Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
CS345 Adatbányászat Hivatkozáselemzés 2: Témaspecifikus oldalrang Központok és tekintélyek Szemétfelderítés Anand Rajaraman, Jeffrey D. Ullman

2
Témaspecifikus oldalrang Az általános népszerűség helyett mérhetjük-e egy témán belüli népszerűséget? pl. számítástudomány, egészség Tereljük a véletlen sétát Amikor a véletlen sétáló teleportál, a weblapok egy S halmazából választ S csak a témával kapcsolatos oldalakat tartalmazza pl. Open Directory (DMOZ) lapok egy témában (www.dmoz.org)www.dmoz.org Minden S teleportáló halmazzal más r S rangvektort kapunk.
 lapok egy témában ( Minden S teleportáló halmazzal más r S rangvektort kapunk..")
3
A mátrix formalizálása A ij = M ij + (1-)/|S|, ha i ∈ S A ij = M ij különben Mutassuk meg, hogy A sztochasztikus Az S teleporthalmaz minden lapjának ugyanazt a súlyt adtuk Adthatnán különböző súlyokat is
/|S|, ha i ∈ S A ij = M ij különben Mutassuk meg, hogy A sztochasztikus Az S teleporthalmaz minden lapjának ugyanazt a súlyt adtuk Adthatnán különböző súlyokat is")
4
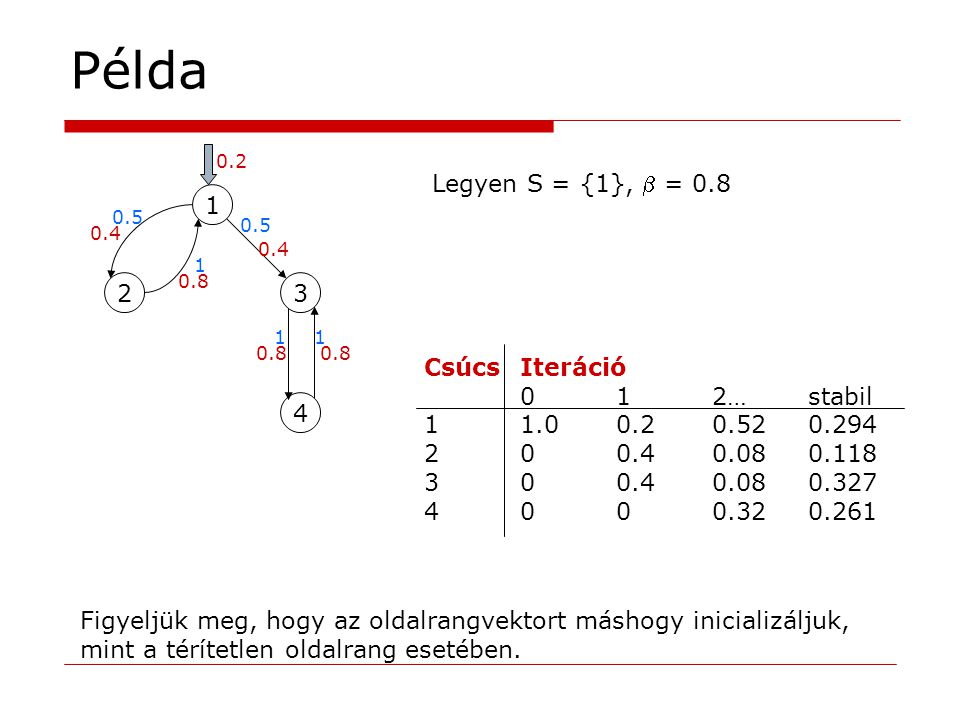
Példa 1 23 4 Legyen S = {1}, = 0.8 CsúcsIteráció 012…stabil 11.00.20.520.294 200.40.080.118 300.40.080.327 4000.320.261 Figyeljük meg, hogy az oldalrangvektort máshogy inicializáljuk, mint a térítetlen oldalrang esetében. 0.2 0.5 1 11 0.4 0.8
5
Milyen jól működik a TSPR? Kísérleti eredmények [Haveliwala 2000] 16 témát választottak ki A teleporthalmazokat a DMOZ alapján pl. művészet, üzlet, sport „Vak tanulmány” önkéntesekkel 35 teszt lekérdezés Az eredményeket rangsorolták a PageRankkel és a legközelebb álló téma TSPR-jével pl. a biciklizést a sport rangjával A legtöbb esetben az önkénteseknek jobban tetszett a TSPR rangsor

