Előadást letölteni
1
3(+1) osztályozó a Bayes világból
febr. 27.

2
Előző előadás Bayes döntéselmélet Bayes osztályozó
P(j | x) = P(x | j ) · P (j ) / P(x) Ha feltesszük, hogy a posterior ismert normális eloszlást követ Paraméterbecslési módszerek ha paraméteres eloszlást feltételezünk és tanító adatbázis rendelkezésre áll
 = P(x | j ) · P (j ) / P(x) Ha feltesszük, hogy a posterior ismert normális eloszlást követ. Paraméterbecslési módszerek ha paraméteres eloszlást feltételezünk és tanító adatbázis rendelkezésre áll.")
3
Példa adatbázis ? kor hitelkeret havi bev. elhagy? <21 nincs
igen 21-50 van 50K-200K 50< nem 200K< ?

4
Naϊve Bayes osztályozó

5
Naϊve Bayes osztályozó
Bayes osztályozó ahol feltesszük, hogy a jellemzők egymástól feltételesen függetlenek egy adott osztály mellett Legyen két osztály, valamint x = [x1, x2, …, xd ]t ahol minden xi bináris, az alábbi valószínűségekkel: pi = P(xi = 1 | 1) qi = P(xi = 1 | 2)
 qi = P(xi = 1 | 2)")
6
Diszkriminancia-függvény (modell):
:")
7
Naive Bayes tanítása - MLE
pi = P(xi = 1 | 1 ) és qi = P(xi = 1 | 2 ) becslése N darab tanító példából tfh. p és q binomiális eloszlást követ (visszatevéses mintavétel modellezése) Maximum-likelihood módszerrel:
 és qi = P(xi = 1 | 2 ) becslése N darab tanító példából. tfh. p és q binomiális eloszlást követ. (visszatevéses mintavétel modellezése) Maximum-likelihood módszerrel:")
8
Naive Bayes tanítása – Bayes becslés
tfh. a becslési prior Beta eloszlásból jön X ~ Beta(a,b) E [X]=1/(1+b/a)
 E [X]=1/(1+b/a)")
9
Naive Bayes tanítása – Bayes becslés
az eredeti pi likelihood binomiális eloszlást követ a becslésre egy Beta(a,b)-t használunk … a Bayes becslés 2 lépése …
-t használunk. … a Bayes becslés 2 lépése …")
10
Naive Bayes tanítása – Bayes becslés (m-becslés)
Ugyanez átjelöléssel: (így egyszerűbb a gyakorlatban) 0 likelihood/posteriori elkerülése m és p konstansok (paraméterek) p a priori becslés pi-re m az „ekvivalens mintaszám”
 0 likelihood/posteriori elkerülése. m és p konstansok (paraméterek) p a priori becslés pi-re. m az „ekvivalens mintaszám")
11
Naϊve Bayes osztályozó
a gyakorlatban nem is olyan naív nagyon gyors, párhuzamosítható kis memóriaigény irreleváns jellemzők „kiátlagolódnak” jó megoldás ha nagyon sok, egyenlően fontos jellemzőnk van

12
Példa ? P() kor hitelkeret havi bev. elhagy <21 nincs < 50K
igen 21-50 van 50K-200K 50< nem 200K< ? P(kor>50| =igen) = (0+mp) / 2+m P(nincs| =igen) P(200K<| =igen)
 = (0+mp) / 2+m. P(nincs| =igen) P(200K<| =igen)")
13
Generatív vs. Diszkriminatív osztályozók
Egy rejtett állapota a rendszernek generálja a megfigyeléseinket Likelihood P(x | j ) és apriori P(j ) becslése Diszkriminatív: Cél az egyes osztályok elkülönítése Közvetlenül az a posteriori P(j | x) valószínűségek becslése x1 x2 x3 x1 x2 x3
 és apriori P(j ) becslése. Diszkriminatív: Cél az egyes osztályok elkülönítése. Közvetlenül az a posteriori P(j | x) valószínűségek becslése. x1. x2. x3. x1. x2. x3.")
14
Logisztikus Regresszió (Maximum Entrópia Osztályozó)
Két osztály esetén:

15
Nem paraméteres osztályozások

16
Nem paraméteres eljárások
16 Nem paraméteres eljárások Nem paraméteres eljárások alkalmazhatók tetszőleges eloszlásnál, anélkül, hogy bármit feltételeznénk a sűrűségfgvek alakjáról Likelihood P(x | j ) becslése vagy közvetlenül az a posteriori P(j | x) valószínűségek becslése
 becslése vagy közvetlenül az a posteriori P(j | x) valószínűségek becslése.")
17
Sűrűség becslése 17 Legye p(x) a becsülni kívánt sűrűségfüggvény
Annak valószínűsége, hogy egy pont az R-be esik: Ha n elemű mintánk van, akkor az R–be eső pontok számának várható értéke k E(k) = nP Pattern Classification, Chapter 2 (Part 1)
 = nP. Pattern Classification, Chapter 2 (Part 1)")
18
Sűrűség becslése Maximum likelihood becsléssel:
18 Sűrűség becslése Maximum likelihood becsléssel: p(x) folytonos, és ha R elég kicsi, akkor p nem változik lényegesen R-en: Ahol x R –beli pont, és V az R térfogata.
 folytonos, és ha R elég kicsi, akkor p nem változik lényegesen R-en: Ahol x R –beli pont, és V az R térfogata.")
19
Iteratív becslési folyamat
19 Iteratív becslési folyamat A V-nek mindenképpen nullához kell tartania, ha ezt a becslést használni akarjuk a pontszerű x-hez tartozó p(x)-re V a gyakorlatban nem lehet nagyon kicsi, mert a minták száma korlátozott A k/n hányadosoknál el kell fogadni egy kis bizonytalanságot…
-re. V a gyakorlatban nem lehet nagyon kicsi, mert a minták száma korlátozott. A k/n hányadosoknál el kell fogadni egy kis bizonytalanságot…")
20
Sűrűség becslés aszimptotikus tulajdonságai
20 Sűrűség becslés aszimptotikus tulajdonságai Három szükséges feltétele van, hogy

21
21

22
Parzen ablakok fix méretű és alakú R régiókkal dolgozunk V állandó p(x)-et egy kérdéses x pontban az R-be eső pontok száma alapján becsüljük (azaz leszámoljuk k-t)
")
23
Parzen ablakok - hiperkocka
23 Parzen ablakok - hiperkocka R egy d-dimenziós hiperkocka ( (x-xi)/hn ) akkor 1, ha xi az x középpontú V hiperkockába esik, 0 különben. (-t kernelnek nevezzük)
/hn ) akkor 1, ha xi az x középpontú V hiperkockába esik, 0 különben. (-t kernelnek nevezzük)")
24
Parzen ablakok - hiperkocka
24 Parzen ablakok - hiperkocka minták száma ebben a hiperkockában: behelyettesítve:

25
Általános eset pn(x) úgy becsüli p(x)-et, mint az átlaga valamilyen távolságnak az x pont és az (xi) (i = 1,… ,n) minták közt tetszőleges fgv-e lehet két pont távolságának

26
Parzen ablakok - példa p(x) ~ N(0,1) esete
26 Parzen ablakok - példa p(x) ~ N(0,1) esete Legyen (u) = (1/(2) exp(-u2/2) és hn = h1/n (n>1) olyan normális sűrűségek átlaga, melyek középpontjai xi-kben vannak.
 ~ N(0,1) esete. Legyen (u) = (1/(2) exp(-u2/2) és hn = h1/n (n>1) olyan normális sűrűségek átlaga, melyek középpontjai xi-kben vannak.")
27
27

28
28

29
Analóg eredmények kaphatók két dimenzióban is:
29 Analóg eredmények kaphatók két dimenzióban is:

30
30

31
31 p(x) ?
")
32
32 p(x) = 1U(a,b) + 2T(c,d) (egyenletes és háromszög eloszlás keveréke)
 = 1U(a,b) + 2T(c,d) (egyenletes és háromszög eloszlás keveréke)")
33
Osztályozás a Parzen ablakok módszerével
33 Minden osztálynál becsüljük a likelihood sűrűségeket (aprioiri egyszerűen közelítendő), aztán a maximális a posteriori valószínűségnek megfelelően osztályozunk A Parzen-ablakokhoz tartozó döntési tartományok az ablak-függvény választásától függenek
, aztán a maximális a posteriori valószínűségnek megfelelően osztályozunk. A Parzen-ablakokhoz tartozó döntési tartományok az ablak-függvény választásától függenek.")
34
34

