Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Dr Quittner Pál Baksa-Haskó Gabriella
ADATBÁZISOK ELŐADÁS Dr Quittner Pál Baksa-Haskó Gabriella

2
Témakörök Adatbázis-kezelő rendszerek Adattárolás, adatszervezés
Adatmodellek Relációs modell Katalógus, adatszótár Gyakorlati problémák és megoldásuk Adattárházak

3
Adatbázisok Információs infrastruktúra Adatfeldolgozás
Vezetői információ Telekommunikáció Központi és egyedi automatizált irodai szolgáltatások Cél: Információs technológia alkalmazásával növelje a szervezetben dolgozó emberek teljesítményét.

4
Az információs rendszer részei
Adatok, Hardver (eszközök), Szoftverek, Felhasználók Az információs rendszer adatokat tárol a hardveren, melyről az eszközök és a szoftver segítségével a felhasználók információkat kaphatnak
, Szoftverek, Felhasználók. Az információs rendszer adatokat tárol a hardveren, melyről az eszközök és a szoftver segítségével a felhasználók információkat kaphatnak.")
5
Adatbázis Tartalmazza
az adatokat, az adatok ábrázolási módját, az adatok közti összefüggéseket, kapcsolatokat, az adatokhoz való hozzáférés ellenőrzési módját. Működni kell rajta egy olyan adatbázis-kezelő rendszernek, mely lehetővé teszi az adatokból a bennük lévő információk előállítását. (Data Base Management System, DBMS)
")
6
Adatbázis Két főtípusuk: A kettő között a határvonal nem éles.
Tény adatbázis Szöveges információ visszakereső rendszerek. A kettő között a határvonal nem éles. Az Oracle az első csoportba tartozik.

7
Tény-adatbázisok csoportosítása
Tranzakció orientált adatbázisok: a szervezet napi feladatait támogatják tranzakciók folyamatos feldolgozását végzik el. Adattárházak: vezetői döntések támogatására szolgáló igen nagy, statikus adatbázisok lekérdezések és elemzések végrehajtására szolgálnak

8
Leggyakrabban használt adatbázis-kezelő rendszerek
ORACLE IBM Universal DataBase (régebben DB2) Microsoft SQL Server Microsoft Access
 Microsoft SQL Server. Microsoft Access.")
9
A (tény)adatbázis-kezelő rendszereknek biztosítani kell:
Különféle igények hatékony kielégítését Adatfüggetlenséget Adatok közti komplex kapcsolatok ábrázolását Redundancia mentességet illetve annak ellenőrzését Egyszerű használatot Az adatok védelmét, nehogy illetéktelenek hozzáférhessenek Az adatok integritását, hogy a hozzáférésre jogosultak se ronthassák el lehetőleg az adatbázist

10
A (tény)adatbázis-kezelő rendszereknek biztosítani kell:
Helyreállíthatóságot, hogy bármely esetleges hiba esetén az eredeti állapotot vissza lehessen állítani Több felhasználós adatbázisoknál az egyidejű hozzáférést, illetve annak ellenőrzését Osztott adatbázisoknál ezenfelül lehetővé kell tenni az adatok szétosztását és megtalálását a különböző helyekről, az egyidejű hozzáférés ellenőrzését és az adatforgalom optimalizációját is

11
Az adatbázis-architektúra három szintje
Belső vagy fizikai szint A tényleges fizikai tárolási és elérési módot írja le. Külső szint Miként látják az egyes felhasználók az adatbázist. Koncepcionális szint Logikailag egységbe ötvözve hogyan néz ki ténylegesen az adatbázis. Ennek különböző vetületeit látják a külső szinten a különböző felhasználók. Ez képződik le tárolási és elérési struktúraként a belső szinten.

12
Az adatbázis-architektúra három szintje
Az Oracle-ben elsősorban a koncepcionális és a külső szintet határozzuk meg. A belső szintet csak bizonyos határok között tudjuk befolyásolni

13
Komponensek Kapcsolattartó Feladatkonvertáló
A DBMS nyelvén megfogalmazott utasításokat értékeli, elemzi és ha végrehajthatók, meghatározza ennek optimális módját. Elérés meghatározó Átfordítja az operációs rendszer számára érthető parancsokká. Elindítja, majd értékeli végrehajtásukat.

14
Működési elv

15
Működési elv 1 Adat kérése az adatbázisból (Alkalmazási program)
2 Kérés értelmezése, elemzése (Adatbázis-kezelő rendszer) (szintaktika, létezés, jogosultság) 3a Végrehajtható → operációs rendszerhez 3b Nem hajtható végre → programhoz 4 Kapcsolat a külsö tárolóhoz (operációs rendszer) 5 Kért adat átvitele (op rendszer, tárolóból pufferbe) 6 Adatok átadása, visszajelzés programnak 7 Adatok átvétele programba.
 (szintaktika, létezés, jogosultság) 3a Végrehajtható → operációs rendszerhez. 3b Nem hajtható végre → programhoz. 4 Kapcsolat a külsö tárolóhoz (operációs rendszer) 5 Kért adat átvitele (op rendszer, tárolóból pufferbe) 6 Adatok átadása, visszajelzés programnak. 7 Adatok átvétele programba.")
16
Hozzáférés szabályozása

17
Követelmények Egy korszerű adatbáziskezelő szoftvertől megkövetelhető, hogy a következő szolgáltatásokat megfelelő szinten biztosítsa: Valamennyire tudják használni csekély számítástechnikai ismeretekkel rendelkezők is, Legyen felhasználóbarát lekérdező nyelve és jelentés készítője (report generátor), Biztosítsa a rendszer legfontosabb jellemzőinek automatikus dokumentálását, Képernyőhasználat egyszerű legyen, Párbeszédesen (interaktív módon) lehessen használni, Egyszerűen lehessen az adatbázis-kezelő utasításokból (magas szintű) programnyelvi utasításokat generálni.
, Biztosítsa a rendszer legfontosabb jellemzőinek automatikus dokumentálását, Képernyőhasználat egyszerű legyen, Párbeszédesen (interaktív módon) lehessen használni, Egyszerűen lehessen az adatbázis-kezelő utasításokból (magas szintű) programnyelvi utasításokat generálni.")
18
Szoftver rétegek Operációs rendszer Adatbázis-kezelő rendszer
Alkalmazási programok Az Oracle különböző operációs rendszerek alatt tud futni. Az alkalmazási feladatokat az SQL nyelven interaktívan, vagy programba építve fogalmazhatjuk meg.

19
A DBMS nyelv funkciói Adatleíró nyelv (Data Definition Language) adatok és a köztük lévő kapcsolatok leírása, Adatkezelő nyelv (Data Manipulation Language) adatok visszanyerésére, beírására, módosítására, törlésére. Tranzakció vezérlő nyelv (Data Control Language) tranzakciós folyamatok vezérlése :
 adatok visszanyerésére, beírására, módosítására, törlésére. Tranzakció vezérlő nyelv (Data Control Language) tranzakciós folyamatok vezérlése. :")
20
Alkalmazási lehetőségek
önálló, interaktív (Self Contained System), programnyelvbe beépíthető (Host Language System). Alapjuk a szabványos SQL nyelv (Structured Query Language). A felhasználó csak azt mondja meg, mit akar csinálni. A „hogyan”-t a DBMS határozza meg.
, programnyelvbe beépíthető (Host Language System). Alapjuk a szabványos SQL nyelv (Structured Query Language). A felhasználó csak azt mondja meg, mit akar csinálni. A „hogyan -t a DBMS határozza meg.")
21
Adatbázis felügyelő fő feladatai
Az adatbázis megszervezése. Ez rendszerint magában foglalja az adatmodell kialakítását, az adatbázis leírását, a definiált adatok elnevezését, amennyiben mód van rá, a keresési stratégiák megválasztását, a hozzáférési jogok meghatározását és az adatbázis betöltését; Az adatbázist használók segítése; Az adatbázisba bevitt adatok helyességének ellenőrzése, illetve segítségnyújtás az erre kijelölt felhasználóknak az ellenőrzés elvégzéséhez; Az adatbázis adatainak rendszeres kimentése, hogy esetleges hibák után az eredeti helyes állapotot vissza tudjuk állítani; Az adatbázis használatának állandó figyelése, a hatásfok jelentős csökkenése esetén az adatbázis újraszervezése; A felhasználók igényei alapján az adatbázis struktúrájának módosítása.

22
Adatbázis felügyelő fő feladatai
Az adatbázis-felügyelő munkája azért is igen bonyolult, mert az adatbázis létrehozásakor és karbantartásakor igen sok, egymással gyakran ellentétes szempontot és érdeket kell figyelembe venni. Ráadásul az egyes szempontok rangsorolása sem mindig egyértelmű, és az idők folyamán változhat is. Jó DBMS önmagában nem elegendő. Az adatbázist jól kell megtervezni és jól is kell tudni használni. Különben csak egy bonyolultabb, lassabb, drágább, nagyobb erőforrás igényű módszert használhatunk

