Előadást letölteni
1
Adatmodellek A modellezés statisztikai alapjai

2
Statisztikai modell??? cél: feltárni, hogy bizonyos jelenségek között létezik-e az általunk feltételezett valóban létezik-e ehhez adatok kellenek, melyek elemzésével az összefüggések feltárhatók itt mindegy, hogy statisztikáról beszélünk, vagy geoinformatikáról – a lényeg ugyanaz

3
Az adatgyűjtés problémája Valós világ Elméleti modell Logikai modell Fizikai modell entitások leegyszerűsítése azon jellemzőkre, amik a későbbiekben szerepet játszanak a modellben az entitások megfelelői, az objektumok tényleges adatgyűjtés

4
Az adatgyűjtés problémája

5
Populáció és minta alapsokaság v. populáció minta mintavétel megszámlálható megszámlálhatatlan minden egyed választott egyedek mintavételi hiba mintavételi egység mérési hiba

6
A minta mennyire jó reprezentációja a populációnak? - mérőszámok átlag: hipotetikus érték minél nagyobb a minta, annál jobb a közelítés DE rendszerint a minta nem nagy – sőt! igen kicsi, kisebb mint kellene

7
A minta mennyire jó reprezentációja a populációnak? - mérőszámok total error, négyzetes összeg, variancia, szórás

8
TE=0 SS=5.2 S2=1.3 SD=1.14

9
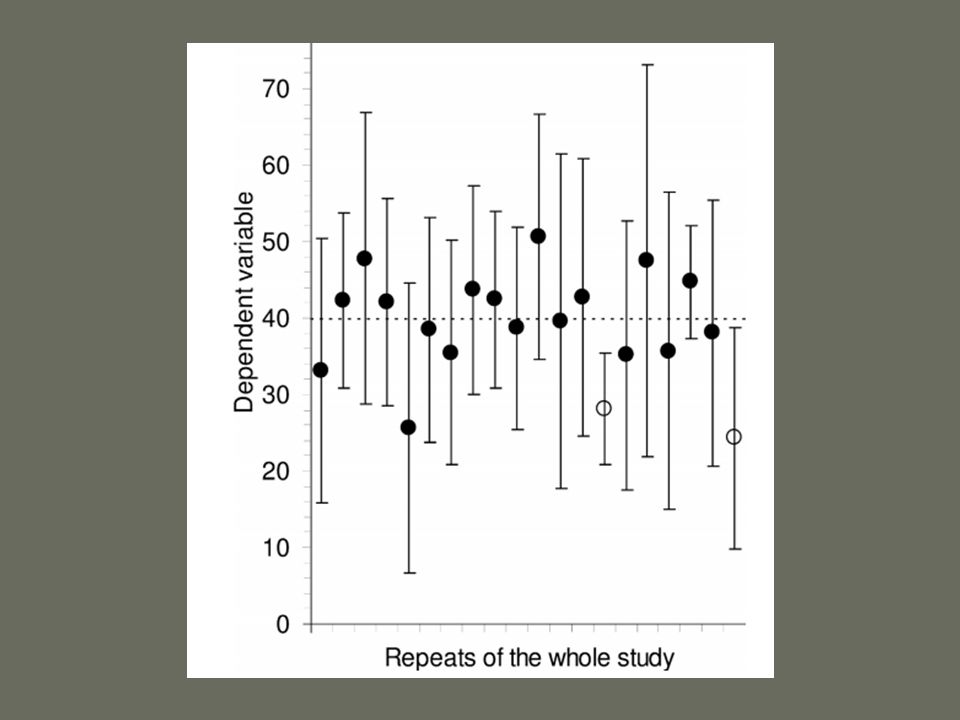
A minta mennyire jó reprezentációja a populációnak? - mérőszámok Standard error – az átlag hibája (a mintaátlagok szórása): megmutatja, hogy a minta mennyire reprezentálja a populációt -ha nagy a szám, akkor a hiba is nagy -ha kicsi, akkor a mintaátlag hasonló a populációátlagéhoz, vagyis a gyűjtött adatok jól tükrözik a valós világot (populáció)
: megmutatja, hogy a minta mennyire reprezentálja a populációt -ha nagy a szám, akkor a hiba is nagy -ha kicsi, akkor a mintaátlag hasonló a populációátlagéhoz, vagyis a gyűjtött adatok jól tükrözik a valós világot (populáció).")
10
A minta mennyire jó reprezentációja a populációnak? - mérőszámok konfidencia intervallum: egy tartomány, amibe a populáció átlaga esik a mintaátlagok 95%-ában (esetenként 99%- ában)
.")
11
M: átlag adatpontok SD: szórás SE: átlag hibája CI: konfidencia tartomány

