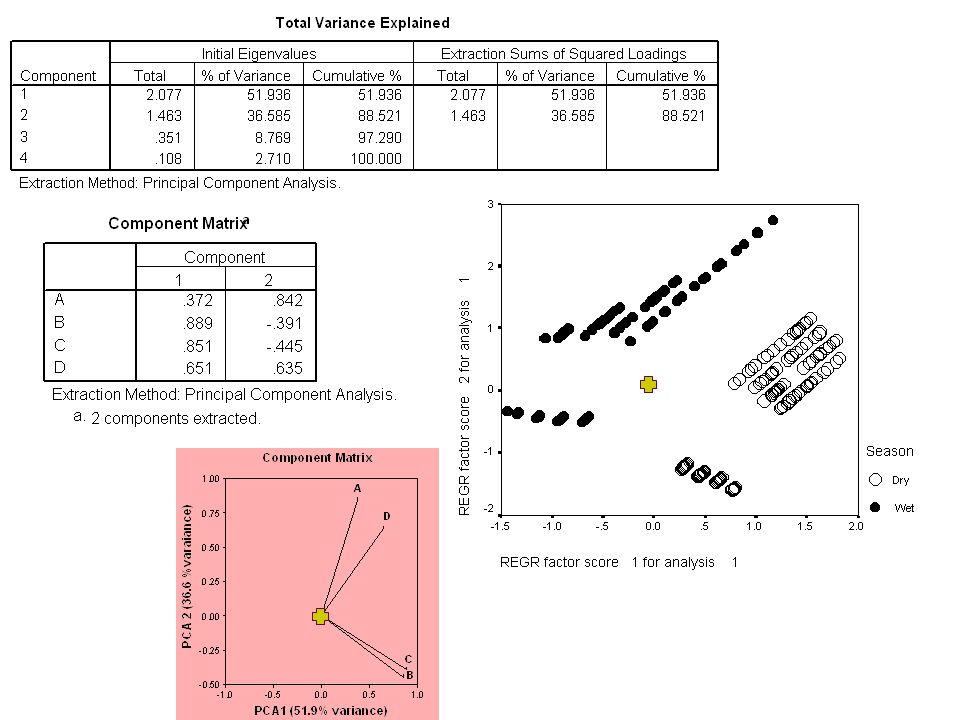
33
Példa…. Urbanizáció és futóbogarak

34
Távolság mátrixok… dist… dist <- dist(dk, method=„…”)
")
35
dist(x, method= "euclidean",diag=FALSE, upper=FALSE, p=2) euclidean: Usual square distance between the two vectors (2 norm). maximum: Maximum distance between two components of x and y (supremum norm) manhattan: Absolute distance between the two vectors (1 norm). canberra: sum(|x_i - y_i| / |x_i + y_i|). Terms with zero numerator and denominator are omitted from the sum and treated as if the values were missing. binary: (aka asymmetric binary): The vectors are regarded as binary bits, so non-zero elements are ‘on’ and zero elements are ‘off’. The distance is the proportion of bits in which only one is on amongst those in which at least one is on. minkowski: The p norm, the pth root of the sum of the pth powers of the differences of the components.
 manhattan: Absolute distance between the two vectors (1 norm). canberra: sum(|x_i - y_i| / |x_i + y_i|). Terms with zero numerator and denominator are omitted from the sum and treated as if the values were missing. binary: (aka asymmetric binary): The vectors are regarded as binary bits, so non-zero elements are ‘on’ and zero elements are ‘off’. The distance is the proportion of bits in which only one is on amongst those in which at least one is on. minkowski: The p norm, the pth root of the sum of the pth powers of the differences of the components..")