23
Gyakori tervezési hibák
Nyílt logikai átfedés: ugyanaz az adattípus azonos névvel több állományban is szerepel; Rejtett logikai átfedés: ugyanaz az adattípus különböző elnevezéssel bár, de több állományban is szerepel; Látszólagos logikai átfedés: ugyanaz az elnevezés különböző adatállományokban más adattípust jelent; Fizikai átfedés: ugyanazon adatokat többszörösen tároljuk; Logikai átfedés hiánya: a különböző adatállományok között a megfelelő logikai kapcsolatot nem tudjuk létrehozni. (Pl. az árucikkekről és a raktárakról is egyedenként külön-külön minden adatunk megvan, de azt nem tudjuk ebből megállapítani, hogy melyik raktárban milyen cikkek vannak.): Eltérő kódolás: ugyanannak a fogalomnak az azonosítására többfajta kódrendszert használunk.
: Eltérő kódolás: ugyanannak a fogalomnak az azonosítására többfajta kódrendszert használunk.")
24
A kilencvenes évektől az adatbázisokat jellegük szerint három nagy csoportba oszthatjuk:
személyi számítógépen megvalósított egy személy vagy csoport információs igényeit kielégítő adatbázis, melyhez egy időben csak egy felhasználó férhet hozzá, nagy számítógépen (mainframe), vagy megfelelő hozzáférési védelemmel rendelkező személyi számítógép hálózaton levő, egy központi helyre telepített integrált adatbázis, melynek a legkülönbözőbb személyek és csoportok különféle igényeit kell egyidejűleg, és egymástól függetlenül kielégítenie, nagy- és/vagy személyi számítógépek hálózatára alapozott integrált, de megosztott adatbázis, melyben a leginkább helyileg igényelt adatok a felhasználás helyén vannak, ahol a hálózat bármelyik másik pontjáról is elérhetőek. A mindenki által használt adatok tárolása, és annak nyilvántartása, hogy az elosztott adatok melyik adatbázisban találhatók, viszont centralizáltan, vagy legalább is központi felügyelet alatt történik.
, vagy megfelelő hozzáférési védelemmel rendelkező személyi számítógép hálózaton levő, egy központi helyre telepített integrált adatbázis, melynek a legkülönbözőbb személyek és csoportok különféle igényeit kell egyidejűleg, és egymástól függetlenül kielégítenie, nagy- és/vagy személyi számítógépek hálózatára alapozott integrált, de megosztott adatbázis, melyben a leginkább helyileg igényelt adatok a felhasználás helyén vannak, ahol a hálózat bármelyik másik pontjáról is elérhetőek. A mindenki által használt adatok tárolása, és annak nyilvántartása, hogy az elosztott adatok melyik adatbázisban találhatók, viszont centralizáltan, vagy legalább is központi felügyelet alatt történik.")
25
A főhangsúlyt olyan adatbázisok létrehozásának és működtetésének ismertetésére helyezzük, melyekben
igen sok (több száz) különböző típusú rekord van a különböző típusú rekordok között igen sokféle kapcsolat áll fenn a rekordok össz száma milliótól több százmillióig is terjedhet naponta akár több ezer műveletet (lekérdezés, módosítás) is végeznek az adatbázisban egyszerre több tucat, sőt több száz terminálról is elérhető és használható az adatbázis interaktív módon az adatok védelmét, biztonságát, helyreállíthatóságát a rendszer biztosítja
 különböző típusú rekord van. a különböző típusú rekordok között igen sokféle kapcsolat áll fenn. a rekordok össz száma milliótól több százmillióig is terjedhet. naponta akár több ezer műveletet (lekérdezés, módosítás) is végeznek az adatbázisban. egyszerre több tucat, sőt több száz terminálról is elérhető és használható az adatbázis interaktív módon. az adatok védelmét, biztonságát, helyreállíthatóságát a rendszer biztosítja.")
26
Mindegy, hogy milyen gépen, milyen szoftverrel dolgozunk, általános érvényű a szabály, hogy bizonyos adatmennyiségig, és/vagy tranzakciószámig nem kell törődnünk a hatékonysággal; egy adott küszöb fölött viszont már nem árt, ha gondolunk rá; míg egy meghatározott szint fölött már okvetlenül tekintetbe kell vennünk, ha működőképes rendszert akarunk létrehozni. Az, hogy ezek a szintek ezer vagy százezer rekordnál, 1 vagy 100 tranzakció/percnél vannak, az már a rendelkezésünkre álló hardvertől, az alkalmazott operációs rendszertől, és nem csekély mértékben az adatbáziskezelő szoftvertő, az adatbáziskezelő rendszer hatékonyságától függ.

27
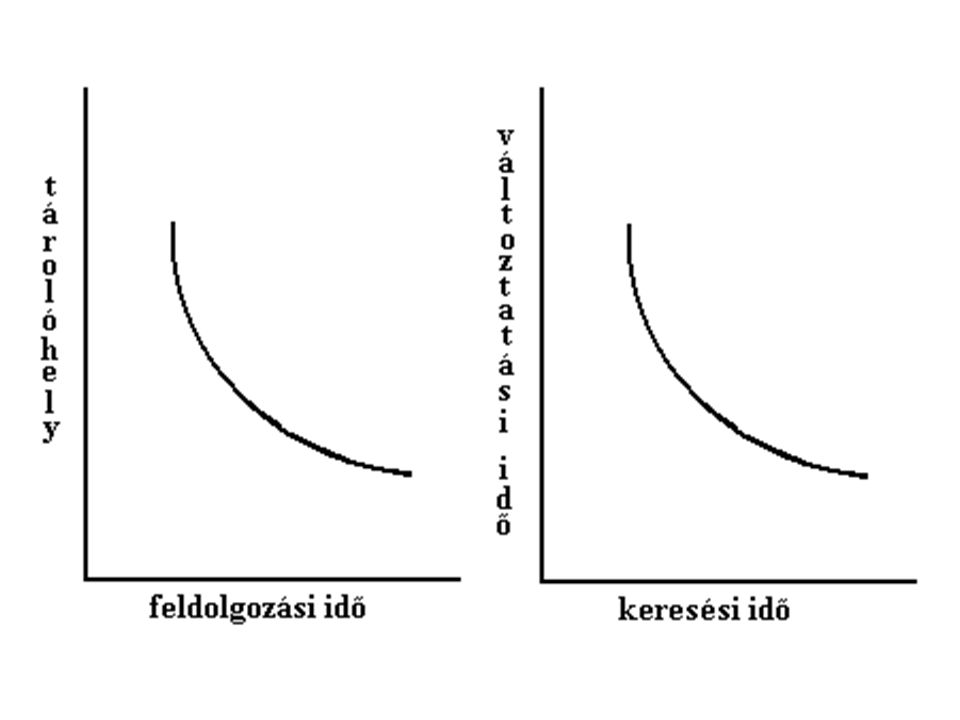
Tárolás és elérés Az adatmodell belső, fizikai szintje Feladat
Szerkezet kialakítása Adatok elérése Ellentétes szempontok Létrehozási idő csak egyszeri feladat

29
Adatszervezési szempontok
Milyen adatokra lesz leggyakrabban szükségünk Milyen hardveren tároljuk az adatokat Mekkora az adatmennyiség Mekkora adatmennyiséget kell meghatározott sorrendben elérni Milyen mezők alapján kell keresni Véletlen keresésnél hány rekordot találunk Csak olvasunk, vagy változtatunk is Növekedhet-e a rekordhossz Hány új adatot írunk be, mennyit törlünk és milyen gyakorisággal

30
Adatszervezési szempontok
Belső szint átlagos felhasználó előtt elvileg rejtve marad Gyakorlatban fontos Elérési idő nagyságrendekkel megnövekedhet Okok: Nem megfelelő adatszerkezet Adatok rossz eloszlása Adatszerkezet nem felel meg a feldolgozás logikájának

31
Lemezek Mágneslemez CD/DVD akárhányszor írható és olvasható
csak olvasható egyszer irható

32
Lemez felépítése blokk (lap) sáv cilinder Író/olvasó fej
fizikai olvasás blokkonként történik logikai olvasás rekordonként történik

33
Lemez hozzáférési idő min max Fejmozgatás 0 2-50 ms
Fejkiválasztás 0 mikrosec Forgási idő ms Adatátvitel Mbyte/sec Hozzáférési idő Átlagosan: ms Optimális: 0

34
Mágneslemezek jellemzői
Felületek száma 20 Cilinderek száma 200 – 400 Sávok kapacitása kB Lapméret kB Teljes tároló kapacitás 100 MB – 500 GB

35
Címzés Lapcím: Lemezegység Cilinder Felület Sáv blokk Abszolút Relatív
Szimbolikus Lapcím + relatív cím a lap címtáblázatában

36
Címzés

37
Szervezési és elérési módok
Lineáris Soros (fizikai sorrend) Szekvenciális (logikai sorrend) Közvetlen Indexelt Hashing Hierarchikus Particionált
 Szekvenciális (logikai sorrend) Közvetlen. Indexelt. Hashing. Hierarchikus. Particionált.")
38
Soros szervezés/elérés
A rekordok helye és keresési kulcsa között semmilyen összefüggés nem áll fenn. Az adatokat fizikai elhelyezésük alapján, sorban egymás után dolgozzuk fel. Minden adatállományon automatikusan megvalósul. Karbantartása egyszerű. Sok adat beolvasásakor igen gyors. Egy egyedi kulcsértékkel rendelkező rekord megtalálásához átlagosan a tároló helyek felét végig kell vizsgálnunk. Ha több rekord is rendelkezhet a keresett értékkel és mindegyiket meg kell találnunk, vagy annak megállapítására, hogy az adott kulcsú rekord nincs bent az állományban, mindig végig kell olvasnunk az állomány tárolására szolgáló egész területet. Mindig alkalmazható

39
Szekvenciális szervezés/elérés
Szekvenciális szervezésnél az egymást követő rekordok keresési kulcsa között egyértelmű logikai kapcsolat van. Növekvő sorrendnél mindegyik rekord kulcsa nagyobb (vagy egyenlő, ha duplikátumok is lehetnek) a közvetlenül előtte lévő rekord kulcsánál, csökkenő sorrendnél kisebb, vagy egyenlő. Bármely rekord után csak a közvetlenül utána következőt tudjuk elérni (egyes szerkezetekben még a közvetlenül előtte lévőt is). Szekvenciális elérést ugyanazokon az adatokon többféle szempont szerint is létrehozhatunk.
 a közvetlenül előtte lévő rekord kulcsánál, csökkenő sorrendnél kisebb, vagy egyenlő. Bármely rekord után csak a közvetlenül utána következőt tudjuk elérni (egyes szerkezetekben még a közvetlenül előtte lévőt is). Szekvenciális elérést ugyanazokon az adatokon többféle szempont szerint is létrehozhatunk.")
40
Lista szerkezet A listaszerkezetben a fizikai és a logikai sorrend között semmiféle kapcsolat sem kell legyen. A szekvenciális sorrendben álló, a logikailag egymás után következő rekordokat pointerek kapcsolják össze. Minden adatrekord két részből tevődik össze: a tényleges adatmezőkből álló adatrészből a pointer mezőből, mely a hozzá logikailag közvetlenül kapcsolódó rekord(ok) címét tartalmazza. Ezt az adatbázis kezelő rendszer kezeli, a felhasználó számára rejtve van. Az elérési idő minimalizálása érdekében célszerű, ha az adatok fizikai elhelyezésének a sorrendje megegyezik, vagy legalább is nem túl sok, a sorból kilógó rekord kivételével majdnem megegyezik a logikai sorrenddel.
 címét tartalmazza. Ezt az adatbázis kezelő rendszer kezeli, a felhasználó számára rejtve van. Az elérési idő minimalizálása érdekében célszerű, ha az adatok fizikai elhelyezésének a sorrendje megegyezik, vagy legalább is nem túl sok, a sorból kilógó rekord kivételével majdnem megegyezik a logikai sorrenddel.")
41
Lista

