Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
STATISZTIKA II. 9. Előadás
Dr. Balogh Péter egyetemi adjunktus Gazdaságelemzési és Statisztikai Tanszék

2
Nemlineáris regresszió
Ha a lineáris közelítés nem megfelelő nem lineáris regressziót kell alkalmazni. Megjegyzések: Elvileg bármelyik függvényt alkalmazhatjuk Lehetnek változóiban vagy paramétereiben nem lineáris modellek Csak változóiban nem lineáris modellek visszavezethetők lineárisra Kezelésük, értelmezésük nehezebb

3
Gyakori nemlineáris regressziós függvények sematikus alakjai
Nem monoton függvény Y Y Y X X X jövedelem és az élelmiszerek fogyasztása minőség és a termék ár műtrágya felhasználás és a termésátlag

4
Nemlineáris regresszió
Nemlineáris modellek kezelése: a modell linearizálása tranzformációval, eredeti nemlineáris modell alkalmazása (számítástechnikai eszközök jelentősége, Statisztikai programok alkalmazása).
.")
5
Nemlineáris regresszió
Exponenciális regresszió alapfüggvénye: mind változójában, mind paramétereiben nemlineáris (inkább trendfüggvényként alkalmazzák). Ha egy ν multiplikatív maradékváltozót feltételezünk (1 körül ingadozik) , akkor az egyenlet mindkét oldal logaritmálása után a következő ez az egyszeresen logaritmikus vagy féllogaritmikus függvény. A β1 az x növekedéséhez kapcsolódó átlagos y növekedést jelenti (ekvidisztáns x változó esetén ad jól értelmezhető eredményt). A β0 az x=0 értéknél az y várható értékét mutatja.
. Ha egy ν multiplikatív maradékváltozót feltételezünk (1 körül ingadozik) , akkor az. egyenlet mindkét oldal logaritmálása után a következő. ez az egyszeresen logaritmikus vagy féllogaritmikus függvény. A β1 az x növekedéséhez kapcsolódó átlagos y növekedést jelenti (ekvidisztáns x változó esetén ad jól értelmezhető eredményt). A β0 az x=0 értéknél az y várható értékét mutatja.")
6
Nemlineáris regresszió
Hatványkitevős regresszió függvénye: gyakrabban alkalmazzák, mint az előzőt, mind változójában, mind paramétereiben nemlineáris, logaritmálás után lineáris alakra hozható: mindkét változónak vettük a logaritmusát kettős logaritmikus (double logarithmic) függvény
 függvény.")
7
Nemlineáris regresszió
A becsült egyenletre felírjuk az elaszticitás függvényt: Ez azt mutatja, hogy ennél a függvénynél az elaszticitás állandó és megegyezik a kitevőben szereplő paraméterrel. Ez azt jelenti, hogy a magyarázó változó 1 %-kal nagyobb értékéhez százalékos azonos irányú elmozdulás tartozik a becsült eredményváltozóban. konstans elaszticitású függvény A paraméter jelentése: az x=1 helyen mutatja az eredményváltozó értékét.

8
Tanulásban töltött idő (év)
Képzettség és bér kapcsolata– hatványkitevős regresszió linearizálással Sorszám Tanulásban töltött idő (év) Havi kereset (y) (Ft) ln y ln x 1 19 167500 12,03 2,94 2 12 92260 11,43 2,48 3 93700 11,45 4 16 172200 12,06 2,77 5 188600 12,15 6 59900 11,00 7 15 101500 11,53 2,71 8 96000 11,47 9 81380 11,31 10 75400 11,23 11 17 82300 11,32 2,83 117000 11,67 13 160020 11,98 14 73150 11,20 83700 11,33
 Havi kereset (y) (Ft) ln y. ln x ,03. 2, ,43. 2, , ,06. 2, , , ,53. 2, , , , ,32. 2, , , , ,33.")
9
Nemlineáris regresszió
Mindkét változó logaritmusát képezzük, majd ezekre lineáris regressziót illesztünk. ebből az eredeti hatványkitevős forma: A becsült egyenlet: A tanulással töltött évek 1 %-os növekedése 1,47%-kal nagyobb keresetet okoz. A β0 paramétert nem értelmezzük.

