Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Többváltozós standard lineáris regresszió.
A regresszió számítás lényege az, hogy egy sokaság két vagy több ismérve közt sztochasztikus kapcsolatot tételezünk fel, és ezt a kapcsolatot szeretnénk leírni. A regresszió számítás során feltételezzük, hogy eredményváltozónk (Y) sztochasztikus kapcsolatban áll a magyarázó változókkal (X). Általános képlet: k számú magyarázó változó (X), egy eredményváltozó (Y) és egy maradékváltozó van.
 sztochasztikus kapcsolatban áll a magyarázó változókkal (X). Általános képlet: k számú magyarázó változó (X), egy eredményváltozó (Y) és egy maradékváltozó van.")
2
A regressziós elemzés során a változók közötti összefüggéseket kifejező regressziós függvényt egy mintából határozzuk meg. A mintából becslést adunk a függvény paramétereire, azaz görbeillesztési feladatot oldunk meg. A paraméterek kiszámításához a legkisebb négyzetek módszerét használjuk fel. A , paramétereket parciális regressziós együtthatóknak nevezzük. Jelentésük: az adott magyarázó változó (x1, x xm) változása mekkora változást eredményez az eredmény-változóban (y), ha a többi magyarázó változó nem változik
 változása mekkora változást eredményez az eredmény-változóban (y), ha a többi magyarázó változó nem változik.")
3
Három változós regressziós modell esetén a β szerinti deriválás eredményeként a következő normálegyenleteket kapjuk.

4
A változók transzformálásával az egyenletek megoldására egyszerűbb lehetőség adódik.
Az átlagtól való eltérések összege nulla, azaz Σd1i=0; Σd2i=0; Σdyi=0. Ezeket az aggregátumokat elhagyva a normálegyenletekből a következő két két-ismeretlenes normálegyenlethez jutunk:

5
Példa. Regressziós modell segítségével, 10 tapasztalati megfigyelés alapján kívánjuk vizsgálni, hogy a szállítási távolság és a szállított tömeg milyen mértékben befolyásolja a szállítás időtartamát. Szállítási idő (perc) Távolság (km) Tömeg (t) yi x1i x2i 1. 10 4 2. 13 5 3. 8 2 4. 20 5. 27 19 6. 35 7 7. 22 16 6 8. 40 9. 45 25 9 10. 50 30 270 150 60
 Távolság (km) Tömeg (t) yi. x1i. x2i")
6
yi x1i x2i Első lépés: a transzformáció: Szállítási idő (perc)
Távolság (km) Tömeg (t) yi x1i x2i 10 4 -17 -11 -2 13 5 -14 -1 8 2 -19 -13 -4 20 -7 -5 27 19 35 7 1 22 16 6 40 45 25 9 18 3 50 30 23 15 270 150 60
 Tömeg (t) yi. x1i. x2i")
7
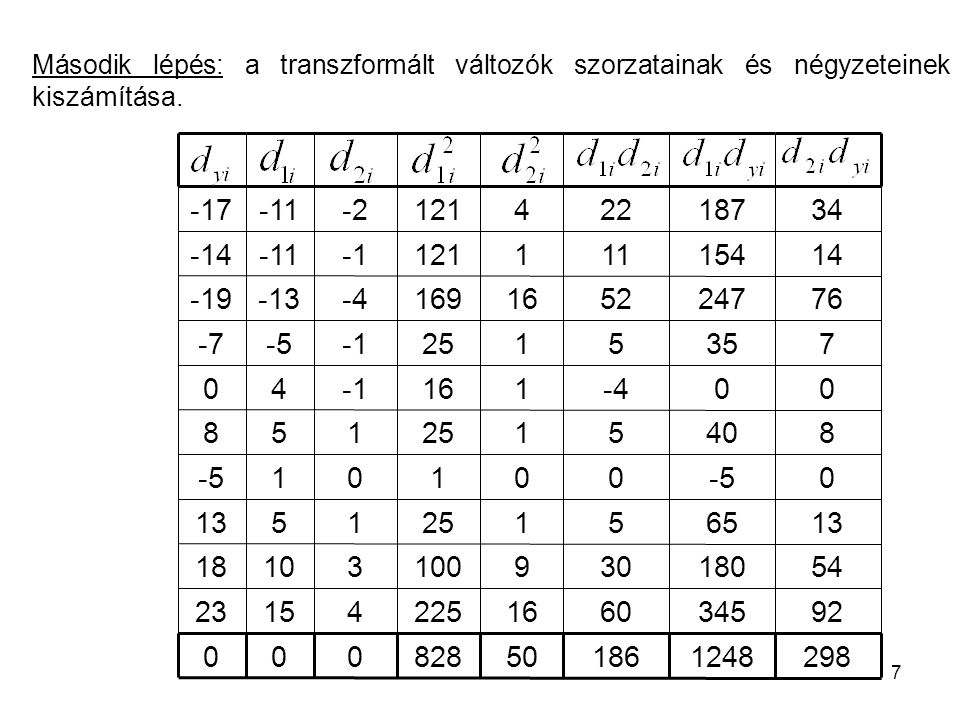
Második lépés: a transzformált változók szorzatainak és négyzeteinek kiszámítása.
298 1248 186 50 828 92 345 60 16 225 4 15 23 54 180 30 9 100 3 10 18 13 65 5 1 25 -5 8 40 -4 -1 7 35 -7 76 247 52 169 -13 -19 14 154 11 121 -11 -14 34 187 22 -2 -17
8
Harmadik lépés: a β paraméterek kiszámítása.
1248 = 828β β2 298 = 186β1 + 50β2 / * 3,72 1108,56 = 691,92β1 +186β2 139,44 = 136,08 β1 β1 = 1,025