42
Lista szerkezetek

43
Változtatás listában

44
Lista és soros szerkezet
Lista szerkezet előnyei Módosítás, beszúrás egyszerűbb Szekvenciális feldolgozáshoz nem kell rendezés Többféle szekvencialitás is megvalósítható Kevesebb adatot kell végigvizsgálni Más adatszerkezet is megvalósítható (pl hierarchikus) Lista szerkezet hátrányai Törlés, beszúrás lassabb Ha nincs sűrűsödés, sokkal lassabb a keresés Pointerek miatt nagyobb tárolóigény Bonyolultabb programozás (nem igazi hátrány)
 Lista szerkezet hátrányai. Törlés, beszúrás lassabb. Ha nincs sűrűsödés, sokkal lassabb a keresés. Pointerek miatt nagyobb tárolóigény. Bonyolultabb programozás (nem igazi hátrány)")
45
Közvetlen elérés A keresett adatokhoz azonnal hozzá tudunk férni
(gyakorlatilag 1 – 4 lépéssel) indexek hashing
 indexek. hashing.")
46
Indexek Meggyorsítják az indexelt oszlopra a
közvetlen és a szekvenciális hozzáférést. Karbantartásuk automatikus. Lassítja a változtatást. Helyet foglalnak el. Bármikor létrehozható, törölhető.

47
Indexek Indextáblázat tartalmazza Index lehet Megvalósítás
indexértékeket, hozzátartozó rekord címét. Index lehet egyedi illetve duplikált, növekvő illetve csökkenő, elemi illetve összetett Szelektív illetve nem szelektív Megvalósítás B+ fa (szelektív) bitmap (nem szelektív)
 bitmap (nem szelektív)")
48
Index tábla

49
Index terület Tároló feloszlása:
a tényleges adatokat tartalmazó adatterület kb. 2/3 az indexeket és az indexekben való gyors keresést lehetővé tevő egyéb szerkezeteket tartalmazó indexterület kb. 1/3

50
B+ fa

51
B+ fa módosítás

52
Bitmap index Duplikált indexekre célszerű definiálni, ha az index nem nagyon szelektív. ROW-ID-1 ROW-ID-2 ROW-ID Ind-ért Ind-ért Ind-ért Ha a bitmap-ben a bit értéke 1, akkor az adott sorban a mező értéke a megfelelő index értéke. Párhuzamos tranzakcióknál módosításkor kevésbé hatékony, de nagyon jó lehet adattárházaknál (Date Warehouse).
.")
53
Bittérkép példa

54
Keresés több kulcs szerint
Alapeset: SQL utasításban WHERE oszlop1=érték1 AND oszlop2=érték2 WHERE oszlop1=érték1 OR oszlop2=érték2 Elegendő (lehet) az egyik feltétel kielégítése. SQL optimalizáló határozza meg a kiértékelés módját soros szekvenciális (melyik index) direkt (melyik index) sorrendjét Ez az elérési út (Access Path)
 az egyik feltétel kielégítése. SQL optimalizáló határozza meg a kiértékelés. módját. soros. szekvenciális (melyik index) direkt (melyik index) sorrendjét. Ez az elérési út (Access Path)")
55
ÉS/VAGY feltétel - 1

56
ÉS/VAGY feltétel - 2 Két feltétel összekapcsolása bit-térkép segítségével. ÉVFOLYAM = 2 VAGY SZÜLETÉSI ÉV = 1998 feltételnek az 1112 és az 5212 rekordok ÉVFOLYAM = 2 ÉS SZÜLETÉSI ÉV = 1998 feltételnek csak az 1112 rekord felel meg

57
Keresési példa 10 rekord/lap
Feladat: rekord egyenletes eloszlásban 10 rekord/lap 3 kulcs (életkor, végzettség, szakképesítés) 10 – 10 különböző értékkel egyenletes eloszlásban Indexek 100 rekord/lap Keresés: Együttesen a 3 kulcs kombinációja alapján A feltételnek 100 rekord fog megfelelni!
 10 – 10 különböző értékkel egyenletes eloszlásban. Indexek. 100 rekord/lap. Keresés: Együttesen a 3 kulcs kombinációja alapján. A feltételnek 100 rekord fog megfelelni!")
58
Keresési példa - Helyigény
Adatok lap Egy tulajdonságra index lap Mindhárom tulajdonságra index lap Hármas index lap Minimális helyigény lap Maximális helyigény lap

59
Keresési példa - Lehetőségek
Összes adat beolvasása, ellenőrzés (pl. nincsenek indexek) soros lapolvasás. Valamelyik kulcson végigmenve (a kulcshoz tartozik index), másik két érték ellenőrzése index, 100 indexlap soros beolvasása lap beolvasása és ellenőrzése nem sűrűsödő (majdnem) rekord/lap direkt beolvasása. Rosszabb!!! sűrűsödő rekord, 1000 lap soros beolvesása 1 100 soros beolvasás
 soros lapolvasás. Valamelyik kulcson végigmenve (a kulcshoz tartozik index), másik két érték ellenőrzése index, 100 indexlap soros beolvasása lap beolvasása és ellenőrzése. nem sűrűsödő (majdnem) rekord/lap direkt beolvasása. Rosszabb!!! sűrűsödő rekord, 1000 lap soros beolvesása soros beolvasás.")
60
Keresési példa - Lehetőségek
3. Végigmenni a három indexen, kiválasztani a közös rekordokat 3* index, 300 indexlap soros beolvasása 100 rekord/lap direkt beolvasása 4. Új index a három tulajdonságra együttesen 1 indexlap direkt beolvasása (Ha sűrűsödik, akkor soros) Időnyereség 1 -2 nagyságrend!!!
 Időnyereség 1 -2 nagyságrend!!!")
61
Hashing - 1 Jól kiválasztott algoritmus segítségével a keresési kulcs és a rekord tárolási címe között egy „majdnem egyértelmű” kapcsolatot hozunk létre. Olyan leképezést alkalmazunk a kulcsok és a címek között, amely különböző kulcsokhoz optimálisan mindig, gyakorlatilag csaknem mindig különböző címeket rendel hozzá. A leképezés által azonos címhez rendelt, de különböző kulcsú elemeket szinonimáknak nevezzük. A szinonimák címét leggyakrabban egy pointerrel, több szinonima esetén egy pointer-lánccal csatoljuk az eredetileg kijelölt címhez.

62
Hashing - 2 A hash-algoritmus kiválasztási szempontjai
ne pazaroljunk el túl sok helyet minél kevesebb szinonim rekordunk legyen Algoritmus pl. primszámmal osztás maradéka Észszerű kompromisszum: 80-85%-os kitöltöttség mellett nem eredményez 20%-nál több szinonimát. Ez azt jelent, hogy az adatokat durván 1,2 lépéssel tudjuk elérni.

63
A relációs modell Az adatmodellben leírjuk a különböző típusú adatokat, a köztük fennálló kapcsolatokat, összefüggéseket, valamint a velük kapcsolatos adatvédelmi eljárásokat is. A logikailag összetartozó adatokat összegyűjtjük önálló egyedtípusokba, entitásokba. Meghatározzuk, hogy az egyes entitásokat mivel tudjuk egyértelműen azonosítani, és ezen kívül milyen további tulajdonságokkal rendelkeznek (attribútumok).
.")
64
Főbb modellek hierarchikus (pl. IMS) hálós (pl. IDMS)
relációs (pl. Oracle, DB2) objektum orientált Ma a gyakorlatban használatos rendszerek zöme a relációs modellen alapul.
 objektum orientált. Ma a gyakorlatban használatos rendszerek zöme a relációs modellen alapul.")
65
Kapcsolat Lehet két entitás típus között, vagy ugyanazon entitás különböző attribútumai között. A relációs modellben általában a különböző entitások közti kapcsolat a fontos. Az entitáson belüli kapcsolatokat rendszerint kiküszöböljük.

66
Kapcsolattípusok A két elem független egymástól;
Kölcsönösen egyértelmű kapcsolat (pl. jó kódrendszerben a kód és a megnevezés között); Egyik irányba egy, a másikba többértelmű (1: N) kapcsolat (Pl. szülőanya és gyerekei); Több-több (M:N) kapcsolat (pl. férfiak és nők). Az egyes kapcsolatok egymásra is épülhetnek.
; Egyik irányba egy, a másikba többértelmű (1: N) kapcsolat. (Pl. szülőanya és gyerekei); Több-több (M:N) kapcsolat. (pl. férfiak és nők). Az egyes kapcsolatok egymásra is épülhetnek.")
67
1:1 Kapcsolat

68
1:N Kapcsolat

69
N:M Kapcsolat

70
Relációs ábrázolási mód
Egyedeket relációkban (speciális táblázatok) ábrázolja. Ezek írják le a valós világ különböző egyedeit (entitásait) és azok tulajdonságait. Egyedek közti kapcsolatokat is ábrázolhat relációkban. Adatkezelés relációs műveletekkel valósul meg.
 ábrázolja. Ezek írják le a valós világ különböző egyedeit (entitásait) és azok tulajdonságait. Egyedek közti kapcsolatokat is ábrázolhat relációkban. Adatkezelés relációs műveletekkel valósul meg.")
71
Előnyök és hátrányok Előnyök:
Nagyon közel áll a mindennapi szemlélethez; Igen rugalmasan módosítható; Jól elkülöníthető, függetleníthető a három szint. Hátrányok: Gépi megvalósítás kevésbé hatékony; Ma már ez nem olyan nagy baj.