10
Az oktatásban töltött évek és a havi bér kapcsolata

11
Nemlineáris regresszió
Ha nem linearizáljuk a függvényt akkor más eredményt kapunk. SPSS-ben megoldva: A két függvény azonos x-ek esetén közeli eredményeket ad: x=12-nél x=16-nál

12
(USD, vásárlóerőparitáson) Internet kapcsolat (y) (tízezer lakosra)
Ország GDP/fő (x) (USD, vásárlóerőparitáson) Internet kapcsolat (y) (tízezer lakosra) ln x ln y Ausztria 29591 713 10,30 6,57 Belgium 28484 203 10,26 5,31 Bulgária 7274 67 8,89 4,20 Csehország 16124 274 9,69 5,61 Franciaország 27866 401 10,24 5,99 Görögország 19631 170 9,88 5,14 Horvátország 10492 68 9,26 4,22 Írország 33801 395 10,43 5,98 Lengyelország 11461 204 9,35 5,32 Lettország 9683 179 9,18 5,19 Litvánia 11036 9,31 Magyarország 14629 358 9,59 5,88 Nagy-Britannia 29080 545 10,28 6,30 Németország 26396 315 10,18 5,75 Olaszország 26170 114 10,17 4,74 Portugália 18321 220 9,82 5,39 Románia 6974 23 8,85 3,14 Spanyolország 23264 222 10,05 5,40 Szlovákia 13005 212 9,47 5,36 Szlovénia 19618 215 5,37
 (USD, vásárlóerőparitáson) Internet kapcsolat (y) (tízezer lakosra) ln x. ln y. Ausztria ,30. 6,57. Belgium ,26. 5,31. Bulgária ,89. 4,20. Csehország ,69. 5,61. Franciaország ,24. 5,99. Görögország ,88. 5,14. Horvátország ,26. 4,22. Írország ,43. 5,98. Lengyelország ,35. 5,32. Lettország ,18. 5,19. Litvánia ,31. Magyarország ,59. 5,88. Nagy-Britannia ,28. 6,30. Németország ,18. 5,75. Olaszország ,17. 4,74. Portugália ,82. 5,39. Románia ,85. 3,14. Spanyolország ,05. 5,40. Szlovákia ,47. 5,36. Szlovénia ,37.")
13
Nemlineáris regresszió
Az egyes országok gazdasági fejlettsége és az internet elterjedése közötti kapcsolatot vizsgáljuk 2003-ban. A linearizált alakból történt becslés eredménye: Ha az egy főre jutó GDP 1 %-kal magasabb akkor ez 1,16 %-kal növeli az internettel rendelkező háztartások arányát. SPSS-szel megoldva: a rugalmassági paraméter lassuló növekedést mutat, mivel 1-nél kisebb értékű. Az ellentétes eredmény miatt szakmailag kell eldöntenünk melyik a jobb !!! (a lineáris regresszió elemzés is felmerülhet) az első függvény, mivel gyorsuló ütemben növeli az internet használatot ?
 az első függvény, mivel gyorsuló ütemben növeli az internet használatot.")
14
A gazdasági fejlettség és az internet kapcsolata

15
Nemlineáris regresszió
A polinomiális regresszió függvény: csak a változókban nemlineáris. A hatványokat előre kitudjuk számítani, így többváltozós lineáris regresszióvá alakítható x=x1, x2=x2, xl=xl ; a maradékváltozóval együtt a következő alakban írható fel: Előny: Az eddigi nemlineáris függvények közül a polinom adja a legkényelmesebben használható függvényformát. Hátrány: Nehéz tárgyi értelmet adni a nemlineáris tagoknak és együtthatóiknak (négyzetes, köbös stb.). Fokszám növelés!!!!!!!!
. Fokszám növelés!!!!!!!!")
16
Nemlineáris regresszió
Nemlineáris esetekben a kapcsolat szorosságának mérésére a korrelációs indexet (0 - 1) használjuk: Az I mutató analóg a lineáris esetben a determinációs együtthatóból vont négyzetgyökkel. Ha az illeszkedés jó 1-hez közeli az értéke Ha rossz az illeszkedés alacsony az értéke (a maradék négyzetösszeg viszonylag nagy). Nem mutatja meg a kapcsolat irányát!!!!! Lineáris esetben megegyezik az előjel nélküli lineáris korrelációs együtthatóval.
 használjuk: Az I mutató analóg a lineáris esetben a determinációs együtthatóból vont négyzetgyökkel. Ha az illeszkedés jó 1-hez közeli az értéke. Ha rossz az illeszkedés alacsony az értéke (a maradék négyzetösszeg viszonylag nagy). Nem mutatja meg a kapcsolat irányát!!!!! Lineáris esetben megegyezik az előjel nélküli lineáris korrelációs együtthatóval.")
17
Nemlineáris regresszió
Egy 1996-os vizsgálat a gazdasági fejlettség és a városi népesség aránya közötti összefüggést vizsgálta.

