Előadást letölteni
Az előadás letöltése folymat van. Kérjük, várjon

1
Fájlszervezés, rekordhozzáférés

2
Számítógép szerepe Az adatbáziskezelés az a terület, amelyre a számítógépet talán leggyakrabban alkalmazzák. Két fogalom: Adatbázis (DB) Adatbáziskezelő rendszer (DBMS).
 Adatbáziskezelő rendszer (DBMS).")
3
Az adatbáziskezelés Adatbázis:
a valós világ egy részhalmazának leírásához használt adatok összefüggő, rendezett halmaza. Ma ezek többé kevésbé állandó formában egy számítógépben tárolódnak.

4
Az adatbáziskezelés Adatbáziskezelő rendszer: Szoftver,
egy vagy több felhasználó számára lehetővé teszi, ezen adatok olvasását vagy módosítását. Database management system.

5
DBMS felépítése és környezete
- Egyfajta változat -

6
DBMS felépítése és környezete

7
DBMS rendszer használatának két fázisa
Első fázis: Meg kell határozni az adatok majdani tárolásának logikai rendjét: ez a DB fogalmi váza (sémája). Második fázis: Az 1. fázis után van lehetőség a DB-t adatok tárolására használatba venni: Adatok feltöltése, Adatok különböző szempontok alapján történő visszakeresése.
. Második fázis: Az 1. fázis után van lehetőség a DB-t adatok tárolására használatba venni: Adatok feltöltése, Adatok különböző szempontok alapján történő visszakeresése.")
8
DBMS A DBMS-hez a következő műveletekkel lehet fordulhatni:
Sémaműveletek. Lekérdezések. Adatműveletek.

9
DBMS - Sémaműveletek Sémaműveletek:
a DB logikai vázának kialakítását, módosítását jelentik (a DDL igénybevételével).
.")
10
DBMS - lekérdezések Kérdéseket fogalmazunk meg a DB tartalmával kapcsolatban. Kétféle (bár nem teljesen független) változata.
 változata.")
11
DBMS felépítése és környezete

12
Lekérdezés Két módja: Egy személy speciális adatbázis lekérdező nyelven (QL) kérdéseket (pl. SQL) fogalmaz meg, melyeket egy interpreter azonnal értelmez és a DBMS válaszol rá. Alkalmazói programon keresztül feltett kérdésekkel nyerünk ki adatokat. Ez utóbbiesetben beszélhetünk gazdanyelvről (host language), mely egy, a DBMS-hez hívásokat intéző általános célú programozási nyelv.
 kérdéseket (pl. SQL) fogalmaz meg, melyeket egy interpreter azonnal értelmez és a DBMS válaszol rá. Alkalmazói programon keresztül feltett kérdésekkel nyerünk ki adatokat. Ez utóbbiesetben beszélhetünk gazdanyelvről (host language), mely egy, a DBMS-hez hívásokat intéző általános célú programozási nyelv.")
13
Lekérdezés A lekérdezés bármelyik esete:
Egy interpreter, egy lekérdezés feldolgozó alakítja a lekérdezéseket az DB menedzser által értelmezhető formába.

14
DBMS - Adatműveletek Az adatok beillesztését, törlését, módosítását célozzák - ezek a DML funkciói is egyben. Az adatműveletekben is érvényes a lekérdezéseknél megismert két változat.

15
1. fázis Az adatdefiníciós nyelv (DDL) támogatja:
segítségével megfogalmazhatjuk: milyen adatokat milyen formában fogunk az adatbázisban tárolni. A Séma fordító értelmezi a DB-nek ezt a logikai (fogalmi) leírását és külön lefordítja.
 leírását és külön lefordítja.")
16
2. fázis A DB használatát jelenti. Lefordított séma kell hozzá.
Van saját nyelve: Adatlekérdező és adatmanipluációs nyelv (DML). A DML és a DDL gyakran jelenik meg egységes nyelvként, mint pl. a szabványosított SQL nyelvekben.
. A DML és a DDL gyakran jelenik meg egységes nyelvként, mint pl. a szabványosított SQL nyelvekben.")
17
DB menedzser A DBMS központi része: DB menedzser, feladata:
Lefordított séma alapján kezeli a felhasználói lekérdezéseket A lefordított lekérdezéseket az állománykezelő (fájl menedzser) által értelmezhető parancsokká alakítja. Adatvédelem, adatbiztonság, integritás stb. feladatok ellátása.
 által értelmezhető parancsokká alakítja. Adatvédelem, adatbiztonság, integritás stb. feladatok ellátása.")
18
Állománykezelő Állománykezelő: File manager
Fizikai DB-hez való hozzáférést biztosítja. Általában szoros kapcsolat az opr. rendszerrel: Az állománykezelő egyszerűbb esetben része lehet az alkalmazott operációs rendszernek.

19
Adatbázis Adatbázis: Data Base. Csupán a fizikai adatbázis.

20
DBMS felépítése és környezete
- Másik változat -

21
DBMS leggyakoribb felépítése és környezete

22
A DBMS architektúra komponensei
Tárkezelő. "Lekérdezés" processzor (lekérdezés feldolgozó). Tranzakció-kezelő.
. Tranzakció-kezelő.")
23
Tárkezelő komponens Tárkezelő Részei: a diszkre ír és onnan olvas.
Fájl-kezelő. Puffer-kezelő.

24
Tárkezelő komponens File-kezelő:
a fizikai szintű I/O-ot végzi, ami az állomány nyilvántartására és elemeinek kezelésére szolgál. (DB-környezetben az adatvesztés veszélye miatt nem megengedett a "nem fizikai" írás/olvasás, így például a UNIX-ban használt lapozás, ami nem mindig jár konkrét I/O-tal. Vagyis a módosításokat azonnal rögzíteni kell!)
")
25
Tárkezelő komponens Puffer-kezelő :
ez a file-kezelő belső memóriás kiegészítése; elkülönülést tesz lehetővé az operációs rendszer tárkezelő mechanizmusaitól és kezeli az I/O számára rendelkezésre álló belső memóriát.

26
Tárkezelő komponens A blokk egy ütemben írható/olvasható terület.

27
"Lekérdezés" processzor (lekérdezés feldolgozó)
Magas szintű kérdések átalakítását végzi egyszerű utasítások sorozatára. A standard formában megfogalmazott kérdéseket lehetőséghez mérten átalakítja, majd a már végrehajtható utasításokkal a tárkezelő felé fordul.

28
"Lekérdezés" processzor (lekérdezés feldolgozó)
Azokra az Ügyfelekre vagyunk kíváncsiak az Ugyfel táblából, akikhez negatív egyenleg tartozik és a nemzetiség francia. SELECT nev From Ugyfel Where egyenleg < 0 AND nemzetiseg=‘francia’

29
"Lekérdezés" processzor (lekérdezés feldolgozó)
Lényeges a tábla elérési mechanizmusa is,ami lehet szekvenciális vagy indexelt, esetleg B-fával megoldott, stb.

30
Tranzakciókezelő komponens
Célja egyidejűleg több folyamat párhuzamos hozzáférését biztosítsa az adatbázishoz. Kulcsfogalma a tranzakció: utasítások egybetartozó sorozata, ami felfogható egy program-egységnek is. Alapvető követelmény a rendszerben a tranzakciók atomisága. A tranzakcióhoz tartozó utasítás-sorozat a "mindent vagy semmit" elven hajtódik végre, vagyis megszakíthatatlanul, oszthatatlanul. Vagy az összes, egy tranzakcióhoz tartozó utasítás lefut, vagy közülük egy sem.