72
A relációk tulajdonságai
Egyértelmű relációnév az adatbázisban; Sorok jellemzik az egyedeket, oszlopok az egyes tulajdonságokat; Minden sorban azonos számú oszlop van; Oszlopoknak a reláción belül egyértelmű neve van; Bármely oszlop egy sorban legfeljebb egy értéket vehet fel. Ha nincs értéke, akkor NULL; Oszlopok sorrendje tetszőleges; Nincs két teljesen azonos sor; Létezik az oszlopoknak legalább egy olyan kombinációja, amelyik egyértelműen azonosítja a sort. Ez az elsődleges kulcs. Bármely adatot azonosít: relációnév + oszlopnév + elsődleges kulcs értéke.

73
Táblázatok, nézetek Nem tároljuk minden egyed minden tulajdonságának értékét fizikailag. Alap vagy bázis reláció. Táblázat, tábla Fizikailag tárolt. Virtuális reláció. Nézet, view Nem tartalmaz adatokat. Táblázatokból állítjuk elő relációs műveletekkel. Materialitált nézet. Táblázatokból állítjuk elő relációs űveletekkel. Fizikailag tárolt. Változik, ha változnak az alaptáblázatok Pillanatfelvétel, snapshot Táblázatok, nézetek adatai egy meghatározott pillanatban. Fizikailag tárolt. Lekérdezések, kiválasztások eredménye Nem igazi reláció és csak ideiglenesen létezik. Közbenső táblázatok Ideiglenesen kellenek adott műveletekhez, feladatokhoz.

74
Kulcsok Adatok integritását, relációk ellentmondás mentességét biztosítják. A rendszer automatikusan ellenőrzi elsődleges kulcs idegen kulcs (relációk közti kapcsolat, pl. megrendelésben levő áruk kódjai között),
,")
75
Elsődleges kulcs PRIMARY KEY
Egyértelműen azonosítja egy reláció sorait. Az elsődleges kulcs (vagy annak része) nem lehet (vagy ne legyen) null érték, és ne tartalmazzon fölösleges oszlopokat. Fontos eldönteni, mi legyen az elsődleges kulcs, ha több lehetőségünk van. Pl. periódusos rendszerben: elem neve, rendszáma, vagy vegyjele
 nem lehet (vagy ne legyen) null érték, és ne tartalmazzon fölösleges oszlopokat. Fontos eldönteni, mi legyen az elsődleges kulcs, ha több lehetőségünk van. Pl. periódusos rendszerben: elem neve, rendszáma, vagy vegyjele.")
76
További integritási lehetőségek
Egyedi index definiálása (ez az oszlop sem vehet fel azonos értéket két sorban) Adott mezőre meghatározott feltételnek kell teljesülnie (pl. ellenőrző szám, adott érték lehet csak)
 Adott mezőre meghatározott feltételnek kell teljesülnie (pl. ellenőrző szám, adott érték lehet csak)")
77
Idegen kulcs FOREIGN KEY
Hivatkozó relációban egy oszlop (kombináció) csak olyan értéket vehet fel, amelyik vagy a NULL-érték, vagy a hivatkozott táblázat elsődleges kulcsértékeinek valamelyikével egyenlő. Relációk között hoz létre 1: N kapcsolatot. Érvényesnek kell maradnia minden változtatásnál, bevitelnél, törlésnél.
 csak olyan értéket vehet fel, amelyik vagy a NULL-érték, vagy a hivatkozott táblázat elsődleges kulcsértékeinek valamelyikével egyenlő. Relációk között hoz létre 1: N kapcsolatot. Érvényesnek kell maradnia minden változtatásnál, bevitelnél, törlésnél.")
78
Példák idegen kulcs kapcsolatra
Nem lehet megrendelni nem létező árut Nem lehet felvenni nem létező tantárgyat Csak létező témára/osztályba lehet a dolgozókat beosztani

79
Idegen kulcs módosítása
Bevitel Hivatkozottba: bármelyik helyes elsődleges kulcs Hivatkozóba: csak olyan érték, amilyen elsődleges kulcs van a hivatkozottban, vagy NULL-érték.

80
Idegen kulcs módosítása
Törlés Hivatkozóból: korlátozás nélkül Hivatkozottból: Ha egy értékre nincs hivatkozás, korlátozás nélkül Ha van korlátozott (restricted, nem törölhető) null értékre állítás (set null, a hivatkozó táblázat idegen kulcsa NULL-érték lesz) tovagyűrűző (cascade, a hivatkozó megfelelő sora is törlődik)
 null értékre állítás (set null, a hivatkozó táblázat idegen kulcsa NULL-érték lesz) tovagyűrűző (cascade, a hivatkozó megfelelő sora is törlődik)")
81
Idegen kulcs módosítása
Hivatkozóból: lásd bevitelt Hivatkozottból: lásd törlést, de a cascade a hivatkozóban az új értékre való módosítást jelenti.

82
Idegen kulcs kapcsolat

83
Idegen kulcs kapcsolat

84
Idegen kulcs kapcsolat

85
Indexek Meggyorsítják az indexelt oszlopra a
közvetlen és a szekvenciális hozzáférést. Karbantartásuk automatikus. Lassítja a változtatást. Helyet foglalnak el. Bármikor létrehozható, törölhető

86
Indexek Indextáblázat (B+ fa) tartalmazza indexértékeket,
hozzátartozó rekord címét. Index lehet egyedi illetve duplikált, növekvő illetve csökkenő, elemi illetve összetett.

87
Entity-Relationship modell
Adatbázis tervezésének egyik módja. Top-down tervezés. Meghatározzuk az entitásokat és a köztük fennálló kapcsolatokat

88
A koncepcionális szint kialakítása
Meghatározzuk az egyes entitásokat, azok elsődleges kulcsát és attribútumait; Az 1:N kapcsolatokat idegen kulccsal biztosítjuk; Az N:M kapcsolatokat fölbontjuk 1:N kapcsolatra egy új reláció közbeiktatásával. Ennek elsődleges kulcsa a két reláció elsődleges kulcsának konkatenációja, oszlopai, amelyek mindkét reláció kulcsától együttesen függenek; Normalizálással, ha kell, tovább bontjuk a relációkat; Kiszűrjük a redundanciát. (Minden attribútum, ami nem kulcs, csak egyszer szerepelhet.)
")
89
E-R diagram

90
Gépjármű reláció … RENDSZÁM GYÁRTMÁNY TÍPUS SZÍN ŰRTAR-TALOM EGYÉB
CYX462 Mitsubishi Colt GL Fehér 1298 … DY9680 Ford Sierra L Ezüst 1598 ABC017 Daihatsu Charade Kék 980 V24034 Escort Piros 1199 CZ9404 Volkswagen Fastback TL Zöld 1596 HHU561 Carisma 1790

91
Tulajdonos reláció … NÉV LAKCÍM JOGOSÍTVÁNY FOGLAL-KOZÁS EGYÉB
Kiss János 1 Budapest I. Fő u. 1. CX162233 autószerelő … Quittner Pál Budapest V. Markó u. 1/b. CC23456 adatbázis szakértő Lakinger Béla Abádszalók, Hős u. 69. ABC4321 tengerész Kiss János 2 Pécs, Anna u. 16 tanár Computer Kft Győr, Rába köz 1/b

92
G&T reláció RENDSZÁM TULAJDONOS TULAJDONJOG KEZDETE TULAJDONJOG VÉGE
CYX462 Quittner DY9680 PálKiss János 1 Lakinger Béla ABC017 Computer Kft Y24034 Kovács Imre HHU561 Quittner Pál

93
Relációs műveletek A relációs modell legfőbb előnye az, hogy a különféle feltételeknek megfelelő fizikailag is létező egyedeit vagy ezekből logikai úton előállítható, vagy csak ideiglenes egyedeit, könnyen, egyszerűen megtudjuk határozni, azonosíthatjuk, kiválaszthatjuk, definiálhatjuk őket.

94
A relációs műveleteket az alábbi feladatok elvégzésére használjuk:
A kereséskor kiválasztandó adatok meghatározása; A módosítandó, törlendő adatok kiválasztása; A beviendő adatok meghatározása; Virtuális adatok definiálása. Ezek lehetnek az adatmodellnek állandó, névvel azonosított relációi (nézetek, pillanatfelvételek) vagy csak ideiglenesen létezők, melyek az adott feladat megoldásához szükségesek és utána automatikusan megszűnnek A fentieken kívül felhasználjuk még a relációs műveleteket az adatbázishoz való hozzáférési jogok meghatározásánál és integritási feltételek megadásánál is, amikor is ezek segítségével jelöljük ki a védelemmel rendelkező, lezárandó illetve egymással kapcsolatban álló objektumok, relációk körét.
 vagy csak ideiglenesen létezők, melyek az adott feladat megoldásához szükségesek és utána automatikusan megszűnnek. A fentieken kívül felhasználjuk még a relációs műveleteket az adatbázishoz való hozzáférési jogok meghatározásánál és integritási feltételek megadásánál is, amikor is ezek segítségével jelöljük ki a védelemmel rendelkező, lezárandó illetve egymással kapcsolatban álló objektumok, relációk körét.")
95
Legfontosabb műveletek
A rendszer zárt a műveletekre. Az eredmény újra reláció lesz. Megkülönböztethetünk egy és két (több) operandus műveleteket. átnevezés (RENAME) korlátozás vagy restrikció (RESTRICT) vetület vagy projekció (PROJECT) keresztszorzat (TIMES) unio (UNION) metszet (INTERSECT) különbség (DIFFERENCE) egyesítés (JOIN) egyesítés alapértelmezéssel (külső v. OUTER JOIN) bővítés (EXTEND) csoportfüggvény képzés (SUMMARIZE) kijelölés.
 operandus műveleteket. átnevezés (RENAME) korlátozás vagy restrikció (RESTRICT) vetület vagy projekció (PROJECT) keresztszorzat (TIMES) unio (UNION) metszet (INTERSECT) különbség (DIFFERENCE) egyesítés (JOIN) egyesítés alapértelmezéssel (külső v. OUTER JOIN) bővítés (EXTEND) csoportfüggvény képzés (SUMMARIZE) kijelölés.")
96
Egy relációs műveletek