36
Távolság mátrixok… vegdist… dk.dist <- vegdist(dk, method=„…”)
")
37
vegdist(x, method="bray„, binary=FALSE, diag=FALSE, upper=FALSE, na.rm=FALSE,...) euclidean d[jk] = sqrt(sum (x[ij]-x[ik])^2) manhattan d[jk] = sum(abs(x[ij] - x[ik])) gower d[jk] = (1/M) sum (abs(x[ij]-x[ik])/(max(x[i])-min(x[i])) where M is the number of columns (excluding missing values) canberra d[jk] = (1/NZ) sum ((x[ij]-x[ik])/(x[ij]+x[ik])) where NZ is the number of non-zero entries. bray d[jk] = (sum abs(x[ij]-x[ik])/(sum (x[ij]+x[ik])) kulczynski d[jk] 1 - 0.5*((sum min(x[ij],x[ik])/(sum x[ij]) + (sum min(x[ij],x[ik])/(sum x[ik])) morisita {d[jk] = 2*sum(x[ij]*x[ik])/((lambda[j]+lambda[k]) * sum(x[ij])*sum(x[ik])) } where lambda[j] = sum(x[ij]*(x[ij]-1))/sum(x[ij])*sum(x[ij]-1) horn Like morisita, but lambda[j] = sum(x[ij]^2)/(sum(x[ij])^2) binomial d[jk] = sum(x[ij]*log(x[ij]/n[i]) + x[ik]*log(x[ik]/n[i]) - n[i]*log(1/2))/n[i] where n[i] = x[ij] + x[ik]
![vegdist(x, method= bray„, binary=FALSE, diag=FALSE, upper=FALSE, na.rm=FALSE,...) euclidean d[jk] = sqrt(sum (x[ij]-x[ik])^2) manhattan d[jk] = sum(abs(x[ij] - x[ik])) gower d[jk] = (1/M) sum (abs(x[ij]-x[ik])/(max(x[i])-min(x[i])) where M is the number of columns (excluding missing values) canberra d[jk] = (1/NZ) sum ((x[ij]-x[ik])/(x[ij]+x[ik])) where NZ is the number of non-zero