6
Melyik téma rangjait használjuk? A felhasználó menüből választhat Bayes-osztályozást használunk a lekérdezés témába sorolásához Használhatjuk a lekérdezés környezetét pl. a lekérdezés egy ismert témáról szóló oldalról indult Lekérdezések története, pl. „kosárlabda” után „jordan” Felhasználói környezet, pl. My Yahoo beállítások, könyvjelzők

7
Központok és tekintélyek Tegyük fel, hogy van egy dokumentumkollekciónk egy tág témakörben pl. stanford, evolúció, irak esetleg szöveges keresés eredménye Szervezhetjük-e ezeket valamilyen módon? Az oldalrang egy megoldás HITS (Hypertext-Induced Topic Selection, hiperszövegből levezetett témaválasztás) egy másik kb. ugyanabban az időben javasolták (1998)
 egy másik kb. ugyanabban az időben javasolták (1998).")
8
HITS modell Az érdekes dokumentumok két osztályba tartoznak 1.A tekintélyek hasznos információkat tartalmazó lapok kari dolgozók honlapjai buszgyárak honlapjai 2.A központok olyan lapok, amelyek tekintélyekre hivatkoznak kar dolgozóinak jegyzéke magyarországi buszgyárak listája

9
Ideális látvány KözpontokTekintélyek

10
Kölcsönösen rekurzív definíció Egy jó központ sok jó tekintélyre hivatkozik Egy jó tekintélyre sok jó központ hivatkozik A modell minden csúcshoz két számot rendel Központ érték és Tekintély érték Reprezentáljuk a h és a vektorokkal

11
Átmeneti mátrix: A A H&A mátrixában A [i, j ] = 1, ha az i. lap hivatkozik a j.-re, 0, ha nem. A T, azaz A transzponáltja, hasonlít a PageRank M mátrixra, csak A T -ben 1- esek vannak, M-ben pedig törtek.
![Átmeneti mátrix: A A H&A mátrixában A [i, j ] = 1, ha az i.](http://images.slideplayer.hu/10/2975019/slides/slide_11.jpg "lap hivatkozik a j.-re, 0, ha nem. A T, azaz A transzponáltja, hasonlít a PageRank M mátrixra, csak A T -ben 1- esek vannak, M-ben pedig törtek..")
12
Példa Yahoo M’softAmazon y 1 1 1 a 1 0 1 m 0 1 0 y a m A =

13
Központ és tekintély egyenletei Egy P lap központ értéke arányos az általa hivatkozott lapok tekintély értékeinek összegével h = λ Aa A λ konstans skálázó tényező Egy P lap tekintély értéke arányos a rá hivatkozó lapok központ értékeinek összegével a = μ A T h A μ konstans skálázó tényező

14
Iterációs algoritmus Legyen h, a kezdetben csupa 1-es h = Aa Skálázzuk h-t úgy, hogy a maximális eleme 1 legyen a = A T h Skálázzuk a-t úgy, hogy a maximális eleme 1 legyen Folytassuk, amíg h, a nem konvergál

15
Példa 1 1 1 A = 1 0 1 0 1 0 1 1 0 A T = 1 0 1 1 1 0 a(yahoo) a(amazon) a(m’soft) ====== 111111 111111 1 4/5 1 0.75 1... 1 0.732 1 h(yahoo) = 1 h(amazon) = 1 h(m’soft) = 1 1 2/3 1/3 1 0.73 0.27... 1.000 0.732 0.268 1 0.71 0.29
 = 1 h(amazon) = 1 h(m’soft) = 1 1 2/3 1/")
16
Létezés és egyértelműség h = λ Aa a = μ A T h h = λμ AA T h a = λμ A T A a Ésszerű feltételezésekkel élve A-ról, a duális iterációs algoritmus a h* és a* vektorokhoz tart, ahol: h* a fő sajátvektora az AA T mátrixnak a* a fő sajátvektora az A T A mátrixnak

17
Páros magok KözpontokTekintélyek Leginkább sűrűn összefüggő mag (elsődleges mag) Kevésbé sűrűn összefüggő mag (másodlagos mag)
 Kevésbé sűrűn összefüggő mag (másodlagos mag)")
18
Másodlagos magok Egy témának lehet sok páros magja különböző jelentésekhez vagy nézőpontokhoz abortusz: választás melletti, élet melletti érv evolúció: darwini, intelligens tervezés lokomotív: mozdony, focicsapat, rockegyüttes Hogyan keressünk ilyen másodlagos magokat?