31
Absztrakciós szintek Fizikai adatbázis: Fogalmi (logikai) adatbázis:
Fizikai adatbázison azt értjük, hogyan helyezkednek el az adatbázis adatai a fizikai tárolókon. Ide érthetjük a fizikailag megvalósított szerkezetet is. Fogalmi (logikai) adatbázis: Az a modell, ahogyan az adatbázis tükrözi a való világot. Azt határozza meg, hogy melyik adatot hogyan kell értelmezni. Nézet (view): Nézet az, amit a felhasználó az adatbázisból lát. Ha az adatbázisnak több felhasználási lehetősége van, ezek mindegyikéhez külön nézet tartozhat.
 adatbázis: Az a modell, ahogyan az adatbázis tükrözi a való világot. Azt határozza meg, hogy melyik adatot hogyan kell értelmezni. Nézet (view): Nézet az, amit a felhasználó az adatbázisból lát. Ha az adatbázisnak több felhasználási lehetősége van, ezek mindegyikéhez külön nézet tartozhat.")
32
"Lekérdezés" processzor (lekérdezés feldolgozó)
Lényeges a tábla elérési mechanizmusa is,ami lehet szekvenciális vagy indexelt, esetleg B-fával megoldott, stb.

33
Az adatbáziskezelők felépítése
Bonyolult szoftverrendszerek. Mérnöki gyakorlat: Rétegezési koncepció: az eredeti probléma több részre osztása, a felosztott részek egymásra épüljenek, egymással a részek minimális felületen keresztül érintkezzenek.

34
Az adatbáziskezelők 3 rétegű architektúrája

35
Legalsó réteg Legalsó réteg: Fizikai DB.
Itt valósul meg a DB adatainak fizikai tárolókon való elhelyezése. Ide tartoznak az adatstruktúrák, amelyekben a fizikai tárolást megvalósítjuk. Fogalmak: Kötet, állomány, blokk stb.

36
Középső réteg Fogalmi – logikai DB.
A valós világ egy darabjának leképezése. Egy modell, ahogy a DB tükrözi a valós világ egy részét. Meghatározza melyik adatot hogyan kell értelmezni. Pl. Rendeléskezelő DB-ben ide tartozik: Rendeles termek stb.

37
Legfelső réteg Az, amit és ahogy a felhasználó az adatbázisból lát.
Ha a DB-nek több felhasználási lehetősége van, ahhoz külön nézetek tartoznak. Pl. Neptun-rendszer Hallgatók Oktatók Tanulmányi stb.

38
Fizikai DB Az opr. rendszer a DB adatait állományokban, fájlokban tárolja. Az állományok blokkokból épülnek fel. Az opr. rendszer nyilvántartja: Az állományhoz mely blokkok tartoznak. A blokk egy ütemben írható/olvasható terület.: Abszolút cím: egyetlen fejmozgatással és I/O művelettel a blokk elérhető, az adatai az operatív tárba mozgathatók.

39
Fizikai DB Fizikai adatszervezés célja:
Az adatok háttértáron való tárolása, úgy hogy a kért adat a lehető legkevesebb blokkművelettel legyen elérhető. Blokkműveletek: Blokkírás Blokkolvasás.

40
Blokk szerkezete A blokkok tartalmazzák az adatrekordokat.
Egy blokk szerkezete: Header record1 record2 … recordN Szabad hely Pointerek Foglalt/szabad helyek

41
Blokkfejléc Blokkfejlécben tárolt információk:
Blokkbeli rekordok kezdőcímei Blokkbeli szabad hely kezdete Időbélyegzések (mikor módosították utoljára) Zárolási információk Lehet-e a blokkba még további sorokat tenni Mutató a túlcsordulási blokkra Mutatók további blokkokra (Az említett mutatókat az ábrákon általában a blokkok végére rajzoljuk.)
 Zárolási információk. Lehet-e a blokkba még további sorokat tenni. Mutató a túlcsordulási blokkra. Mutatók további blokkokra. (Az említett mutatókat az ábrákon általában a blokkok végére rajzoljuk.)")
42
Egy adatrekord szerkezete
Rekordok: Kötött: Ha mutató (pointer) mutat rá. A rekordot a helyéről nem mozgathatjuk el anélkül, hogy a rá mutató pointer meg ne változna. Szabad: Ha mutató nem mutat rá. Háttértár jobb kihasználását segíti. Header/fejléc mező1 mező2 mező3 … mezőM Törölt bit stb.
 mutat rá. A rekordot a helyéről nem mozgathatjuk el anélkül, hogy a rá mutató pointer meg ne változna. Szabad: Ha mutató nem mutat rá. Háttértár jobb kihasználását segíti. Header/fejléc. mező1. mező2. mező3. … mezőM. Törölt bit stb.")
43
Mutatók Mutatók: Mutathat rekordra vagy blokkra.
Egy mutató általában a rekord vagy blokk abszolút címét jelenti. blokkmutató rekordmutató

44
Rekord fizikai címe abszolút cím: relatív cím
A rekordot cilinder-sáv-szektor-rekordsorszám adatokból álló cím azonosítja. relatív cím Az állomány kezdőcíme + a rekordnak az ehhez viszonyított eltolási értéke.

45
Rekordok címzése Abszolút fizikai cím. Gyakoribb:
Blokk fizikai címét adjuk meg, amelyik a rekordot tartalmazza, és egy offsetet, amely a blokkon belüli kezdőcímet adja meg. Logikailag is megcímezhető: Ha pl. megadjuk kulcsának az értékét.

46
Egy adatrekord szerkezete
A rekordfejléc tartalma:: A rekord hossza Törölt/nem törölt bit (törölt-e a rekord) Használt/nem használt a rekord Időbélyegzések (mikor módosították utoljára, mikor olvasták utoljára) Nem használt hely (hogy a mezők megfelelő - pl. 4-gyel osztható - címen kezdődhessenek) A rekord formátuma (a reláció sémája) A fentiekből bizonyosakat tárolhatunk a blokkfejlécben is. Header/fejléc mező1 mező2 mező3 … mezőM Törölt bit stb.
 Használt/nem használt a rekord. Időbélyegzések (mikor módosították utoljára, mikor olvasták utoljára) Nem használt hely (hogy a mezők megfelelő - pl. 4-gyel osztható - címen kezdődhessenek) A rekord formátuma (a reláció sémája) A fentiekből bizonyosakat tárolhatunk a blokkfejlécben is. Header/fejléc. mező1. mező2. mező3. … mezőM. Törölt bit stb.")
47
Adatrekordok fájlba szervezése
Heap – rendezetlen Soros, szekvenciális Fizikai szekvenciális Logikai szekvenciális Indexelt szervezés Direkt fájlszervezés Indexelt szekvenciális szervezési megoldás Cluster szervezés

48
Heap – rendezetlen Heap – rendezetlen Rekordokat szabály nélkül,
Rendezetlenül (a beszúrások sorrendjében) helyezzük el a blokkokban. A blokkok elhelyezése nem követ semmilyen speciális elvet. 12 69 37 23 21 52 17 43 76 29
 helyezzük el a blokkokban. A blokkok elhelyezése nem követ semmilyen speciális elvet")
49
Heap – rendezetlen Keresés:
Egymás után beolvassuk a háttértárról a memóriába a kérdéses rekordokat tartalmazó állomány blokkjait, Végigolvassuk a blokkokat, amíg rá nem találunk a keresettre: Vagy egy blokk – (szerencsés eset) Az állomány valamennyi blokkja.
 Az állomány valamennyi blokkja.")
50
Soros, szekvenciális hozzáférési eljárás
Rekordok fizikailag rendezetlenül, vagy Valamilyen logikai sorrend szerint, de fizikailag rendezetlenül egymás után helyezzük el. Rendezési szempont: Egy vagy több mező, ami alapján lehet keresni. Keresési kulcs.