entries.](http://images.slideplayer.hu/8/2193763/slides/slide_37.jpg "bray d[jk] = (sum abs(x[ij]-x[ik])/(sum (x[ij]+x[ik])) kulczynski d[jk] *((sum min(x[ij],x[ik])/(sum x[ij]) + (sum min(x[ij],x[ik])/(sum x[ik])) morisita {d[jk] = 2*sum(x[ij]*x[ik])/((lambda[j]+lambda[k]) * sum(x[ij])*sum(x[ik])) } where lambda[j] = sum(x[ij]*(x[ij]-1))/sum(x[ij])*sum(x[ij]-1) horn Like morisita, but lambda[j] = sum(x[ij]^2)/(sum(x[ij])^2) binomial d[jk] = sum(x[ij]*log(x[ij]/n[i]) + x[ik]*log(x[ik]/n[i]) - n[i]*log(1/2))/n[i] where n[i] = x[ij] + x[ik].")
38
Klaszter elemzés library(vegan) setwd("c:/!myR/anosim") dk<-read.table("dk-04.txt",header=T) attach(dk) names(dk) fix(dk) dk.env<-read.table("dk-env-04.txt",header=T) dk.env$Area<-factor(dk.env$Area) dk.env$sites<-factor(dk.env$sites) dk.env$traps<-factor(dk.env$traps) attach(dk.env) names(dk.env) fix(dk.env) str(dk) dk.dist <- vegdist(dk) x<-hclust(dk.dist, method = "ward") plot(x, hang=-1)
 setwd( c:/!myR/anosim ) dk<-read.table( dk-04.txt ,header=T) attach(dk) names(dk) fix(dk) dk.env<-read.table( dk-env-04.txt ,header=T) dk.env$Area<-factor(dk.env$Area) dk.env$sites<-factor(dk.env$sites) dk.env$traps<-factor(dk.env$traps) attach(dk.env) names(dk.env) fix(dk.env) str(dk) dk.dist <- vegdist(dk) x<-hclust(dk.dist, method = ward ) plot(x, hang=-1)")
40
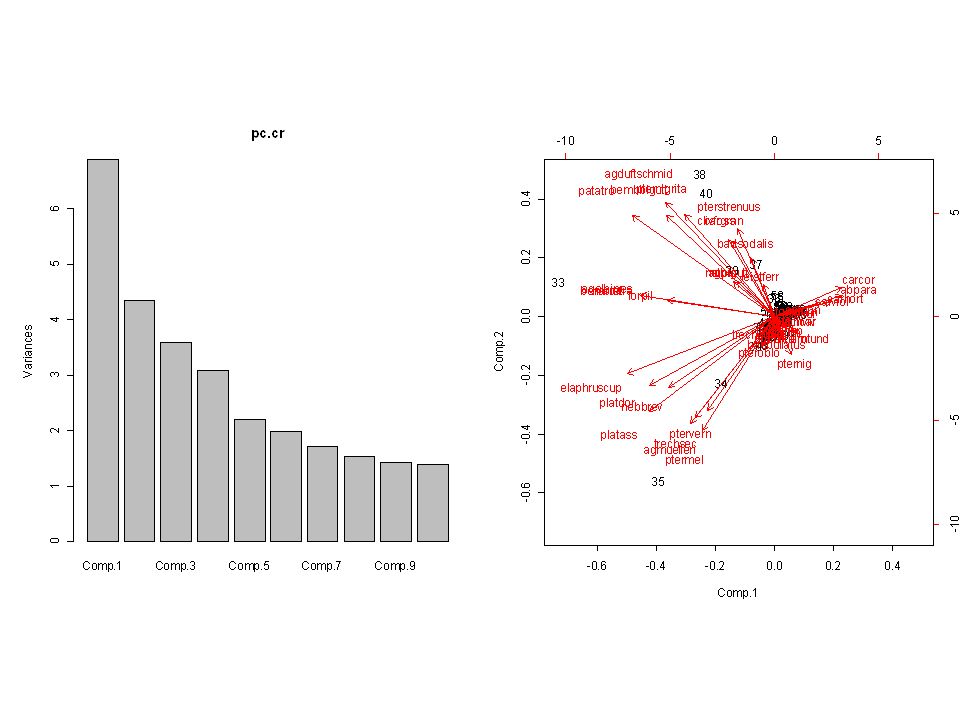