19
Másodlagos magok keresése Amint megtaláltuk az elsődleges magot, eltávolíthatjuk a hivatkozásait a gráfból Ismételjük meg a HITS algoritmust a maradék gráfra, így megtaláljuk a következő páros magot Durván ezek a nem fő sajátvektoroknak felelnek meg az AA T és A T A mátrixokban

20
A HITS gráf létrehozása Összefüggő gráf kell, hogy a HITS jól működjön

21
A Page Rank és a HITS A Page Rank és a HITS ugyanarra a problémára két megoldás Mi S-ből D-be vivő hivatkozás értéke? Az oldalrang modellben a hivatkozás értéke az S felé menő hivatkozásoktól függ A HITS modellben az S-ből kimenő egyéb hivatkozások értékétől függ A Page Rank és a HITS 1998 utáni végzete nagyon különböző lett Miért?

22
Webszemét A keresés lett a web általános kapuja Nagyon nagy kiváltság a keresési találatok első oldalán megjelenni pl. e-kereskedelmi lapok reklám által fenntartott lapok

23
Mi a webszemét? Szemetelés (spamming) = szándékos cselekedet, amelynek célja egy weboldal helyzetének javítása a keresők eredményeiben, az oldal valódi értékéhez képest aránytalan mértékben Szemét = olyan weblapok, amelyek szemetelés eredményeként jöttek létre Ez nagyon tág definíció A SEO ipar nem ért egyet! SEO = keresőgépre optimalizálás Hozzávetőlegesen a weblapok 10-15%-a szemét
 = szándékos cselekedet, amelynek célja egy weboldal helyzetének javítása a keresők eredményeiben, az oldal valódi értékéhez képest aránytalan mértékben Szemét = olyan weblapok, amelyek szemetelés eredményeként jöttek létre Ez nagyon tág definíció A SEO ipar nem ért egyet. SEO = keresőgépre optimalizálás Hozzávetőlegesen a weblapok 10-15%-a szemét.")
24
A webszemét rendszertana Gyöngyi Zoltán és Hector García-Molina megközelítését követjük [2004] Fellendítő technikák Olyan technikák, amellyel magas relevancia/fontosság érhető el egy weblapon Elrejtő technikák A fellendítő technikák elrejtésére szolgálnak Elrejtés emberek és webtetűk * elől *web crawler
![A webszemét rendszertana Gyöngyi Zoltán és Hector García-Molina megközelítését követjük [2004] Fellendítő technikák Olyan technikák, amellyel magas relevancia/fontosság érhető el egy weblapon Elrejtő technikák A fellendítő technikák elrejtésére szolgálnak Elrejtés emberek és webtetűk * elől *web crawler](http://images.slideplayer.hu/10/2975019/slides/slide_24.jpg "A webszemét rendszertana Gyöngyi Zoltán és Hector García-Molina megközelítését követjük [2004] Fellendítő technikák Olyan technikák, amellyel magas relevancia/fontosság érhető el egy weblapon Elrejtő technikák A fellendítő technikák elrejtésére szolgálnak Elrejtés emberek és webtetűk * elől *web crawler")
25
Fellendítő technikák Szószemetelés A weblap szövegének módosítása úgy, hogy az relevánsnak tűnjön egy keresésben Linkszemetelés Olyan hivatkozási szerkezet létrehozása, amely az oldalrangot vagy a központ és tekintély értékeket lendíti fel