51
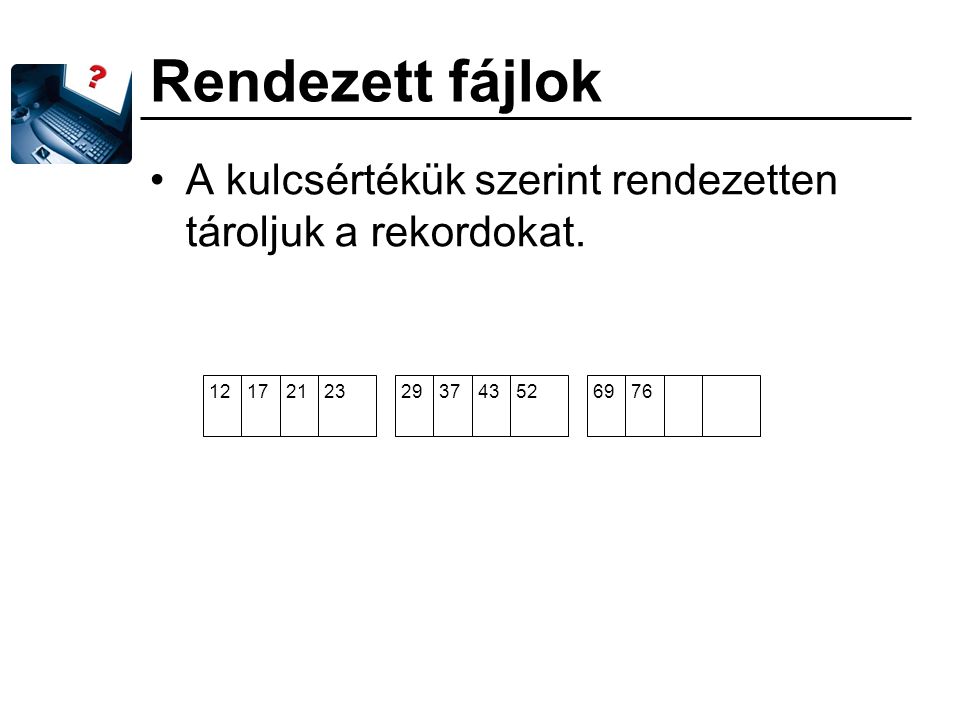
Rendezett fájlok A kulcsértékük szerint rendezetten tároljuk a rekordokat. 12 17 21 23 29 37 43 52 69 76
52
Rekordok elérése szekvenciális file-okban
fizikai szekvenciális a fizikai sorrend azonos a logikaival logikai szekvenciális: Nincs logikai kapcsolat a rekord azonosítója és az elhelyezés fizikai címe között, A sorrendiséget vmilyen „logikailag következő rekord címe” mező biztosítja. Csak közvetlen elérésű tárolón.

53
Rekordok elérése szekvenciális file-okban
logikai szekvenciális: teljes listaszerkezet indextáblában másodlagos kulcs szerinti lánc mutatótömbös megoldás

54
Logikai szekvenciális szervezés: teljes lista
Kezdőcím: 620 Logikai szekvenciális szervezés: teljes lista

55
Indextáblák alkalmazása
Indextábla Indextáblák alkalmazása Indextábla másodlagos kulcs szerinti kereséshez

56
Indextömbök alkalmazása másodlagos kulcs szerinti eléréshez

57
A szekvenciális file-szervezés
Előnyei: gyors teljes keresés háttértároló-független jó tárolókihasználás Hátrányok: egyedi keresés csak rekordvizsgálattal nehéz, lassú karbantartás körülményes kapcsolatmegvalósítás

58
A rekordokat tároló blokkok
Indexelt szervezés A keresés kulcsát egy un. index állományban megismételjük, a kulcshoz egy mutatót rendelünk, amely a tárolt adatrekord helyére mutat. A rekordokat tároló blokkok Index keresett rekordok kulcsérték

59
Indexelt szervezés A rekordok címeit az állomány feltöltésekor és később az új rekordok hozzáadásakor megőrizzük. A rekordeléréskor a rekord fizikai címét kell meghatározni, így a rekord gyorsan beolvasható.

60
Indexelt szervezés Az index:
egy olyan további adatszerkezet, amelyik a rekordok gyorsabb megkeresését segíti elő. Mindig megadott kulcsértékű rekordok megkeresését segíti elő. Az indexállomány a következő alakú bejegyzésekből (rekordokból) áll: kulcsérték mutató
 áll: kulcsérték. mutató.")
61
Index állomány Állomány

62
Sűrű index és ritka index fogalma
Az az index, ha minden adatrekordra vonatkozóan tartalmaz egy (kulcs, mutató) típusú bejegyzést. Ritka index: Az az index, ha csak bizonyos adatrekordokra vonatkozóan tartalmaz (kulcs, mutató) típusú bejegyzést. Ezek általában a blokkok első rekordjai.
 típusú bejegyzést. Ritka index: Az az index, ha csak bizonyos adatrekordokra vonatkozóan tartalmaz (kulcs, mutató) típusú bejegyzést. Ezek általában a blokkok első rekordjai.")
63
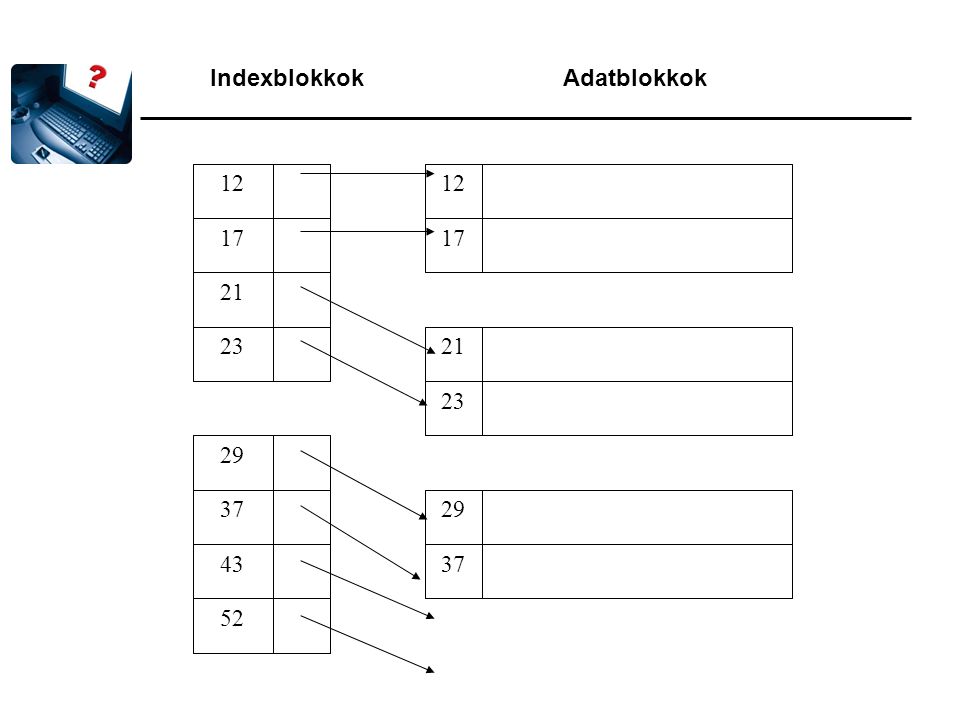
Sűrű index Az indexnek ugyanannyi rekordja van, mint az adatállománynak. Az adatállománynak a rekordokat nem kell rendezetten tárolnia. Miért jó? Az index rekordjai általában sokkal kisebbek az adatrekordoknál, így az indexblokkok száma is jóval kisebb az adatblokkok számánál. Az index rekordjai mindig kulcs szerint rendezettek, így abban bináris kereséssel lehet keresni. Ha az index elég kis méretű, akkor a leggyakrabban használt blokkjait (vagy akár az egészet) állandóan a memóriában tarthatjuk.
 állandóan a memóriában tarthatjuk.")
64
Indexblokkok Adatblokkok
12 12 17 17 21 23 21 23 29 37 29 43 37 52
65
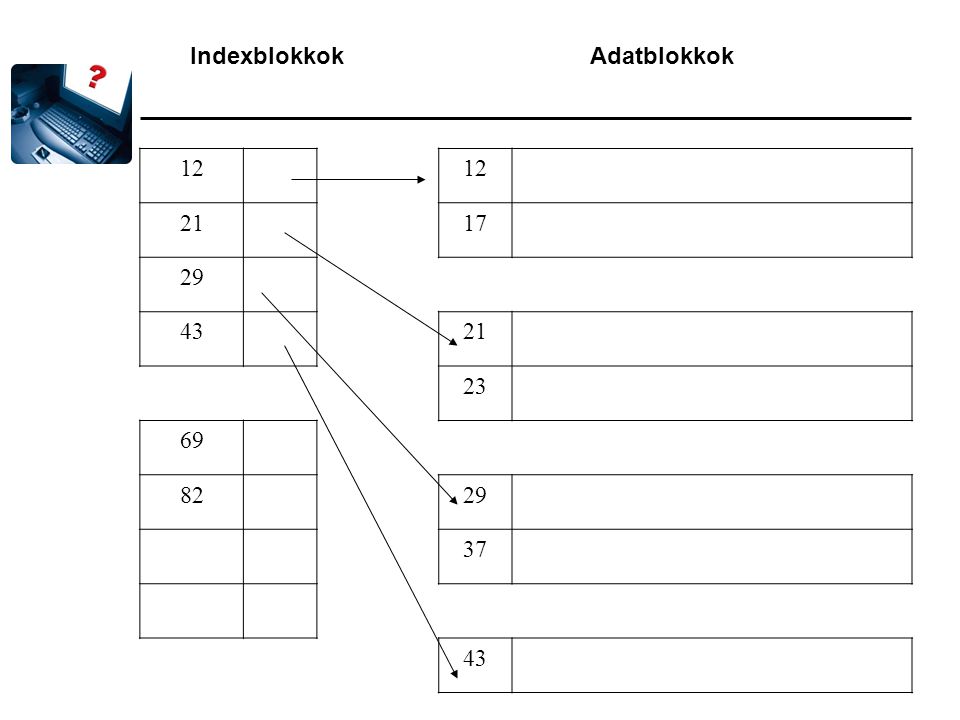
Ritka index Az indexnek annyi rekordja van, ahány blokkja van az adatállománynak. Az adatállománynak rendezetten kell tárolnia a rekordokat.