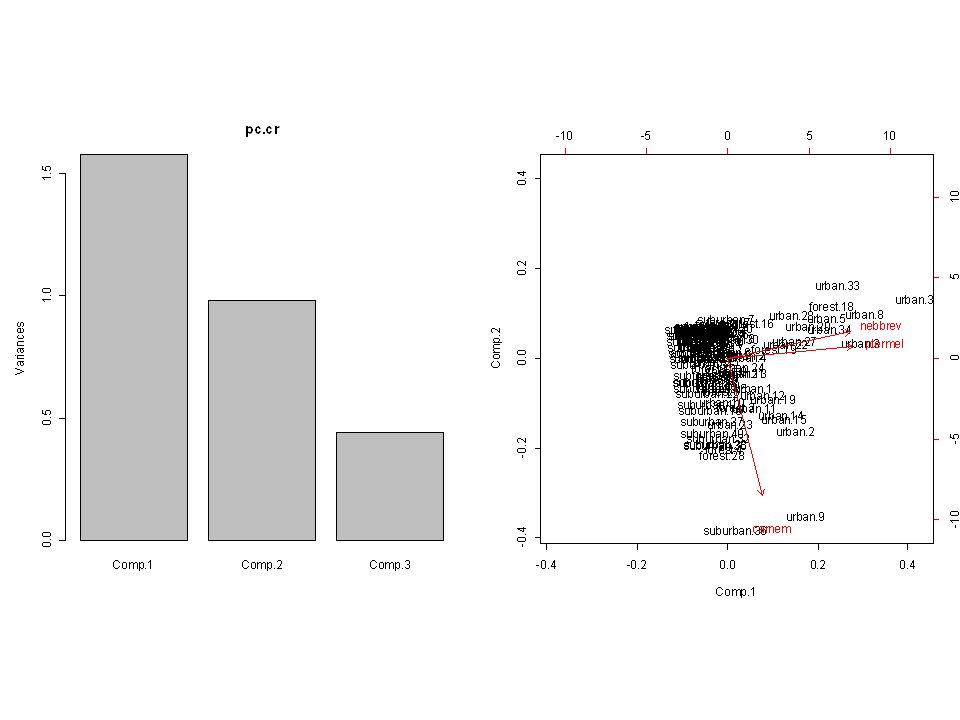
PCA require(graphics) (pc.cr <- princomp(dk)) princomp(dk, cor = TRUE) summary(pc.cr <- princomp(dk, cor = TRUE)) loadings(pc.cr) par(mfrow=c(1,2), pty="s") plot(pc.cr) biplot(pc.cr) --------------------------------------------------------------------------- ----------- Importance of components: Comp.1 Comp.2 Comp.3 Standard deviation 1.2557374 0.9900492 0.6655269 Proportion of Variance 0.5256255 0.3267325 0.1476420 Cumulative Proportion 0.5256255 0.8523580 1.0000000
 (pc.cr <- princomp(dk)) princomp(dk, cor = TRUE) summary(pc.cr <- princomp(dk, cor = TRUE)) loadings(pc.cr) par(mfrow=c(1,2), pty= s ) plot(pc.cr) biplot(pc.cr) Importance of components: Comp.1 Comp.2 Comp.3 Standard deviation Proportion of Variance Cumulative Proportion")
43
Metrikus-MDS require(graphics) dk.dist <- vegdist(dk) loc <- cmdscale(dk.dist) x <- loc[,1] y <- -loc[,2] plot(x, y, type="n", xlab="1st Axis", ylab="2nd Axis", main="cmdscale(dk.dist)", cex=1.8, family="serif") text(x, y, rownames(loc), cex=0.8, family="serif")
![Metrikus-MDS require(graphics) dk.dist <- vegdist(dk) loc <- cmdscale(dk.dist) x <- loc[,1] y <- -loc[,2] plot(x, y, type= n , xlab= 1st Axis , ylab= 2nd Axis , main= cmdscale(dk.dist) , cex=1.8, family= serif ) text(x, y, rownames(loc), cex=0.8, family= serif )](http://images.slideplayer.hu/8/2193763/slides/slide_43.jpg "Metrikus-MDS require(graphics) dk.dist <- vegdist(dk) loc <- cmdscale(dk.dist) x <- loc[,1] y <- -loc[,2] plot(x, y, type= n , xlab= 1st Axis , ylab= 2nd Axis , main= cmdscale(dk.dist) , cex=1.8, family= serif ) text(x, y, rownames(loc), cex=0.8, family= serif )")
45
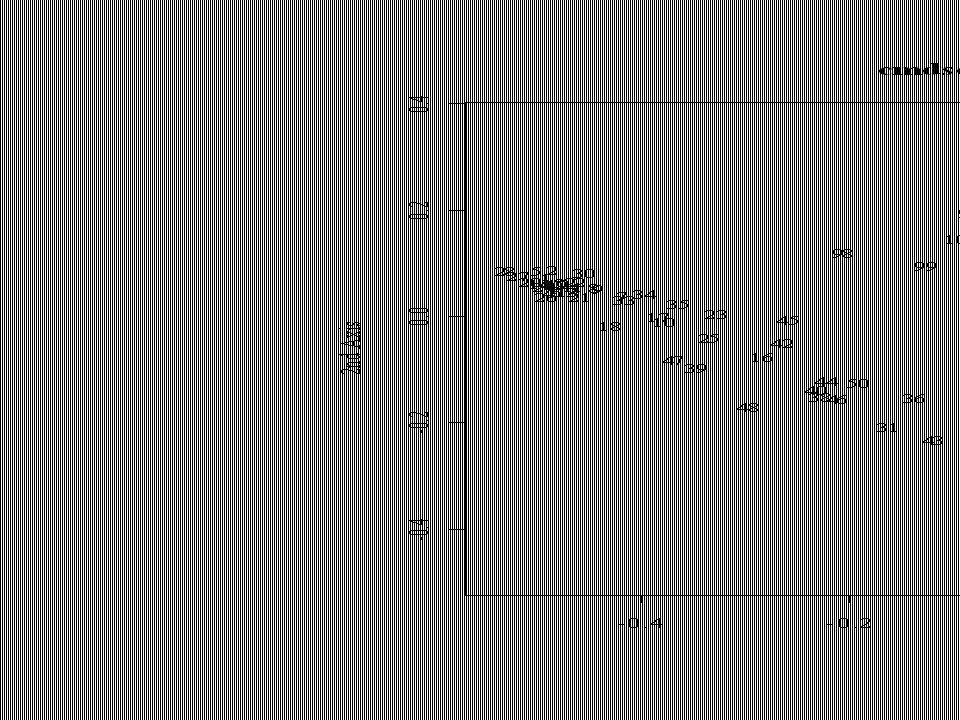
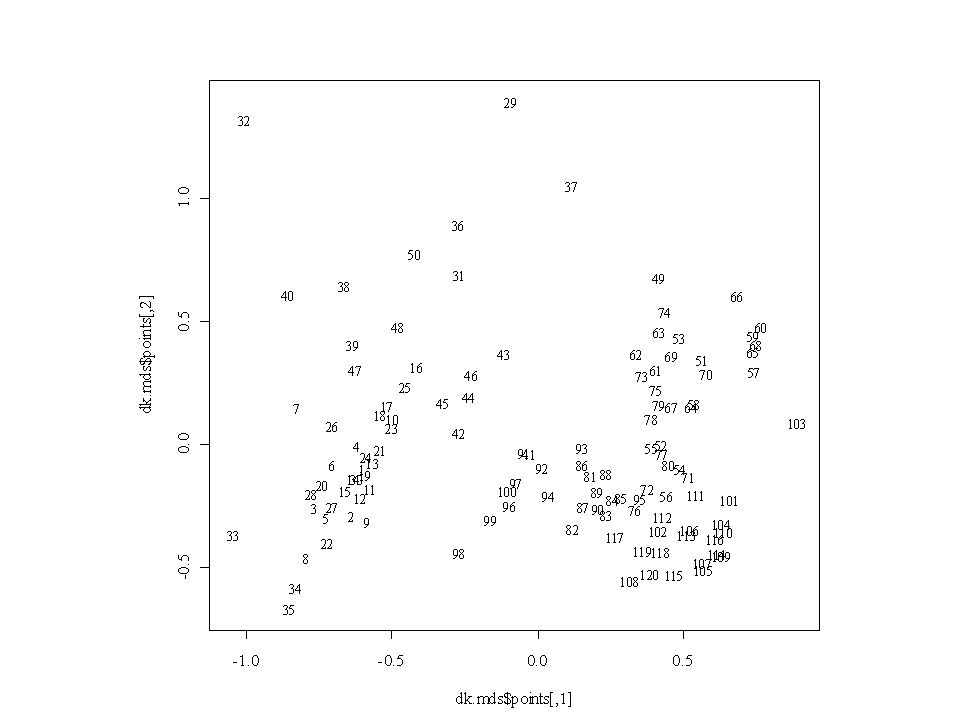
Nem-metrikus MDS library(MASS) dk.dist <- vegdist(dk) dk.mds <- isoMDS(dk.dist) plot(dk.mds$points, type = "n",cex=0.8, family="serif") text(dk.mds$points, labels = as.character(1:nrow(dk)),cex=0.8, family="serif")
 dk.dist <- vegdist(dk) dk.mds <- isoMDS(dk.dist) plot(dk.mds$points, type = n ,cex=0.8, family= serif ) text(dk.mds$points, labels = as.character(1:nrow(dk)),cex=0.8, family= serif )")
47
Anosim – Analysis of Similarity Ha két minta fajösszetétele valóban különbözik, akkor a csoportok közötti disszimilaritás nagyobb mint a csoportok(on) belül. Az anosim R értéke a csoportok közötti rangok különbségén alapszik A módszer közvetlenül a távolságmátrixból számol. R = (r_B - r_W)/(N (N-1) / 4) Ahol, (r_B)- Csoportok között; (r_W)- csoporton belül R (-1... +1), ahol 0 – teljesen random csoportosulás
/(N (N-1) / 4) Ahol, (r_B)- Csoportok között; (r_W)- csoporton belül R ( ), ahol 0 – teljesen random csoportosulás.")