12
Student félet-paraméter értékei t(2)=12,706 t(3)=4,303 t(4)=3,182 t(10)=2,262 t(20)=2,093 t(∞)=1.96
=12,706 t(3)=4,303 t(4)=3,182 t(10)=2,262 t(20)=2,093 t(∞)=1.96")
14
Regresszió – mint modell mi az amit látunk? mennyire megbízható az eredmény? mekkora a hibája? minden körülményt figyelembe vettünk?

16
Előfeltételek normalitás outlier, influent data homoszkedaszticitás autokorreláció

17
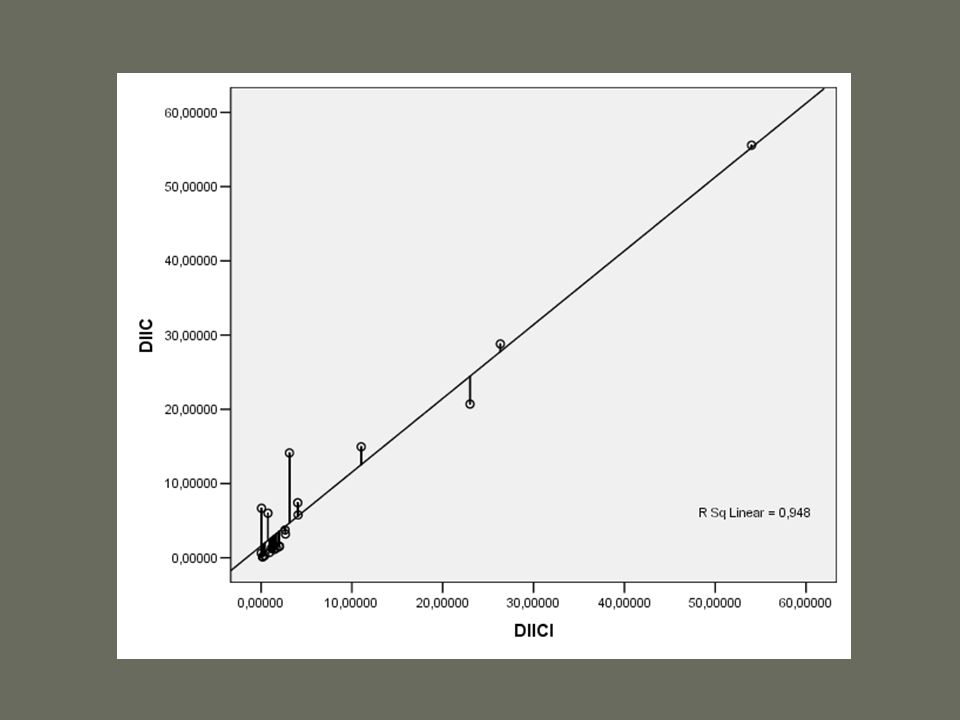
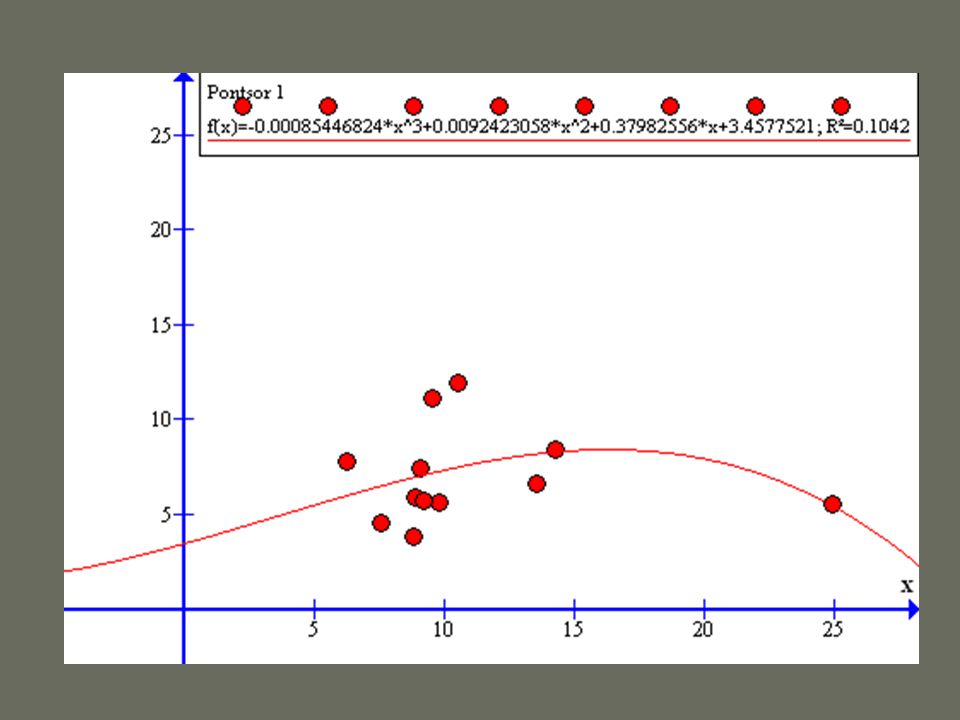
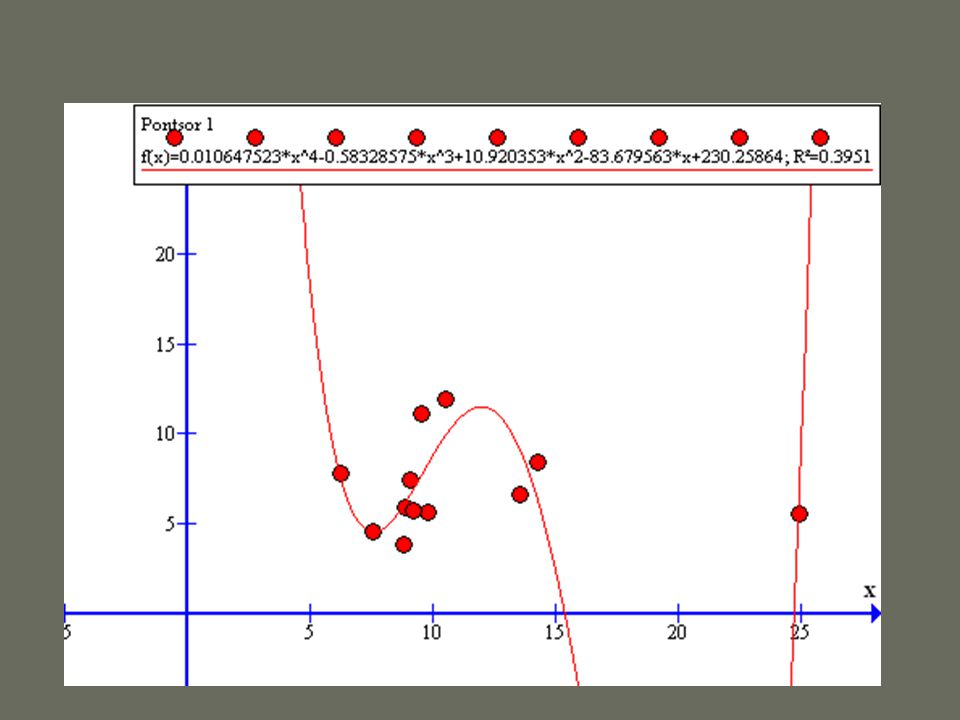
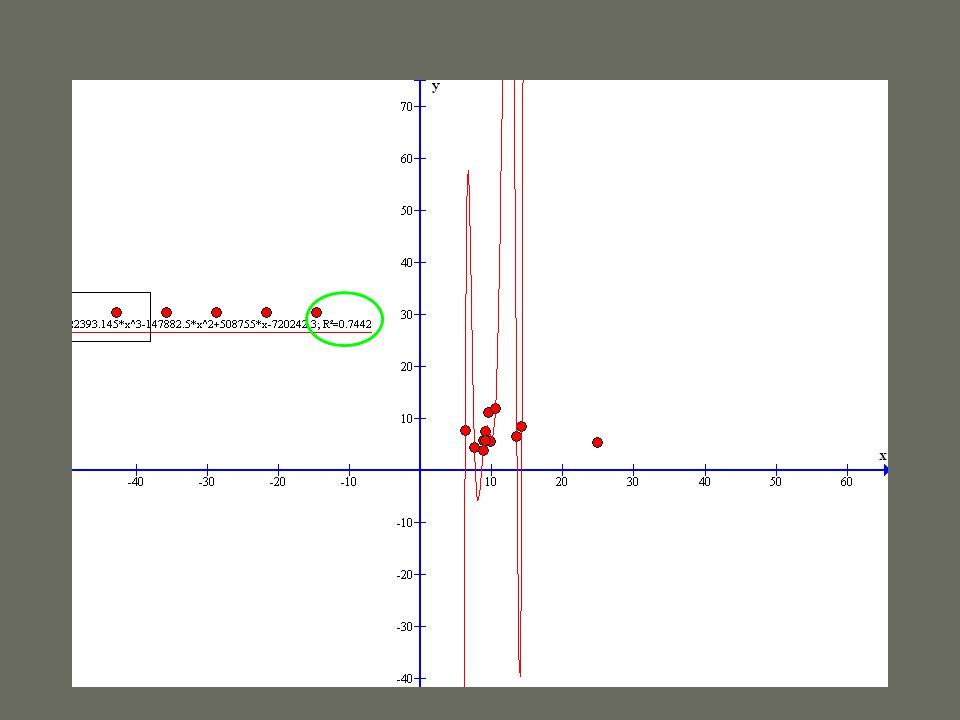
Az R 2 bűvöletében a modell annál jobb, minél jobban illeszkedik a trendvonal DE nem minden áron