66
Indexblokkok Adatblokkok
12 21 17 29 43 23 69 82 37
67
Indexelt szervezés Az indexállományt mindig rendezetten tartjuk.
Összetett kulcs: Kulcs több mezőből áll, Definiálni kell a rendezés módját.

68
Beszúrás rendezett állományba
A beszúrás nagyon költséges lehet, ha a rekord nem fér be a megfelelő blokkba, mert a rendezettség fenntartásához sok rekordot arrébb kell mozgatnunk. Ehelyett általában túlcsordulási blokkot alkalmazunk.

69
Rekordok és a fizikai cím egymáshoz rendelése
Megközelítések: Hozzárendelés alapú Algoritmus alapú Indexelt szekvenciális.

70
Hozzárendelés alapú Keresési kulcs és a fizikai cím egymáshoz rendelése: Rekordokon belül elhelyezzük, vagy Keresési kulcshoz egy vagy többszintű táblázat formájában hozzárendeljük a fizikai címet. Indextábla előnye: Méretük miatt beolvashatók a részben vagy egészben memóriába.

71
Indexelési technikák Korszerű DBMS-ek által alkalmazott:
Egy vagy többszintű indextábla Indextömbök Állományon belüli láncolás pointerekkel (előre és visszamutató láncok stb.)
")
72
Többszintű indexek Az index rekordjaira is készíthetünk egy újabb indexet. A második szintű és a további indexek mindig ritka indexek! Ellenkező esetben ugyanannyi rekordjuk lenne, mint az általuk indexelt adatszerkezetnek, és így semmit nem érnénk velük.

73
Többszintű indexek 43 52 37 29 23 21 … 69 17 12

74
Elsődleges és másodlagos indexek
Elsődleges index: olyan index, amely meghatározza az adatrekordok fizikai elhelyezését. Pl. egy új rekord beszúrásakor az index egyértelműen meghatározza, hogy hova tehetjük be az új rekordot. Másodlagos index: az index független a rekordok fizikai elhelyezésétől.

75
Elsődleges index Elsődleges index:
A rekordok fizikai elhelyezését az elsődleges indexbeli kulcsértékük határozza meg. Elsődleges index lehet sűrű vagy ritka index, többszintű index vagy B-fa, vagy akár hasítótábla is. Elsődleges indexből csak egy lehet.

76
Másodlagos indexek Másodlagos indexből többet is létrehozhatunk. Példa
Vizsgáljuk azt a fájlt, amelynek rekordjait korábban az elsődleges kulcsa szerinti sorrendben tároltuk. Hozzunk létre egy másodlagos indexet a második (név) mező alapján. A másodlagos index mindig sűrű index, vagy többszintű index, aminek az első szintje sűrű!
 mező alapján. A másodlagos index mindig sűrű index, vagy többszintű index, aminek az első szintje sűrű!")
77
Másodlagos indexek Budai 12 Kovács Dudás 17 Dudás Felméri Kiss 21 Nagy
23 Budai Kovács Kutas 29 Kiss Major 37 Takács Nagy

78
Algoritmus alapú Fizikai cím meghatározás transzformációval
Direkt hozzáférés

79
Direkt hozzáférési eljárás
A legegyszerűbb direkt hozzáférési eljárás hasításos (angolul> hashing) módszer. Alkalmazásához szükség van: egy kulcs kijelölésére és egy úgynevezett hasítófüggvényre, amely egy kulcs értékéhez egy rekordmutatót rendel hozzá. Rekordbeíráskor: az így meghatározott rekord helyére kerül a beírandó rekord, a beírt rekordot pedig az így meghatározott rekordmutatóval érhetjük el.
 módszer. Alkalmazásához szükség van: egy kulcs kijelölésére és. egy úgynevezett hasítófüggvényre, amely egy kulcs értékéhez egy rekordmutatót rendel hozzá. Rekordbeíráskor: az így meghatározott rekord helyére kerül a beírandó rekord, a beírt rekordot pedig az így meghatározott rekordmutatóval érhetjük el.")
80
Direkt (indexelt) file-szervezés
 file-szervezés")
81
Direkt hozzáférési eljárás
A módszer alkalmazására akkor kerül sor, ha: a rekordok elhelyezése és keresése kiegészítő állományok nélkül csak egy kulcs értékei alapján történik. A módszer hátránya az úgynevezett ütközés (a hasítófüggvény két különböző kulcsértékhez ugyanazt a rekordmutatót rendeli) miatt az állomány sokkal nagyobb, mint amennyit a fájlban tárolt rekordok száma szükségessé tesz.
 miatt az állomány sokkal nagyobb, mint amennyit a fájlban tárolt rekordok száma szükségessé tesz.")
82
A direkt file-szervezés változatai
Közvetlen megfeleltetés Transzformációs eljárás determinisztikus random számítási eljárások: prímszámmal való osztás, alaptranszformáció, szorzás, négyzetre emelés, polinommal való osztás helyérték kiválasztás kombinált algoritmusok: hajtogatás, eltolás, csonkítás nem numerikus azonosítók leképezése Többszintű indextáblák

83
A direkt file-szervezés
Előnyök: gyors egyedi keresés gyors, egyszerű karbantartás egyszerű kapcsolat-megvalósítás Hátrányok: nehéz, lassú teljes keresés túlcsordulások problémája rossz tárkihasználás Tárolóközeg függő.