26
Szószemetelés Ismétlés néhány konkrét kifejezés, pl. ingyen, olcsó, viagra Célja a TF.IDF rangsémák átverése Dömping sok nem kapcsolódó kifejezés pl. egész szótárak másolata Szövés valódi oldalak lemásolása és véletlenszerű helyeken szemétkifejezések beszúrása Kifejezéstűzés Különböző forrásokból származó mondatok és kifejezések összeragasztása

27
Linkszemetelés Háromféle weboldal a szemetelő nézőpontjából Elérhetetlen lapok Elérhető lapok pl. blog hozzászóló lapok a szemetelő hivatkozhat a saját lapjára Saját lapok teljesen a szemetelő irányítása alatt több tartománynevet is átfoghat

28
Linkfarmok A szemetelő célja Maximalizálni a t céloldal rangját Technika Szerezzünk sok hivatkozást a t céloldalra az elérhető oldalakról Építsünk „linkfarmot”, hogy elérjük az oldalrangot szorzó hatást

29
Linkfarmok Elérhetetlen t ElérhetőSaját 1 2 M Az egyik leggyakoribb és leghatékonyabb linkfarm szervezés.

30
Elemzés Tegyük fel, hogy az elérhető lapoktól származó rang = x Legyen a céloldal rangja = y Egy „farm” oldal rangja = y/M + (1-)/N y = x + M[y/M + (1-)/N] + (1-)/N = x + 2 y + (1-)M/N + (1-)/N y = x/(1- 2 ) + cM/N, ahol c = /(1+) Elérhetetlen t Elérhető Saját 1 2 M Nagyon kicsi; elhanyagolható
![Elemzés Tegyük fel, hogy az elérhető lapoktól származó rang = x Legyen a céloldal rangja = y Egy „farm oldal rangja = y/M + (1-)/N y = x + M[y/M + (1-)/N] + (1-)/N = x + 2 y + (1-)M/N + (1-)/N y = x/(1- 2 ) + cM/N, ahol c = /(1+) Elérhetetlen t Elérhető Saját 1 2 M Nagyon kicsi; elhanyagolható](http://images.slideplayer.hu/10/2975019/slides/slide_30.jpg "Elemzés Tegyük fel, hogy az elérhető lapoktól származó rang = x Legyen a céloldal rangja = y Egy „farm oldal rangja = y/M + (1-)/N y = x + M[y/M + (1-)/N] + (1-)/N = x + 2 y + (1-)M/N + (1-)/N y = x/(1- 2 ) + cM/N, ahol c = /(1+) Elérhetetlen t Elérhető Saját 1 2 M Nagyon kicsi; elhanyagolható")
31
Elemzés y = x/(1- 2 ) + cM/N, ahol c = /(1+) Ha = 0.85 akkor 1/(1- 2 )= 3.6 Szorzó hatás a „szerzett” oldalrangnak M növelésével y-t bármilyen nagyra növelhetjük Elérhetetlen t Elérhető Saját 1 2 M
 + cM/N, ahol c = /(1+) Ha = 0.85 akkor 1/(1- 2 )= 3.6 Szorzó hatás a „szerzett oldalrangnak M növelésével y-t bármilyen nagyra növelhetjük Elérhetetlen t Elérhető Saját 1 2 M")
32
A szemét felfedezése Szószemetelés Statisztikai módszerrel, pl. naív Bayes- osztályozással elemezzük a szöveget Hasonló az e-mail szemétszűréshez Hasznos is lehet: nagyjából megegyező lapok felfedezése Linkszemetelés Nyitott kutatási terület Egy megközelítés: TrustRank

33
TrustRank ötlete Alapelv: közelítők elkülönítése Ritka, hogy egy „jó” oldal mutat egy „rossz” (szemét) oldalra Vegyünk mintát egy néhány „magoldalról” a weben Kérjünk meg egy „jóst” (embert), hogy azonosítsa a jó és szemét oldalakat a maghalmazban Drága feladat, ezért a maghalmaz legyen minél kisebb
 oldalra Vegyünk mintát egy néhány „magoldalról a weben Kérjünk meg egy „jóst (embert), hogy azonosítsa a jó és szemét oldalakat a maghalmazban Drága feladat, ezért a maghalmaz legyen minél kisebb")
34
A bizalom terjedése Nevezzük a maghalmaz „jó”-nak ítélt oldalait „megbízható” oldalaknak A megbízható oldalak bizalom értéke legyen 1 Terjesszük a bizalmat a hivatkozásokon keresztül Minden oldal kap egy 0 és 1 közötti bizalom értéket Használjunk egy küszöbértéket, és jelöljük meg a küszöb alatti oldalakat szemétként

