Doctopus Dokumentum Elemző Keretrendszer Labor ismertető
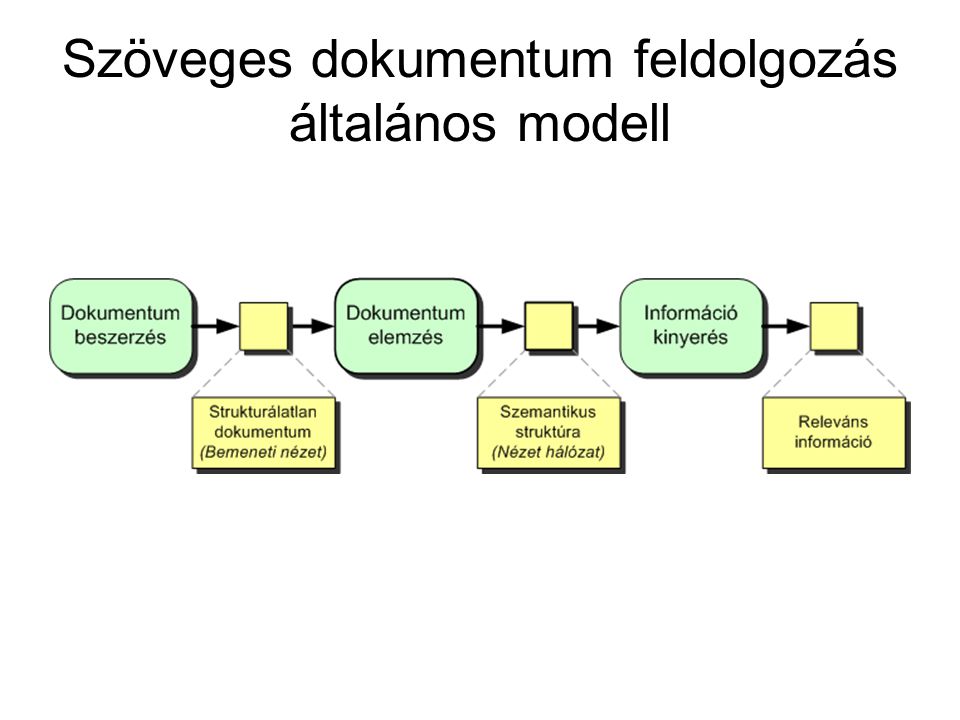
Szöveges dokumentum feldolgozás általános modell
Dokumentum elemző keretrendszer modell
Nézet Nézet típus –Szemantikai tartalom –Struktúra (XML Séma)
Nézethálózat
Citex – Dokumentum elemzés menete
Adaptív dokumentum elemzés
STRIPS operátor - Elemző
IKF TV-Whizz elemzési terv
Példa elemzési terv készítés FAFA S H F(fs) FNFN F W HA CE H A TO AT PO T P ST T S G F FS F E N SP PE FP F P N C NL SN NH SN CO S C F(fp) F(fs) N(nl) N(nh) F(fp) N(nl) N(nh) F(fs) F(fp) A(w) A(ce) A(w) A(ce)A ANAN AFAF Analyzers S: Start FS: Fact extractor (based on parsed sentences) FP: Fact extractor (based on fitting patterns) SP: Sentence parser PO: Part of Speech tagger NL: Lexicon-based named entity recognizer NH: Heuristic named entity recognizer CO: Concept finder ST: Stemmer TO: Tokenizer W: Web-wrapper CE: Content extractor G: Goal Views H: HTML source page F: Extracted fact candidates E: Parsed sentence trees P: Part of speech of words N: Recognized names C: Recognized concepts S: Word stems T: Tokenized text A: Extracted textual article
Adaptív körfolyamat
Citex – Dokumentum elemzés menete
Citex - Új referencia kontextus kinyerő (feladat)