84
Indexelt-szekvenciális hozzáférési eljárás
A rekordokat egy keresési kulcs (ált. elsődleges kulcs) alapján rendezve valójában szekvenciális tárolást valósít meg. A rekordokra mutató címeknek (index) az állományba vagy külön indexterületekbe építésével biztosítja a direkt elérést. Ez az eljárás: a szekvenciális hozzáférés mellett lehetővé teszi, egy kulcs értékei szerinti keresést is.
 alapján rendezve valójában szekvenciális tárolást valósít meg. A rekordokra mutató címeknek (index) az állományba vagy külön indexterületekbe építésével biztosítja a direkt elérést. Ez az eljárás: a szekvenciális hozzáférés mellett lehetővé teszi, egy kulcs értékei szerinti keresést is.")
85
Indexelt-szekvenciális hozzáférési eljárás
Egy meghatározott kulcsértékű rekord megtalálásához indexet használ, amely kulcsértékeknek és rekordmutatóknak egy táblázata. Az index lehet egy vagy többszintű.

86
Indexszekvenciális szervezés
Sajátosságai egyesíti a szekvenciális és direkt szervezés előnyeit fizikailag folytonos, sorrend szerinti tárolás (azonosító, gyakoriság, betöltési sorrend) többszintű indextechnika különböző területek: indexterület elsődleges adatterület túlcsordulási terület törölt rekordok helyének felhasználása gyors egyedi és teljes keresés
 többszintű indextechnika. különböző területek: indexterület. elsődleges adatterület. túlcsordulási terület. törölt rekordok helyének felhasználása. gyors egyedi és teljes keresés.")
87
Indexszekvenciális szervezési módok
ISAM: Indexed Sequential Access Method VSAM: Virtual Sequential Access Method C-ISAM B fa, B+ tree

88
B fa A B-fa egy kiegyensúlyozott fa, egy többszintű index.
A fa csúcsait alkotó blokkok mindig legalább félig telítettek. Az indexhez soha nem kellenek túlcsordulási blokkok. Relációs DBMS-ek az indexelt szekvenciális módot B+fa szerkezettel oldják meg.

89
B tree sűrű indexelési technika Kétféle indextábla:
szekvenciális indextáblák (a logikai sorrend biztosítására) B+ fa indexek (a direkt keresésre), ezek többszintű indexállományok
 B+ fa indexek (a direkt keresésre), ezek többszintű indexállományok.")
90
B+ fa Szekvenciális indextáblák: B+fa indexek:
Célja a sorosan elhelyezkedő rekordok logikai sorrendjének biztosítása. B+fa indexek: Többszintű indextábla állományok a fa következő szintjén levő táblára mutatva tartalmazzák annak: Fizikai címét és az ott hivatkozott legmagasabb logikai azonosítót. Utolsó szint: Sorrend indextáblára mutatnak, ahol a rekordokat kulcsuk alapján keressük.

91
59. Rekord keresése B+ fa indexek (a direkt keresésre), ezek többszintű indexállományok 35 67 96 17 35 49 67 szekvenciális indextáblák (a logikai sorrend biztosítására) 6 12 17 53 59 67 6 … 17 59 35 67 96 12 53
 …")
93
Címzési módszerek Közvetlen elérésű adattárolók Két címzési forma:
egy meghatározott hely pontos megjelölése a tároló címe – fizikai cím logikai azonosító leképezése fizikai címre (milyen a kapcsolat a logikai rekord azonosítója (logikai azonosító) és az elhelyezés fizikai címe között) Két címzési forma: direkt címzés indirekt címzés
 és az elhelyezés fizikai címe között) Két címzési forma: direkt címzés. indirekt címzés.")
94
Fizikai címek Pointerek Változatai: abszolút cím:
cilinder-sáv-szektor-rekordsorszám megadásával relatív cím kezdőcím+eltolási érték szimbolikus címforma

95
Címzési módszerek Direkt címzés
logikai azonosítóból közvetlenül fizikai cím kölcsönös és egyértelmű megfeleltetés a logikai rekord kulcsa (logikai azonosító) és az elhelyezés fizikai címe között
 és az elhelyezés fizikai címe között.")
96
Címzési módszerek Indirekt címzés lényege
a rendezési fogalomból különböző képletek segítségével tároló címeket gyártanak és a rekordokat ezeken a címeken helyezik el. Ennek a tárolási módszernek az a problémája, hogy a rendezési elv és a tárolóhelyek között nem lehet olyan képletet gyártani, mely biztosítja, hogy valamennyi tárolóhely betöltésre kerüljön és csak egy rekord által, hanem előfordul az, hogy más és más rendezési elvnek ugyanaz a tároló cím felel meg a képletek alapján.

97
Címzési módszerek Indirekt címzés
Ebben az esetben úgy járnak el, hogy a már betöltött tárolóhelyen szabadon hagyott rekeszekbe megjelölik azt a helyet, ahová az úgynevezett túlcsordulási területen a kérdéses rekordot elhelyezik. ily módon a fizikai cím megkeresése után a kereső programnak lehetősége van arra, hogy a címen tájékoztatást kapjon a rekord túlcsordulási területen történő elhelyezkedésére.

98
Címzési módszerek Indirekt címzés
a számítási algoritmus két logikai rekordot ugyanarra a fizikai helyre (fizikai cím) logikai azonosító többszörös leképezés, vagy a rekordokat un. túlcsordulási területre helyezzük (Hashing algoritmus) fizikai cím
 logikai azonosító többszörös leképezés, vagy. a rekordokat un. túlcsordulási területre helyezzük. (Hashing algoritmus) fizikai cím.")
99
Adatok visszanyerése

100
Keresési módszerek Adatvisszanyerés: Keresési módszerek:
a rekord fizikai címe ismert a fizikai cím nem ismert Keresési módszerek: címmeghatározés nélküli keresés a rekord fizikai címe szerinti keresés keresés pointerláncokon keresztül keresés indextáblákkal

101
Keresés A logikai adatszervezés:
a keresési eljárásoknál a rekordok virtuális tehát logikai elhelyezkedése alapján fogjuk végezni a keresést. a rekord tároló helye: ezt úgy kell érteni, hogy melyik az a relatív hely, amelyet a rekord a logikai file-ban elfoglal. A fentiekből következik, hogyha a tárolás alatt azt értjük, hogy hogyan építjük fel a logikai file szerkezetet.