48
Anosim… library(vegan) setwd("c:/!myR/anosim") dk<-read.table("dk-04.txt",header=T) attach(dk) names(dk) fix(dk) dk.env<-read.table("dk-env-04.txt",header=T) dk.env$Area<-factor(dk.env$Area) dk.env$sites<-factor(dk.env$sites) dk.env$traps<-factor(dk.env$traps) attach(dk.env) names(dk.env) fix(dk.env) str(dk) dk.dist <- vegdist(dk) attach(dk.env) dk.ano <- anosim(dk.dist, sites) summary(dk.ano) plot(dk.ano) savePlot(filename="dk-04a", type=c("emf"))
 setwd( c:/!myR/anosim ) dk<-read.table( dk-04.txt ,header=T) attach(dk) names(dk) fix(dk) dk.env<-read.table( dk-env-04.txt ,header=T) dk.env$Area<-factor(dk.env$Area) dk.env$sites<-factor(dk.env$sites) dk.env$traps<-factor(dk.env$traps) attach(dk.env) names(dk.env) fix(dk.env) str(dk) dk.dist <- vegdist(dk) attach(dk.env) dk.ano <- anosim(dk.dist, sites) summary(dk.ano) plot(dk.ano) savePlot(filename= dk-04a , type=c( emf ))")
50
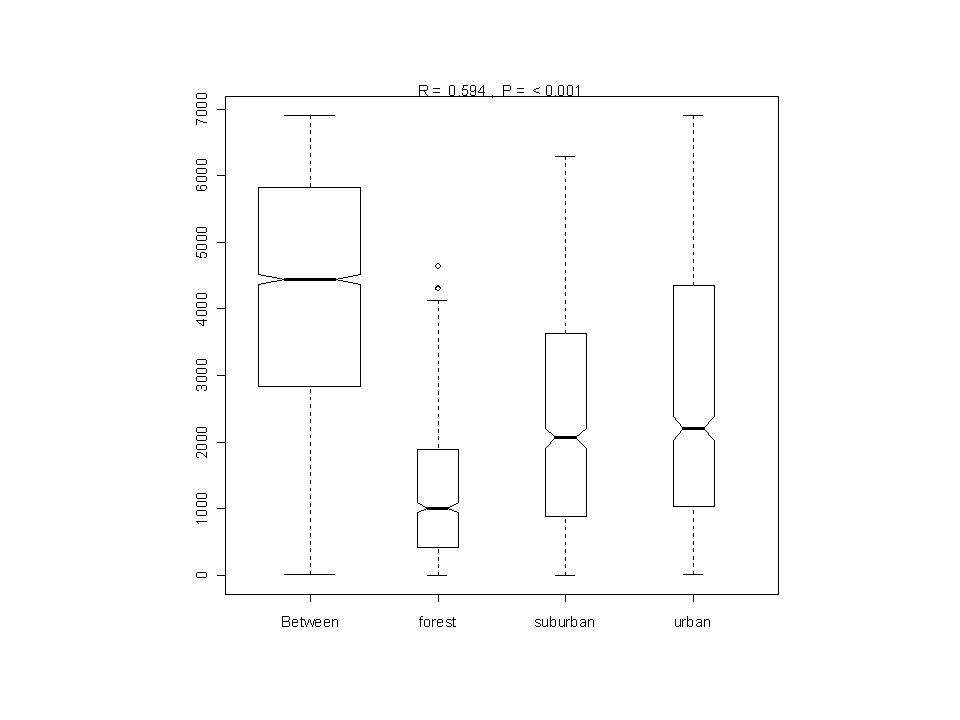
Anosim - results Call: anosim(dis = dk.dist, grouping = sites) Dissimilarity: bray ANOSIM statistic R: 0.5944 Significance: < 0.001 Based on 1000 permutations Empirical upper confidence limits of R: 90% 95% 97.5% 99% 0.0160 0.0228 0.0287 0.0361 Dissimilarity ranks between and within classes: 0% 25% 50% 75% 100% N Between 26 2835.75 4439.0 5821.50 6906.0 4800 forest 5 418.50 1020.5 1902.50 4634.0 780 suburban 1 889.25 2060.5 3625.50 6297.5 780 urban 19 1040.25 2205.0 4352.25 6906.0 780
 Dissimilarity: bray ANOSIM statistic R: Significance: < Based on 1000 permutations Empirical upper confidence limits of R: 90% 95% 97.5% 99% Dissimilarity ranks between and within classes: 0% 25% 50% 75% 100% N Between forest suburban urban")
54
Irodalom Podani János, 1997. Bevezetés a többváltozós biológiai adatfeldolgozás rejtelmeibe. Scientia Kiadó, Budapest Drs. Alan S.L. Leung and Kenneth M.Y. Leung, 2008. An Introduction to Multivariate Analysis. (lectures 14-15.) Dr. Michael R. Hyman, 2008. Brief introduction to mutlivariate statistics. (supplementary material)
 Dr. Michael R. Hyman, Brief introduction to mutlivariate statistics. (supplementary material).")







 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")










.>")