35
A bizalom terjedésének szabályai A bizalom csillapítása Egy megbízható oldal által adott bizalom csökken a távolsággal A bizalom elosztása Minél több a kimenő hivatkozás, annál kevesebb figyelmet fordít az oldal szerzője a kimenő hivatkozásokra A bizalom „eloszlik” a kimenő hivatkozások között

36
Egyszerű modell Tegyük fel, hogy egy p oldal bizalma t(p) A kimenő hivatkozások halmaza O(p) Minden q ∈ O(p)-ra p átadja a bizalmat t(p)/|O(p)|, ahol 0<<1 A bizalom additív p bizalma a rá hivatkozó oldalak által p-nek átadott bizalmak összege Hasonlít a témaspecifikus oldalranghoz Egy skálázó tényezővel a bizalomrang = terelt oldalrang a megbízható oldalakat használva teleporthalmazként
 A kimenő hivatkozások halmaza O(p) Minden q ∈ O(p)-ra p átadja a bizalmat t(p)/|O(p)|, ahol 0<<1 A bizalom additív p bizalma a rá hivatkozó oldalak által p-nek átadott bizalmak összege Hasonlít a témaspecifikus oldalranghoz Egy skálázó tényezővel a bizalomrang = terelt oldalrang a megbízható oldalakat használva teleporthalmazként")
37
A maghalmaz kiválasztása Két egymásnak ellentétes megfontolás Embernek kell átnéznie minden egyes magoldalt, ezért a maghalmaznak minél kisebbnek kell lennie Biztosítani kell, hogy minden „jó oldal” elég jó bizalomrangot kapjon, tehát gondoskodni kell róla, hogy a jó lapok elérhetők legyenek a maghalmazból rövid utakon

38
Megközelítések a maghalmaz kiválasztására Tegyük fel, hogy k elemű maghalmazt szeretnénk kiválasztani PageRank Válasszuk ki az első k oldalt oldalrang alapján Feltesszük, hogy a magas oldalrangú oldalak közel állnak másik magas rangú oldalakhoz Jobban érdekelnek minket a magas rangó „jó” oldalak

39
Fordított oldalrang Válasszuk a legtöbb kimenő hivatkozással rendeklező oldalakat Tehetjük ezt rekurzívan Válasszunk sok kimenő hivatkozású oldalakra hivatkozó oldalakat Formalizáljuk „fordított oldalrang”-ként Vegyük a G’ gráfot, amely a G web gráf megfordítása A G’-ben az oldalrang a G-beli fordított oldalranggal egyenlő Válasszuk az első k oldalt fordított oldalrang alapján

40
Szeméttömeg A TrustRank modellben megbízható lapokkal indulink és terjesztjük a bizalmat Kiegészítő nézet: az oldalrang mekkora töredéke származik „szemét” lapokról? A gyakorlatban nem ismerjük az összes szemétoldalt, ezért becsülnünk kell

41
Szeméttömeg becslése r(p) = a p oldal oldalrangja r + (p) = p oldalrangja, ha csak „jó” lapokra teleportálhatunk r - (p) = r(p) – r + (p) p szeméttömege = r - (p)/r(p)
 = a p oldal oldalrangja r + (p) = p oldalrangja, ha csak „jó lapokra teleportálhatunk r - (p) = r(p) – r + (p) p szeméttömege = r - (p)/r(p)")
42
Jó oldalak Szeméttömeghez nagy mennyiségű „jó” oldalra van szükségünk. Nem kell olyan óvatosnak lenni az oldalak minőségét illetően, mint a TrustRank esetén Egy ésszerű megközelítés oktatási webhelyek kormányzati webhelyek katonai webhelyek

43
Másik megközelítés Visszaáramlás az ismert szemétoldalakról Még nyitott kutatási terület…

Hasonló előadás














 egy halmaza. Feladatunk: az objektumokat - valamilyen.>")

 mátrixot.>")