102
Keresési mechanizmusok egy rekord megtalálására
Az állománynak a keresési algoritmus szerint kell rendezve lenni. Keresési mechanizmusok: Lineáris keresés m-utas keresés bináris keresés Peterson féle keresési algoritmus

103
Keresési mechanizmusok egy rekord megtalálására
Lineáris keresés a rekordokat egyenként beolvasva hasonlítjuk a keresési argumentummal m-utas keresés az állományt azonos számú részekre bontjuk, és mindig a blokk első rekordjához hasonlítjuk

104
Keresési mechanizmusok egy rekord megtalálására
bináris keresés a keresés kezdése az állomány közepénél Peterson féle keresési algoritmus ismerni kell a kulcsok valószínűség-eloszlását az állomány két olyan részre osztása, amelyekben a kérdéses rekord előfordulási valószínűsége azonos

105
Fájl-szerkezetet Társzervezvezési mód Kapcsolatteremtés
Fájl-szervezési mód Fájl elérési mód (keresés) Kapcsolatteremtés az állományok rekordjainak egymáshoz rendelési módja
 Kapcsolatteremtés. az állományok rekordjainak egymáshoz rendelési módja.")
106
Fájlszervezési mód Fájlszervezési mód:
az a rend, ahogyan az adatrekordokat a fizikai tárolóhelyeken elhelyezzük Fájlszervezési módok: soros szervezés – rekordok az érkezés sorrendjében szekvenciális – elhelyezés a logikai azonosító sorrendjében direkt szervezés: determinisztikus kapcsolat: a logikai azonosító és az fizikai cím között random kapcsolat:: véletlen kapcsolat

107
Fájl elérési mód (keresés)
az a lehetőség, ahogyan a tárolt adatrekordokat visszanyerhetjük. Elérést meghatározó tényezők: elsődleges: a feldolgozási igény, másodlagos: tárolási lehetőség, választott szervezési mód.

108
Állománylétrehozási módszerek
Állománystruktúrák a rekordok egymáshoz való helyzete alapján szekvenciális fájlszerkezet: hierarchikus fájlszerkezet hálós fájlszerkezet asszociatív struktúrák

109
Állománylétrehozási módszerek
szekvenciális fájlszerkezet: első és az utolsó rekord kivételével mindegyik rekordnak van egy megelőző és egy követő rekordja fizikai, logikai szekvenciális fájlszervezési mód

110
Állománylétrehozási módszerek
hierarchikus fájlszerkezet rekordoknak van egy megelőzője, de több követje lehet fastruktúrák, ahol a rekordok kapcsolata, azok sorrendisége belső pointerekkel vagy indextáblákkal oldható meg hálós fájlszerkezet minden rekordnak több megelőzője és több követője is lehet a rekordok kapcsolata, azok sorrendisége belső pointerekkel vagy indextáblákkal oldható meg

111
Állománylétrehozási módszerek
asszociatív struktúrák a rekordok egymást valamilyen logikai sorrendben követik egymást indexszekvenciális állományok, B+ fák

112
A file-ok közötti kapcsolatok megteremtése

113
A file-ok közötti kapcsolatok megteremtése
rekordpárosítás azonos rendezettségű állományok között pointerek beépítése pointerlánc: egyirányú, kétirányú gyűrűs szerkezetek pointer tömbök alkalmazása indextáblák létrehozása

114
Állományon belüli pointerek alkalmazása
A láncolt listát a logikai kapcsolat ábrázolására használjuk

115
1:N fokú kapcsolat Láncszerkezet kialakítása pointerrel
Listafej Azonosító Pointer Azonosító Pointer

116
Gyűrűs szerkezet egyirányú láncolással

117
Gyűrűs szerkezet egyirányú láncolással listafejre (gyökérre mutatóan)
")
118
Gyűrűs szerkezet kétirányú láncolással

119
Állományon kívüli pointer hivatkozás
Láncolt lista a fizikai kapcsolat ábrázolására

120
Többlistás lánc gyors egyedi rekord keresés
gyors szekvenciális feldolgozási igényesetén javasolt

121
Cellás láncok 1-100

122
Állományszervezési mód megválasztása - működési hatékonyság
tárolóterület nagysága logikai tárigény nem azonos a fizikaival időtényező: létrehozási, lekérdezési, karbantartási, feldolgozási idők hardver-szoftver támogatás: tárolók típusa, IOCS, adatkezelési lehetőségek

123
Állományszervezési mód megválasztása -felhasználói igények
azonnali feldolgozások érvényességi kérdések eseményt követő feldolgozás, időbeliség feldolgozással szembeni elvárások szekvenciális közvetlen elérések gyakorisága elsődleges, másodlagos kulcs szerinti keresések

124
Állományszervezési mód megválasztása -kiválasztási szempontok
az adatbázis és állományainak jellemzői adattömeg azonosítók felépítése felhasználási paraméterek tranzakcióarány - a feldolgozandó rekordok száma feldolgozott rekordok aránya az összeshez képest karbantartás gyakorisága, mértéke

125
Állományszervezési mód megválasztása -fizikai adatkezelési jellemzők
központi tár mérete, címzési lehetőségek adatcsatorna, pufferelési technika, kapacitás perifériavezérlő képessége, működési módja adathordozók jellemzői: címezhetőség, műveleti sebesség, kapacitás, cserélhetőség

126
2005. október 10.

127
Az adathalmaz Egy meghatározott információ vagy információk egy halmazának előállításához szükséges összes objektum adatokkal történő leírásának összes előfordulását adathalmaznak nevezzük.

128
A fájl háttértárolón tárolt adathalmaz.

129
Fájlok feladata Az adatösszefüggések megjelenítése.
Az adatok tárolása a számítógép által feldolgozható formában. Adattárolás: a számítógép egy külső perifériáján valósul meg.

130
Fájl értelmezése Fájlfogalom: Kezdetben: Fájlok fizikai megvalósulása.
Logikai fájlmodell. Kezdetben: a fájlok feladata elsődlegesen az adatok tárolása volt.

131
Fájl értelmezése Fájlok fizikai megvalósulása:
ahogy a fájl az adathordozón "kinéz„. A fájl fizikai képét a állománynak nevezik. Fájl logikai képe (modellje): ahogy a fizikai megvalósulást a fájlt kezelő program a számítógép memóriájából "látja".
: ahogy a fizikai megvalósulást a fájlt kezelő program a számítógép memóriájából látja .")
132
Fájl fizikai képe – az állomány
Az állományt az adott háttértár operációs rendszere hozza létre. Ez a fizikai kép a felhasználót és a szervezőt egyáltalán nem, a programozót is csak speciális esetekben szokta érdekelni.

133
Logikai fájlmodell A fájl logikai modelljének megalkotása:
szervező feladata. Logikai fájlmodell függ: az adathalmaz méretétől és tulajdonságaitól, a felhasználás jellemzőitől, valamint annak a perifériának a jellemzőitől, amelynek segítségével a fájl adathordozóra írását megoldja.

134
Fájlok alapfogalmai Fájl: Rekord fogalmának fizikai értelmezése:
Egy adathalmaz külső adathordozón tárolt formája. Rekord fogalmának fizikai értelmezése: Ha adathalmazunk adat n-esekből áll, egy adat n-es adathordozón tárolt formáját rekordnak nevezzük.

135
Fájl fizikai képe – az állomány
Az állományokkal való gépen belüli kommunikáció meggyorsítása érdekében a háttértárak fizikailag a rekordnál nagyobb egységet kezelnek, a blokkot. Egy blokk több rekordból áll. A blokkolási tényező határozza meg ezt a rekordszámot. Ha a blokkolási tényező 1, akkor a blokk és a rekord megegyezik. Egy blokk a számítógép elkülönített memóriájában, a bufferben vár a blokkba tartozó összes rekord feldolgozására.

136
Rekorddefiníció Rekord fogalmának fizikai értelmezése
Rekord fogalmának logikai értelmezése: rekord egy adatobjektumról megállapított összes adatból álló összetett adat, azaz egy egyedelőfordulás összes egyedtulajdonságának leírása a rekord.