97
Keresztszorzat

98
Union A két reláció minden sorát tartalmazza
Az azonos sorok csak egyszer szerepelnek benne. A relációknak unió kompatibilisnek kell lenniük. (Azonos számú, azonos sorrendben lévő, azonos adattípust tartalmazó oszlopokból állnak). UNION ALL A duplikált sorok duplikálva szerepelnek benne. Gyorsabb. Ha tudjuk, hogy a két reláció biztosan különböző sorokból áll, akkor ezt használjuk
. UNION ALL. A duplikált sorok duplikálva szerepelnek benne. Gyorsabb. Ha tudjuk, hogy a két reláció biztosan különböző sorokból áll, akkor ezt használjuk.")
99
Union példa

100
Intersection (metszet)
A két táblázat közös sorait tartalmazza. A táblázatok unió kompatibilisek

101
Minus (különbség) R – S azokat a sorokat tartalmazza, amik bent vannak R-ben, de nincsenek bent S-ben. A táblázatok unió kompatibilisek

102
JOIN (Egyesítés) A művelet két táblázat keresztszorzatának (Descartes szorzat) választja ki meghatározott sorait a JOIN feltétel alapján. Ez a gyakorlatban a két objektum meghatározott oszlopainak (join oszlopok) páronkénti összehasonlítását jelenti. A táblázatok/nézetek sorainak összekapcsolása szerint megkülönböztetünk Természetes vagy belső egyesítést (natural vagy inner join). Ha nem teszünk hozzá kiegészítést, akkor a join műveleten általában ezt értjük. Külső egyesítést (outer join).
 választja ki meghatározott sorait a JOIN feltétel alapján. Ez a gyakorlatban a két objektum meghatározott oszlopainak (join oszlopok) páronkénti összehasonlítását jelenti. A táblázatok/nézetek sorainak összekapcsolása szerint megkülönböztetünk. Természetes vagy belső egyesítést (natural vagy inner join). Ha nem teszünk hozzá kiegészítést, akkor a join műveleten általában ezt értjük. Külső egyesítést (outer join).")
103
Természetes (belső) JOIN
A természetes (belső) join eredménye csak azokat a sorokat tartalmazza, amelyekben mindkét join táblázat soraira érvényes a join feltétel. A természetes join szimmetrikus, a join objektumok megadásának sorrendje lényegtelen.
 join eredménye csak azokat a sorokat tartalmazza, amelyekben mindkét join táblázat soraira érvényes a join feltétel. A természetes join szimmetrikus, a join objektumok megadásának sorrendje lényegtelen.")
104
JOIN példa G&T GÉPJÁRMŰ
RENDSZÁM GYÁRTMÁNY CYX462 Mitsubishi DY9680 Ford ABC017 Daihatsu V24034 TULAJDONOS RENDSZÁM Quittner Pál CYX462 Kiss János 1 DY9680 Kiss János 2 ABC017 Lakinger Béla V24034 Az egyes személyek tulajdonában levő gépkocsik gyártmánya a (GÉPJÁRMŰ és G&T táblázatokból) RESTRICT G&T WHERE TULAJDONJOG VÉGE IS NULL) JOIN GÉPJÁRMŰ (RENDSZÁM)) PROJECT (TULAJDONOS, RENDSZÁM, GYÁRTMÁNY)
 RESTRICT G&T WHERE TULAJDONJOG VÉGE IS NULL) JOIN GÉPJÁRMŰ (RENDSZÁM)) PROJECT (TULAJDONOS, RENDSZÁM, GYÁRTMÁNY)")
105
JOIN példa

106
Külső (outer) JOIN A külső join eredménye nem csak azokat a sorokat tartalmazza, amelyekben mindkét join táblázat soraira érvényes a join feltétel, hanem azokat is, amelyek a join bal oldalán levő táblázatban/nézetben szerepelnek, de a jobboldaliban nincs olyan sor, amelyik a join feltételnek megfelel. Az eredményben ennek oszlopai a NULL Értéket veszik fel. Ez a LEFT OUTER JOIN vagy röviden LEFT JOIN , egyesítés balról. Igy az előző példából szerepelnének azok a tulajdonosok is, akiknek jelenleg nincsen gépkocsijuk.

107
Külső (outer) JOIN a join jobb oldalán levő táblázatban/nézetben szerepelnek, de a bal oldaliban nincs olyan sor, amelyik a join feltételnek megfelel. Az eredményben ennek oszlopai a NULL Értéket veszik fel. Ez a RIGHT OUTER JOIN vagy röviden RIGHT JOIN , egyesítés jobbról a join bármelyik táblázatban/nézetben szerepelnek. Ez a FULL OUTER JOIN vagy röviden FULL JOIN , teljes egyesítés. Az eredmény a két join komponens left outer join-jának és right outer join-jának unió-ja lesz. Tartalmazza mindazon sorokat, melyek vagy a balról vagy a jobbról való egyesítésben szerepelnek. Azok a sorok, amelyek mindkettőben benne vannak, csak egyszer jelennek meg a végeredményben.

108
Normalizáció A tervezés előző lépéseiként kapott entitásokat jól kezelhető, szabványos alakra hozza. Algoritmizálható. Eredményeképpen Az adatok tárlóigénye kisebb lesz; Az elemi adatokat gyorsabban és kevesebb hibalehetőséggel változtathatjuk meg; Az adatbázis logikailag áttekinthetőbb lesz.

109
Funkcionális függés Bármely relációban egyes attribútumok értékei függnek más attribútumok értékeitől. Ha az R relációban az egyik attribútum, (X), a független változó értéke egyértelműen meghatározza egy másik attribútum (Y), a függő változó értékét, akkor azt mondjuk, hogy Y funkcionálisan függ X-től az R relációban. Természetesen ez az egyértelmű kapcsolat nem csak R éppen aktuális tartalmára érvényes, hanem időtől független, az egész adatbázis létezésének időtartamára fennálló megszorítás. Mind az X, mind az Y attribútum lehet összetett, azaz állhat több oszlopból is. A funkcionális függőség szokásos jelölése R.X R.Y Lehet ezt még funkcionális diagrammban, más névvel függőségi ábrában is ábrázolni.
, a független változó értéke egyértelműen meghatározza egy másik attribútum (Y), a függő változó értékét, akkor azt mondjuk, hogy Y funkcionálisan függ X-től az R relációban. Természetesen ez az egyértelmű kapcsolat nem csak R éppen aktuális tartalmára érvényes, hanem időtől független, az egész adatbázis létezésének időtartamára fennálló megszorítás. Mind az X, mind az Y attribútum lehet összetett, azaz állhat több oszlopból is. A funkcionális függőség szokásos jelölése. R.X R.Y. Lehet ezt még funkcionális diagrammban, más névvel függőségi ábrában is ábrázolni.")
110
Funkcionális függés ábrázolása.
A független attribútumból nyíl mutat a függő attribútumra. Az ábrán Y és Z is függ funkcionálisan X-től, Z pedig Y-tól is.

111
Teljes funkcionális függés
Általánosan megfogalmazva, az R relációban az Y attribútum funkcionálisan akkor és csak akkor függ teljesen az X (összetett) attribútumtól, ha funkcionálisan függ X-től, de nem függ X-nek egyetlen egy valódi összetevőjétől sem. Ha X nem összetett, akkor a funkcionális és a teljes funkcionális függőség ugyanazt jelenti.
 attribútumtól, ha funkcionálisan függ X-től, de nem függ X-nek egyetlen egy valódi összetevőjétől sem. Ha X nem összetett, akkor a funkcionális és a teljes funkcionális függőség ugyanazt jelenti.")
112
Példa teljes függésre Példa funkcionális függőségre, de nem teljes függőségre egy több tételes szállítólevél, amely többek között tartalmazza a szállítólevél számát, az áru kódját (a kettő együttesen alkotja az elsődleges kulcsot), az áru nevét, mennyiségét, árát, és a szállítási dátumot. Itt a mennyiség funkcionálisan teljesen függ az elsődleges kulcstól, míg a dátum, az áru neve és ára nem. A dátumot a szállítólevél száma, a másik kettőt az áru kódja is egyértelműen meghatározza már.
, az áru nevét, mennyiségét, árát, és a szállítási dátumot. Itt a mennyiség funkcionálisan teljesen függ az elsődleges kulcstól, míg a dátum, az áru neve és ára nem. A dátumot a szállítólevél száma, a másik kettőt az áru kódja is egyértelműen meghatározza már.")
113
Normalizáció (1) A különböző relációk közötti függőségeket az adatbázis-kezelő rendszer az idegen kulcsok definiálásával automatikusan szavatolni tudja. Ugyanazon reláció oszlopai közti függőségek betartására azonban ilyen automatizmus nem létezik. Ezt vagy programmal kellene mindig ellenőrizni, vagy ellentmondás keletkezhet egy reláción belül. A normalizációval, mint látni fogjuk, ezeket a függőségeket küszöböljük ki. Így a helyesen normalizált adatbázisba nem kerülhetnek ellentmondásban lévő adatok.