18
Ország Arány (y) (%) GDP/fő (x) (USD/fő) Banglades 16 202 Barbados 45 6950 Burkina Faso 15 357 Közép-afrikai Köztársaság 47 457 Csehország 56 7311 Etiópia 12 122 Finnország 60 15877 Grúzia 4500 Hong Kong 94 14641 India 26 275 Irán 57 1500 Libanon 84 1429 Líbia 82 5910 Litvánia 69 6710 Malajzia 43 2995 Észak-Korea 1000 Hollandia 89 17245

19
Gazdasági fejlettség és a városi népesség aránya

20
Nemlineáris regresszió
A polinomiális (kvadratikus) regressziófüggvény egyenlete: a legfejlettebb országokban már megfordul az arány. A függvény az x=15250 USD/fő pontban éri el a maximumát (a gazdagok kiköltöznek a városokból). A regresszió pontosságát jellemezve a négyzetösszegek így a korrelációs index: közepesnél alig valamivel erősebb a kapcsolat. (másik mintavétel??)
 regressziófüggvény egyenlete: a legfejlettebb országokban már megfordul az arány. A függvény az x=15250 USD/fő pontban éri el a maximumát (a gazdagok kiköltöznek a városokból). A regresszió pontosságát jellemezve a négyzetösszegek. így a korrelációs index: közepesnél alig valamivel erősebb a kapcsolat. (másik mintavétel )")
21
Nemlineáris regresszió
A nemlineáris modelleknél is előfordulhat, hogy egyetlen magyarázó változóval nem írható le a jelenség. A többváltozós esetekben is a leggyakoribb a hatványkitevős (kettős logaritmikus alak): A ν multiplikatív maradékváltozó 1 körül ingadozik. A függvény paramétereinek becslése a legkisebb négyzetek módszerével történik, eredeti formájában nemlineáris szélsőérték-számítással, vagy linearizált alakban a normálegyenlet-rendszer megoldásával. Statisztikai programcsomagok felhasználása A makrogazdasági elemzésekben termelési függvényekként alkalmazzák ezeket.
: A ν multiplikatív maradékváltozó 1 körül ingadozik. A függvény paramétereinek becslése a legkisebb négyzetek módszerével történik, eredeti formájában nemlineáris szélsőérték-számítással, vagy linearizált alakban a normálegyenlet-rendszer megoldásával. Statisztikai programcsomagok felhasználása. A makrogazdasági elemzésekben termelési függvényekként alkalmazzák ezeket.")
22
Nemlineáris regresszió
Ennek a függvénynek is sajátja az állandó (parciális) rugalmasság azaz az eredményváltozónak a j-edik magyarázó változó szerinti parciális rugalmassága állandó:
 rugalmasság azaz az eredményváltozónak a j-edik magyarázó változó szerinti parciális rugalmassága állandó:")
23
Standard lineáris modell (SLM)feltételrendszere
A regresszióban használt adatok minták vagy teljes körű sokasági megfigyelések lehetnek. A számítógépes programok eleve valószínűségi (mintavételi) hátteret feltételeznek a regressziós modellekben. A standard lineáris modell (SLM) feltételrendszere: F1: A magyarázó változók nem valószínűségi változók, hanem a különböző mintákon állandónak tekinthetők. F2: A magyarázó változók megfigyelt értékei lineárisan független rendszert alkotnak. F3: Az eredményváltozó feltételes (adott X-ek esetén feltételezett) várható értéke lineáris függvénye a magyarázó változóknak:
 hátteret feltételeznek a regressziós modellekben. A standard lineáris modell (SLM) feltételrendszere: F1: A magyarázó változók nem valószínűségi változók, hanem a különböző mintákon állandónak tekinthetők. F2: A magyarázó változók megfigyelt értékei lineárisan független rendszert alkotnak. F3: Az eredményváltozó feltételes (adott X-ek esetén feltételezett) várható értéke lineáris függvénye a magyarázó változóknak:")
24
Standard lineáris modell (SLM)feltételrendszere
A standard lineáris modell (SLM) feltételrendszere (folytatás): F4: A regressziós maradékot kifejező változó (maradékváltozó) feltételes eloszlása normális, 0 várható értékkel és állandó varianciával, azaz F5: A maradékváltozó különböző X-ekhez tartozó értékei korrelálatlanok:
 feltételrendszere (folytatás): F4: A regressziós maradékot kifejező változó (maradékváltozó) feltételes eloszlása normális, 0 várható értékkel és állandó varianciával, azaz. F5: A maradékváltozó különböző X-ekhez tartozó értékei korrelálatlanok:")
25
Standard lineáris modell (SLM) feltételrendszerének magyarázata
F1: A magyarázó változók nem valószínűségi változók, hanem a különböző mintákon állandónak tekinthetők. Kontrolált kísérlet Sztochasztikus magyarázó változójú kísérlet árpa termésátlag, műtrágya, szántás mélység előre rögzített véletlenszerű kiválasztás mennyiség és mélység eltérő mennyiség és mélység F2: A magyarázó változók megfigyelt értékei lineárisan független rendszert alkotnak. Ha lineáris kapcsolat van a függvény paraméterei nem határozhatók meg (nem becsülhetők) egyértelműen, parciális paramétereik nem számíthatók. F3: Az eredményváltozó feltételes (adott X-ek esetén feltételezett) várható értéke lineáris függvénye a magyarázó változóknak. A változók között lineáris kapcsolat van.
 egyértelműen, parciális paramétereik nem számíthatók. F3: Az eredményváltozó feltételes (adott X-ek esetén feltételezett) várható értéke lineáris függvénye a magyarázó változóknak. A változók között lineáris kapcsolat van.")
26
Standard lineáris modell (SLM) feltételrendszerének magyarázata
F4: A regressziós maradékot kifejező változó (maradékváltozó) feltételes eloszlása normális A maradékváltozó általában több, a modellben nem specifikált tényező hatásának eredője, ezért közelítőleg normális eloszlást (hibaeloszlást) követ. F5: A maradékváltozó különböző X-ekhez tartozó értékei korrelálatlanok Az X különböző értékeihez tartozó maradékváltozók függetlenek legyenek. A gyakorlatban a feltételek tisztán ritkán teljesülnek!!
 feltételes eloszlása normális. A maradékváltozó általában több, a modellben nem specifikált tényező hatásának eredője, ezért közelítőleg normális eloszlást (hibaeloszlást) követ. F5: A maradékváltozó különböző X-ekhez tartozó értékei korrelálatlanok. Az X különböző értékeihez tartozó maradékváltozók függetlenek legyenek. A gyakorlatban a feltételek tisztán ritkán teljesülnek!!")
27
Becslések a standard lineáris modellben
Az első lépés a β paraméterek (pont)becslése, amit számítógéppel végzünk. A pontbecslések torzítatlanok és konzisztensek. A második lépésben becsülni lehet a függvényértékeket: , majd ezek segítségével a reziduumok vektorát: . A harmadik lépésben a reziduális variancia becslése következik: de ez torzított.
becslése, amit számítógéppel végzünk. A pontbecslések torzítatlanok és konzisztensek. A második lépésben becsülni lehet a függvényértékeket: , majd ezek segítségével a reziduumok vektorát: . A harmadik lépésben a reziduális variancia becslése következik: de ez torzított.")
28
Becslések a standard lineáris modellben
Ezért helyette a torzítatlan becslőfüggvényt, a korrigált reziduális varianciát használjuk: Kétváltozós esetben a kapható. A becsült paraméterek varianciája (standard hibája) miatt számítanunk kell a paraméterek kovarianciamátrixát is. Elméleti értéke
 miatt számítanunk kell a paraméterek kovarianciamátrixát is. Elméleti értéke.")
29
Becslések a standard lineáris modellben
Becsült értéke a magyarázóváltozók megfigyeléseiből, valamint a variancia se2 becsléseiből előállítható, és a számítógépes csomagok kiszámítják. A j-edik főátló elem a j-edik regressziós paraméter varianciája. Így a paraméterbecslés standard hibája: A j-edik becsült együttható eloszlása normális, a következő paraméterekkel: A becsült varianciát illetve standard hibát felhasználva:

30
Becslések a standard lineáris modellben
Ez azt jelenti, hogy az SLM feltételeinek fennállásakor a becsült paraméterek egyszerű transzformáltja Student-féle t-eloszlást követ. Az 1-α megbízhatóságú konfidenciaintervallum a j-edik regressziós együtthatóra: kétváltozós esetben a szf=n-2. Az együtthatók intervallumánál fontosabb a függvényértékek intervallumának becslése. Az intervallum közepének pontbecslésekor egy x1*, x2*,…, xk*=x*T helyen keressük a becsült függvényértéket, akkor az

31
Becslések a standard lineáris modellben
torzítatlanul becsli a sokasági függvényértéket, azaz . Az intervallumbecsléshez elő kell állítani varianciáját, illetve a standard hibáját. Kétváltozós esetben: többváltozós esetben: A konfidenciaintervallum: minimális, ha:

32
Megadja azokat a határokat amelyek az esetek (1-α)
Megadja azokat a határokat amelyek az esetek (1-α)* 100 %-ában lefedik az elméleti regressziós függvény x* ponthoz tartozó értékét.
* 100 %-ában lefedik az elméleti regressziós függvény x* ponthoz tartozó értékét.")
33
Hipotézisvizsgálat a standard lineáris modellben
A hipotézisvizsgálatot a regresszióban két területen használjuk: A paraméterek ill. a modell megfelelő-e? A kiinduló feltételek teljesülnek-e? A 2.-at kellene előbb, de ez nem lehetséges csak az 1. után!!!!! A hipotézisvizsgálat többletet ad a leíró elemzéshez képest. Most a paraméterek és az egész modell tesztelését vizsgáljuk.

34
A paraméterek szeparált tesztelése
A paraméterek szeparált tesztelésekor a nullhipotézisünk az, hogy a j-edik sokasági paraméter értéke 0, ellenhipotézisünk pedig, hogy nem az: A nullhipotézis azt jelenti, hogy a j-edik magyarázó változó regressziós együtthatója 0, azaz a j-edik változó tetszőleges elmozdulása nem befolyásolja az eredményváltozót.

35
A paraméterek szeparált tesztelése
A próbafüggvény a nullhipotézis alatt (fennállása esetén): A regressziós együtthatók szeparált tesztelésére alkalmazott t-próba elvégzéséhez el kell készíteni a j-edik paraméter becslését, meg kell határozni a becsült standard hibát, és a kettő hányadosát kell képezni. Ha az empirikus t-érték abszolút értékben kicsi (az elméleti értéknél kisebb), akkor a nullhipotézis nem utasítható el, ellenkező esetben a nullhipotézist elvetjük, és a j-edik változót adott α szinten fontos (szignifikáns) magyarázó változónak tekintjük.
: A regressziós együtthatók szeparált tesztelésére alkalmazott t-próba elvégzéséhez el kell készíteni a j-edik paraméter becslését, meg kell határozni a becsült standard hibát, és a kettő hányadosát kell képezni. Ha az empirikus t-érték abszolút értékben kicsi (az elméleti értéknél kisebb), akkor a nullhipotézis nem utasítható el, ellenkező esetben a nullhipotézist elvetjük, és a j-edik változót adott α szinten fontos (szignifikáns) magyarázó változónak tekintjük.")
36
A paraméterek szeparált tesztelése
Ezt a próbát regressziós t-próbának vagy parciális t-próbának nevezzük. Minden paraméterre el kell végezni külön-külön a próbát. Így képet kapunk arról, hogy az egyes változók lényeges mértékben járulnak-e hozzá az eredményváltozó magyarázatához. A próba alkalmazható akkor is, ha nem a , hanem valami más, nullhipotézist akarunk vizsgálni. Ekkor -t írunk a baloldalra. A konstansra általában nem végezzük el a próbát, de megtartjuk a modellben.

37
A modell egészének tesztelése
Azt vizsgáljuk, hogy a magyarázó változók összességükben kielégítően magyarázzák-e az eredményváltozót. Ezt a varianciaanalízissel teszteljük. A magyarázó változók sokasági együtthatói mind 0-k, azaz Ellenhipotézisünk az, hogy létezik legalább egy olyan együttható, amely sokasági szinten nem nulla, azaz