9
A β1 értékét behelyettesítve az 1. egyenletbe:
1248 = 828*1, β2 β2 = 399,3 / 186 = 2,148 β0 kiszámítása az első (eredeti) normálegyenletből: β0 = 27 – (1,025*15) – (2,148*6) = - 1,263
 normálegyenletből: β0 = 27 – (1,025*15) – (2,148*6) = - 1,263.")
10
A regressziós függvény:
A parciális regressziós együtthatók értelmezése: β1 a szállítási távolság 1 km-es növekedése 1,025 perccel növeli a szállítási időt. Azonos szállítási tömeg mellett. β2 a szállított tömeg 1 tonnával való növelése 2,148 perccel növeli a szállítási időt. Azonos szállítási távolság mellett.

11
Többváltozós korreláció számítás.
A többváltozós kapcsolatok vizsgálatakor a lineáris korrelációs együtthatót a változók összes lehetséges párosításában ki tudjuk számítani: páronkénti korrelációs együtthatók. Az y és x1 közötti korrelációs együttható kiszámítása korrelációs együttható

12
A regresszió példából az összesen sor:
2006 298 1248 186 50 828

13
A páronkénti korrelációs együtthatók a többi változón keresztül gyakorolt közvetett hatást is kimutatják. Ha ezt ki akarjuk szűrni, akkor parciális korrelációs együtthatót számítunk, a páronkénti korrelációs együtthatókat felhasználva. Például az y és az x1 közötti közvetlen kapcsolatra (a pont után a kizárt változó) számított parciális korrelációs együttható:
 számított parciális korrelációs együttható:")
14
A páronkénti korrelációs együtthatók korrelációs mátrixba rendezhetők.
Háromváltozós korreláció esetén: (238) Az előzőekben kiszámított korrelációs együtthatókból:
 Az előzőekben kiszámított korrelációs együtthatókból:")
15
A korrelációs mátrix inverzéből is kiszámítható a parciális korrelációs együttható:
A korrelációs mátrix inverze. (240)
")
16
Az előzőekben kiszámított R mátrix inverze:
Értelmezés: a szállítási idő (y) és a távolság (x1) között a közepesnél erősebb pozitív irányú kapcsolat van, ha a szállított tömeg (x2) azonos.
 és a távolság (x1) között a közepesnél erősebb pozitív irányú kapcsolat van, ha a szállított tömeg (x2) azonos.")
17
Az összes magyarázó változó együttes hatását méri a többszörös determinációs együttható.
Az eredményváltozó szórásnégyzetéből mekkora hányad tulajdonítható a magyarázó változók szórásának. A páronkénti korrelációs együtthatók a korrelációs mátrixból:

18
A korrelációs mátrix inverzéből számítva a többszörös determinációs együttható képlete:
(241) Értelmezés: a szállítási idő varianciájának 95,7%-át a távolság és a szállított tömeg nagyságának szórása magyarázza.
 Értelmezés: a szállítási idő varianciájának 95,7%-át a távolság és a szállított tömeg nagyságának szórása magyarázza.")
19
A regressziós modell illeszkedésének a vizsgálata variancia analízissel. (Globális F-próba.)
A teljes eltérés-négyzetösszeget a megfigyeléseknek az átlagtól való eltérése adja, (SST) A belső eltérés-négyzetösszeg a megfigyeléseknek a regressziós egyenestől vett eltéréseiből számított négyzetösszeg, (SSE) A külső eltérés-négyzetösszeget a regressziós egyenes pontjainak az átlagtól vett eltérése határozza meg (SSR). Ha a megfigyelések közel vannak a regressziós egyeneshez, akkor a belső eltérés-négyzetösszeg kicsi, és a teljes eltérés- négyzetösszeget jórészt a „külső tényező”, azaz a regresszió magyarázza. Ha a megfigyelések eltérnek a regressziós egyenestől, akkor a belső eltérés-négyzetösszeg nagy lesz, a külső viszonylag kevesebbet magyaráz.
 A belső eltérés-négyzetösszeg a megfigyeléseknek a regressziós egyenestől vett eltéréseiből számított négyzetösszeg, (SSE) A külső eltérés-négyzetösszeget a regressziós egyenes pontjainak az átlagtól vett eltérése határozza meg (SSR). Ha a megfigyelések közel vannak a regressziós egyeneshez, akkor a belső eltérés-négyzetösszeg kicsi, és a teljes eltérés- négyzetösszeget jórészt a „külső tényező , azaz a regresszió magyarázza. Ha a megfigyelések eltérnek a regressziós egyenestől, akkor a belső eltérés-négyzetösszeg nagy lesz, a külső viszonylag kevesebbet magyaráz.")
20
a teljes eltérés-négyzetösszeg
a teljes eltérés-négyzetösszegből a regressziós függvény által magyarázott rész a teljes eltérés-négyzetösszegből a hibataggal magyarázott rész A modell illeszkedése az SSR arányának nagyságával tesztelhető. A nagyobb arány jobb illeszkedést jelent.

21
Próbafüggvény: (234) Az F próbafüggvény lényegében azt vizsgálja, hogy az eredményváltozó szórásnégyzetéből szignifikánsan nagy hányadot magyaráz-e meg a regresszió függvény. Null-hipotézis: a regresszió tagadása (nem jó a függvény); mindegyik parciális regressziós együttható (β) értéke 0. Alternatív hipotézis: van legalább egy szignifikáns regressziós együttható; (legalább egy együttható nem nulla ).
; mindegyik parciális regressziós együttható (β) értéke 0. Alternatív hipotézis: van legalább egy szignifikáns regressziós együttható; (legalább egy együttható nem nulla ).")
22
A számított F értéket összehasonlítjuk a választott szignifikancia-szinthez tartozó kritikus F értékkel. Ha a számított érték nem haladja meg a kritikus értéket, akkor a null-hipotézist elfogadjuk, ami azt jelenti, hogy elfogadjuk a regresszió tagadását, azaz a regressziós modell illeszkedése nem jó. Ellenkező esetben a null-hipotézist elutasítjuk, és az alternatív hipotézist fogadjuk el.

23
Vizsgáljuk meg az előzőekben kiszámított regresszió-függvény illeszkedését 5%-os szignifikancia szinten. 1. lépés: kiszámítjuk a függvény alapján az ŷ értékeket. 150 30 25 20 16 19 10 2 60 9 7 6 5 270,000 Összesen 50,967 10. 43,694 9. 34,273 8. 28,025 7. 6. 28,952 5. 19,727 4. 5,083 3. 4 X1i X2i 13,577 2. 11,429 1. ŷi Sorszám

24
ŷi (yi-ŷ)² yi-ŷ yi SSE SST
2. lépés: kiszámítjuk az eltérésnégyzeteket. 1,306 25 2006 87,037100 529 0,935089 324 1,705636 169 32,798529 36,300625 64 0,528529 3,810304 49 0,074529 361 8,508889 196 0,332929 289 2,042041 (yi-ŷ)² yi-ŷ Összesen 10. 9. 8. 7. 6. 5. 4. 3. 2. 1. Sorszám 270,000 50,967 50 43,694 45 34,273 40 28,025 22 35 28,952 27 19,727 20 5,083 8 13,577 13 11,429 ŷi yi 270 10 -1,429 -0,577 2,917 0,273 -1,952 0,727 -6,025 5,727 -0,967 0,000 SSE SST
². yi-ŷ. Összesen Sorszám. 270, , , , , , , , , ,429. ŷi. yi , ,577. 2,917. 0, ,952. 0, ,025. 5, ,967. 0,000. SSE. SST.")
25
SSE = ∑(yi - ŷ)² = 87 SSR = SST – SSE = 2006 – 87 = 1919 n = 10 = a minta elemszáma; m = 2 = a magyarázó változók száma szabadságfok: v1 = m = 2 v2 = n-m-1 = 7 A szignifikancia szint α = 0,05 Az F elméleti értéke a VI. táblázatból: 4,737 A tapasztalati érték nagyobb, mint az elméleti érték, tehát 5%-os szignifikancia szinten elvetjük a null-hipotézist, azaz van regressziós kapcsolat a szállítási idő, valamint a távolság és a szállított mennyiség között.