114
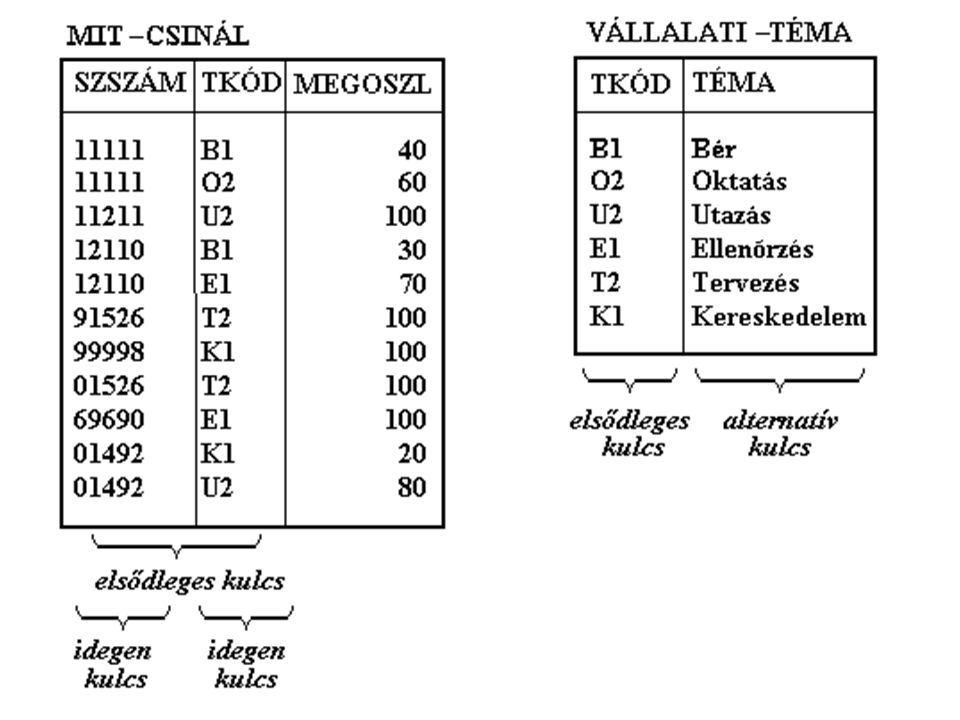
Normalizációs példa Dolgozói nyilvántartást kell készítenünk a vállalatnál. Minden dolgozónál szükségünk van a következő adatokra (zárójelben az oszlop neve): személyi azonosító szám (SZEMSZ) vezetéknév (VEZ-NÉV) keresztnév (KER-NÉV) osztály kódja, ahol dolgozik (OSZT) osztály megnevezése (OSZT-NÉV) téma kódja, amelyen dolgozik (TKÓD) téma megnevezése (TÉMA) munkaidejének hány százalékában dolgozik a témán (MEGOSZL) születésének éve (SZÜL-ÉV) osztálya főnökének személyi azonosító száma (FŐNÖK)
: személyi azonosító szám (SZEMSZ) vezetéknév (VEZ-NÉV) keresztnév (KER-NÉV) osztály kódja, ahol dolgozik (OSZT) osztály megnevezése (OSZT-NÉV) téma kódja, amelyen dolgozik (TKÓD) téma megnevezése (TÉMA) munkaidejének hány százalékában dolgozik a témán (MEGOSZL) születésének éve (SZÜL-ÉV) osztálya főnökének személyi azonosító száma (FŐNÖK)")
115
Normalizációs példa A vállalati feltételek további elemzése alapján megállapítjuk, hogy a személyi azonosítószám egyedi, az osztályok kódja és megnevezése egyedi, a kettő között egyértelmű kapcsolat áll fenn, ugyanez érvényes a témára és témakódra is, egy dolgozó csak egy osztályhoz tartozhat, de több témán is dolgozhat, a témák és osztályok között nem kell kapcsolatot teremtenünk, nem kell automatikusan ellenőriznünk, hogy a témák összességére fordított idő a dolgozó teljes munkaideje-e (100%).
.")
116
Normalizációs példa Az adatokat osztályonként gyűjtik be. Így az induló táblázatunk osztályonként egy-egy rekordot, „sort” tartalmaz, melynek első mezője az osztály kódja, második az osztály neve, utána annyiszor jönnek az egyes dolgozók fent sorolt adatai, ahány dolgozó van az osztályon. Végül az utolsó mező az osztály vezetőjének azonosító száma.

117
Bejövő adatok szerkezete
MEZŐK: OSZT OSZT-NÉV SZEMSZ VEZ-NÉV KER-NÉV TKÓD TÉMA MEGOSZL SZÜL-ÉV FŐNÖK ISMÉTLŐDÉSEK: SZEMSZ VEZ-NÉV KER-NÉV TKÓD TÉMA MEGOSZL SZÜL-ÉV Ismétlődik annyiszor, ahány dolgozó van az osztályon TKÓD TÉMA MEGOSZL minden dolgozónál ismétlődik, annyiszor, ahány témán doldozik. NEM RELÁCIÓ!

118
Bejövő adatok P01 Pénzügy Andrásfai Béla B1 Bér 40 O2 Oktatás Bártfai . . . . . . Tóth Csilla E1 Ellenőrzés Tarnay Gyula T2 Tervezés T01 Titkárság Mohácsi Győző T2 Tervezés Tojásos Kristóf U2 Utazások

119
Ismétlődés megszüntetése
Nem reláció, ismétlődő mezőket tartalmaz. Ezek kiküszöbölése: Eredeti: a b c1, c2, c3, d Átalakított: a b c1 d a b c2 d a b c3 d . . .

120
Első normál forma Első normál formában (INF) van az a reláció, amelyikben minden oszlop egy, és csak egy attribútumot jelent, minden sor különbözik, az attribútumok sorrendje minden sorban ugyanaz, nincsenek ismétlődő mezők, minden sorhoz tartozik (legalább) egy egyedi kulcs, melytől az összes többi attribútum funkcionálisan függ.
 egy egyedi kulcs, melytől az összes többi attribútum funkcionálisan függ.")
121
Első normál forma Minden relációs adatbázis-kezelő rendszer megköveteli, hogy az adatok legalább első normál formában (1NF) legyenek. Bár ezen a normalizáltsági szinten még sok probléma fölmerülhet, ennél magasabb fok már nem szükséges, de mint a későbbiekben látni fogjuk, általában javasolt.
 legyenek. Bár ezen a normalizáltsági szinten még sok probléma fölmerülhet, ennél magasabb fok már nem szükséges, de mint a későbbiekben látni fogjuk, általában javasolt.")
122
Alkalmazottak 1 NF PK PK

123
Anomáliák Látható a sok redundancia (pl. osztály és témanév).
Rejtett hibalehetőségek (változtatási anomáliák): Törlési anomália: Andrásfai Béla vagy Vigécz Jenő kilép, megszűnik az O2 téma, illetve E01 Eladási osztály. Módosítási anomália: Tóth Csilla férjhez megy, vagy a P01 osztályra új főnök kerül. Sok helyen kell módosítani, nem biztos, hogy ez mindenhol megtörténik. Beírási anomália: Új dolgozót csak akkor vihetünk be, ha van már témája, új osztályt, témát, ha van dolgozója. (Elsődleges kulcs része nem lehet NULL-érték.)
: Törlési anomália: Andrásfai Béla vagy Vigécz Jenő kilép, megszűnik az O2 téma, illetve E01 Eladási osztály. Módosítási anomália: Tóth Csilla férjhez megy, vagy a P01 osztályra új főnök kerül. Sok helyen kell módosítani, nem biztos, hogy ez mindenhol megtörténik. Beírási anomália: Új dolgozót csak akkor vihetünk be, ha van már témája, új osztályt, témát, ha van dolgozója. (Elsődleges kulcs része nem lehet NULL-érték.)")
124
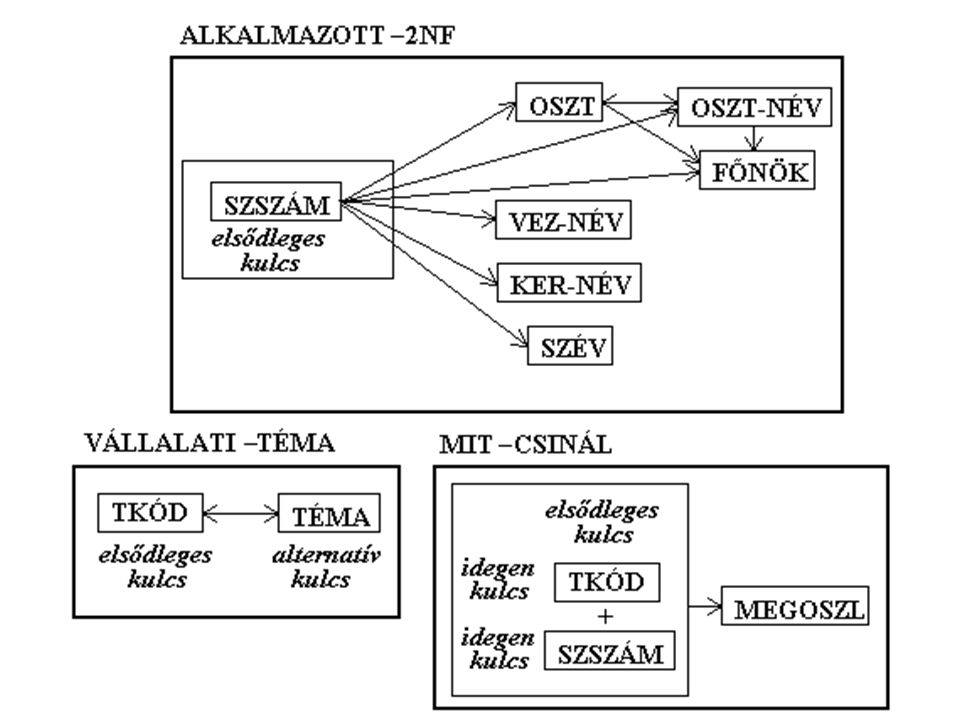
Függőségi diagram