23
Többváltozós lineáris regresszió 1 függő és több független változó modellek –enter (mindent megtart) –forward (változók egyesével lépnek be, az lesz a második, amelyik a megmagyarázott hányadot legjobban növeli) –backward (minden független változó benn van, az kerül ki amelyik elhagyása érdemben nem csökkenti a megmagyarázott hányadot) –stepwise (minden modellbe került változó helye bizonytalan, ha egy új belépésével egy már benn lévő magyarázóereje lecsökken, akkor kikerül)
 –forward (változók egyesével lépnek be, az lesz a második, amelyik a megmagyarázott hányadot legjobban növeli) –backward (minden független változó benn van, az kerül ki amelyik elhagyása érdemben nem csökkenti a megmagyarázott hányadot) –stepwise (minden modellbe került változó helye bizonytalan, ha egy új belépésével egy már benn lévő magyarázóereje lecsökken, akkor kikerül)")
24
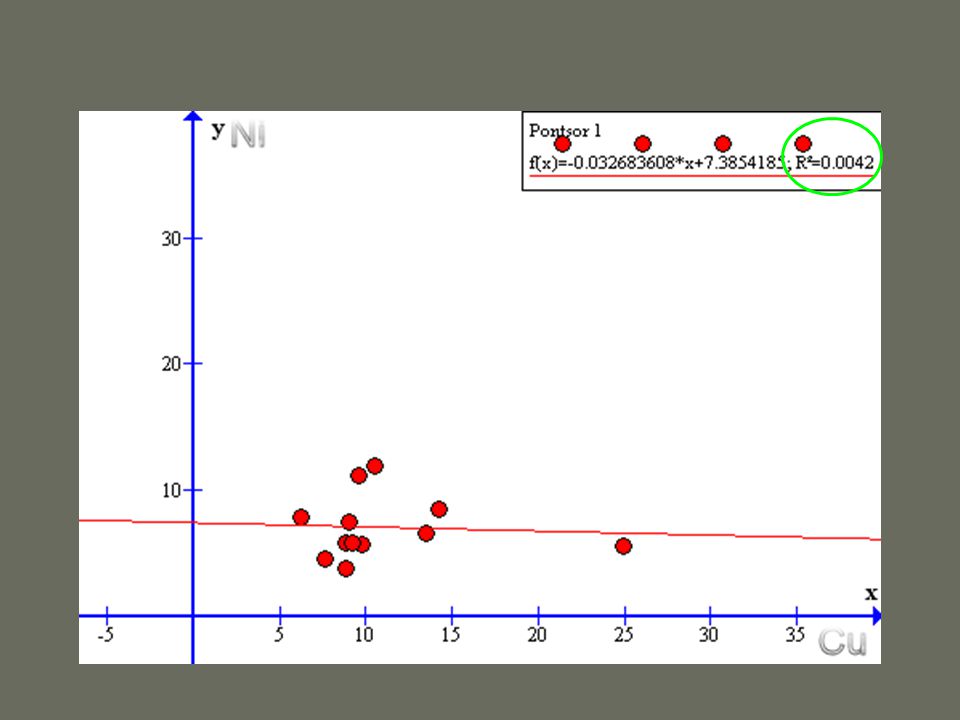
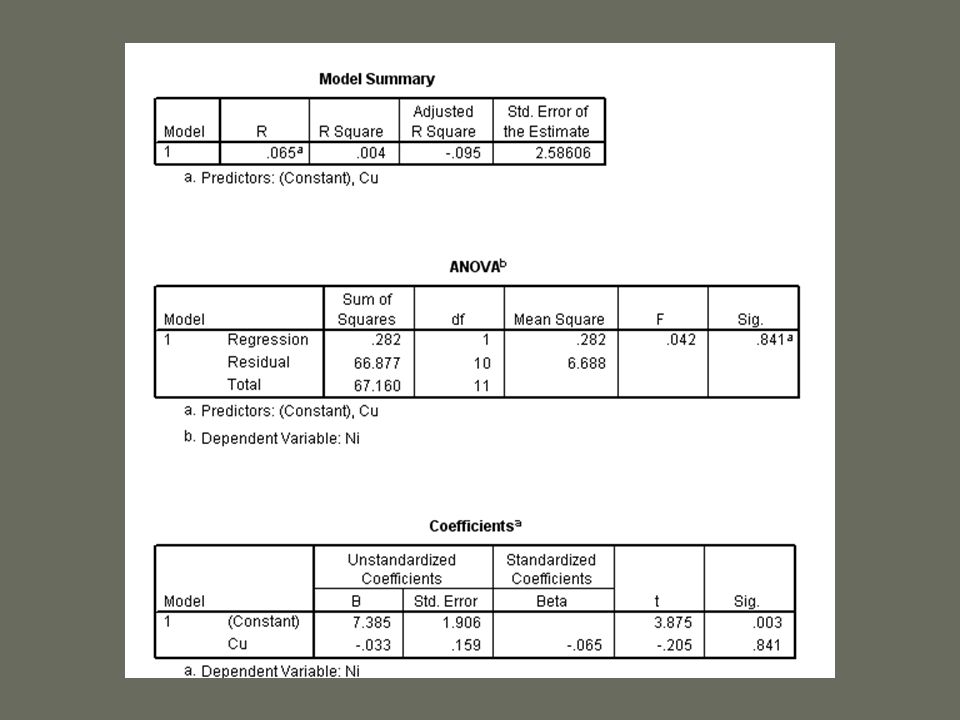
Többváltozós lineáris regresszió multikollinearitás a független változók nem korrelálhatnak egymással – ilyen esetben az R 2 a közös hányad miatt torzít VIF, tolerance

25
Ra standard hiba növekedése a multikollinearitás miatt (hánysorosra nő) 0,01,0000 0,21,0206 0,41,0911 0,61,2500 0,81,6667 0,851,8983 0,902,2942 0,953,2026 0,963,5714 0,974,1135 0,985,0252 0,997,0888 0,99510,0125 0,99922,3663
 0,01,0000 0,21,0206 0,41,0911 0,61,2500 0,81,6667 0,851,8983 0,902,2942 0,953,2026 0,963,5714 0,974,1135 0,985,0252 0,997,0888 0,99510,0125 0,99922,3663")














>")