38
A modell egészének tesztelése
A nullhipotézis itt azt jelenti, hogy a modellünk egészében rossz, míg az ellenhipotézis azt mondja ki, hogy van legalább egy változó a modellben, amit érdemes megtartani, tehát a modellt nem lehet (nem kell) eleve elutasítani. Ezért a varianciaanalízis logikailag megelőzi a parciális t-próbát, mivel ha megállapítjuk hogy rossz a modell nem kell a paramétereket elemezni. A varianciaanalízis próbája a globális F-próba: Ha a számított érték nagyobb vagy egyenlő, mint a táblázatban lévő érték akkor az adott α szignifikanciaszinten a modell nem utasítható el, azaz legalább egy lényeges kapcsolatot megragad.
 eleve elutasítani. Ezért a varianciaanalízis logikailag megelőzi a parciális t-próbát, mivel ha megállapítjuk hogy rossz a modell nem kell a paramétereket elemezni. A varianciaanalízis próbája a globális F-próba: Ha a számított érték nagyobb vagy egyenlő, mint a táblázatban lévő érték akkor az adott α szignifikanciaszinten a modell nem utasítható el, azaz legalább egy lényeges kapcsolatot megragad.")
39
Illeszkedés tesztjének is felfogható (goodness of fit), nagy R2 esetén utasítja el a nullhipotézist
, nagy R2 esetén utasítja el a nullhipotézist")
41
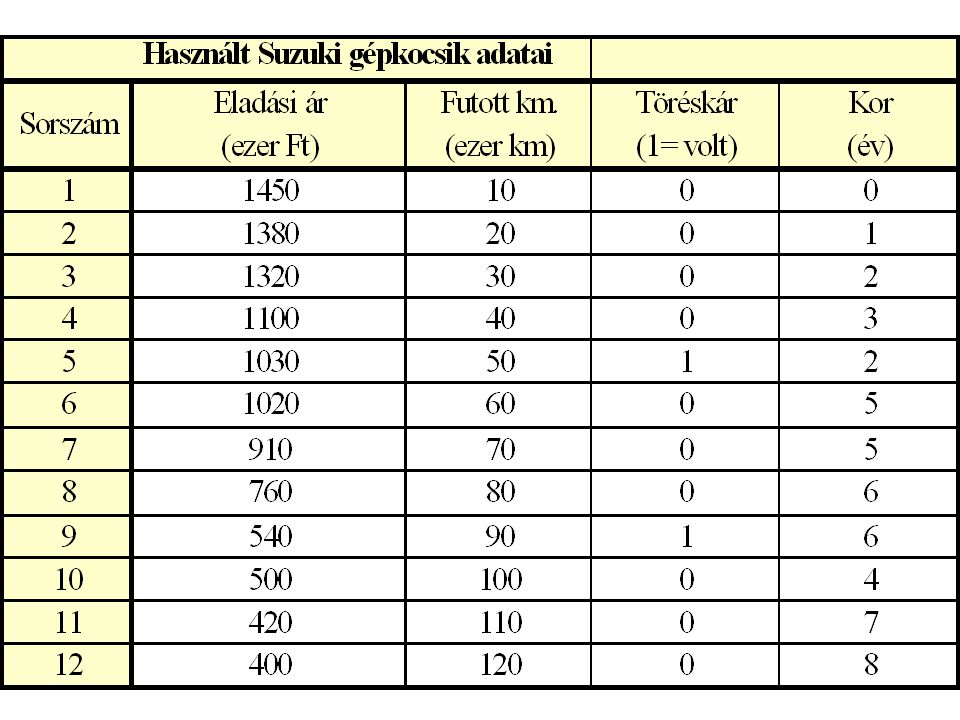
A modell egészének tesztelése
A modell egészének tesztelését a varianciaanalízis F-próbájával végezzük. A p-érték (empirikus szignifikanciaszint) igen kicsi, ezért azt mondhatjuk, hogy a modell elfogadható (magyarázza a gépkocsi árakat). Ha az egyes változókat is vizsgáljuk: 5%-os szinten a t0,975(9)=2,26 a második magyarázó változó (dummy) értéke kisebb a kritikus értéknél. 10%-os szinten a t0,95(9)=1,86 miatt már elfogadható a teljes modell.
 igen kicsi, ezért azt mondhatjuk, hogy a modell elfogadható (magyarázza a gépkocsi árakat). Ha az egyes változókat is vizsgáljuk: 5%-os szinten a t0,975(9)=2,26 a második magyarázó változó (dummy) értéke kisebb a kritikus értéknél. 10%-os szinten a t0,95(9)=1,86 miatt már elfogadható a teljes modell.")
Hasonló előadás