125
Második normál forma Második normál formában (2NF) akkor, és csak akkor van egy reláció, ha 1NF-ben van, és az összes nem kulcs attribútum funkcionálisan teljesen függ az elsődleges kulcstól. Elemi elsődleges kulcsú 1NF relációk automatikusan 2NF-ben is vannak. Összetett kulcsú relációkat azonban a változtatási anomáliák megszüntetése érdekében 2NF-re kell hoznunk. (Ez nem biztos, hogy megszünteti az összes anomáliát, de jelentősen csökkentheti számukat.) Ezt nevezzük a relációk szétbontásának vagy dekompozíciónak. A szétbontás úgy történik, hogy az 1NF relációból projekcióval olyan 2 NF relációkat állítunk elő, melyeknek elsődleges kulcsai az eredeti reláció elsődleges kulcsa, illetve annak részei, oszlopai pedig azok és csak azok, amelyek az új elsődleges kulcstól funkcionálisan teljesen függenek.
 akkor, és csak akkor van egy reláció, ha 1NF-ben van, és az összes nem kulcs attribútum funkcionálisan teljesen függ az elsődleges kulcstól. Elemi elsődleges kulcsú 1NF relációk automatikusan 2NF-ben is vannak. Összetett kulcsú relációkat azonban a változtatási anomáliák megszüntetése érdekében 2NF-re kell hoznunk. (Ez nem biztos, hogy megszünteti az összes anomáliát, de jelentősen csökkentheti számukat.) Ezt nevezzük a relációk szétbontásának vagy dekompozíciónak. A szétbontás úgy történik, hogy az 1NF relációból projekcióval olyan 2 NF relációkat állítunk elő, melyeknek elsődleges kulcsai az eredeti reláció elsődleges kulcsa, illetve annak részei, oszlopai pedig azok és csak azok, amelyek az új elsődleges kulcstól funkcionálisan teljesen függenek.")
126
Dekompozició (1NF 2 NF) R(A,B,C,D) Szétbontás előtt (1NF)
ELSŐDLEGES KULCS (A,B) R.A R.D Szétbontás után (2NF) R1(A,D) ELSŐDLEGES KULCS (A) és R2(A,B,C) IDEGEN KULCS (A), HIVATKOZIK R1-RE
 R.A R.D. Szétbontás után (2NF) R1(A,D) ELSŐDLEGES KULCS (A) és. R2(A,B,C) IDEGEN KULCS (A), HIVATKOZIK R1-RE.")
127
Szétbontás 2 NF relációkra

129
Szétbontás 2 NF relációkra
Ezzel a szétbontással a változtatási anomáliák egy részét kiküszöböltük. Például: Andrásfai Béla kilépésével nem szűnik meg az „Oktatás” téma és az O2 Oktatás kapcsolat sem (törlési anomália) Új dolgozót is felvehetünk anélkül, hogy témát adnánk neki (beírási anomália) A többi probléma azonban még továbbra is fennmarad. Azokat a harmadik normál formába való szétbontás küszöböli csak ki.
 Új dolgozót is felvehetünk anélkül, hogy témát adnánk neki (beírási anomália) A többi probléma azonban még továbbra is fennmarad. Azokat a harmadik normál formába való szétbontás küszöböli csak ki.")
130
Szétbontás 2 NF relációkra
Ez a szétbontás teljes. Az összes olyan információt tartalmazza, ami az eredeti relációban benne volt. De ezen kívül több is van benne, t.i. az, hogy az O2 témakód megnevezése Oktatás, az E01 osztályé pedig „Eladás”, míg az eredeti reláció ezeket csak addig tartalmazza, amíg van legalább egy olyan dolgozó az adatbázisban, aki ezen a témán, illetve ezen az osztályon dolgozik.

131
Szétbontás 2 NF relációkra
A 2NF-be hozott relációkban az ALKALMAZOTTAK-2NF-ben nyilvánvaló redundáns osztálynevek mellett még mindig megmaradtak az alábbi változtatási anomáliák: Vigécz Jenő kilépésével (törlésével) megszűnnek az eladási osztályra vonatkozó információink. Ha a P01 (vagy a T01) osztálynak új főnöke lesz (módosítás), akkor azt továbbra is több helyen kell végigvezetni. Továbbra sem tudunk új osztályt addig fölvenni (beírás), amíg nincsen legalább egy új dolgozója.
 megszűnnek az eladási osztályra vonatkozó információink. Ha a P01 (vagy a T01) osztálynak új főnöke lesz (módosítás), akkor azt továbbra is több helyen kell végigvezetni. Továbbra sem tudunk új osztályt addig fölvenni (beírás), amíg nincsen legalább egy új dolgozója.")
133
Harmadik normál forma Egy reláció akkor és csak akkor van 3NF-ben, ha 2NF-ben van, és az elsődleges kulcshoz nem tartozó attribútumai csak az elsődleges kulcstól függenek funkcionálisan. Másképpen fogalmazva a 3NF azt jelenti, hogy funkcionális függés csak az elsődleges és az alternatív kulcsokból indulhat ki. Az ALKALMAZOTTAK-2NF reláció nincs 3NF-ben, mert pl. az osztály (OSZT) nem elsődleges vagy alternatív kulcs, és más oszlopok (OSZT-NÉV), FŐNÖK) funkcionálisan függnek tőle.
 nem elsődleges vagy alternatív kulcs, és más oszlopok (OSZT-NÉV), FŐNÖK) funkcionálisan függnek tőle.")
134
Szétbontás 2 NF 3 NF A szétbontás úgy történik, hogy a 2 NF relációnak vesszük azt a projekcióját, amelyik csak azokat az attribútumokat tartalmazza, amelyek kizárólag az elsődleges kulcstól függenek. Ennek elsődleges kulcsa ugyanaz marad. A másik új reláció (vagy relációk, ha több összefüggés van) elsődleges kulcsa a szétbontott reláció független attribútuma, oszlopai pedig a tőle függő attribútumok.
 elsődleges kulcsa a szétbontott reláció független attribútuma, oszlopai pedig a tőle függő attribútumok.")
135
Szétbontás 2 NF 3 NF Általánosan megfogalmazva, ha az A,B,C,D oszlopokkal (bármelyik lehet összetett is) rendelkező 2 NF relációban R(A,B,C,D) ELSŐDLEGES KULCS (A) R.B R.C akkor a 3NF-re való szétbontás a következő relációk létrehozását jelenti: R1(B,C) ELSŐDLEGES KULCS (B) és R2(A,B,D) IDEGEN KULCS (B), HIVATKOZIK R1-RE Az R relációt bármikor egyértelműen vissza tudjuk állítani R1 és R2 egyesítéséből (B-re). Lényeges azonban, hogy a szétbontás a fent megadott elv szerint történjen.
 ELSŐDLEGES KULCS (A) R.B R.C. akkor a 3NF-re való szétbontás a következő relációk létrehozását jelenti: R1(B,C) ELSŐDLEGES KULCS (B) és. R2(A,B,D) IDEGEN KULCS (B), HIVATKOZIK R1-RE. Az R relációt bármikor egyértelműen vissza tudjuk állítani R1 és R2 egyesítéséből (B-re). Lényeges azonban, hogy a szétbontás a fent megadott elv szerint történjen.")
136
3 NF relációk Nem mindig célszerű a 3NF alak (pl. cím és irányítószám). A legtöbb adatbázis-kezelő rendszernek elég az 1 NF, sőt, még elsődleges kulcs sem kötelező!!!

137
3 NF relációk

139
Nézetek definiálása Igen nehézkesen dolgoznánk, ha csak a normalizált relációkat használhatnánk. Pl: Rendszeres kérdés: „Egy adott dolgozó milyen nevű osztályon, témán és az utóbbiakon milyen megoszlásban dolgozik?” Négy táblázatot kellene egyesíteni. Ehelyett definiálhatunk egy VÁLASZ nézetet, mely ezeket az adatokat előállítja relációs műveletekkel. A „kérem a VÁLASZ adott dolgozójú sorait” megadja a feleletet.

140
Nézetek definiálása VÁLASZ = PROJECT DOLGOZÓ (VEZ-NÉV,KER-NÉV)
JOIN [SZEMSZÁM] PROJECT MIT-CSINÁL (MEGOSZL) JOIN [TKÓD] PROJECT TÉMÁK (TMEGNEV) JOIN [OSZT] PROJECT OSZTÁLYOK (OSZTNÉV)
 JOIN [TKÓD] PROJECT TÉMÁK (TMEGNEV) JOIN [OSZT] PROJECT OSZTÁLYOK (OSZTNÉV)")
141
A tervezés főbb lépései
A szükséges adatok kiválasztása. Az összetartozó adatok, az entitások meghatározása, adatok csoportosítása. Az entitások közti kapcsolatok meghatározása. A több-több kapcsolatok felbontása új relációk segítségével. A relációk létrehozása, adatok (legalább) első normalizált formákba való csoportosítása. Idegen kulcsok meghatározása a relációk közti kapcsolatok biztosítására.
 első normalizált formákba való csoportosítása. Idegen kulcsok meghatározása a relációk közti kapcsolatok biztosítására.")
142
A tervezés főbb lépései
A szükséges magasabb fokú normalizáció elvégzése. Táblázatok létrehozása a normalizált relációk alapján. A várható feladatok adatait együttesen, egyben tartalmazó relációk meghatározása. Az így kapott relációk állandó nézetként való létrehozása. Adatok betöltése, műveletek az adatokkal. Szükség esetén az adatbázis szerkezetének módosítása, új táblázatok, nézetek létrehozása egy 1-10-ben leírtak szerint.

143
Tervezési gyakorlat (1)
Vannak: áruk, vevők, szállítások. Ehhez tartozik: árukód, árumegnevezés, ár- és leszállított mennyiség az egyes vevőknek, vevőkód, vevő név, telephely és kedvezmény, mely a telephelytől függ. Építsünk fel egy nem normalizált, és különböző szinten normalizált modelleket ezek leírására. Milyen – a valóságban nem megvalósuló – egyszerűsítéseket tettünk? Milyen adatokkal kell kibővítenünk az adatbázist, hogy a realizálásoknak eleget tevő modellt kapjunk?