137
Rekordmező Egy egyedtulajdonság-előfordulásnak a rekordon belüli leírása a (rekord)mező. Kiemelt fontosságú rekordmezők: A kulcsmező (vagy röviden kulcs) egy adott keresési szempont esetén felhasznált mező. Egy rekordkereséseben több mező is szerepelhet kulcsként. több mező esetén mindegyik mezőt kulcsnak nevezzük, de a rekordok sorrendjét meghatározó szerepük/hierarchiájuk alapján beszélünk elsődleges, másodlagos stb. kulcsról.
 egy adott keresési szempont esetén felhasznált mező. Egy rekordkereséseben több mező is szerepelhet kulcsként. több mező esetén mindegyik mezőt kulcsnak nevezzük, de a rekordok sorrendjét meghatározó szerepük/hierarchiájuk alapján beszélünk elsődleges, másodlagos stb. kulcsról.")
138
Fájlokkal kapcsolatos fogalmak
Rekord: egy adatobjektum képe a fájlban. (Rekord)mező: egy adatelem képe a fájlban. Kulcsmező: egy adott szempontú keresés során használt mező. Kulcs: kulcsmezők összessége.
mező: egy adatelem képe a fájlban. Kulcsmező: egy adott szempontú keresés során használt mező. Kulcs: kulcsmezők összessége.")
139
Hierarchikus viszonyok egy fájlban

140
Fájldeklaráció A fájl leírása létrehozás céljából, ahol megadandó:
a fájl mezői; a mezők típusa; a mezők mérete; a fájl rekordtípusa; a fájl kulcsmezői.

141
Fájlok osztályozása Az osztályozás történhet: felhasználás szerint;
a rekordok felépítése szerint; a rekordok elhelyezése szerint; a rekordok hozzáférési eljárásai szerint.

142
Fájlok osztályozása Felhasználás szerint: törzsfájl; tranzakciófájl;
munkafájl; listafájl; kódtáblázatfájl.

143
Fájlok osztályozása A rekordok felépítése szerint:
állandó rekordhosszúságú fájl, változó rekordhosszúságú fájl.

144
Állandó rekordhosszúságú fájl
minden rekord azonos számú mezőt tartalmaz; egy tulajdonságtípusnak megfelelő mező hossza állandó, azaz azonos számú karaktert tartalmazhat. Általában az állandó rekordhosszúságú fájl egy rekordja nem tartalmaz ismétlődő mezőket vagy ha igen, a mező minden rekordban ugyanannyiszor ismétlődik: például ha egy év havi bevételei egy rekordban szerepelnek. Tipikusan: A törzsfájlok, munkafájlok állandó rekordhosszúságú fájlok.

145
Változó rekordhosszúságú fájl
Vagy rekordonként változó számú ismétlődő mezőket találhatunk, vagy egy vagy több olyan mezőt, amelynek mezőhossza rekordonként változhat. Tipikusan: listafájlok változó rekordhosszúságúak.

146
Fájlok osztályozása A fájlok felépítését meghatározza:
a rekordok elhelyezése és a rekordok hozzáférési eljárásai. A rekordok elhelyezése szerint: rendezetlen fájl a rekordok sorrendjét a fájlba érkezés sorrendje határozza meg. rendezett fájl. egy kulcs értékeinek növekvő vagy csökkenő sorrendje határozza meg az egymás utáni rekordokat.

147
A rekordok hozzáférési eljárásai
A tárolt adatokat általában több, különböző program használja, ezért a rekordokat úgy kell elhelyezni, szervezni a fájlon belül, hogy: mindegyik program hozzáférjen a számára szükséges rekordhoz vagy rekordokhoz. A rekordok elérése: a rekordhozzáférési eljárások biztosítják.

148
Fájlok osztályozása A rekordok hozzáférési eljárásai szerint:
szekvenciális fájl; direkt fájl; indexelt-szekvenciális fájl.

149
Fájlszervezés Fájlszervezés:
egy fájl rekordjainak, rekordmutatóinak, indextáblázatainak, kiegészítő állományainak szerkezete. A fájlszervezés és a fájlban használható rekordhozzáférési eljárások szoros kapcsolatban vannak egymással. A legegyszerűbb esetben, amikor csak egyféle hozzáférési eljárás használható, ugyanazt a kifejezést használhatjuk a fájl szervezettségének megjelölésére, mint a hozzáférési eljárásra.

150
Fájlszerkezetek Szekvenciális fájl Direkt fájl

151
Fájlszerkezetek A szekvenciális fájl:
a rekordok fizikailag egymás után következnek, vagy rekordmutatók használatával egy láncolt lista határozza meg a rekordok sorrendjét. A szekvenciális fájlszervezés nem igényli egy kulcs szerinti rendezettséget, de rendezett szekvenciális fájlok használata több feldolgozástípus esetén jelent előnyt.

152
rekordcím = első_rekord_címe + rekordmutató * rekordhossz
Fájlszerkezetek Direkt fájl: a rekordok eléréséhez rekordmutatók használhatók, azaz a fájl tetszőleges sorszámú rekordja kijelölhető feldolgozásra. Ennek a rekordmutatónak az értéke nem szerepel a rekordban, hanem a direkt hozzáférési eljárások egy adott rekord fizikai címét a háttértárban a következőképpen számolják ki: rekordcím = első_rekord_címe + rekordmutató * rekordhossz

153
Fájlszerkezetek Ebből a képletből két következtetést vonható le:
célszerű az első rekord mutatójának 0-t választani; a rekordok hosszúsága állandó. Direkt fájl esetén: az adott feldolgozás és az alkalmazott programnyelv határozza meg, hogy melyik direkt rekordhozzáférési eljárás kerül alkalmazásra, vagy a rekordmutatókon alapuló egyedi eljárás kidolgozására van szükség.

154
Állománylétrehozási módszerek
Állománystruktúrák a rekordok egymáshoz való helyzete alapján szekvenciális fájlszerkezet: hierarchikus fájlszerkezet hálós fájlszerkezet asszociatív struktúrák

155
Állománylétrehozási módszerek
szekvenciális fájlszerkezet: első és az utolsó rekord kivételével mindegyik rekordnak van egy megelőző és egy követő rekordja fizikai, logikai szekvenciális fájlszervezési mód

156
Állománylétrehozási módszerek
hierarchikus fájlszerkezet rekordoknak van egy megelőzője, de több követje lehet fastruktúrák, ahol a rekordok kapcsolata, azok sorrendisége belső pointerekkel vagy indextáblákkal oldható meg hálós fájlszerkezet minden rekordnak több megelőzője és több követője is lehet a rekordok kapcsolata, azok sorrendisége belső pointerekkel vagy indextáblákkal oldható meg

157
Állománylétrehozási módszerek
asszociatív struktúrák a rekordok egymást valamilyen logikai sorrendben követik egymást indexszekvenciális állományok, B+ fák

158
Szekvenciális (soros) hozzáférési eljárás
A rekordok egyetlen sorrendben, a fájl első rekordjától az utolsó felé haladva érhetők el. Ez a sorrend megegyezik a rekordok létrehozásának sorrendjével. Ha az állomány egy vagy több kulcsmező szerint átrendezésre kerül, a rekordok csak a rendezés szerinti sorrendben érhetők el. Alkalmazása a fájlt használó program a rekordok összességének feldolgozását igényli.

159
Rekordok elérése szekvenciális file-okban
fizikai szekvenciális a fizikai sorrend azonos a logikaival logikai szekvenciális: Nincs logikai kapcsolat a rekord azonosítója és az elhelyezés fizikai címe között, A sorrendiséget vmilyen „logikailag következő rekord címe” mező biztosítja. Csak közvetlen elérésű tárolón.