26
A regressziós modell használhatóságának feltételei:
1. A magyarázó változók legyenek lineárisan függetlenek. Ha nem, akkor multikollinearitás. 2. A tényadatok és a modell-adatok közötti különbségek, a hibatagok legyenek nulla várható értékű korrelálatlan valószínűségi változók. Ha nem, akkor autokorreláció. 3. A hibatagok szórásnégyzete legyen állandó. Ha nem, akkor heteroszkedaszticitás, mert a hibatag nagysága függ valamelyik változótól.

27
A multikollinearitás mérőszáma.
1. lépés: a többszörös determinációs együttható kiszámítása A szállítási példánk korrelációs mátrixa:

28
2. lépés: az M mutatószám kiszámítása a korrelációs mátrixból:
= 0,9568 – (0, ,0190) = 0,8663 Jelentése: Az eredményváltozó szórásnégyzetének azon része, melyet a magyarázóváltozók együttesen magyaráznak. A magas érték nagymértékű multikollinearitásra utal a magyarázó változók között.
 = 0,8663. Jelentése: Az eredményváltozó szórásnégyzetének azon része, melyet a magyarázóváltozók együttesen magyaráznak. A magas érték nagymértékű multikollinearitásra utal a magyarázó változók között.")
29
M = 0,9568 – [(0,9568 – 0,9409²) + (0,9568 – 0,9684²)] = = 0,9568 – (0,0715 + 0,0190) = 0,8663
A többszörös determinációs együttható a fentiek alapján az alábbi tényezőkre bontható: X1 magyarázó változó önálló hatása: 0,9568-0,9409² = ,0715 X2 magyarázó változó önálló hatása: 0,9568-0,9684² = ,0190 Együttes hatásuk (M) ,8663 Összesen ,9568
![M = 0,9568 – [(0,9568 – 0,9409²) + (0,9568 – 0,9684²)] = = 0,9568 – (0, ,0190) = 0,8663](http://slideplayer.hu/slide/2085715/8/images/29/M+%3D+0%2C9568+%E2%80%93+%5B%280%2C9568+%E2%80%93+0%2C9409%C2%B2%29+%2B+%280%2C9568+%E2%80%93+0%2C9684%C2%B2%29%5D+%3D+%3D+0%2C9568+%E2%80%93+%280%2C+%2C0190%29+%3D+0%2C8663.jpg "A többszörös determinációs együttható a fentiek alapján az alábbi tényezőkre bontható: X1 magyarázó változó önálló hatása: 0,9568-0,9409² = 0,0715. X2 magyarázó változó önálló hatása: 0,9568-0,9684² = 0,0190. Együttes hatásuk (M) 0,8663. Összesen 0,9568.")
30
Autokorreláció. Ha a tényadatok és a modell-adatok közötti különbségek, a hibatagok értékei és a közvetlenül előttük lévő értékek között korrelációs kapcsolat van, akkor elsőrendű autokorrelációról beszélünk. Az autókorreláció tesztelése a Durbin – Watson féle próbával történik. A kapcsolat szorosságát az autokorrelációs együttható („p”) fejezi ki. A „p” értéke „d” segítségével becsülhető: d = az autokorreláció próbafüggvénye
 fejezi ki. A „p értéke „d segítségével becsülhető: d = az autokorreláció próbafüggvénye.")
31
A null-hipotézis: nincs autokorreláció p = 0
Alternatív hipotézis: negatív autokorreláció (p<0) vagy pozitív autokorreláció (p>0). A próbafüggvény értékét (”d”) a mintából kiszámítva, a meghatározott szignifikancia szint mellett, az alábbi döntési tábla alapján tudunk dönteni az autókorrelációról. d > 4-dL d < 4-dU p < 0 d < dL d > dU p > 0 a null-hipotézist elvetjük elfogadjuk A „dU” és a „dL” értékek a VIII. és a IX. táblázatból olvashatók ki (m = a magyarázó változók száma; n= a megfigyelések száma). Ha a „d” értéke az alsó és a felső érték közé esik, akkor nem tudunk dönteni.
 vagy pozitív autokorreláció (p>0). A próbafüggvény értékét ( d ) a mintából kiszámítva, a meghatározott szignifikancia szint mellett, az alábbi döntési tábla alapján tudunk dönteni az autókorrelációról. d > 4-dL. d < 4-dU. p < 0. d < dL. d > dU. p > 0. a null-hipotézist. elvetjük. elfogadjuk. A „dU és a „dL értékek a VIII. és a IX. táblázatból olvashatók ki (m = a magyarázó változók száma; n= a megfigyelések száma). Ha a „d értéke az alsó és a felső érték közé esik, akkor nem tudunk dönteni.")
32
Vizsgáljuk meg az előzőekben kiszámított regresszió-függvényt, hogy 1%-os szignifikancia szinten van-e elsőrendű auto-korreláció. Null-hipotézis: nincs elsőrendű autokorreláció. 1. lépés: kiszámítjuk a függvény alapján az ŷ értékeket. 150 30 25 20 16 19 10 2 60 9 7 6 5 270,000 Összesen 50,967 10. 43,694 9. 34,273 8. 28,025 7. 6. 28,952 5. 19,727 4. 5,083 3. 4 X1i X2i 13,577 2. 11,429 1. ŷi Sorszám 32 32