35
k legközelbbi szomszéd becslés
35 k legközelbbi szomszéd becslés Az ismeretlen “legjobb” ablak függvény problémájának megoldása: Legyen V a mintaelemek számának függvénye Az x legyen középpontja egy cellának, növeljük addig, amíg k mintát (k = f(n)) tartalmaz Az így kapott mintákat nevezzük az x k legközelebbi szomszédjának 2 lehetőség van: Nagy a sűrűség x közelében; ekkor a cella kicsi lesz, és így a felbontás jó lesz Sűrűség kicsi; ekkor a cella nagyra fog nőni, és akkor áll le, amikor nagy sűrűségű tartományt ér el A becslések egy családját kaphatjuk a kn=k1/n választással, a k1 különböző választásai mellett
) tartalmaz. Az így kapott mintákat nevezzük az x k legközelebbi szomszédjának. 2 lehetőség van: Nagy a sűrűség x közelében; ekkor a cella kicsi lesz, és így a felbontás jó lesz. Sűrűség kicsi; ekkor a cella nagyra fog nőni, és akkor áll le, amikor nagy sűrűségű tartományt ér el. A becslések egy családját kaphatjuk a kn=k1/n választással, a k1 különböző választásai mellett.")
36
36 © Ethem Alpaydin: Introduction to Machine Learning. 2nd edition (2010)
")
37
k legközelbbi szomszéd osztályozó
37 k legközelbbi szomszéd osztályozó k nearest neighbour (knn) P(i | x) közvetlen becslése n címkézett minta segítségével Vegyünk egy cellát x körül ami k elemet tartalmaz Ha ki db minta (a k közül) tartozik i –hez: pn(x, i) = ki /(nV)
 P(i | x) közvetlen becslése n címkézett minta segítségével. Vegyünk egy cellát x körül ami k elemet tartalmaz. Ha ki db minta (a k közül) tartozik i –hez: pn(x, i) = ki /(nV)")
38
k legközelbbi szomszéd osztályozó
38 k legközelbbi szomszéd osztályozó Itt ki/k azon minták aránya, amelyek címkéje i A minimális hibaarány eléréséhez a cellában kiválasztjuk a leggyakrabban reprezentált kategóriát (osztályt) Ha k nagy akkor a hatékonyság közelíti a lehető legjobbat
 Ha k nagy akkor a hatékonyság közelíti a lehető legjobbat.")
39
39

40
Példa ? kor hitelkeret havi bev. elhagy <21 nincs < 50K igen
21-50 van 50K-200K 50< nem 200K< ? k=3 Távolság metrika = diszkrét érték egyezik

41
Nem paraméteres osztályozók
van paraméterük! Bayes osztályozóból vannak levezetve úgy hogy a valószínűségi becslésekre nem paraméteres eloszlásokat használnak Parzen-ablak osztályozó kernel és h ablakméret likelihood becslésére K-legközelebbi szomszéd osztályozó távolság metrika és k szomszédszám Posteriori becslésére

42
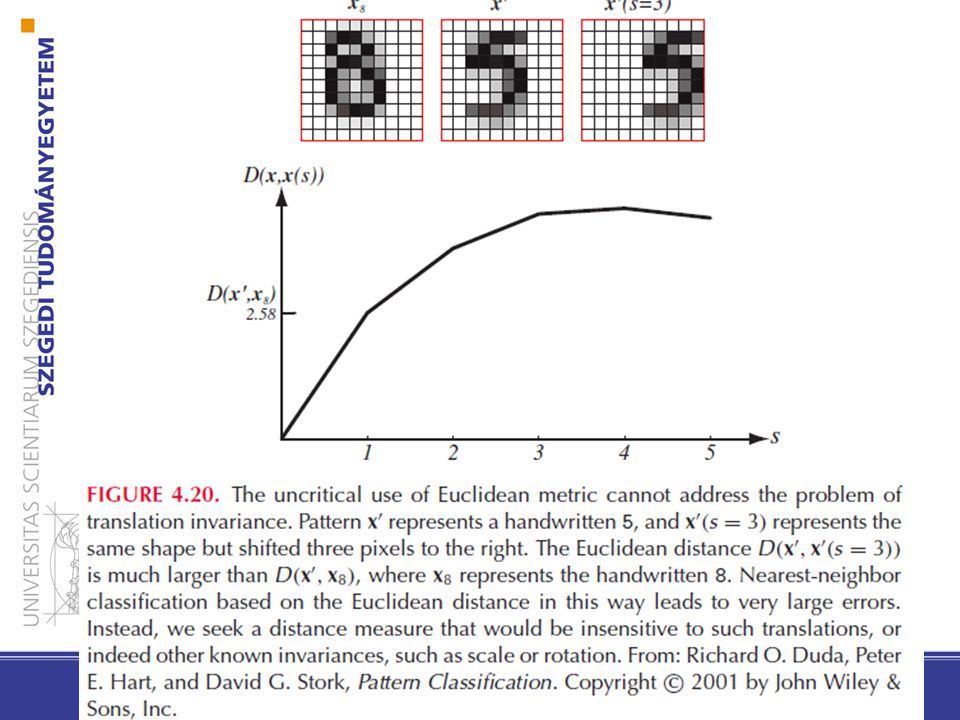
Távolság metrikák érzékenysége

44
Bayes osztályozó megvalósítások a gyakorlatban
Összefoglalás Bayes osztályozó megvalósítások a gyakorlatban Paraméteres Nem paraméteres Likelihood becslése (generatív) Naive Bayes Parzen ablak osztályozó Posteriori becslése (diszkriminatív) Logisztikus Regresszió k legközelebbi szomszéd osztályozó
 Naive Bayes. Parzen ablak osztályozó. Posteriori becslése (diszkriminatív) Logisztikus Regresszió. k legközelebbi szomszéd osztályozó.")

>")


 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")