160
Rekordok elérése szekvenciális file-okban
logikai szekvenciális: teljes listaszerkezet indextáblában másodlagos kulcs szerinti lánc mutatótömbös megoldás

161
Logikai szekvenciális szervezés: teljes lista
Kezdőcím: 620 Logikai szekvenciális szervezés: teljes lista

162
Indextáblák alkalmazása
Indextábla Indextáblák alkalmazása Indextábla másodlagos kulcs szerinti kereséshez

163
Indextömbök alkalmazása másodlagos kulcs szerinti eléréshez

164
A szekvenciális file-szervezés
Előnyei: gyors teljes keresés háttértároló-független jó tárolókihasználás Hátrányok: egyedi keresés csak rekordvizsgálattal nehéz, lassú karbantartás körülményes kapcsolatmegvalósítás

165
Direkt hozzáférési eljárás
Véletlen hozzáférési eljárás. A rekordok tetszőleges sorrendben történő elérését teszi lehetővé, azaz egy rekord eléréséhez nem kell a rekordot megelőző rekordokat is elolvasni, feldolgozni. Alkalmazás: a fájlt használó program csak néhány rekord elérését, feldolgozását igényli. Ez az eset áll fenn az on-line lekérdező programok esetében.

166
Direkt hozzáférési eljárás
A direkt hozzáférési eljárás többféleképpen is megvalósítható. A megvalósítás mindegyik módszere a fájl rekordmutatóin alapszik. A rekordmutató: a fájl rekordjainak azonosítására szolgáló szám, és azt teszi lehetővé, hogy egy meghatározott mutatójú rekord közvetlenül, egy lépésben elérhető legyen.

167
Direkt hozzáférési eljárás
A legegyszerűbb direkt hozzáférési eljárás hasításos (angolul> hashing) módszer. Alkalmazásához szükség van: egy kulcs kijelölésére és egy úgynevezett hasítófüggvényre, amely egy kulcs értékéhez egy rekordmutatót rendel hozzá. Rekordbeíráskor: az így meghatározott rekord helyére kerül a beírandó rekord, a beírt rekordot pedig az így meghatározott rekordmutatóval érhetjük el.
 módszer. Alkalmazásához szükség van: egy kulcs kijelölésére és. egy úgynevezett hasítófüggvényre, amely egy kulcs értékéhez egy rekordmutatót rendel hozzá. Rekordbeíráskor: az így meghatározott rekord helyére kerül a beírandó rekord, a beírt rekordot pedig az így meghatározott rekordmutatóval érhetjük el.")
168
Direkt (indexelt) file-szervezés
 file-szervezés")
169
Direkt hozzáférési eljárás
A módszer alkalmazására akkor kerül sor, ha: a rekordok elhelyezése és keresése kiegészítő állományok nélkül csak egy kulcs értékei alapján történik. A módszer hátránya az úgynevezett ütközés (a hasítófüggvény két különböző kulcsértékhez ugyanazt a rekordmutatót rendeli) miatt az állomány sokkal nagyobb, mint amennyit a fájlban tárolt rekordok száma szükségessé tesz.
 miatt az állomány sokkal nagyobb, mint amennyit a fájlban tárolt rekordok száma szükségessé tesz.")
170
A direkt file-szervezés változatai
Közvetlen megfeleltetés Transzformációs eljárás determinisztikus random számítási eljárások: prímszámmal való osztás, alaptranszformáció, szorzás, négyzetre emelés, polinommal való osztás helyérték kiválasztás kombinált algoritmusok: hajtogatás, eltolás, csonkítás nem numerikus azonosítók leképezése Többszintű indextáblák

171
Direkt file-szervezés
Indextábla Állomány

172
Túlcsordulások kezelése
Két logikai azonosítóból ugyanaz a cím generálódik Megoldás: újabb algoritmus alkalmazása független túlcsordulási területen elhelyezés láncolási technika alkalmazásával: egyedi rekordokat láncolunk vagy bugyrot képezünk láncolás nélkül bugyrok képzésével osztott túlcsordulási területen

173
A direkt file-szervezés
Előnyök: gyors egyedi keresés gyors, egyszerű karbantartás egyszerű kapcsolat-megvalósítás Hátrányok: nehéz, lassú teljes keresés túlcsordulások problémája rossz tárkihasználás Tárolóközeg függő.

174
Indexelt-szekvenciális hozzáférési eljárás
A direkt hozzáférési eljárás másik megvalósítása: az indexelt-szekvenciális hozzáférési eljárás (angol rövidítéssel: ISAM). Ez az eljárás: a szekvenciális hozzáférés mellett lehetővé teszi egy kulcs értékei szerinti keresést is.
. Ez az eljárás: a szekvenciális hozzáférés mellett lehetővé teszi. egy kulcs értékei szerinti keresést is.")
175
Indexelt-szekvenciális hozzáférési eljárás
Direkt hozzáférési eljárás: a kulcs szerinti kereséshez indexeket használ. Egy index kulcsértékeket és rekordmutatókat tartalmazó táblázat. Az index lehet egyszintű vagy többszintű. Az indexek külön fájlba, ún. indexfájlba kerülnek. Alkalmazása Gyakori, összetett feltételű keresése esetén.

176
Indexelt-szekvenciális hozzáférési eljárás
Egy meghatározott kulcsértékű rekord megtalálásához indexet használ, amely kulcsértékeknek és rekordmutatóknak egy táblázata. Az index lehet egy vagy többszintű.

177
Indexelt-szekvenciális hozzáférési eljárás
Az egyszintű indexben, ill. a többszintű index legalsó szintjén a kulcsértékek mellett a rekordmutatókat találjuk, míg a többszintű index felsőbb szintjein a kulcsértékek mellett az alattuk lévő szint táblázataira találunk utalásokat. Az index általában kiegészítő állományba, úgynevezett indexfájlba kerül. Egy fájlhoz általában több indexfájlt is lehet hozzárendelni.

178
Indexszekvenciális szervezés
Sajátosságai egyesíti a szekvenciális és direkt szervezés előnyeit fizikailag folytonos, sorrend szerinti tárolás (azonosító, gyakoriság, betöltési sorrend) többszintű indextechnika különböző területek: indexterület elsődleges adatterület túlcsordulási terület törölt rekordok helyének felhasználása gyors egyedi és teljes keresés
 többszintű indextechnika. különböző területek: indexterület. elsődleges adatterület. túlcsordulási terület. törölt rekordok helyének felhasználása. gyors egyedi és teljes keresés.")
179
Indexszekvenciális szervezési módok
ISAM: Indexed Sequential Access Method VSAM: Virtual Sequential Access Method C-ISAM B tree, B+ tree

180
Egyszintű index aktuális rekordok
Balogh Császár Fazekas Galambos Horváth Huszár Király Kiss Kovács Lovász Mecseki Nagy Németh indextáblázat Balogh Nagy Török Zalai

181
Út “Lovász” rekordjának megtalálásához
Balogh Császár Fazekas Galambos Horváth Huszár Király Kiss Kovács Lovász Mecseki Nagy Németh Balogh Nagy Török Zalai

182
Kétszintű index aktuális rekordok indextáblázat (2. szint)
Balogh Császár Fazekas Galambos Horváth Huszár Király Kiss Kovács Lovász Mecseki Nagy Németh indextáblázat (1. szint) Balogh Galambos Kiss Nagy Szabó Balogh Nagy Török Zalai
 Balogh Galambos Kiss. Nagy Szabó. Balogh Nagy Török Zalai.")
183
Út “Lovász” rekordjának megtalálásához
Balogh Császár Fazekas Galambos Horváth Huszár Király Kiss Kovács Lovász Mecseki Nagy Németh Balogh Galambos Kiss Nagy Szabó Balogh Nagy Török Zalai

Hasonló előadás




 Budapest>")





.>")

 definiálása,>")