33
2. lépés: kiszámítjuk a hibatagok értékeit.

34
3. lépés: a próbafüggvény értékének kiszámítása:
4. lépés: a „p” becslése:

35
6. lépés: a „dU” és a „dL” értékek meghatározása a IX. táblázatból.
5. lépés: az „m” és az „n” értékének megállapítása m(magyarázó változók)=2; n(minta elemszám)=10 6. lépés: a „dU” és a „dL” értékek meghatározása a IX. táblázatból. dU=1, dL=0,700 döntési tábla: d > 4-dL d < 4-dU p < 0 d < dL d > dU p > 0 a null-hipotézist elvetjük elfogadjuk mivel p < 0 az elfogadás feltétele: d < 4 — du=4-1,252=2,748 d=2,7628 nagyobb ennél az értéknél, tehát nem fogadjuk el a null-hipotézist.
=2; n(minta elemszám)= lépés: a „dU és a „dL értékek meghatározása a IX. táblázatból. dU=1,252 dL=0,700. döntési tábla: d > 4-dL. d < 4-dU. p < 0. d < dL. d > dU. p > 0. a null-hipotézist. elvetjük. elfogadjuk. mivel p < 0 az elfogadás feltétele: d < 4 — du=4-1,252=2,748. d=2,7628 nagyobb ennél az értéknél, tehát nem fogadjuk el a null-hipotézist.")
36
Autokorreláció tesztelése a következő adatok ismeretében:
Szignifikancia szint: 5%, tapasztalati adatok száma: 40, magyarázó változók: 3, A hibatagok összegei: A nullhipotézis: nincs autokorreláció

37
nem igaz, tehát nem fogadjuk el a nullhipotézist
d > 4-dL d < 4-dU p < 0 d < dL d > dU p > 0 a null-hipotézist elvetjük elfogadjuk döntési tábla: du értéke ha n = 40 és m = 3: ,659 2,75 < 4 — 1,659 2,75 < 2,341 nem igaz, tehát nem fogadjuk el a nullhipotézist az elvetés feltétele: d > 4 — dL dL értéke: 1,338 2,75 > 4 — 1, ,75 > 2,662 tehát elvetjük a nullhipotézist, azaz negatív autokorrelációt feltételezünk.

38
A heteroszkedaszticitás tesztelése
A hibatag nagysága függ valamelyik változótól, tehát azt kell vizsgálni, hogy milyen szoros a kapcsolat az egyes változók és a hibatagok abszolút értékei között. Kiszámítjuk 1.a függvényértékeket 2. a hibatagokat 3. a lineáris korrelációs együtthatókat 4. a próbafüggvényt

39
A heteroszkedaszticitás tesztelése ( függvényértékek, hibatagok)
")
40
A heteroszkedaszticitás tesztelése (lineáris korrelációs együtthatók)
")
41
A heteroszkedaszticitás tesztelése (a próbafüggvény)
A lineáris korrelációs együtthatók: Az x1 és az „e” között: 0,06847 Az x2 és az „e” között: -0,06986 Az ŷ és az „e” között: 0,02187 A legnagyobb abszolút értékűt teszteljük a próbafüggvénnyel. Null-hipotézis: r= 0, azaz nincs korreláció 5%-os szignifikancia szinten, v=8 esetén a III. táblázatból a t értéke: 2,3060. a tapasztalati érték az elfogadási tartományba esik. Elfogadjuk a null-hipotézist.

Hasonló előadás


>")
