144
Megrendelés – E–R diagram

145
Megrendelés – E–R diagram

146
Tervezési gyakorlat (1)
Árak változnak Új táblázat: ÁRVÁLTOZÁS Egy vevő több árut rendel meg Új táblázat: Megrendelés Ehhez kapcsolódik : TÉTEL Feltétel: Egy megrendelésben ugyanaz az áru csak egyszer szerepelhet. Teljesítést is bevesszük Új mező tételben Feltétel: Egy tételt egyben szállítunk Probléma marad: Egy vevőnek több telephelye van

147
Árváltozás

148
Megrendelés

149
Megrendelés – E–R diagram

150
Tervezési gyakorlat (2)
Készítse el egy vállalat dolgozói nyilvántartásának Entity-relationship diagrammját, definiálja az egyes relációk oszlopait és kulcsait! Minden dolgozónál szükségünk van a következő adatokra (zárójelben az oszlop neve): személyi azonosító szám (SZEMSZ) név (NÉV) osztály kódja, ahol dolgozik (O-KÓD) osztály megnevezése (O-NÉV) téma kódja, amelyen dolgozik (T-KÓD) téma megnevezése (T-NÉV) munkaidejének hány százalékában dolgozik a témán (MEGOSZL) beosztása (BEOSZT) a beosztásához tartozó maximális és minimális fizetés (MAX-FIZ, MIN-FIZ) osztálya főnökének személyi azonosító száma (FŐNÖK)
: személyi azonosító szám (SZEMSZ) név (NÉV) osztály kódja, ahol dolgozik (O-KÓD) osztály megnevezése (O-NÉV) téma kódja, amelyen dolgozik (T-KÓD) téma megnevezése (T-NÉV) munkaidejének hány százalékában dolgozik a témán (MEGOSZL) beosztása (BEOSZT) a beosztásához tartozó maximális és minimális fizetés (MAX-FIZ, MIN-FIZ) osztálya főnökének személyi azonosító száma (FŐNÖK)")
151
Tervezési gyakorlat (2)
A vállalati feltételek további elemzése alapján megállapítjuk, hogy a személyi azonosítószám egyedi, az osztályok kódja és megnevezése egyedi, a kettő között egyértelmű kapcsolat áll fenn, ugyanez érvényes a témára és témakódra is, a beosztás egyértelműen meghatározza a hozzátartozó maximális és minimális fizetést egy dolgozó több osztályhoz is tartozhat és több témán is dolgozhat, egy dolgozó egy adott osztályon csak egy beosztásban dolgozhat, a különböző osztályokon azonban más lehet a beosztása a témák, beosztások és osztályok között nem kell kapcsolatot teremtenünk, nem kell automatikusan ellenőriznünk, hogy a témák összességére fordított idő a dolgozó teljes munkaideje-e (100%).
.")
152
E–R diagram, alkalmazottak

153
E–R diagram, alkalmazottak

154
Tervezési gyakorlat (2)
OSZTÁLYOK, MIT_CSINÁL, TÉMÁK: ugyanaz ALKALMAZOTTAK: oszt kikerül belőle HOL_DOLGOZIK szemszám PK, FK oszt PK, FK beosztás max_fiz min_fiz Nem 3NF, beosztástól függ max_fiz és min_fiz

155
Tervezési gyakorlat (2)
")
156
Hatékony munka Egy adatbázisban sokan dolgozhatnak egyszerre, egymással párhuzamosan. A hatékony munkához a felhasználóknak az alkalmazásaikat úgy kell elkészíteniük, hogy azok A lehető leggyorsabb módon érjék el és dolgozzák fel az adatokat, optimalizálják a saját alkalmazásukat. Ezt hatékony programok tervezésével és az adatszerkezet és az adatelérési módok megfelelő megválasztásával érhetjük el. Minél kevésbé zavarják, hátráltassák mások munkáját az adatbázisban (és természetesen, viszonzásul, a többiek se akadályozzák az ő munkájukat). Ez időnként csak saját munkájuk hatékonyságának rovására valósítható meg. Mivel nem mindenkitől várható el ilyen erős közösségi elkötelezettség, a jó adatbázis-kezelő rendszerek automatikusan rákényszerítik a felhasználókat a közös munka alapszabályainak betartására.
. Ez időnként csak saját munkájuk hatékonyságának rovására valósítható meg. Mivel nem mindenkitől várható el ilyen erős közösségi elkötelezettség, a jó adatbázis-kezelő rendszerek automatikusan rákényszerítik a felhasználókat a közös munka alapszabályainak betartására.")
157
Hibalehetőségek párhuzamos munkánál
A párhuzamos feldolgozásból eleve adódnak a következő hibalehetőségek: elveszett módosítás nem véglegesített adatok feldolgozása munka inkonzisztens adatokkal patthelyzet

158
Elveszett módosítás

159
Nem véglegesített adatok feldolgozása

160
Munka inkonzisztens adatokkal

161
Zárak Az adatbázisban használt zárakra jellemző a zár mérete
a zár erőssége a zár időtartama

162
Zárak mérete Database (Adatbázis) Tablespace Table (Táblázat)
Page (Lap) Row (Sor)
 Row (Sor)")
163
Zárak erőssége Osztott (Share) Kizárólagos (Exclusive) (Update)
 Kizárólagos (Exclusive) (Update)")
164
Zárak kompatibilitása
S U X S x x - U x - - X - - -

165
Várakozás Amikor egy tranzakció egy olyan erősségű új zárat
kíván elhelyezni, amelyik nem kompatibilis a rekordon már rajta lévő(k)vel, akkor ez a tranzakció vár addig, amíg az inkompatibilis zár meg nem szűnik. vár a rendszer paraméterei által meghatározott ideig (általában 30 – 120 másodpercig). Ha ez alatt az idő alatt az inkompatibilitást okozó zár megszűnik, akkor ráteszi a saját zárát. Ha az inkompatibilitás fennmarad, akkor hibajelzést ad (és ennek eredményeként általában ROLLBACK-kel befejeződik). Azonnal hibajelzést ad (és ennek eredményeként általában ROLLBACK-kel befejeződik
vel, akkor ez a tranzakció. vár addig, amíg az inkompatibilis zár meg nem szűnik. vár a rendszer paraméterei által meghatározott ideig (általában 30 – 120 másodpercig). Ha ez alatt az idő alatt az inkompatibilitást okozó zár megszűnik, akkor ráteszi a saját zárát. Ha az inkompatibilitás fennmarad, akkor hibajelzést ad (és ennek eredményeként általában ROLLBACK-kel befejeződik). Azonnal hibajelzést ad (és ennek eredményeként általában ROLLBACK-kel befejeződik.")
166
Zár mechanizmus

167
Patthelyzet

168
Adattárház Hagyományos adatbázis: Adattárház (Data Warehouse):
Lekérdezések Tranzakciók Dinamikus Elsősorban az aktuális állapotot tükrözi Adattárház (Data Warehouse): Lekérdezések igen nagy statikus adatmennyiségből Időbeli változásokat mutatja Adatok elemzésére szolgál Adatbányászat (Data Mining): Az adattárház adatai közt fennálló (rejtett) összefüggésekre derít fényt
: Lekérdezések igen nagy statikus adatmennyiségből. Időbeli változásokat mutatja. Adatok elemzésére szolgál. Adatbányászat (Data Mining): Az adattárház adatai közt fennálló (rejtett) összefüggésekre derít fényt.")
169
Adattárház jellemzői Témaorientált Integrált Statikus
Eladások adattárháza: Kik voltak az utóbbi időszakban a legjobb vevők Integrált Különböző forrásokból gyűjti össze az adott témához tartozó adatokat és azokat egységes formában tárolja Statikus Az egyszer bevitt adatok nem változnak már. Annak elemzésére szolgál, hogy mi történt Az adatok időbeli változását mutatja hosszú időre visszamenőleg

170
Komponensek Relációs adatbázis Adatkiválasztó
Adattranszformáló (egységesítő) Adatbevivő On-line analitikus elemző (On-Line Analytical Prosessing) Felhasználói analizáló eszközök Speciális alkalmazások
 Adatbevivő. On-line analitikus elemző (On-Line Analytical Prosessing) Felhasználói analizáló eszközök. Speciális alkalmazások.")
171
Tranzakció feldolgozásra orientált adatbázis
Összehasonlítás Tranzakció feldolgozásra orientált adatbázis Adattárház Komplex adatszerkezet, 3NF relációk Adatszerkezet Multidimenzionális adatszerkezet Nem túl sok Indexek Igen sok Minimális (3NF dominál) Redundancia Jelentős (1NF, 2NF, 3NF) Ritkán Származtatott adatok, aggregátumok tárolása Rendszeresen
 Redundancia. Jelentős (1NF, 2NF, 3NF) Ritkán. Származtatott adatok, aggregátumok tárolása. Rendszeresen.")
172
Tranzakció feldolgozásra orientált adatbázis
Követelmények Tranzakció feldolgozásra orientált adatbázis Adattárház Adott feladatokra optimalizált lekérdezések Feladatok Ad hoc jellegű lekérdezések Bármikor lehetséges Adatok változtatása Új adatok meghatá-rozott intervallumokban Normalizált (3NF) Adatmodell Részben normalizált (csillag), lekérdezésre optimalizált Néhány rekord kiválasztása, beolvasása Tipikus műveletek Sok millió rekord beolvasása Aktuális, vagy csak rövid időre visszamenőleges Adatok időbeli változásának tárolása Hosszú időre visszamenőleges
 Adatmodell. Részben normalizált (csillag), lekérdezésre optimalizált. Néhány rekord kiválasztása, beolvasása. Tipikus műveletek. Sok millió rekord beolvasása. Aktuális, vagy csak rövid időre visszamenőleges. Adatok időbeli változásának tárolása. Hosszú időre visszamenőleges.")
173
Adattárház felépítése

174
Csillag elrendezés

175
Dátum dimenzió

176
Eladás tény-táblázat

177
Eladási hely dimenzió

178
Adatbányászat Célja, miként lehet nagy adatbázisokban
rejtett tudást, új összefüggéseket, eddig nem ismert szabályokat, nem várt mintákat felfedezni Ha pontosan tudjuk, hogy mit keresünk, akkor használhatjuk az SQL nyelvet is

179
Adatbányászati kérdések
Melyek a legfontosabb ügyfél típusok? Melyek a legfontosabb ügyfélvásárlási szokások? Miért maradnak vagy lépnek ki a dolgozók a vállalattól? Mikor és milyen áron érdemes egy új terméket a piacra dobni?

Hasonló előadás




 Budapest>")








.>")
 1 Az objektum orientált szemlélet elterjedésével egyre nőtt az igény az olyan SDM (Semantic Data Model) modellek iránt,>")





